
Abstract
A number of experiments have revealed that matched-case identity PRIME–TARGET pairs are responded to faster than mismatched-case identity prime–TARGET pairs for pseudowords (e.g., JUDPE–JUDPE < judpe–JUDPE), but not for words (JUDGE–JUDGE = judge–JUDGE). These findings suggest that prime–target integration processes are enhanced when the stimuli tap onto lexical representations, overriding physical differences between the stimuli (e.g., case). To track the time course of this phenomenon, we conducted an event-related potential (ERP) masked-priming lexical decision experiment that manipulated matched versus mismatched case identity in words and pseudowords. The behavioral results replicated previous research. The ERP waves revealed that matched-case identity-priming effects were found at a very early time epoch (N/P150 effects) for words and pseudowords. Importantly, around 200 ms after target onset (N250), these differences disappeared for words but not for pseudowords. These findings suggest that different-case word forms (lower- and uppercase) tap into the same abstract representation, leading to prime–target integration very early in processing. In contrast, different-case pseudoword forms are processed as two different representations. This word–pseudoword dissociation has important implications for neural accounts of visual-word recognition.
Similar content being viewed by others
Despite the variability in physical appearance of a written word (e.g., house, HOUSE, house), skilled readers are able to access the appropriate lexical entry in a few hundreds of milliseconds. When and how the stimulus features are coded in an abstract manner are the main questions in this article. These are not trivial issues, since this process of abstraction might take place at an individual-letter level, at a graphemic level, at a whole-word level, or even at a semantic level. To make matters even more complex, feedforward and feedback connections might also exist among the levels.
There is some consensus among researchers that a word’s constituent letters are coded in an abstract form that is independent of its physical features (see Bowers, 2000, and Thompson, 2009, for reviews). Although initially the word-processing system is sensitive to differences in the visual features of stimuli, these differences are quickly diffused by mapping these features onto unique orthographic abstract representations (see Dehaene, Cohen, Sigman, & Vinckier, 2005, and Grainger, Rey, & Dufau, 2008, for neurally motivated accounts of this phenomenon). The assumption that abstract representations are rapidly accessible during visual-word recognition has come mainly from previous experimental evidence using the masked-priming technique (Forster & Davis, 1984; see Grainger, 2008, for a review; see Dehaene et al., 2001, 2004, for the neuroanatomic signature of masked priming). In the present experiment, we aimed to analyze the time course of the abstract orthographic level of representation (independent of visual feature mapping) through a matched- versus mismatched-case masked-priming experiment with words and pseudowords.Footnote 1
In an elegant masked-priming lexical decision experiment, Jacobs, Grainger, and Ferrand (1995) compared matched-case versus mismatched-case identity word pairs (YEUX–####–YEUX vs. yeux–####–YEUX [eyes]) and found that, despite the greater visual similarity for the matched-case identity pairs, word identification times were virtually the same in the two conditions. Perea, Jiménez, and Gómez (2014) replicated the Jacobs et al. (1995) pattern in words with high degree of cross-case visual similarity (e.g., city–###–CITY = CITY–###–CITY) and in words with low degree of cross-case visual similarity (e.g., edge–###–EDGE = EDGE–###–EDGE; see also Perea, Jiménez, & Gomez, 2015, for evidence with developing readers). Furthermore, the magnitude of the repetition priming effect (i.e., identity condition vs. unrelated condition) was similar in both types of stimuli, thus replicating Bowers, Vigliocco, and Haan (1998). Taken together, these findings are consistent with the accounts that assume that there is fast access to abstract representations. In order to disentangle whether the functional and structural specialization on abstract orthographic coding begins at a letter or at a lexical level of processing, it is relevant to examine whether this pattern of results holds for pseudowords (i.e., orthographic codes with no lexical entry).
Importantly, the response times (RTs) for pseudowords were shorter in the matched-case identity PRIME–TARGET condition than in the mismatched-case identity prime–TARGET condition (e.g., CURDE–####–CURDE faster than curde–#####–CURDE; Jacobs et al., 1995; see Perea et al., 2014, for parallel evidence in French, Spanish, and English). To explain this dissociation, Perea et al. (2014) argued that, for words, fast access to abstract lexical representations makes the visual dissimilarity between prime and target irrelevant for further processes. In contrast, for pseudowords, there is no abstract lexical representation that could cancel out the facilitative effect of case-specific identity priming. This means that the null differences between matched- versus mismatched-case identity priming for words occur as a consequence of top-down effects from the lexical to the orthographic/letter level, thus posing problems for purely feedforward accounts of letter/word processing (e.g., the Bayesian reader model; Norris & Kinoshita, 2008). Indeed, interactive models of visual-word recognition assume that visual information continuously cascades throughout the entire orthographic–phonological–lexical–semantic network (see Carreiras, Armstrong, Perea, & Frost, 2014, for a recent review), and the interaction between different levels of processing is what consolidates the orthographic units of the target word.
To tease apart the different components during lexical processing, an excellent approach is to collect event-related potentials (ERPs). Previous research using masked repetition priming in combination with ERPs has defined a series of components during visual-word recognition (see Grainger & Holcomb, 2009, for a review). Two of these ERP components are of specific interest for our present study: the N/P150 and the N250. First, the N/P150 is a bipolar ERP component peaking between 80 and 150 ms approximately. It reaches positive (P) values over more anterior sites, and negative (N) values on more occipital sites. Importantly, its amplitude is modulated by physical-feature overlap across the prime and target, which may reflect processing at the level of size-invariant visual features (Holcomb & Grainger, 2006). Second, the N250 is an ERP component that starts around 150 ms and peaks around 300 ms. This component shows a widespread scalp distribution (larger over anterior scalp areas), and its amplitude is a function of the prime–target orthographic overlap (e.g., larger for porch–TABLE than for teble–TABLE, which in turn is larger than for table–TABLE; HoIcomb & Grainger, 2006; Kiyonaga, Grainger, Midgley, & Holcomb, 2007). Of particular relevance here are the findings of Chauncey, Holcomb, and Grainger (2008) in a semantic categorization task with word targets, in which they manipulated changes in size (e.g., table–table) and font (e.g., table–table) between the prime and target. ERP effects were restricted to an N/P150 amplitude modulation by the font manipulation, whereas null effects were observed in the N250 component. Hence, when the N250 component appears, size and shape invariance have already been achieved, and this can be interpreted as further evidence of access to abstract orthographic representations. Recent research has shown that the N250 amplitude can also be modulated by lexical factors (Duñabeitia, Molinaro, Laka, Estévez, & Carreiras, 2009; Massol, Midgley, Holcomb, & Grainger, 2011; Morris, Franck, Grainger, & Holcomb, 2007), reflecting the interaction between prelexical bottom-up and lexical-semantic top-down representations (Morris et al., 2007).
Taken together, there is substantial evidence for early effects of physical feature processing leading to later abstract representations. There are still, however, unanswered questions related to the degree of feedback in the system. The main aim of the present experiment was to examine how abstract orthographic representations are computed during visual-word recognition. In particular, we tracked the time course of the electrophysiological response to words and pseudowords preceded by an identity prime that either matched or mismatched in case (e.g., words: ALTAR–ALTAR vs. altar–ALTAR; pseudowords: CURDE–CURDE vs. curde–CURDE). To avoid the differential impact of any low-level characteristics of the letters that composed the words and pseudowords (e.g., in terms of cross-case visual overlap; cf. a–A vs. u–U), each letter occurred approximately the same number of times in words and pseudowords.Footnote 2 For consistency with previous research on this issue (e.g., Jacobs et al., 1995; Perea et al., 2014), we also included unrelated words and pseudowords as primes—half of the unrelated primes in lowercase and the other half in uppercase.
At early orthographical encoding stages, no difference in the ERP waves should be obtained between words and pseudowords regarding the case-match identity manipulation: Any difference should emerge as a consequence of top-down effects from the lexical to the abstract orthographic level of encoding. Therefore, the latency of this dissociation would reveal feedback from lexical to orthographic processing. Specifically, we predicted an N/P150 effect of case-match identity masked priming for both the word and pseudoword targets, since the visual features of prime and target are different in the mismatched-case identity condition (as compared to the matched-case condition). This effect was expected to disappear/attenuate as soon as shape invariance was achieved during orthographic processing (around 200–300 ms poststimulus: N250: Carreiras, Perea, Gil-López, Abu Mallouh, & Salillas, 2013; Chauncey et al., 2008; Petit, Midgley, Holcomb & Grainger, 2006). That is, if prelexical orthographic representations are tapped into relatively early in processing, then N/P150 differences due to prime–target visual dissimilarity would be expected to dissipate in later epochs (N250) not only for words, but also for pseudowords. However, if the early difference due to visual dissimilarity does not dissipate for pseudowords, as would be inferred from previous behavioral evidence (Jacobs et al., 1995; Perea et al., 2014), then this would imply that the N250 component reflects lexical rather than (abstract) orthographic effects. Importantly, a word–pseudoword dissociation in the N250 component would also imply that the orthographic (abstract) encoding of words is modulated by lexical factors, thus posing strong problems for purely feedforward accounts of letter–word processing.
Method
Participants
A group of 24 undergraduate students of the University of Valencia (14 women, 10 men) participated in the experiment in exchange for course credit or for a small gift. All of them were native Spanish speakers with no history of neurological or psychiatric impairment, and with normal (or corrected-to-normal) vision. Their ages ranged from 19 to 30 years (mean = 22.5 years, SD = 3.4). All participants were right-handed, as assessed with a Spanish abridged version of the Edinburgh Handedness Inventory (Oldfield, 1971). The data from two participants were discarded because of noisy electroencephalogram (EEG) data.
Materials
We selected a set of 160 five-letter words from the B-Pal Spanish database (Davis & Perea, 2005). The mean frequency per million was 18.6 (range: 10–37.7), and the mean number of orthographic neighbors was 1.9 (range: 0–4). A matched set of 160 pseudowords was created using the Wuggy package (Keuleers & Brysbaert, 2010). The set of words and pseudowords was carefully matched in terms of the distributional properties of the letters [i.e., a given letter (a, b, c, etc.) occurred equally frequently in the experimental set of words and pseudowords: χ 2(22) = 4.25, p > .95]. The list of words/pseudowords is presented in Appendix A. All targets (words or pseudowords) were presented in uppercase and were preceded by a prime that was (i) the same as the target, including the case (matched-case identity condition; e.g., ALTAR–ALTAR); (ii) the same as the target, but in a different case (mismatched-case identity condition; e.g., altar–ALTAR); (iii) an unrelated word prime (half in lowercase, half in uppercase); and (iv) an unrelated pseudoword prime (half in lowercase, half in uppercase). Four counterbalanced lists were created so that each target stimulus was rotated across the different conditions.
Procedure
Participants were seated comfortably in a dimly lit and sound-attenuated chamber. All stimuli were presented on a high-resolution monitor that was positioned at eye level one meter in front of the participant. The stimuli were displayed in white lowercase Courier 24-pt font against a dark-gray background. Participants performed a lexical decision task: they had to decide as accurately and rapidly as possible whether or not the stimulus was a Spanish word. They pressed one of two response buttons (YES/NO). The hand used for each type of response was counterbalanced across subjects. RTs were measured from target onset until the participant’s response.
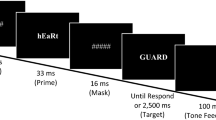
The sequence of events in each trial was as follows: A forward pattern mask (i.e., a series of #s) of 500-ms duration preceded the prime stimulus, which was shown for 33 ms (i.e., two refresh cycles at 60 Hz), which in turn was replaced by a 16.7-ms pattern mask (i.e., one refresh cycle). Then, the target stimulus was presented in the same spatial location as the prime until the participant responded or 1,500 ms had elapsed. A blank screen of random duration (range: 700–1,000 ms) was presented after the response (see Fig. 1).

Depiction of events within a trial
Sixteen practice trials preceded the experimental phase, and brief, 10-s breaks occurred every 60 trials. Every 120 trials, there was a brief pause for resting and impedance checking. To minimize participant-generated artifacts in the EEG signal during the presentation of the experimental stimuli, participants were asked to refrain from blinking and making eye movements from the onset of each trial to the response. Each participant received the stimuli in a different random order. The whole experimental session lasted approximately 45 min.
EEG recording and analyses
The EEG was recorded from 32 electrodes mounted in an elastic cap, and referenced to the right mastoid. The EEG recording was re-referenced offline to an average of the left and right mastoids. Impedances were kept below 5 kΩ. The EEG signal was band-pass filtered between 0.01 and 20 Hz and sampled at 250 Hz. All single-trial waveforms were screened offline for amplifier blocking, drift, muscle artifacts, eye movements, and blinks. This was done for a 550-ms epoch with a 150-ms prestimulus baseline. Trials containing artifacts and/or trials with incorrect lexical decision responses were not included in the average ERPs or in the statistical analyses. These processes led to an average rejection rate of 12 % of all trials (8.3 % due to artifact rejection; 3.7 % due to incorrect responses). An ANOVA on the number of included trials per condition showed no difference between conditions (Fs < 1). Importantly, at least 30 trials were included for each condition in the average ERP data from each participant. ERPs were averaged separately for each of the experimental conditions, each of the participants, and each of the electrode sites.
Statistical analyses were performed on the mean ERP values in three contiguous time windows (N/P150: 80–150 ms; N250: 250–350 ms; N400: 400–500 ms). This was done for the four experimental conditions defined by the combination of the factors Lexicality (words, pseudowords) and Case (matched, mismatched). The selection of these epochs was motivated by our aim to track the time course of the potential differences between experimental conditions, and was determined by visual inspection and on the basis of previous studies (Chauncey et al., 2008; Grainger & Holcomb, 2009; Holcomb & Grainger, 2006). Following a similar strategy in the related literature (see, e.g., Vergara-Martínez, Perea, Gómez, & Swaab, 2013; Vergara-Martínez & Swaab 2011), we analyzed the topographical distribution of the ERP results by including the averaged amplitude values across three electrodes of four representative scalp areas that resulted from the factorial combination of the factors Hemisphere (left, right) and Anterior–Posterior (AP) Distribution (anterior, posterior): left anterior (F3, FC5, FC1), left posterior (CP5, CP1, P3), right anterior (F4, FC2, FC6), and right posterior (CP2, CP6, P4) (see Fig. 2).

Schematic representation of the electrode montage
This strategy was applied in each ERP analysis of the present experiment. For each time window, a separate repeated measures analysis of variance (ANOVA) was performed, including the factors Hemisphere, AP Distribution, Lexicality, and Case. In all analyses, List (1–4) was included as a between-subjects factor in order to extract the variance that was due to the counterbalanced lists (Pollatsek & Well, 1995). Main effects of lexicality are reported when they are relevant for the interpretation of the results. Effects of the AP Distribution or Hemisphere factor are reported when they interact with the experimental manipulations. Interactions between factors were followed up with simple-effect tests.
Results
Behavioral results
Incorrect responses and lexical decision times less than 250 ms or greater than 1,500 ms were excluded from the latency analyses. The mean lexical decision times and the error rates per condition are displayed in Table 1. The mean lexical decision times and percentages of errors were submitted to separate ANOVAs with a 2 (Lexicality: word, pseudoword) × 2 (Case: matched, mismatched) design. As we indicated above, List was also included in the analyses as a dummy factor in the design (four levels: Lists 1–4). In the behavioral analyses, we computed the F ratios by participants (F 1) and by items (F 2). We examined the usual “repetition-priming” effect (i.e., identity vs. unrelated priming conditions), with results presented in Appendix B (see Perea et al., 2014, for a similar approach). To summarize the findings reported in the appendix, we replicated the same pattern from the earlier experiments: We found a substantial repetition-priming effect for words, and a rather weak effect for pseudowords, at both the behavioral level (see Jacobs et al., 1995; Perea et al., 2014) and the electrophysiological level (e.g., see Kiyonaga et al., 2007, for smaller masked repetition effects in pseudowords than in words on the N250 component, and for null effects on subsequent time windows for pseudoword relative to word stimuli; see also Figs. 6b and 8a in Grainger & Holcomb, 2009).
The ANOVA on the latency data revealed that, unsurprisingly, words were responded to faster than the pseudowords (579 vs. 682 ms, respectively), F 1(1, 18) = 184.07, p < .001; F 2(1, 312) = 480.23, p < .001. In addition, the target stimuli were responded to faster when they were preceded by a matched-case identity prime rather than a mismatched-case identity prime (622 vs. 639 ms), F 1(1, 18) = 7.56, p = .013; F 2(1, 312) = 13.2, p < .001. More importantly, the effect of case was qualified by a significant interaction between the two factors, F 1(1, 18) = 7.26, p = .015; F 2(1, 312) = 7.44, p = .007. This interaction reflected that, for pseudoword targets, responses were, on average, 27 ms faster when the pseudoword was preceded by a matched-case rather than a mismatched-case identity prime, F 1(1, 18) = 10.41, p = .005; F 2(1, 156) = 18.01, p < .001, whereas, for word targets, no signs of a parallel effect were apparent (i.e., a nonsignificant 6-ms difference, both Fs < 1).
The ANOVA on the error data failed to reveal any main effects of lexicality or case (all Fs < 1), but we did find a significant interaction between the two factors, F 1(1, 18) = 11.3, p = .003; F 2(1, 312) = 14.82, p < .001. This interaction reflected that, for pseudoword targets, participants made more errors when they were preceded by a mismatched-case identity prime than when they were preceded by a matched-case identity prime (5.1 % vs. 3.1 %, respectively), F 1(1, 18) = 2.64, p = .12; F 2(1, 156) = 4.56, p = .034. For word targets, participants made fewer errors when the words were preceded by a mismatched-case identity prime than when they were preceded by a matched-case identity prime (2.0 % vs. 4.9 %, respectively; this corresponds to 0.8 vs. 1.9 errors per participant), F 1(1, 18) = 22.30, p < .001; F 2(1, 156) = 11.05, p = .001.Footnote 3
Taken together, the behavioral data replicated previous research (Jacobs et al., 1995; Perea et al., 2014): For pseudoword targets, lexical decision times were shorter when the target was preceded by a matched-case identity prime than when it was preceded by a mismatched-case identity prime (e.g., CURDE–CURDE < curde–CURDE), whereas for word targets, the case of the identity prime did not matter (e.g., ALTAR–ALTAR = altar–ALTAR). Note, however, that a small speed–accuracy trade-off occurred in the word data: Participants were slightly faster (6 ms) when the prime had the same case as the target, but they also made more errors (1.1, on average). This marginal trade-off is likely to be an empirical anomaly, since Perea et al. (2014, 2015) reported a null effect for word targets in the RTs and accuracy for these same conditions.
ERP results
Figure 3 shows the ERP waves for words and pseudowords (matched vs. mismatched case) in four representative electrodes (the occipital electrodes are also displayed, to show the bipolar nature of the N/P150). The ERPs in the target epoch produced an initial small negative potential peaking around 50 ms, which was followed by a much larger and slower positivity (P2) ranging between 100 and 250 ms (see the anterior locations; note that the opposite pattern is shown in the occipital electrodes). At posterior sites, in this same time frame, the positivity is smaller and faster, peaks earlier (before 150 ms), and is followed by two subsequent negativities (at 180 and 250 ms, approx.). Following these early potentials, a large and slow negativity peaking around 350 ms can be seen at both anterior and posterior areas (N400). Following the N400 component, the waves remain positive until the end of the epoch (550 ms).

Grand average event-related potentials to words and pseudowords in the two matched-case conditions (see legend), in four representative electrodes from the four areas of interest. Electrodes O1 and O2 are presented at the bottom to show the mirror nature of the N/P150 in different areas. The bar chart represents the effect of case (matched minus mismatch) in the left anterior area of interest
The first ERP component to show different amplitudes is the N/P150, a positive potential (over anterior sites) reaching its maximum at around 150 ms poststimulus: The matched-case condition showed larger positive values than the mismatched-case condition (for both words and pseudowords). Case effects were also observed between 150 and 200 ms. Importantly, in the following time epochs, case effects vanished for the word stimuli, whereas they were sizeable for pseudowords (around 250 ms and also shown in the N400): The mismatched-case identity condition showed larger negative values than the matched-case identity condition. To capture the dissociation between words and pseudowords regarding the effect of case, we conducted an ANOVA that included the factors Time Epoch (80–150, 250–350, and 400–500 ms), Case (matched, mismatched), Lexicality (words, pseudowords), Hemisphere (left, right), and AP Distribution (anterior, posterior). This initial analysis revealed an interaction of time epoch, case, and lexicality: F(2, 36) = 3.87, p = .045. We then conducted separate ANOVAs for each time epoch. The results of the ANOVAs for each epoch (80–150, 250–350, and 400–500 ms) are shown below.
80- to 150-ms epoch
The ANOVA revealed a main effect of case [F(1, 18) = 4.6, p < .05] that was modulated by an interaction with AP distribution [F(1, 18) = 22.56, p < .001]: Larger positive values were observed for the mismatched- over the matched-case identity condition over frontal areas of the scalp [F(1, 18) = 13.40, p < .005; posterior areas: F < 1]. No differences were apparent between words and pseudowords (F < 1).Footnote 4
250- to 350-ms epoch
The ANOVA showed a main effect of lexicality [F(1, 18) = 17.1, p < .001]: Larger negativities were observed for pseudowords than for words. The interaction between lexicality and AP distribution [F(1, 18) = 10.29, p < .01] revealed that the lexicality effect was much larger over frontal (1.4 μV) [F(1, 18) = 20,14, p < .01] than over posterior (0.75 μV) [F(1, 18) = 9.4, p < .01] scalp areas. In addition, we found an interaction between case and lexicality [F(1, 18) = 14.96, p < .001]: Larger negativities were observed for the mismatched- than for the matched-case identity condition for pseudowords [F(1, 18) = 7.6, p < .02], but not for words (F < 1). Again, the interaction between case and AP distribution [F(1, 18) = 9.29, p < .01] revealed that the effect of case was located over frontal scalp areas [F(1, 18) = 4.01, p = .06; posterior: F < 1].
400- to 500-ms epoch
The ANOVA revealed larger negativities for pseudowords than for words [main effect of lexicality: F(1, 18) = 62.4, p < .001], as well as an interaction between lexicality and AP distribution [F(1, 18) = 17.90, p < .01]: In contrast to the previous epoch, the lexicality effect was larger over posterior (3.8 μV) [F(1, 18) = 77.97, p < .001] than over anterior (2.7 μV) [F(1, 18) = 39.16, p < .001] scalp areas. As in the previous time epoch, the interaction between case and lexicality was significant [F(1, 18) = 10.61, p < .005]: Larger negativities were observed for the mismatched- than for the matched-case condition for pseudowords [F(1, 18) = 13.14, p < .005], but not for words [F(1, 18) = 1.8, p = .19].
Discussion
In the present ERP experiment, we examined the temporal course of the effect of case (lowercase vs. uppercase) in a masked-priming paradigm with matched-case PRIME–TARGET identity pairs and mismatched-case prime–TARGET identity pairs. The behavioral data and the ERP data provided converging evidence for the dissociating role of lexicality in this effect: The matched-case identity condition showed an advantage over the mismatched-case identity condition for pseudoword targets (e.g., CURDE–CURDE faster than curde–CURDE), but not for word targets (e.g., similar RTs to ALTAR–ALTAR and altar–ALTAR; see also Jacobs et al., 1995; Perea et al., 2014). The ERP data revealed case-match effects at the earliest time epoch of analysis (N/P150: 80–150 ms). The N/P150 is driven by featural overlap across the prime and target, and it has been suggested to reflect processing at the level of size-invariant visual features (see Petit et al., 2006). At this very early processing stage, visual features are subject to a low-level analysis resulting in differences for upper- and lowercase versions of the same word or pseudoword (note that in the matched-case condition, the prime and target stimuli fully overlap in their physical features). Importantly, this takes places at a prelexical level of processing, and consistent with this interpretation, the lexicality of the letter string did not have an impact on the mapping of features onto case-specific letter representations. We would point out, however, that the effects were slightly larger for pseudowords than for words (see Fig. 4); thus, it is possible that even at this early stage of processing, there are some subtle modulations from higher-order lexical information, as has been previously reported by Hauk et al. (2006; see also Assadollahi & Pulvermüller, 2003; Dambacher, Kliegl, Hofmann, & Jacobs, 2006). The effect of case match lasted until approximately 200 ms, as revealed by a complementary analysis performed on a following time epoch [150–200 ms: F(1, 18) = 6.00, p < .05].

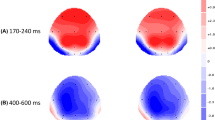
Topographic distributions of the case effect (calculated as the difference in voltage amplitudes between the event-related potential responses to matched- vs. mismatched-case identity priming) for words and pseudowords in the three time windows of the analysis
The effect of case match interacted with lexicality in the second time epoch (N250: 250–350 ms): Case-match effects were dramatically attenuated for words in this time window. For pseudowords, however, case-match effects were sizeable in this time epoch, as well as in the following time epoch. The lack of an N250 effect of case for word stimuli is in line with previous studies in which the manipulations on size and font across prime and target word stimuli did not have any impact on the N250 component (Chauncey et al., 2008). The idea is that by this time in processing, size and shape invariance have already been achieved. This could be taken as further evidence of access to orthographic representations that are insensitive to changes in physical parameters of letters, like font, size, or case (Cohen & Dehaene, 2004). Importantly, although this was true for words, it was not for pseudowords. Therefore, orthographic abstract retrieval is achieved in the context of the activation of lexical entries, as revealed by the lack of N250 effects for words. In pseudowords, visual dissimilarity between prime and target is not cancelled out as no common abstract lexical representation is tapped into. That is, the abstract orthographic coding of a pseudoword is not attained, as different electrophysiological and behavioral responses are obtained for the various allographic forms of the same letters.
As Fig. 4 shows, the dissociation between words and pseudowords regarding the effects of case starts around 200 ms and is present further on: Null N400 effects were observed for the match-case manipulation for word targets (but not for pseudoword targets), thus revealing that the mapping between whole-word and semantic representations is not sensitive to visual feature differences between prime and target (Grainger & Holcomb, 2009; see Kutas & Federmeier, 2011, for a review on the N400 component). We are treating the effects obtained in these two separate time windows (N250 [250–350 ms] and N400 [400–500 ms]) as pertaining to two different functional ERPs, as we take into account the different scalp distribution for each of them (N250 [anterior] vs. N400 [central–posterior]).Footnote 5
What are the implications of these data for models of visual-word recognition? The present results challenge the theoretical accounts that assume that there is automatic activation of abstract orthographic codes during the process of visual-word recognition in a purely feedforward manner. Most hierarchical (and, at a certain point, “encapsulated”) models of orthographic processing assume that letters are initially processed by detectors at a retinotopic level (i.e., the letter detector for “a” would be activated by the letter “a” but not by the letter “A), whereas later in processing, “invariant to visual-features” detectors respond to multiple versions of the same letter (at an abstract, orthographic level—i.e., the detectors for the abstract representation of “a” would react similarly upon the presentation of “a” or “A”; see Dehaene et al., 2005; see also Grainger et al., 2008, for a neural account of abstract letter identification). Likewise, some computational models of visual-word recognition have provided a purely feedforward account of sublexical orthographic processing (e.g., Bayesian reader model: Norris & Kinoshita, 2008).
However, the present ERP data suggest that abstract orthographic processing is modulated by lexical processing: When no lexical representations are available (as is the case for pseudowords), there are processing differences between matched- and mismatched-case identity pairs in the N250 and N400 components. This divergence occurs because there is no feedback from higher-level processes, because pseudowords do not have lexical representations. Therefore, the present pattern of ERP and behavioral data favors the view that fully interactive processes are involved in orthographic encoding during word reading at relatively early stages of processing (see Carreiras et al., 2014, for a recent review of neural accounts of visual-word recognition). The type of top-down feedback that we propose may be neurobiologically instantiated in terms of frontal–occipito-temporal connections. Consistent with our interpretation, Woodhead et al. (2012) found higher activation in the left inferior frontal gyrus for words (as compared to false fonts), together with feedback connections from the inferior frontal gyrus to the left ventral occipito-temporal cortex within the first 200 ms of stimulus processing (see also Thesen et al., 2012, for converging evidence). Likewise, Twomey, Kawabata Duncan, Price, and Devlin (2011) found that the activation of the left ventral occipito-temporal cortex, a brain structure involved in early stage processing during visual word recognition, was modulated differently by emphasizing phonological versus orthographical criteria in the lexical decision task. Further evidence along the same lines was provided by Cornelissen et al. (2009), who used magnetoencephalography (MEG) measures to show very early coactivation (within 200 ms) of speech motor areas and fusiform gyrus (orthographic word-form processing) during the presentation of words, consonant strings, and unfamiliar faces (see also Cai, Paulignan, Brysbaert, Ibarrola, & Nazir, 2010; Devlin, Jamison, Gonnerman, & Matthews, 2006; Kherif, Josse, & Price, 2011; Pammer et al., 2004).Footnote 6
The present data apparently are at odds with the evidence obtained with single letters as stimuli, which has shown N/P150 effects of feature-level processing, whereas more abstract relatedness effects are shown later in time (Carreiras et al., 2013; Petit et al., 2006). However, the differences may be more apparent than real. The retrieval of abstract orthographic representations (or abstract letter representations; Brunsdon, Coltheart, & Nickels, 2006; Jackson & Coltheart, 2001; Rothlein & Rapp, 2014) may originate in modality-specific (visual, phonological, or even motor) representations. Although the Petit et al. (2006) and the Carreiras et al. (2013) experiments controlled for the visual similarity between cross-case letter pairs (a–A, b–B, c–C . . .), the obtained priming effects could have originated at a phonological or motor level (letter-name or motor representations shared by cross-case pairs; see Rothlein & Rapp, 2014). As an illustration, in the Carreiras et al. (2013) cross-case same–different experiment, the stimuli “a” and “A” corresponded to “same” responses. Leaving aside that the cross-case same–different letter task has an inherent letter level of processing (i.e., a prelexical level of processing) rather than a lexical level of processing, this may have resulted in the preactivation of any other type of representation common to both allographs (not only orthographic, but phonological or motoric as well). What we should note here is that during normal reading—or when performing a lexical decision task—the activated codes should be lexical (rather than prelexical) in nature, and in this scenario, fine-grained decomposing processes may be overrun by whole-word processing.
In conclusion, we have demonstrated that different-case word forms (lower- and uppercase) tap into the same abstract representation, leading to prime–target integration very early in processing, as we deduced from similar ERP waves for the N250 and N400 components. Importantly, this process does not occur for pseudowords. This poses some problems for accounts that assume that an abstract orthographic code is automatically attained during word processing in the absence of lexical feedback, and favors fully interactive models of visual-word recognition. Further research should be devoted to exploring how these abstract representations are constructed (and retrieved) in the process of learning to read (see Polk et al., 2009).
Notes
Pseudowords are nonwords that respect the phonotactic restrictions of a given language.
One might argue that it would have been desirable to compare pairs such as edge–EDGE versus EDGE–EDGE (all letters visually different in lower- and uppercase) and kiss–KISS versus KISS–KISS (all the letters visually similar in lower- and uppercase). However, the number of these pairs for word stimuli was just too small to obtain stable ERP waves. At the behavioral level, Perea et al. (2014) found that cross-case feature similarity did not play a role in the dissociation effect of matched- versus mismatched-case identity priming for words and pseudowords (e.g., pseudowords: CIKY–CIKY < ciky–CIKY [cross-case visually similar stimuli] and EDEL–EDEL < edel–EDEL [cross-case visually dissimilar stimuli]; words: edge–EDGE = EDGE–EDGE and kiss–KISS = KISS–KISS).
As a reviewer pointed out, generalized linear mixed models can be more appropriate than ANOVAs to examine dependent variables that are binomial in origin (1 = correct response, 0 = error response). The results of this analysis backed up the small but significant effect of case in the error rates for word targets (β = .905, SE = .290, z = 3.12, p = .002).
A separate analysis was applied on the occipital electrodes to capture the negative counterpart of the N/P150 component, which revealed a main effect of case: Negative values were significantly larger for the matched- than for the mismatched-case identity condition, F(1, 18) = 12.99, p < .01.
To further examine whether the N250 component is functionally independent from the late N400, we performed a topographic analysis in which we contrasted the effect of case for targets in the 250- to 350-ms epoch with the effect of case for targets in the 400- to 500-ms epoch (N400). Two separate ANOVAs were conducted: A first analysis was applied on the raw ERP mean values, and a second analysis was applied on the normalized values using a z-score procedure (Handy, 2005; Holcomb, Kounios, Anderson, & West, 1999). The two analyses revealed interactions between anterior–posterior and epoch [raw ERP: F(1, 18) = 9.65, p < .01; normalized: F(1, 18) = 5.1, p < .05].
As two reviewers pointed out, one might argue that the case-change effect observed with pseudowords might be driven by a verification mechanism used mostly with pseudoword stimuli in lexical decision, which somehow could be more sensitive to case changes. That would save feedforward accounts of sublexical orthographic processing that hypothesize a shift from case-specific to case-invariant letter representations. This research question could be tested in a version of the masked-priming task in which words and pseudowords required the same answer (e.g., in a categorization task [“Is the stimulus an animal?”], altar–ALTAR vs. ALTAR–ALTAR and curde–CURDE vs. CURDE–CURDE both require a “no” decision).
References
Assadollahi, R., & Pulvermüller, F. (2003). Early influences of word length and frequency: A group study in the MEG. NeuroReport, 14, 1183–1187.
Bowers, J. S. (2000). In defense of abstractionist theories of repetition priming and word identification. Psychonomic Bulletin & Review, 7, 83–99.
Bowers, J. S., Vigliocco, G., & Haan, R. (1998). Orthographic, phonological, and articulatory contributions to masked letter and word priming. Journal of Experimental Psychology: Human Perception and Performance, 24, 1705–1719. doi:10.1037/0096-1523.24.6.1705
Brunsdon, R., Coltheart, M., & Nickels, L. (2006). Severe developmental letter-processing impairment: A treatment case study. Cognitive Neuropsychology, 23, 795–821.
Cai, Q., Paulignan, Y., Brysbaert, M., Ibarrola, D., & Nazir, T. A. (2010). The left ventral occipito-temporal response to words depends on language lateralization but not on visual familiarity. Cerebral Cortex, 20, 1153–1163.
Carreiras, M., Armstrong, B. C., Perea, M., & Frost, R. (2014). The what, when, where, and how of visual word recognition. Trends in Cognitive Sciences, 18, 90–98.
Carreiras, M., Perea, M., Gil-López, C., Abu Mallouh, R., & Salillas, E. (2013). Neural correlates of visual vs. abstract letter processing in Roman and Arabic scripts. Journal of Cognitive Neuroscience, 25, 1975–1985.
Chauncey, K., Holcomb, P. J., & Grainger, J. (2008). Effects of stimulus font and size on masked repetition priming: An event-related potentials (ERP) investigation. Language and Cognitive Processes, 23, 183–200. doi:10.1080/01690960701579839
Cohen, L., & Dehaene, S. (2004). Specialization within the ventral stream: The case for the visual word form area. NeuroImage, 22, 466–476.
Cornelissen, P. L., Kringelbach, M. L., Ellis, A. W., Whitney, C., Holliday, I. E., & Hansen, P. C. (2009). Activation of the left inferior frontal gyrus in the first 200 ms of reading: Evidence from magnetoencephalography (MEG). PLoS ONE, 4, e5359. doi:10.1371/journal.pone.0005359.g00
Dambacher, M., Kliegl, R., Hofmann, M., & Jacobs, A. M. (2006). Frequency and predictability effects on event-related potentials during reading. Brain Research, 1084, 89–103.
Davis, C. J., & Perea, M. (2005). BuscaPalabras: A program for deriving orthographic and phonological neighborhood statistics and other psycholinguistic indices in Spanish. Behavior Research Methods, 37, 665–671. doi:10.3758/BF03192738
Dehaene, S., Cohen, L., Sigman, M., & Vinckier, F. (2005). The neural code for written words: A proposal. Trends in Cognitive Sciences, 9, 335–341.
Dehaene, S., Jobert, A., Naccache, L., Ciuciu, P., Poline, J.-B., Le Bihan, D., & Cohen, L. (2004). Letter binding and invariant recognition of masked words: Behavioral and neuroimaging evidence. Psychological Science, 15, 307–313. doi:10.1111/j.0956-7976.2004.00674.x
Dehaene, S., Naccache, L., Cohen, L., Le Bihan, D., Mangin, J.-F., Poline, J.-B., & Rivière, D. (2001). Cerebral mechanisms of word masking and unconscious repetition priming. Nature Neuroscience, 4, 752–758. doi:10.1038/89551
Devlin, J., Jamison, H., Gonnerman, L., & Matthews, P. (2006). The role of the posterior fusiform gyrus in reading. Journal of Cognitive Neuroscience, 18, 911–922.
Duñabeitia, J. A., Molinaro, N., Laka, I., Estévez, A., & Carreiras, M. (2009). N250 effects for letter transpositions depend on lexicality: “Casual” or “causal”? NeuroReport, 20, 381–387.
Forster, K. I., & Davis, C. (1984). Repetition priming and frequency attenuation in lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 680–698. doi:10.1037/0278-7393.10.4.680
Grainger, J. (2008). Cracking the orthographic code: An introduction. Language and Cognitive Processes, 23, 1–35. doi:10.1080/01690960701578013
Grainger, J., & Holcomb, P. J. (2009). Watching the word go by: On the time-course of component processes in visual word recognition. Language and Linguistic Compass, 3, 128–156. doi:10.1111/j.1749-818X.2008.00121.x
Grainger, J., Rey, A., & Dufau, S. (2008). Letter perception: From pixels to pandemonium. Trends in Cognitive Sciences, 12, 381–387.
Handy, T. C. (2005). Event related potentials: A methods handbook. Cambridge, MA: MIT Press, Bradford Books.
Hauk, O., Patterson, K., Woollams, A., Watling, L., Pulvermuller, F., & Rogers, T. T. (2006). [Q:] When would you prefer a SOSSAGE to a SAUSAGE? [A:] At about 100 msec. ERP correlates of orthographic typicality and lexicality in written word recognition. Journal of Cognitive Neuroscience, 18, 818–832. doi:10.1162/jocn.2006.18.5.818
Holcomb, P. J., & Grainger, J. (2006). On the time course of visual word recognition: An event-related potential investigation using masked repetition priming. Journal of Cognitive Neuroscience, 18, 1631–1643. doi:10.1162/jocn.2006.18.10.1631
Holcomb, P. J., Kounios, J., Anderson, J. E., & West, W. C. (1999). Dual-coding, context-availability, and concreteness effects in sentence comprehension: An electrophysiological investigation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25, 721–742. doi:10.1037/0278-7393.25.3.721
Jackson, N. E., & Coltheart, M. (2001). Routes to reading success and failure: Towards and integrated cognitive psychology of atypical reading (1st ed.). New York, NY: Psychology Press.
Jacobs, A. M., Grainger, J., & Ferrand, L. (1995). The incremental priming technique: A method for determining within-condition priming effects. Perception & Psychophysics, 57, 1101–1110.
Keuleers, E., & Brysbaert, M. (2010). Wuggy: A multilingual pseudoword generator. Behavior Research Methods, 42, 627–633. doi:10.3758/BRM.42.3.627
Kherif, F., Josse, G., & Price, C. J. (2011). Automatic top-down processing explains common left occipito-temporal responses to visual words and objects. Cerebral Cortex, 21, 103–114.
Kiyonaga, K., Grainger, J., Midgley, K., & Holcomb, P. J. (2007). Masked cross-modal repetition priming: An event-related potential investigation. Language and Cognitive Processes, 22, 337–376. doi:10.1080/01690960600652471
Ktori, M., Grainger, J., Dufau, S., & Holcomb, P. J. (2012). The “electrophysiological sandwich”: A method for amplifying ERP priming effects. Psychophysiology, 49, 1114–1124.
Kutas, M., & Federmeier, K. D. (2011). Thirty years and counting: finding meaning in the N400 component of the event-related brain potential (ERP). Annual Review of Psychology, 62, 621–647. doi:10.1146/annurev.psych.093008.131123
Massol, S., Midgley, K. J., Holcomb, P. J., & Grainger, J. (2011). When less is more: Feedback, priming, and the pseudoword superiority effect. Brain Research, 1386, 153–164.
Morris, J., Franck, T., Grainger, J., & Holcomb, P. J. (2007). Semantic transparency and masked morphological priming: An ERP investigation. Psychophysiology, 44, 506–521.
Norris, D., & Kinoshita, S. (2008). Perception as evidence accumulation and Bayesian inference: Insights from masked priming. Journal of Experimental Psychology: General, 137, 434–455. doi:10.1037/a0012799
Oldfield, R. C. (1971). The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia, 9(1), 97–113. doi:10.1016/0028-3932(71)90067-4
Pammer, K., Hansen, P. C., Kringelbach, M. L., Holliday, I., Barnes, G., Hillebrand, A., & Cornelissen, P. L. (2004). Visual word recognition: The first half second. NeuroImage, 22, 1819–1825.
Perea, M., Jiménez, M., & Gómez, P. (2014). A challenging dissociation in masked identity priming with the lexical decision task. Acta Psychologica, 148, 130–135. doi:10.1016/j.actpsy.2014.01.014
Perea, M., Jiménez, M., & Gomez, P. (2015). Do young readers have fast access to abstract lexical representations? Evidence from masked priming. Journal of Experimental Child Psychology, 129, 140–147. doi:10.1016/j.jecp.2014.09.005
Petit, J. P., Midgley, K. J., Holcomb, P. J., & Grainger, J. (2006). On the time-course of letter perception: A masked priming ERP investigation. Psychonomic Bulletin & Review, 13, 674–681.
Polk, T. A., Lacey, H. P., Nelson, J. K., Demiralp, E., Newman, L. I., Krauss, D. A., & Farah, M. J. (2009). The development of abstract letter representations for reading: Evidence for the role of context. Cognitive Neuropsychology, 26, 70–90.
Pollatsek, A., & Well, A. D. (1995). On the use of counterbalanced designs in cognitive research: A suggestion for a better and more powerful analysis. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 785–794. doi:10.1037/0278-7393.21.3.785
Rothlein, D., & Rapp, B. (2014). The similarity structure of distributed neural responses reveals the multiple representations of letters. NeuroImage, 89, 331–344.
Thesen, T., McDonald, C. R., Carlson, C., Doyle, W., Cash, S., Sherfey, J., & Halgren, E. (2012). Sequential then interactive processing of letters and words in the left fusiform gyrus. Nature Communications, 3, 1284. doi:10.1038/ncomms2220
Thompson, G. B. (2009). The long learning route to abstract letter units. Cognitive Neuropsychology, 26, 50–69.
Twomey, T., Kawabata Duncan, K. J., Price, C. J., & Devlin, J. T. (2011). Top-down modulation of ventral occipito-temporal responses during visual word recognition. NeuroImage, 55, 1242–1251. doi:10.1016/j.neuroimage.2011.01.001
Vergara-Martínez, M., Perea, M., Gómez, P., & Swaab, T. Y. (2013). ERP correlates of letter identity and letter position are modulated by lexical frequency. Brain and Language, 125, 11–27. doi:10.1016/j.bandl.2012.12.009
Vergara-Martínez, M., & Swaab, T. Y. (2011). Orthographic neighborhood effects as a function of word frequency: An event‐related potential study. Psychophysiology, 49, 1277–1289. doi:10.1111/j.1469-8986.2012.01410.x
Woodhead, Z. V. J., Barnes, G. R., Penny, W., Moran, R., Teki, S., Price, C. J., & Leff, A. P. (2012). Reading front to back: MEG evidence for early feedback effects during word recognition. Cerebral Cortex, 24, 817–825. doi:10.1093/cercor/bhs365
Author note
The research reported in this article was partially supported by Grant No. PSI2011-26924 from the Spanish Ministry of Economy and Competitiveness. We thank three anonymous reviewers for very helpful comments on an earlier version of this article.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: list of target words/pseudowords
Word targets: DUCHA; FLUJO; ABRIL; RIGOR; LLAVE; QUESO; COSTE; SABIO; ALDEA; RASGO; MONTE; PAUSA; ANSIA; JUNIO; MARZO; SODIO; PRIMO; RUINA; MOSCA; NOBLE; CITAR; MUSEO; NOVIA; DIANA; COBRE; SABOR; JAULA; JUNTA; CABLE; GUIÓN; VERJA; DANZA; CICLO; DUEÑA; CHINO; FURIA; MOTOR; MOVER; PELEA; REINO; TURCO; PESCA; RUEDA; METER; PULSO; TROZO; SUBIR; FUMAR; VILLA; ROLLO; NIETO; OREJA; RIVAL; QUEJA; BUQUE; TORRE; PRESO; MEDIR; CALMA; ADIÓS; COÑAC; DRAMA; PALMA; NORMA; BRISA; NOTAR; CLIMA; FALLA; BULTO; BARBA; ENERO; AROMA; SOÑAR; DUQUE; VICIO; TALLA; ÁNGEL; CERCO; JUDÍO; TUMOR; DUDAR; ALTAR; ECHAR; FERIA; FALLO; CULTO; PARAR; ORINA; DEBER; TACTO; BAILE; METAL; ALGAS; OESTE; FALDA; PRIMA; HOGAR; ABUSO; SELVA; CEDER; VÍDEO; TOCAR; ACERA; LÁSER; PLOMO; FIJAR; SIGNO; BOTÓN; TIRAR; TEMER; DISCO; LECHO; BORDE; TRIBU; SUSTO; CAUCE; GIRAR; LANZA; CIRCO; ÁTOMO; ÚTERO; FIRMA; AVISO; RUMOR; FAVOR; VEJEZ; MÓVIL; CELDA; CABRA; COGER; DIETA; TABLA; VERSO; FRUTA; TOQUE; TÚNEL; CURAR; NOVIO; BAHÍA; ARROZ; GAFAS; ÓPERA; TRAER; HUIDA; TENIS; ÁCIDO; PLUMA; FLORA; OTOÑO; GENIO; VALLE; TURNO; ÁRABE; DEUDA; MIRAR; BOTÍN; VAPOR; VIUDA; GOZAR; BOLSO
Pseudoword targets: MABAR; GOVIO; MENCA; VEBOZ; GULLA; BIUTO; RENUS; SURBO; RUCEA; ANCEO; VIBAR; DRIRA; ZURÁO; MEBRE; DIBAL; PIEMA; HAUÓN; ÁRGIL; CAONE; COTIR; CECTO; MEMER; APIAL; LALCA; CEGLO; BULMO; SÚREL; PASGA; MOBRE; ADUCA; VENVA; CILAN; DABOR; ECARA; MUETA; VETER; GUCAR; DRINA; FATER; CHOJO; FUÑIO; LUDUI; MISCA; MUSTE; ÁDACO; ÚDENA; ECENA; TUTIR; GOVIA; RUCER; ÓCETO; MAUTO; CHOÍN; TOFAR; PUSMO; RULTO; ECOPO; ÁDOPA; PLARE; ODEPO; NÍCEA; LORÍN; CENMO; GAZIS; MÓFEL; GUQUI; FLURA; ERTAR; SEÑEO; VIZDA; TRIRO; ROTUI; AGETO; MABRA; DIRRA; CILMO; MUBAR; SIBOR; DARRE; MANVO; GOFAR; LUÑUI; SOSUA; MEROR; DETOR; FILGA; FLOSO; IONTE; MIDAR; LICHO; SILAR; LUSAR; RENRE; FANJA; TELTO; BATRA; FELLO; TELZA; RIESA; BONAR; PLUVO; JUSIA; ALCÓS; ZOJAR; SUSOR; ÁFIPE; COTIC; ABLEL; PLOLA; SESER; VIASA; BRIRO; VATOA; ZETAR; BABRA; VINIA; JUIRA; VANJA; SIDMO; LELÓN; TUANO; BOARE; NILAR; GLIDA; TUEBA; CLASA; HENIA; RITAL; DUNCO; MATRA; ALLAZ; ODOPA; ORRAR; BANJA; MOJOR; TAROR; FÁNER; ODIRO; FLUDA; DOCHO; CASNA; VIODA; REUCA; TELIO; JORTA; BREMO; TULGO; VINSO; RIOSO; GUEJA; RALRO; GAUDA; CHOJU; GORLA; CENOR; ZAPIO; CEZCA; ARBIA; TARRE; BOLCE
Appendix B: effects of repetition priming (identity vs. unrelated)
The critical issue in the present experiment was to compare the matched versus mismatched identity priming conditions for word and pseudoword targets. The data corresponding to this research question were analyzed and discussed in the main text of this article.
However, as we indicated in the introduction, in the present experiment we also included an unrelated priming condition, as is customary in masked repetition-priming experiments. For comparison purposes with previous research, we have included in this appendix the analyses on the masked repetition-priming effect (identity vs. unrelated priming conditions; see Perea et al., 2014, for a similar approach). Specifically, we compared, for word and pseudoword targets, the identity priming condition (mismatched case: words, monte–MONTE; pseudowords, lusar–LUSAR) and the unrelated priming condition (half of the unrelated primes in lowercase and half in uppercase: words, tabla [TABLA]–MONTE; pseudowords, pluvo [or PLUVO]–LUSAR). We employed the unrelated priming condition that corresponded to the same lexical category as that of the targets (i.e., word primes for word targets, and pseudoword primes for pseudoword targets).
Behavioral results
The mean lexical decision times and percentages of errors were submitted to separate ANOVAs with a 2 (Lexicality: word, pseudoword) × 2 (Repetition: identity, unrelated) design. List was included in the analyses as a dummy factor. The F ratios were conducted by subjects (F 1) and by items (F 2).
The ANOVA on the latency data revealed that words were responded to faster than pseudowords (620 vs. 705 ms, respectively), F 1(1, 18) = 127.39, p < .001; F 2(1, 312) = 330.22, p < .001. In addition, the target stimuli were responded to faster when they were preceded by a mismatched-case identity prime rather than by an unrelated prime (639 vs. 686 ms, respectively), F 1(1, 18) = 65.77, p < .001; F 2(1, 312) = 116.64, p < .001. The interaction between lexicality and repetition was significant, F 1(1, 18) = 54.90, p < .001; F 2(1, 312) = 52.72, p < .001. This interaction reflected that the repetition-priming effect was substantially larger for word targets (responses were, on average, 76 ms faster when preceded by a mismatched-case identity prime than when preceded by an unrelated prime: 582 vs. 658 ms, respectively), F 1(1, 18) = 98.28, p < .001; F 2(1, 156) = 193.78, p < .001, than for pseudoword targets (responses were, on average, 18 ms faster when preceded by a mismatched-case identity prime than when preceded by an unrelated prime: 696 vs. 714 ms, respectively), F 1(1, 18) = 8.04, p < .01; F 2(1, 156) = 5.41, p = .021.
The ANOVA on the error data failed to reveal any main effects of lexicality (both Fs < 1) or repetition, F 1(1, 18) = 3.54, p = .078; F 2(1, 312) = 1.96, p = .16, but we did find a significant interaction between the two factors, F 1(1, 18) = 5.64, p = .02; F 2(1, 312) = 14.83, p < .001. This interaction reflected that, for word targets, participants made more errors when the target was preceded by an unrelated prime than when it was preceded by a mismatched-case identity prime (5.6 % vs. 2.0 %, respectively), F 1(1, 18) = 14.2, p = .001; F 2(1, 156) = 14.26, p < .001. For pseudoword targets, the difference between the unrelated condition and the mismatched-case identity priming condition was not significant (3.3 % vs. 5.1 %, respectively), F 1(1, 18) = 1.35, p = .25; F 2(1, 156) = 2.90, p = .09.
ERP results
Figure 5 shows the ERP waves for words (repetition priming: monte–MONTE vs. unrelated: tabla [TABLA]–MONTE) and pseudowords (repetition priming, lusar–LUSAR, vs. unrelated, pluvo [PLUVO]–LUSAR). As can be seen in the figure, the ERP waves show a positive potential reaching its maximum at around 100 ms poststimulus (over posterior sites), whereas it reaches a maximum at around 200 ms over anterior sites. Following this peak, and for words only, the unrelated condition reaches larger negativities than does the repetition condition. Importantly, no differences are apparent for the pseudowords until approximately 500 ms. The present ERP analyses paralleled the analyses presented in the main text (matched- vs. mismatched-case identity priming; see the ERP Recording and Analysis section). In particular, the analyses were performed on the mean ERP values in three time windows (80–150, 250–350, and 400–500 ms). This was done for the four experimental conditions defined by the factorial combination of the factors Lexicality (words, pseudowords) and Repetition (repeated, unrelated). For each time window, a separate repeated measures ANOVA was performed, including the factors Hemisphere, AP Distribution, Lexicality, and Repetition. As in the behavioral analyses, List was included as a between-subjects factor in order to extract the variance due to the counterbalanced lists. Interactions between factors were followed up with simple-effect tests. The results of the ANOVAs for each epoch are shown below.

Grand average event-related potentials to words and pseudowords in the identity and unrelated conditions (see legend), in four representative electrodes from the four areas of interest. Electrodes O1 and O2 are presented at the bottom to show the mirror nature of the N/P150 in different areas. The bar chart represents the repetition-priming effect (identity minus unrelated) in the left anterior area of interest
80- to 150-ms epoch
The ANOVA did not show any significant effects of lexicality (F < 1) or repetition [F(1, 18) = 2.21, p = .15].
250- to 350-ms epoch
The ANOVA revealed main effects of lexicality [F(1, 18) = 11.09, p < .005] and repetition [F(1, 18) = 14.19, p < .002]. The interaction between lexicality and repetition was also significant [F(1, 18) = 17.52, p < .002]. This revealed a repetition-priming effect for words [F(1, 18) = 21.04, p < .001], but not for pseudowords (F < 1).
400- to 500-ms epoch
The ANOVA revealed main effects of lexicality [F(1, 18) = 64.28, p < .001] and repetition [F(1, 18) = 17.35, p < .002]. The interaction between lexicality, repetition, and AP distribution was significant [F(1, 18) = 8.27, p < .05]. This interaction revealed that the repetition effect (only for words) was larger over posterior areas [posterior: 3.5 μV, F(1, 18) = 58.05, p < .001; anterior: 1.5 μV, F(1, 18) = 9.64, p < .01]. In contrast, the pseudowords did not show any effect of repetition (F < 1).
In sum, the behavioral data replicated earlier findings: The magnitude of the repetition-priming effect was substantially larger for word than for pseudoword targets (76 vs. 18 ms, respectively; e.g., see Jacobs et al., 1995; Perea et al., 2014).
At the electrophysiological level, a substantial repetition-priming effect was observed for words; however, this did not hold for pseudowords in the three epochs under analysis. This is consistent with previous findings reporting ERP masked repetition effects for words but not for pseudowords in the P325 and N400 components (Kiyonaga et al, 2007; Ktori, Grainger, Dufau, & Holcomb, 2012). These results were interpreted in terms of interactions between whole-word and semantic representations. What we should note here is that although Kiyonaga et al. (2007) reported similar N250 effects for words and pseudowords (see note 1 in Kiyonaga et al., 2007), this effect was smaller for pseudowords than for words according to Fig. 6b in Grainger and Holcomb (2009).
Rights and permissions
About this article

Cite this article
Vergara-Martínez, M., Gómez, P., Jiménez, M. et al. Lexical enhancement during prime–target integration: ERP evidence from matched-case identity priming. Cogn Affect Behav Neurosci 15, 492–504 (2015). https://doi.org/10.3758/s13415-014-0330-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13415-014-0330-7