
Abstract
Missing ordinal data are common in studies using structural equation modeling (SEM). Although several methods for dealing with missing ordinal data have been available, these methods often have not been systematically evaluated in SEM. In this study, we used Monte Carlo simulation to evaluate and compare five existing methods, including one direct robust estimation method and four multiple imputation methods, to deal with missing ordinal data. On the basis of the simulation results, we provide practical guidance to researchers in terms of the best way to deal with missing ordinal data in SEM.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Ordinal data, such as those measured using Likert scales, are very common in the social and behavioral sciences. An ordinal variable contains a few response points, which are ordered, but the distances among the values are not meaningful. The past research on missing data has primarily focused on continuous missing data. Little guidance has been provided to researchers in terms of how to appropriately deal with missing ordinal data for their studies.
Such guidance is especially needed, given that multiple methods to deal with ordinal missing data have been made available, due to recent advances in missing data analysis and software developments (Enders, 2001b, 2010; Graham, 2009; Rubin, 1976, 1996; Schafer & Graham, 2002). Many of these methods have not been thoroughly studied and compared. Thus, it is not clear which method(s) should be adopted in a study that involves ordinal missing data. Of course, the appropriate method(s) may also vary depending on the kind of analysis adopted in the study. This article evaluates the performance of available methods for missing ordinal data, focusing on one of the most popular data analytical frameworks, structural equation modeling (SEM). These methods can be grouped into two categories: robust estimation methods and multiple imputation (MI) methods. Robust estimation methods deal with missing ordinal data without filling in the missing values. MI methods, on the other hand, replace missing ordinal data with multiple sets of plausible values.
It is important to point out that the performance of a missing data method is highly related to the mechanism through which data are missing. Rubin (1976) classified such processes into three missing data mechanisms: missing completely at random (MCAR), missing at random (MAR), and missing not at random (MNAR). MCAR refers to the case in which the probability of missing data for a variable is unrelated to the underlying values of the missing data or to any observed variables. MAR refers to the case in which the probability of missing data for a variable is related only to other observed variables. And MNAR refers to the case in which the probability of missing data for a variable is determined by the underlying values of the missing data themselves. Both MCAR and MAR are deemed ignorable, in the sense that the missing data generation process does not need to be explicitly modeled. We only consider methods developed for ignorable missingness in this study.
The rest of the article is organized as follows. We first describe the six methods that have been used or that theoretically can be used to deal with missing ordinal data in SEM. We then present a simulation study conducted to evaluate the performance of five of these methods under a variety of conditions for fitting a typical structural equation model. We conclude the article by discussing the results and limitations of the simulation study and providing recommendations on the use of these methods in practice.
Robust estimation methods for missing ordinal data
Robust full information maximum likelihood (RFIML)
RFIML treats missing ordinal data as if they were continuous. To understand how RFIML works, we start with the maximum-likelihood estimation method (ML) for continuous complete data. ML assumes that the data are continuous and multivariate normally distributed. Under certain assumptions, such as normality, independent observations, large sample size, and a correctly specified model (Bollen, 1989; Finney & DiStefano, 2006; Savalei & Falk, 2014), the parameter estimates produced by ML have desirable asymptotic properties, such as unbiasedness (i.e., they are close enough to the true population values), consistency (they converge to the true values as the sample size goes large), and efficiency (the sampling distribution of the estimates has minimum variance). If any of the assumptions are violated, these properties might not hold. In reality, the assumption of normality is always violated when data are not continuous. According to Bollen, when the observed indicators in SEM models are ordinal, there are at least two important consequences if the ordinal data are treated as normal: (1) the linear measurement model does not hold for ordinal indicators, and (2) the fundamental hypothesis of SEM does not hold—in other words, the population covariance matrix is not equal to the model-implied covariance matrix.
The effect of discontinuity on the performance of ML is dependent on at least two factors: (1) the distribution of categorical variables and (2) the number of categories. Researchers generally believe that when ordinal data are not severely skewed or kurtotic and have at least five categories, treating them as continuous does not result in severe bias in the parameter estimates, standard errors, or fit indices (Finney & DiStefano, 2006). In other situations, with a small number of categories or/and higher levels of skewness and kurtosis, bias in the parameter estimates and standard errors could be more pronounced, and the fit indices could be misleading (Dolan, 1994; Green, Akey, Fleming, Hershberger, & Marquis, 1997; Muthén & Kaplan, 1985).
One solution to these problems is to use ML accompanied with robust correction for nonnormality. Satorra and Bentler (1994) developed a correction method by rescaling the standard errors and the test statistic from ML. This method is well-known as Satorra–Bentler scaling or robust ML (RML). However, RML is only applicable when the data are complete. When data are incomplete but normally distributed, SEM estimates can be obtained by iteratively maximizing the sum of N case-wise log-likelihood functions (Enders, 2001b). This method is referred to as full information maximum likelihood (FIML), which is one of the popular missing data techniques. To deal with missing nonnormal data with FIML, Yuan and Bentler (2000) developed three correction methods, of which the “direct” method is the most commonly used, known as robust FIML (RFIML). For continuous data, past research has shown that RFIML generally performed well under MCAR and MAR, except for one situation in which MAR missingness occurred mainly in the heavy tail of the distribution and the proportion of missing data was large (30%; Enders, 2001a; Savalei & Falk, 2014). Although RFIML was developed for missing continuous data, it has been widely used to deal with missing ordinal data in practice. However, research on the performance of RFIML for ordinal incomplete data is lacking.
Diagonally weighted least squares estimation methods (cat-DWLS)
Another solution is to use an estimation method developed specifically for ordinal data. For example, weighted least squares (WLS) estimators are often used for ordinal data. WLS estimators account for ordinal data by fitting a SEM model to the polychoric correlation matrix. There are different versions of WLS estimators for ordinal data. Among these, cat-DWLS is the most popular. Briefly speaking, cat-DWLS uses the diagonal elements of the asymptotic polychoric correlation matrix as a correction factor for the covariance matrix of parameters in calculating the standard errors. Since cat-DWLS uses summary statistics in the estimation process, it cannot deal with missing data by itself, but needs to be combined with a missing data technique (Asparouhov & Muthén, 2010).
A common missing data technique used along with cat-DWLS is pairwise deletion. Specifically, pairwise deletion is used to calculate the polychoric correlations, which are then used in the cat-DWLS fit function. Asparouhov and Muthén (2010), however, showed that pairwise deletion could produce biased parameter estimates and unacceptable confidence interval coverage rates when the data were not MCAR. In addition, once the polychoric correlations are calculated on the basis of pairwise deletion, cat-DWLS treats them as if they were from complete data when estimating the model parameters. Thus, the uncertainty due to missing data is not taken into account, leading to inflated Type I error rates. Given the obvious disadvantages of pairwise deletion, we do not examine it in the present study. In comparison, multiple imputation (MI) is a better strategy to use when combined with cat-DWLS (Asparouhov & Muthén, 2010).
MI methods for missing ordinal data
MI is a widely used modern missing data technique designed for ignorable missingness (Rubin, 1987; Schafer & Graham, 2002). A standard MI procedure involves three phases: (1) the imputation phase—generate multiple sets of complete data with missing values filled in using a specific imputation model; (2) the analysis phase—fit the hypothesized model to each of the imputed data sets; and (3) the pooling phase—pool the results (e.g., the parameter estimates, standard errors, and fit indices) across the imputed data sets to produce a final set of results. We refer to the model used to impute/predict missing data as an imputation model. An imputation model can be either parametric or nonparametric. In this article, we consider MI with three parametric imputation models and one nonparametric imputation model. Depending on which imputation model is used, there are different MI methods. The parametric imputation methods include imputing the data based on multivariate normal distributions (MI-MVN), ordinal logistic regression models (MI-LOGIT), or latent variable models (MI-LV). The nonparametric imputation method is MI using random forests (MI-RF). These methods are described in detail below.
MI-MVN
MI-MVN treats ordinal data as if they were continuous and generates imputed data sets based on a multivariate normal distribution. Although MI-MVN is not designed for ordinal missing data, it has been used in practice to deal with ordinal missing data, because of its wide availability. The imputed values from this method are continuous. For ordinal missing data, past research has recommended keeping the fractional part of the continuous imputed values rather than rounding them, unless a follow-up analysis requires use of a categorical metric for the imputed values (Enders, 2010; Graham, 2009; Honaker, King, & Blackwell, 2011; Schafer & Graham, 2002). Wu, Jia, and Enders (2015) found that MI-MVN generally performed well when imputing Likert-type ordinal missing values that were then aggregated to scale scores for regression analysis, unless the sample size was small and the distributions of the ordinal variables were severely asymmetrical. Limited research has examined the performance of MI-MVN in the context of SEM with missing ordinal data.
MI-LV
The imputation model used in MI-MVN is not designed specifically for ordinal data. Given this reality, it is natural to think, why not use a statistical model designed for ordinal data instead? One popular model for predicting ordinal data is the so-called latent variable model, which is basically a formulation of the cumulative/ordinal probit model (Cowles, 1996). The latent variable model assumes that a continuous latent variable underlies each observed ordinal variable (Asparouhov & Muthén, 2010). The latent variables are typically assumed to follow a multivariate normal distribution. When this model is used for imputation, the missing values are first imputed at the continuous latent-variable level and then discretized on the basis of estimated thresholds.
MI-LV has received increasing attention in recent years. Asparouhov and Muthén (2010) compared using the MI-LV method followed by cat-DWLS with using direct cat-DWLS along with pairwise deletion for estimating a growth model of five binary variables observed at five time points. They found that MI-LV outperformed direct cat-DWLS by providing more accurate parameter estimates and higher confidence interval coverage under MAR. Wu et al. (2015) also found that MI-LV performed well in a context in which the ordinal variables were to be aggregated to scale scores for regression analysis, regardless of the missing data proportions, sample sizes, numbers of categories of the ordinal data, and the degree of unbalance of the categories. However, the performance of MI-LV has not been systematically examined in SEM.
MI-LOGIT
Another popular model for predicting ordinal data is ordinal logistic regression. This imputation model is used with the chained equations algorithm (van Buuren, Brand, Groothuis-Oudshoorn, & Rubin, 2006; van Buuren & Groothuis-Oudshoorn, 2011). Unlike MI-MVN or MI-LV, the chained equations algorithm does not impute on the basis of a joint distribution. Rather, it imputes missing data on a variable-by-variable basis. Prediction of the missing data for each variable is conditional on the current values of the other variables at a specific iteration. The imputation model for each missing data variable can be specified individually. Van Buuren et al. (2006) found that MI-LOGIT was superior to listwise deletion when estimating odds ratios. Van Buuren (2007) also recommended using MI-LOGIT rather than MI-MVN for ordinal logistic regression analysis. Wu et al. (2015), however, found that MI-LOGIT led to substantial bias in estimating reliability coefficients, mean scale scores, and regression coefficients for predicting one scale score from another when the items that formed the scale were ordinal, especially with small sample sizes, unbalanced categories, and more than five categories. Thus, an imputation model designed specifically for ordinal data might not necessarily have satisfying empirical performance in predicting missing ordinal data.
MI-RF
All of the imputation models introduced above are parametric. Random forests (RF), on the other hand, is a nonparametric method that can be used to predict both continuous and categorical data, including ordinal data using the chained equations algorithm. Briefly speaking, RF is a recursive partitioning method that predicts a variable with missing values by successively splitting the data set based on one predictor at a time, so that the subsets become more homogeneous with each split (Breiman, 2001). One advantage of RF is that it does not rely on distributional assumptions, and thus has the potential to accommodate nonnormality and nonlinear relationships among the variables that cannot be easily parameterized (Doove, van Buuren, & Dusseldorp, 2014; Shah, Bartlett, Carpenter, Nicholas, & Hemingway, 2014). When used for MI, the data are bootstrapped first. Each bootstrapped sample is then split into several subsets. The values in each subset are called “donors.” Missing data are then imputed by random draws from the donors. Doove et al. (2014) compared MI-RF with MI-LOGIT for recovering interaction effects in logistic regression analyses. They found that MI-RF produced more accurate estimates of the interaction effects and was more efficient (yielded smaller standard errors) than MI-LOGIT. However, MI-RF and MI-LOGIT have not been compared in the context of SEM.
In sum, in this study we considered five methods that have the potential to be used for missing ordinal data in SEM. These methods include RFIML and different forms of MI based on the multivariate normal distribution (MI-MVN), based on the latent variable model (MI-LV), using ordinal logistic regression (MI-LOGIT), and using random forests (MI-RF). Among these methods, RFIML and MI-MVN treat missing ordinal data as if they were continuous. All of the methods are parametric, except for MI-RF. A brief summary of the characteristics of the five methods can be found in Table 1.
Simulation study
In this section, we use Monte Carlo simulation to evaluate the performance of the five methods. We attempt to address the following three questions.
Question 1: Are the continuous-data methods RFIML and MI-MVN applicable to ordinal data? Under what situations and to what extent are the two methods robust to discontinuity?
Question 2: How is the performance of each of the methods influenced by number of categories, asymmetry of thresholds, sample size, missing data proportion, and missing data mechanism?
Question 3: Which of the five methods performs best under the examined conditions?
Data generation model
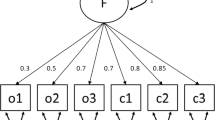
Following Ferrari and Barbiero (2012), we generated continuous data first and then discretized the continuous data into ordinal data. The continuous data were generated on the basis of the SEM used in Enders (2001a; see Fig. 1), which represents a model that is often seen in the SEM literature (e.g., Bollen, 1989; Palomo, Dunson, & Bollen, 2011). The model has three latent variables: η1, η2, and η3, where η3 was predicted by η1 and η2, and η2 was predicted by η1. As is shown in Fig. 1, the values of the structural paths among the three variables were .4 (η1➔η2), .286 (η2➔η3), and .286 (η1➔η3), respectively. The variance of η1 was fixed at 1 for identification purposes. The residual variances of η2 and η3 were set to .840 and .771, respectively, so that their total variances would both equal 1. Each latent variable was indicated by three continuous variables/items with all loadings set to .70. The residual variances on the indicators were all set to .51 so that the indicators would form a standardized metric. These continuous indicators were then discretized on the basis of thresholds in order to create ordinal indicators. For ordinal indicators with G categories, there were G minus 1 thresholds. To examine how the methods performed under different conditions, we manipulated the following factors.

The structural equation model for data generation
Design factors
Number of categories
Both dichotomous and polytomous ordinal data were considered in the study. The numbers of ordinal categories were set at two, three, and five.
Asymmetry of thresholds
In practice, the distributions of ordinal indicators can be either symmetric or asymmetric. Following Rhemtulla, Brosseau-Liard, and Savalei (2012), we varied the asymmetry of the thresholds at three levels (symmetry, moderate asymmetry, and severe asymmetry) in order to introduce different levels of asymmetry in the item distributions (see Table 2). For the sake of simplicity, all variables shared the same set of thresholds and number of categories in each condition.
Sample size
Two levels of sample size (N) were examined: 300 and 600,Footnote 1 which represent typical sample sizes in studies that have used SEM.
Missing data proportion
Missing data proportions (mp) were manipulated at two levels: low (15%) and high (30%).
Missing data mechanism
Missing data were imposed on two of the indicators for each latent variable. Specifically, missing values occurred for X1, X2, X4, X5, X7, and X8. The missing data were generated using three mechanisms: MCAR, MAR-head, and MAR-tail. MCAR data were generated by randomly selecting a desired proportion of values to be missing for the variables. When the ordinal indicators were asymmetric, we considered two versions of MAR: missingness occurring more frequently on the head of the distribution (MAR-head) or on the tail of the distribution (MAR-tail). To generate the MAR data, the rank order of the values on each of the fully observed variables (i.e., X3, X6, and X9) was used to determine the probability of having a missing observation on the other two indicators for the same latent variable. For example, the missingness for X1 and X2 was determined by X3. MAR-head data were generated on the basis of ascending rank order. Using X1 as an example, the probability of having missing data for X1 was computed as 1 - (the ascending order of the values on X3/N). Because all variables were positively correlated, the probability of having missing observations for X1 increased as X3 increased. In addition, because all of the indicators were positively skewed, MAR-head led to more missing data on the head of the X1 distribution.
In contrast, MAR-tail data were generated in such a way so that the probability of having missing data for X1 decreased as X3 increased. Consequently, more data were missing on the tail of the X1 distribution; the distribution of the observed data became more skewed; and the density of the higher levels in the ordinal variable (e.g., four or five in a five-category variable) drastically decreased. In more extreme cases, some of the categories (e.g., five) might have zero observations. Therefore, we believe that MAR-tail was a more challenging situation than MAR-head, and it was necessary to differentiate the two situations. Figure 2 demonstrates the distribution of one three-category indicator from one replication with different degrees of asymmetry and missing data mechanisms.

Distributions of X1 (three categories) from one replication with N = 300, both before (light gray) and after (dark gray) imposing 30% missing data
In sum, there were 108 fully crossed conditions (3 × 3 × 2 × 2 × 3 = 108). One thousand replicated samples were created for each condition. The analysis model was the same as the data generation model. For the imputation methods, 50 imputed data sets were obtained for each replication. Following the guideline of White, Royston, and Wood (2011), 50 imputations should be sufficient for the amount of missing data simulated.
Computational characteristics
This simulation study was carried out using various packages in R 3.2 (R Core Team, 2015) and Mplus 7.2 (Muthén & Muthén, 2012). Data were generated using functions provided in the R package GenOrd (Ferrari & Barbiero, 2012). RFIML was implemented in lavaan (Rosseel, 2012). MI-MVN was implemented using Amelia (Honaker et al., 2011). MI-LOGIT and MI-RF were implemented through functions in the package mice (van Buuren & Groothuis-Oudshoorn, 2011), with ten burn-in iterations (van Buuren et al., 2006; White et al., 2011). For MI-RF, ten bootstrap samples were generated from each original sample, based on the suggestion of Shah, Bartlett, Carpenter, Nicholas, and Hemingway (2014), and the default minimum number of donors (i.e., 1) was used to create classification trees (Liaw & Wiener, 2002). MI-LV was implemented in Mplus.
We used cat-DWLS to analyze the imputed data sets from all of the imputation methods, given that past research on complete ordinal data had shown that this technique generally outperformed RML (Li, 2016). The only exception was MI-MVN, for which RML was used in the follow-up analysis, because MI-MVN produced continuous imputed data, and cat-DWLS could not be applied. For the imputation methods, a replication was determined to be converged if the model converged for all 50 imputed datasets.
Evaluation criteria
The performance of the five methods was evaluated for four outcomes: proportion of convergence failures, relative bias in the parameter estimates (Est bias), relative bias in the standard errors (SE bias), and confidence interval coverage rate (CIC).
Proportion of convergence failures
We defined convergence failures as replications that failed to converge to proper solutions. These included replications that failed to produce any solutions and replications that produced improper solutions (i.e., extreme parameter or standard error estimates). Improper solutions included (1) standard error estimates greater than 10, (2) parameter estimates ten SDs above or below the mean parameter estimate for the design cell, and (3) standard error estimates ten SDs above or below the mean standard error for the design cell. The convergence failures were removed before computing the other three outcomes. We calculated the proportion of the convergence failures in each condition.
Relative bias in parameter estimates (Est bias)
The relative bias for a specific parameter estimate was calculated as the percentage of raw bias relative to the true population value:
where the numerator represents the raw bias, which is the difference between the average parameter estimate across replications within a design cell (\( \overline{\widehat{\theta}} \)) and the population value (θ0). According to Hoogland and Boomsma (1998), an Est bias less than 5% is considered acceptable. However, Muthén, Kaplan, and Hollis (1987) argued that “a bias of less than 10%–15% may not be serious in most SEM contexts.” We used 10% as the cutoff in the present study.
Relative bias in standard error estimates (SE bias)
Bias in standard error estimates is the degree to which a standard error accurately reflects the sampling standard deviation of the corresponding parameter estimate, which can be calculated using the following formula:
\( \mathrm{SE}\;\mathrm{Bias}=\frac{\overline{\mathrm{SE}}- ESE}{ESE}\times 100\%, \)
where \( \overline{\mathrm{SE}} \) is the average standard error across replications in a design cell, and ESE is the empirical standard error (i.e., the standard deviation of the parameter estimates across converged replications). An SE bias is considered acceptable if its absolute value is less than 10% (Hoogland & Boomsma, 1998).
Confidence interval coverage (CIC)
Confidence interval coverage was estimated as the percentage of replications in a design cell for which the 95% confidence intervals covered the population value. Ideally, the CIC values should be equal to 95%. Following Collins, Schafer, and Kam (2001), a coverage value below 90% was considered problematic.
Results
Convergence failures
Symmetrical thresholds
The convergence failures were low (below 15%) for all methods, regardless of N, mp, and missing data mechanism.
Moderately asymmetrical thresholds
Some of the methods show significant convergence problems when the item distributions were moderately asymmetrical, particularly for dichotomous data and MAR-tail conditions. Figure 3 displays the proportions of convergence failures in conditions with moderately asymmetrical thresholds. All methods converged well under MCAR or MAR-head, except that MI-LOGIT failed in more than 60% of replications for five-category data with N = 300 and mp = 30%. More convergence failures occurred under MAR-tail. Specifically, for dichotomous data, all methods had convergence failures to some degree, with MI-RF and MI-MVN being the most problematic (more than 98% failures) when N = 300 and mp = 30%. The convergence rates improved in general as N increased to 600. However, with N = 600, MI-RF still had substantial convergence problems when mp = 30%. For polytomous data, all methods converged well, except that MI-RF produced substantial convergence failures for both three-catgory data and five-category data when N = 300 and mp = 30%. Overall, MI-LV seemed the best performer, followed by RFIML, and MI-RF was the worst performer, followed by MI-MVN and MI-LOGIT in terms of convergence.

Proportions of convergence failures with moderately asymmetrical distributions. RFIML = robust full-information maximum liklihood; MI-MVN = multiple imputation based on multivariate normal distributions; MI-LV = latent variable imputation; MI-LOGIT = multiple imputation using logistic regression or ordinal logistic regression; MI-RF = multiple imputation using random forests
Severely asymmetrical thresholds
Convergence failures occurred more frequently for almost all methods when the item distributions were severely asymmetrical (see Fig. 4). Again, the convergence problem was more severe if N was small and mp was large. Also, MAR-tail continued to be the most challenging situation. Both RFIML and MI-LV seemed to have the least convergence problems under MCAR or MAR-head. Other methods also converged well under MCAR or MAR-head, except that they encountered substantial convergence problems for dichotomous data. Under MAR-tail, all methods had substantial convergence failures with dichotomous data, but MI-LV started to outperform the other methods quickly as sample size increased. For polytomous data, only MI-LV worked well for all conditions, except that it had substantial convergence problems (91% failures) for three-category data when N = 300 and mp = 30%. The other methods all had substantial convergence failures under either N = 300, mp = 30%, or both. Overall, in terms of convergence, MI-LV appeared to be the best performer, followed by RFIML, and MI-RF was the worst performer, followed by MI-MVN.

Proportions of convergence failures with severely asymmetrical distributions. RFIML = robust full-information maximum liklihood; MI-MVN = multiple imputation based on multivariate normal distributions; MI-LV = latent variable imputation; MI-LOGIT = multiple imputation using logistic regression or ordinal logistic regression; MI-RF = multiple imputation using random forests
Note that if the proportion of convergence failures was higher than 75% for a method in a condition (Figs. 3 and 4), the method was considered failed for that condition, and the other three outcomes (i.e., Est bias, SE bias, and CIC) are not reported.
Est biases, SE biases, and CICs for factor loadings
We report Est biases, SE biases, and CICs for factor loadings first, followed by those for structural path coefficients. For ease of presentation, we report the averaged results across all factor loadings or all structural paths. The results for the conditions with 15% missing data followed patterns very similar to those for the conditions with 30% missing data. Thus, we report only the results for 30% missing data. (The results for 15% missing data can be requested from the authors.) In addition, the results were similar between symmetric thresholds and moderately asymmetrical thresholds. Thus, the results for the two threshold conditions are described together below.
Symmetric or moderately asymmetrical thresholds
For factor loadings, the results for Est bias, SE bias, and CIC under the two threshold conditions are summarized in Tables 3 and 4. The results show the same pattern across the two tables for all methods. Under MCAR, all methods performed well except for MI-RF, which produced unacceptable bias (> 10%) in both the parameter estimates and standard error estimates. Under MAR-head or MAR-tail, all methods performed well except for MI-RF and MI-LOGIT. Although MI-RF and MI-LOGIT produced acceptable parameter estimates, the standard error estimates from both methods were substantially biased, especially when the ordinal data had more than two categories. MI-LOGIT tended to produce too narrow CIs, whereas the CIs from MI-RF were too wide. Note that although MI-MVN and MI-LV performed well in general, there was one condition (moderately asymmetrical thresholds with N = 300, dichotomous indicators, and 30% MAR-tail missing data) under which MI-MVN failed to converge and MI-LV yielded unacceptable SE bias (15.2%; see Table 4).
Severely asymmetrical thresholds
The results for factor loadings under severely asymmetrical thresholds are summarized in Table 5. Under MCAR, MI-LOGIT produced acceptable results under all conditions. RFIML, MI-MVN, and MI-LV also performed well, except for the dichotomous data with N = 300. MI-RF yielded problematic replications for dichotomous data and N = 300, and also failed all other conditions by producing biased results in terms of all three outcomes.
Under MAR-head, all methods performed well except for MI-RF. Under MAR-tail, however, all methods failed for dichotomous data, by either having convergence problems or resulting in biased results. For ordinal data with three categories, only MI-LV performed well, and only with a relatively large sample size of N = 600. For ordinal data with five categories, only MI-LV and RFIML performed well with both sample sizes. MI-MVN show acceptable performance only with N = 600.
Est biases, SE biases, and CICs for path coefficients
Symmetric or moderately asymmetrical thresholds
The results for the path coefficients under symmetric thresholds and moderately asymmetrical thresholds are presented in Tables 6 and 7, respectively. Under MCAR, all methods performed well in general except for MI-RF, which produced substantial biases in the parameter or standard error estimates, as well as too-wide CIs. There was also one condition (N = 300 with dichotomous indicators) in which MI-LV produced slightly above 10% biases in the path coefficient estimates.
Under MAR-head and MAR-tail, RFIML was the best performer when the thresholds were not severely asymmetric. MI-MVN performed well in general, but it had convergence problems for dichotomous data with N = 300. MI-LV also had difficulties with this condition. It produced substantial biases in parameter estimates or standard error estimates, especially when the thresholds were moderately asymmetric. MI-RF and MI-LOGIT led to substantially biased parameter estimates or standard error estimates for many of the conditions, with MI-RF being more problematic. Again, MI-LOGIT produced too-narrow CIs, whereas MI-RF produced too-wide CIs.
Severely asymmetrical thresholds
The results for path coefficients with severely asymmetrical thresholds are presented in Table 8. Under MCAR, only RFIML performed well for all outcomes. MI-MVN produced acceptable results for all conditions, except that it had convergence problems with N = 300 and dichotomous indicators. MI-LV and MI-LOGIT was acceptable only when the ordinal data had five categories. MI-RF produced substantial SE biases, or both Est biases and SE biases for all conditions.
Under MAR-head, the only method that worked under all conditions was RFIML. MI-MVN produced acceptable results for all outcomes for only polytomous indicators. MI-LV and MI-LOGIT produced substantial bias in the path coefficient estimates for all conditions except for conditions with five-category indicators. MI-RF produced unbiased parameter estimates across all conditions but overestimated the standard errors, leading to wide CIs.
Under MAR-tail, all methods failed for dichotomous data, regardless of sample size. For three-category data, no methods worked well with N = 300, and only RFIML produced acceptable results with N = 600. For ordinal data with five categories, RFIML, MI-MVN, and MI-LV were acceptable. MI-LOGIT failed to produce accurate standard errors and CIs under any conditions for polytomous data. MI-RF also encountered severe convergence problems for polytomous data.
Conclusion and discussion
In this article, we evaluated five available methods to deal with missing ordinal data in SEM across a broad range of conditions, using Monte Carlo simulation. In this section, we summarize the major findings for each of the research questions raised above.
-
Question 1: Are the continuous-data methods RFIML and MI-MVN applicable to ordinal data? Under what situations and to what extent are the two methods robust to discontinuity?
The results show that the continuous-data methods RFIML and MI-MVN in general worked quite well for ordinal data in estimating factor loadings and structural path coefficients. In fact, in most conditions they outperformed the methods designed specifically for ordinal data, except for MI-LV, probably because of their simplicity. RFIML was reliable under various conditions examined in this study, except that it failed to converge for dichotomous data when the distributions were severely asymmetrical and were likely truncated by missing data (i.e., MAR-tail). MI-MVN also had convergence problems when the ordinal data had ≤ 3 categories and when the distributions were asymmetrical.
As compared to RFIML, MI-MVN required a larger sample size or a smaller proportion of missing data in some of the most difficult situations to converge to admissible solutions. This is probably due to the fact that RFIML is a one-step approach that handles missing data directly in the estimation process, whereas MI-MVN separates the missing data handling and model estimation processes. Thus, RFIML is more efficient than MI-MVN. In addition, although RFIML does not account for the ordinal nature of the data, it accounts for the nonnormality due to ordinal data. In comparison, MI-MVN only partially account for nonnormality (in the analysis stage, by using RML, but not in the imputation stage).
-
Question 2: How is the performance of each of the methods influenced by number of categories, asymmetry of thresholds, sample size, missing data proportion, and missing data mechanism?
RFIML was least impacted by the examined design factors. However, it may fail to converge or may generate large biases under the most difficult conditions (i.e., the distributions were severely asymmetrical, the missing data were MAR-tail, and the number of categories was two or three). RFIML could also produce substantial biases in the loading estimates for dichotomous data, if the distributions were severely asymmetrical. Otherwise, the performance of RFIML was stable and reliable in general.
The other methods were influenced by all design factors to some degree. MI-MVN and MI-LV generally performed well, except that they could fail when the distributions were asymmetrical, the missing data were MAR-tail, and the number of categories was small (i.e., two or three). MI-MVN was more sensitive to asymmetrical distributions and MAR-tail than was MI-LV, given that MI-MVN treated missing data as continuous and did not account for nonnormality when imputing the missing data.
As compared to the other methods, MI-LOGIT was impacted by the factors in different ways. In general, it worked adequately under MCAR or for dichotomous data, except for data with severely asymmetrical distributions. The performance of MI-RF was not satisfactory across all conditions for the outcomes considered in the study. One possible explanation for this poor performance of MI-RF is that, as a nonparametric method, MI-RF probably required a larger sample size (e.g., N = 1,000 in Doove et al., 2014) than those examined in the study. Specifically, MI-RF predicts missing data from donors that share similar properties with the incomplete cases. With a small sample size, it could have been difficult for MI-RF to find donors that were sufficiently homogeneous to those incomplete cases, resulting in either convergence problems or biased estimates. Future research will be warranted to study the conditions under which MI-RF may deliver satisfactory performance.
In terms of the general impact of a single factor, we found that the missing data mechanism was most influential on the performance of the examined methods. In other words, the methods performed quite differently under MAR-tail than under MCAR or MAR-head. In our study, MAR-tail was created in such a way that the values on the right tail of the distribution were most likely to be truncated. Thus, when the distribution was right-skewed, the least frequently observed values became sparser or completely missing, creating a challenging situation for the missing data techniques we examined.
-
Question 3: Which of the five methods performs best under the examined conditions?
For dichotomous data, RFIML appeared to be the best method among the five. For indicators with three categories, RFIML was also the best performer, closely followed by MI-MVN and MI-LV. RFIML was slightly better than MI-MVN by being easier to converge and slightly more robust to asymmetrical distributions and to MAR-tail. MI-LV combined with cat-DWLS also worked well for three-category data, except that it could result in substantially biased estimates for structural path coefficients when the item distributions were severely asymmetrical. For indicators with five categories, both RFIML and MI-LV combined with cat-DWLS seemed the best methods. They converged properly and produced accurate loading and structural path estimates under all conditions. MI-MVN also had comparable performance, except that it might produce biased loading estimates in the most challenging situation (small sample size, MAR-tail, and a distribution that was severely asymmetrical). The other two methods, MI-LOGIT and MI-RF, could produce biased results or fail to converge to a proper solution for various types of data examined in this study, with MI-RF being the worst.
Limitations and future directions
The findings and conclusions from this article are limited to the scope of the study. Several of these limitations are worth mentioning. First, we only examined one type of SEM model and focused on factor loadings and three latent paths. More studies will be needed to examine the performance of these methods for other types of parameters and other types of SEMs, such as growth curve models and mixture models.
Second, when generating the data, we assumed that missing data occurred on two indicators of all three latent variables. In such a model, with three latent variables playing different roles, it would be interesting to examine to what extent the location of the missing data might have affected the performance of the five methods. To shed some light on the impact of this factor, we conducted a small-scale simulation study based on a representative set of conditions (i.e., the distributions were moderately asymmetrical, the number of categories was three, and the missing data proportion was 30%). The same data generation and analysis model was used, but missing data occurred on two indicators of only one latent variable at a time. The results showed that only MI-RF was sensitive to the location of the missing data. Specifically, when the missing data only occurred among the indictors for η1, MI-RF yielded extremely large positive biases in the path coefficient estimates. The biases decreased when the missing data occurred only among the indictors for η2. When the missing data occurred only among the indictors for η3, MI-RF yielded negative but acceptable Est biases for the structural path coefficients. Given that the other methods did not seem to be affected by the location of the missing data, varying the location of missing data would not alter our conclusions. More research, however, should be conducted to examine the reason why MI-RF performed differently with different missing data locations.
Third, the examined methods were implemented on the basis of the commonly used settings of the software packages. For the methods that had frequent convergence problems, modifying the settings may improve convergence. For example, one might try different optimization techniques, if they are available, or a larger number of iterations. For MI-RF, in particular, one might try different numbers of bootstrapped samples or different minimum numbers of donors. One might also use a less conservative rule (e.g., 50% imputations converged) to determine convergence for the imputation methods. Future research could be conducted to examine the existing strategies or to develop new strategies to improve the convergence of the missing data methods.
Fourth, we only considered the situation in which all the indicators were ordinal and had the same thresholds. In practice, continuous and ordinal missing data may coexist, and the thresholds or number of categories might also vary across ordinal items. It would be interesting to investigate whether the same conclusions would hold when different types of incomplete variables needed to be analyzed simultaneously.
Finally, we focused on the accuracy and precision of parameter estimates when evaluating the performance of the methods. In SEM, researchers often care about model fit information such as the chi-square test statistic and practical fit indices. Thus, it would be interesting to examine which method(s) lead to accurate statistical inference in terms of model fit (e.g., the chi-squared test statistic). We did record the Type I error rates of the chi-squared test statistic associated with RFIML (the detailed results can be requested from the authors). We found that the Type I error rates from RFIML were in general close to 5%, except they were inflated substantially (above 10%) with severely asymmetrical thresholds, especially when the ordinal data had only two or three categories. Again, these findings are limited to the conditions manipulated in the simulation. For example, the Type I error rates might be inflated when the threshold values, missing data mechanisms, or missing data proportions are substantially different across items (Savalei & Falk, 2014). It is important to note that valid model fit test statistics cannot be obtained from the multiple imputation methods investigated in this study, because there is no good way so far to pool the rescaled test statistics across imputations for cat-DWLS or RML (Enders & Mansolf, 2018). For this reason, we did not report fit indices in the Results section. Developing an appropriate method to pool the rescaled test statistics over imputations for RML or cat-DWLS would be a fruitful avenue for future research.
To conclude, among the five methods examined in the present study, RFIML performed the best for the outcomes considered in the study, and was most stable for a wide range of conditions. Aside from RFIML, MI-MVN and MI-LV also performed well most of the time, unless the conditions were extremely difficult (e.g., small number of categories, small sample size, severely asymmetrical distributions, and a large proportion of data missing on the tail of the distribution). Thus, MI-MVN and MI-LV can serve as good alternatives to RFIML, especially when MI is chosen to deal with missing data or RFIML fails to converge. Interested researchers might also try more than one method to see whether the different methods converge to similar results. Although MI-LOGIT and MI-RF are theoretically appealing, their empirical performance was not satisfying for the model and conditions examined in the present study. Thus researchers should be cautious about using them to deal with missing ordinal data in SEM.
Notes
Originally, we also considered a smaller sample size of 150. However, severe convergence problems were found for this sample size, and no estimates could be obtained in most conditions with the examined levels of missing data proportion and asymmetry of the distribution. Therefore, we do not report this sample size in the present article.
References
Asparouhov, T., & Muthén, B. (2010). Multiple imputation with Mplus (Technical report). www.statmodel.com.
Bollen, K. A. (1989). Structural equations with latent variables. New York, NY: Wiley.
Breiman, L. (2001). Random forests. Machine Learning, 45, 5–32.
Collins, L. M., Schafer, J. L., & Kam, C. M. (2001). A comparison of inclusive and restrictive strategies in modern missing data procedures. Psychological Methods, 6, 330–351.
Cowles, M. K. (1996). Accelerating Monte Carlo Markov chain convergence for cumulative-link generalized linear models. Statistics and Computing, 6, 101–111. https://doi.org/10.1007/BF00162520
Dolan, C. V. (1994). Factor analysis of variables with 2, 3, 5, and 7 response categories: A comparison of categorical variable estimators using simulated data. British Journal of Mathematical and Statistical Psychology, 47, 309–326.
Doove, L., van Buuren, S., & Dusseldorp, E. (2014). Recursive partitioning for missing data imputation in the presence of interaction effects. Computational Statistics and Data Analysis, 72, 92–104.
Enders, C. K. (2001a). The impact of nonnormality on full information maximum-likelihood estimation for structural equation models with missing data. Psychological Methods, 6, 352–370. https://doi.org/10.1037/1082-989X.6.4.352
Enders, C. K. (2001b). A primer on maximum likelihood algorithms available for use with missing data. Structural Equation Modeling, 8, 128–141.
Enders, C. K. (2010). Applied missing data analysis. New York, NY: Guilford Press.
Enders, C. K., & Mansolf, M. (2018). Assessing the fit of structural equation models with multiply imputed data. Psychological Methods, 23, 76–93. https://doi.org/10.1037/met0000102
Ferrari, P. A., & Barbiero, A. (2012). Simulating ordinal data. Multivariate Behavioral Research, 47, 566–589.
Finney, S. J., & DiStefano, C. (2006). Non-normal and categorical data in structural equation modeling. In G. R. Hancock & R. O. Mueller (Eds.), Structural equation modeling: A second course (pp. 269–314). Greenwich, CT: Information Age.
Graham, J. W. (2009). Missing data analysis: Making it work in the real world. Annual Review of Psychology, 60, 549–576.
Green, S. B., Akey, T. M., Fleming, K. K., Hershberger, S. L., & Marquis, J. G. (1997). Effect of the number of scale points on chi-square fit indices in confirmatory factor analysis. Structural Equation Modeling, 4, 108–120.
Honaker, J., King, G., & Blackwell, M. (2011). Amelia II: A program for missing data. Journal of Statistical Software, 45, 1–47.
Hoogland, J. J., & Boomsma, A. (1998). Robustness studies in covariance structure modeling An overview and a meta-analysis. Sociological Methods and Research, 26, 329–367.
Li, C.-H. (2016). The performance of ML, DWLS, and ULS estimation with robust corrections in structural equation models with ordinal variables. Psychological Methods, 21, 369–387. https://doi.org/10.1037/met0000093
Liaw, A., & Wiener, M. (2002). Classification and regression by randomForest. R News, 2, 18–22.
Muthén, B., & Kaplan, D. (1985). A comparison of some methodologies for the factor analysis of non-normal Likert variables. British Journal of Mathematical and Statistical Psychology, 38, 171–189.
Muthén, B., Kaplan, D., & Hollis, M. (1987). On structural equation modeling with data that are not missing completely at random. Psychometrika, 52, 431–462.
Muthén, L. K., & Muthén, B. (2012). Mplus user’s guide (Version 7). Los Angeles, CA: Muthén & Muthén.
Palomo, J., Dunson, D. B., & Bollen, K. (2011). Bayesian structural equation modeling. In S.-Y. Lee (Ed.), Handbook of latent variable and related models (pp. 163–188). Amsterdam, The Netherlands: Elsevier.
R Core Team. (2015). R: A language and environment for statistical computing. R Foundation Statistical Computing, Vienna, Austria. Retrieved from www.R-project.org
Rhemtulla, M., Brosseau-Liard, P. E., & Savalei, V. (2012). When can categorical variables be treated as continuous? A comparison of robust continuous and categorical SEM estimation methods under suboptimal conditions. Psychological Methods, 17, 354–373.
Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48, 1–36. https://doi.org/10.18637/jss.v048.i02
Rubin, D. B. (1976). Inference and missing data. Biometrika, 63, 581–592.
Rubin, D. B. (1987). Multiple imputation for nonresponse in surveys. New York, NY: Wiley.
Rubin, D. B. (1996). Multiple imputation after 18+ years. Journal of the American Statistical Association, 473–489. https://doi.org/10.1080/01621459.1996.10476908
Satorra, A., & Bentler, P. M. (1994). Corrections to test statistics and standard errors in covariance structure analysis. In A. von Eye & C. C. Clogg (Eds.), Latent variable analysis: Applications for developmental research (pp. 399–419). Thousand Oaks, CA: Sage.
Savalei, V., & Falk, C. F. (2014). Robust two-stage approach outperforms robust full information maximum likelihood with incomplete nonnormal data. Structural Equation Modeling, 21, 280–302. https://doi.org/10.1080/10705511.2014.882692
Schafer, J. L., & Graham, J. W. (2002). Missing data: Our view of the state of the art. Psychological Methods, 7, 147–177.
Shah, A. D., Bartlett, J. W., Carpenter, J., Nicholas, O., & Hemingway, H. (2014). Comparison of random forest and parametric imputation models for imputing missing data using MICE: A CALIBER study. American Journal of Epidemiology, 179, 764–774. https://doi.org/10.1093/aje/kwt312
van Buuren, S. (2007). Multiple imputation of discrete and continuous data by fully conditional specification. Statistical Methods in Medical Research, 16, 219–242.
van Buuren, S. (2012). Flexible imputation of missing data. Boca Raton: Chapman and Hall/CRC Press.
van Buuren, S., Brand, J. P. L., Groothuis-Oudshoorn, C., & Rubin, D. B. (2006). Fully conditional specification in multivariate imputation. Journal of Statistical Computation and Simulation, 76, 1049–1064.
van Buuren, S., & Groothuis-Oudshoorn, K. (2011). MICE: Multivariate imputation by chained equations in R. Journal of Statistical Software, 45, 1–67.
White, I. R., Royston, P., & Wood, A. M. (2011). Multiple imputation using chained equations: Issues and guidance for practice. Statistics in Medicine, 30, 377–399.
Wu, W., Jia, F., & Enders, C. (2015). A comparison of imputation strategies for ordinal missing data on Likert scale variables. Multivariate Behavioral Research, 50, 484–503. https://doi.org/10.1080/00273171.2015.1022644
Yuan, K.-H., & Bentler, P. M. (2000). Three likelihood-based methods for mean and covariance structure analysis with nonnormal missing data. Sociological Methodology, 30, 165–200.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Jia, F., Wu, W. Evaluating methods for handling missing ordinal data in structural equation modeling. Behav Res 51, 2337–2355 (2019). https://doi.org/10.3758/s13428-018-1187-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-018-1187-4