
Abstract
People usually become faster at finding a visual target after repeated exposure to the same search display. This effect, known as contextual cueing, is often thought to rely on a highly efficient learning mechanism, relatively unconstrained by the availability of attentional resources. Consistent with this view, experimental evidence suggests that contextual cueing can be found even when participants are instructed to ignore the repeated visual context, although this learning remains latent until the context receives full attention. The present study explores the contribution of selective attention to contextual cueing in four high-powered preregistered experiments. None of them supported the hypothesis that latent learning can occur without selective attention. In general, our results suggest that selective attention to visual context plays an essential role in both the acquisition and the expression of contextual cueing.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Visual attention is not solely driven by the physical properties of the stimuli we are exposed to, but also by our current goals and by previous experience (Chun & Turk-Browne, 2007; Theeuwes, 2018). An experimental paradigm known as contextual cueing provides an excellent example of the deep interconnections between learning, memory, and attention (Chun & Jiang, 1998). In a typical experiment, participants are asked to find a rotated T among several L-shaped distractors and report its orientation using two response keys. Some of the search displays are presented several times over the experiment, which usually leads to participants becoming comparatively faster at finding the target in repeated than in completely random search displays.
Of central importance for the present article, contextual cueing is often seen as a highly efficient type of learning that demands few attentional resources (Pollmann, 2019) and can take place even when the stimuli that cue the location of the target have been actively ignored by participants (Jiang & Leung, 2005). These findings dovetail with previous research on other implicit learning paradigms, such as the serial response time task, where participants seem to acquire information about a regular sequence of events, even when they are distracted by a demanding secondary task or instructed to ignore the target stimuli (e.g., Cock, Berry, & Buchner, 2002; Jiménez & Méndez, 1999). In contrast, other studies have found that learning in the serial reaction time task and other implicit learning paradigms depends heavily on the availability of attentional resources (e.g., Fernandes, Kolinsky, & Ventura, 2010; Rowland & Shanks, 2006; Tanaka, Kiyokawa, Yamada, Dienes, & Shigemasu, 2008; Toro, Sinnett, & Soto-Faraco, 2005; Turk-Browne, Jungé, & Scholl, 2005).
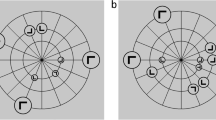
In the seminal experiments exploring the role of selective attention in contextual cueing, Jiang and Chun (2001) instructed participants to search for target stimuli in a particular color (e.g., red), while the distractors could appear in either of two colors (e.g., red or green). This created effectively two sets of distractors: An attended set, consisting of all the distractors presented in the same color as the target, and an ignored set, with the distractors presented in the alternative color. This procedure allowed Jiang and Chun to investigate the effects of presenting repeatedly either the attended set or the ignored set on contextual cueing. For some search displays, both the attended and the ignored sets repeated over the experiment (“both-old” condition); for other search displays, only the attended set repeated over the training trials, while the ignored set was composed of stimuli in random locations (“attended-old” condition); in another condition, only the ignored set repeated across training trials, while the stimuli in the attended set appeared in random locations (“ignored-old” condition); finally, in a fourth condition, all distractors, regardless of color, were presented in random locations (“both-new” condition or control). The first two columns of Fig. 1 show a black-and-white example of the search displays used in each of these conditions. The results showed a robust contextual cueing for conditions where the attended set of the search display was repeated. In contrast, contextual cueing for ignored distractors tended to be small and nonsignificant in most experiments.

Examples of search displays across conditions and blocks. Participants were instructed to find a white T and report its orientation. This particular example was taken from Experiments 2–3
A follow-up experiment by Jiang and Leung (2005) suggested that this impairment in contextual cueing might be due not to a genuine failure to learn about ignored distractors but to a failure to express learning. The experiment conducted by Jiang and Leung largely replicated the procedure and design of Jiang and Chun (2001), except that at the end of the experiment participants completed a transfer stage where the color of all distractors was reversed, so that items presented in the previously ignored color would now be attended to and vice versa (see Fig. 1). This reversal completely altered the pattern of results: Participants were now faster at finding the target in the ignored-old condition than in the both-new condition. These results led the authors to conclude that people can actually learn about “ignored” stimuli, although this learning remains latent until those stimuli are selectively attended.
To the best of our knowledge, only Goujon, Didierjean, and Marmèche (2009) have reported a somewhat similar effect in a visual-search paradigm. Instead of using the standard L-shaped and T-shaped stimuli as distractors and targets, Goujon et al. asked participants to find a target word among a number of distractor words, whose semantic category sometimes predicted the location of the target. In their Experiment 4, Goujon et al. found evidence of latent learning for semantic categories that participants had been instructed to ignore. Given the relevance of this finding, it is surprising that only two studies have explored latent learning of ignored context so far. Furthermore, in light of the (typically) small samples sizes of these two studies (N = 20 and 36, for Jiang & Leung, 2005, and Goujon et al., 2009, respectively), it is not impossible that previous findings on latent learning from ignored context may be entirely spurious. The goal of the present series of experiments is to reevaluate the role of selective attention in contextual cueing in a standard task, following preregistered protocols and using large samples.
Overview of Experiments 1–4
The four experiments described in the present article tried to replicate the results of Jiang and Leung (2005). The experimental procedures were similar, though not identical, to those of the original study. For instance, each condition in Experiments 1–2 comprised only four search displays, instead of the eight included in Jiang and Leung. This was done to reduce the length of the experiment for participants. However, given that both experiments failed to find significant evidence of latent learning, in Experiments 3–4 we duplicated the number of search displays per condition. Similarly, in Experiments 1 and 4, distractors and targets were presented in red and green. This mirrored the procedure of Jiang and Chun (2001), but departed from Jiang and Leung, who presented stimuli in black and white. To discard the possibility that this feature of the design made a difference in the results, in Experiments 2–3 we used black and white stimuli.
The results of Experiment 1 revealed that reaction times (RTs) were, overall, slower than in the original study by Jiang and Leung (2005), suggesting that our task may have been slightly more difficult for participants, possibly because of the use of distractors that were too similar to the target. To facilitate the detection of the target, in Experiments 2–3 we removed the small offset in the horizontal axis of the distractors that rendered them so similar to the target in Experiment 1. The screenshots in Fig. 1 show stimuli as they were presented in Experiments 2–3. RTs became more consistent with the data reported by Jiang and Leung (2005), but we still failed to find evidence of latent learning. Upon completion of Experiments 1–3, it was evident that, if anything, the results of Experiment 1 were the closest to the original study. Therefore, in Experiment 4 we replicated the procedure of Experiment 1, but duplicating the number of search displays per condition from four to eight, and recruiting a much larger sample. In the following sections, we provide detailed information about the design and procedure of each study. All four experiments followed a preregistered protocol (available at https://osf.io/g5w4n/).
Method
Participants and Apparatus
In Experiments 1–3 we followed Simonsohn’s (2015) recommendation to test at least 2.5 times as many participants as the original study we intended to replicate (where N = 20). Therefore, we planned to test 50 participants in each experiment. Given our failure to find learning of ignored visual context in Experiments 1–3, in Experiment 4 we planned to test an even larger number of participants, namely, 120. In practice, due to the lack of precise control of recruitment in our subject pool, we tested more participants in each experiment, but we also had to remove some of them from the analyses because (a) they were unable to complete the experimental task because of computer errors or (b) they failed to meet the selection criteria. The final valid sample sizes of Experiments 1–4 were 49, 55, 47, and 106, respectively. All participants were psychology students at Universidad Autónoma de Madrid (UAM). They completed the experimental task in small groups in a laboratory equipped with 12 individual cubicles and were rewarded with course credit for their contribution. All participants provided informed consent, and the studies were approved by the UAM ethics committee (ref. CEI-80-1473).
Stimuli
On each trial, participants were shown a search display with 16 L-shaped distractors and one T-shaped target presented against a gray background. In Experiments 1 and 4, all search displays contained eight red distractors (two per quadrant) and eight green distractors (two per quadrant). In all cases, distractors were L-shaped stimuli, which could be rotated 0°, 90°, 180° and 270°. In Experiments 1 and 4, the vertical line of the distractors was slightly offset to make them more similar to the target and, consequently, increase task difficulty. The T-shaped target was always rotated 90° or 270°, and it was presented in the same color across trials (red or green, randomly chosen for each participant). The stimuli used in Experiments 2–3 were identical to those of Experiments 1 and 4, except that distractors and targets were presented in black and white (instead of red and green), and that there was no offset in the vertical line of distractors, which rendered the task somewhat easier than in Experiments 1 and 4. Distractors and targets were positioned in a 12 × 12 grid, invisible to participants. At the beginning of the experiment, 16 locations (four per quadrant) of the grid, roughly equidistant from the center of the screen, were preselected to contain the targets. Distractors could never appear in these locations. (Note that this procedure departs slightly from the original study by Jiang & Leung, 2005, who preselected target locations with different eccentricities and then balanced eccentricities across conditions.)
Procedure and Design
Participants were instructed to search for the target as fast as possible and press key “z” if the stem of the T pointed to the left and “m” if the stem of the T pointed to the right. Instructions encouraged them to be as fast as possible, but without making errors. Before starting the experiment, participants were told that the target would always be presented in one color (red or green, in Experiments 1 and 4, and black or white, in Experiments 2–3) and that, to improve their performance, they should ignore all the stimuli presented in the other color.
Experiments 1–2 began with a learning stage consisting of 24 blocks of trials, each of them comprising 16 trials. Each block contained four search displays for each of the four experimental conditions: both old, attended old, ignored old, and both new. Figure 1 provides an example of the displays used in each condition. The four search displays in the both-old condition were presented repeatedly over the experiment, once per block. In the attended-old condition, only the distractors presented in the same color as the target were presented in the same location, orientation and color across blocks. Distractors presented in the ignored color were presented in random locations across blocks. In contrast, in the ignored-old condition, only the distractors presented in the ignored color were presented in the same location, orientation and color across blocks, while distractors in the attended color were presented in random locations across blocks. Finally, in the both-new condition, all the distractors, regardless of color, were presented in random locations. In all cases, search displays were constrained so that each quadrant contained exactly two distractors in the attended color and two distractors in the ignored color. The left/right orientation of the target was determined randomly in each trial, so that participants could not learn a direct association between search displays and responses.
Immediately after the learning stage and without any interruption, participants completed two transfer blocks, each comprising 32 trials. On each block, participants were presented with the same 16 search displays used during the learning stage, in addition to 16 new search displays created by reversing the colors of the distractors.
The design and procedure of Experiments 3–4 were identical to those of Experiments 1–2, except that eight (instead of four) search displays are used in each condition. Consequently, each block of trials in the learning stage comprised 32 trials: eight in the both-old condition, eight in the attended-old condition, eight in the ignored-old condition, and eight in the both-new condition. In the same vein, each block of trials in the transfer stage comprised 64 trials: The same 32 search displays used during the learning stage, in addition to 32 new search displays created by reversing the colors of the distractors. This change also implied that at the beginning of the experiment, 32 locations (eight per quadrant) of the grid, roughly equidistant from the center of the screen, were preselected to contain the targets. Otherwise, the task was identical to the one used in Experiments 1–2.
In all the experiments, each trial began with a 1-s fixation cross presented at the center of the screen, followed by the search display, which remained visible until participants responded pressing either “z” or “m” in the computer keyboard. After an incorrect response, the message “Wrong!” appeared on the screen for two seconds. Trials were separated by a 1-s blank screen. Participants were given the opportunity to make a 20-s pause after every 100 trials.
Results
Except where noted otherwise, all the analyses and data preprocessing steps presented in this section followed the preregistered protocol. Data from 1, 4, 7, and 5 participants in Experiments 1–4, respectively, could not be included in the analyses because the experimental program malfunctioned before completing the experiment. An additional 2, 4, 1, and 9 participants were removed because their overall accuracy was below 95%. Final sample sizes were 49, 55, 47, and 106 for Experiments 1–4, respectively. Trials with incorrect responses, trials immediately following a rest break and trials with RTs greater than 10 s were removed from the analysis. We also removed trials three or more standard deviations faster or slower than each participant’s mean. To further reduce noise in the data, we collapsed data from adjacent blocks in two-block epochs.
Figure 2 shows mean RTs from the learning and transfer stages. RTs from the learning stage were analyzed with 2 (attended context: repeated vs. new) × 2 (ignored context: repeated vs. new) × 12 (epoch) repeated-measures analyses of variance (ANOVAs). The results of these analyses are presented in Table 1. The main effect of Attended Context was significant in all experiments, showing that, overall, participants were faster in conditions in which the attended context was repeated (both old and attended old) than in conditions in which the attended context was random (ignored old and both new). The Attended Context × Epoch interaction was significant in all cases but in Experiment 2, suggesting that the search advantage for displays where attended stimuli were repeated became stronger over epochs. These results are in perfect agreement with those of Jiang and Leung (2005).

Reaction times during learning and transfer. Each panel presents reaction times across epochs and conditions for each experiment. Green lines denote conditions where the attended distractors were repeated during the learning stage
Contrastingly, there is little evidence that the repetition of ignored distractors facilitated visual search. The main effect of Ignored Context was marginally significant only in Experiment 3, suggesting that, in general, repeating the stimuli that participants were supposed to ignore made little difference in RTs. In other words, RTs were similar for the both-old and attended-old conditions and for the ignored-old and both-new conditions. Similarly, the Ignored Context × Epoch interaction was significant in Experiment 1, and the Ignored Context × Attended Context was significant in Experiment 4. The reader can find a (nonregistered) analysis collating all data from Experiments 1–4 in the Supplementary Material (see Table S1 and Fig. S1). The combined analysis confirmed the significant interaction between Ignored and Attended Context found in Experiment 4 and suggested that this effect was due to a small search advantage in the both-old condition over the attended-old condition. These results are at odds with those of Jiang and Leung (2005), but dovetail with the results of Jiang and Chun (2001), who found that ignored context may also produce contextual cueing.
RTs from the transfer stage were analyzed with 2 (attended context: repeated vs. new) × 2 (ignored context: repeated vs. new) × 2 (switch: color stay vs. color switch) ANOVAs. The critical prediction is that when there is a color switch, RTs will be facilitated in the ignored-old compared with the control (both-new) condition, as latent learning about the ignored distractors becomes revealed by the color switch. This difference is predicted to be larger than the corresponding difference when color is not switched, where learning remains latent. Therefore, a successful demonstration of this effect would require either a significant Ignored Context × Switch interaction or a triple interaction. The results, summarized in Table 2, show that these interactions were nonsignificant in all cases. The critical interactions also failed to reach statistical significance in a (nonregistered) analysis collating data from all experiments (see Table S2, in the Supplementary Material).
One of the key predictions for these experiments is that, once the colors of the distractors reverse and the predictive distractors of the ignored-old condition receive full attention, they will immediately boost search performance over the control both-new condition. The t tests for color switch trials presented in Table 3 yield no support for this prediction. Although these analyses were not preregistered, Table 3 also reports the meta-analytic average effects across experiments, which were nonsignificant both for color stay and color switch trials. Similarly, one-sided Bayes factors for each individual contrast and for the meta-analytic aggregate (Rouder & Morey, 2011) provide substantial (>3) or strong (>10) support for the null hypothesis, except for color stay trials in Experiment 3, which provides anecdotal (>1/3) support for the alternative hypothesis. Table S5 in the Supplementary Material provides the results of the same analysis for the both-old and attended-old conditions, although these analyses were not preregistered. Overall, the analyses of the transfer stage do not reveal any evidence of latent learning of ignored visual context.
Previous research (Jiang & Chun, 2001, Experiment 4) suggests that distractor–target similarity might be a crucial factor determining the relative amount of attention allocated to relevant and irrelevant stimuli. Under conditions of low distractor–target similarity, the task may become sufficiently easy to allow participants to allocate some attention even to irrelevant stimuli. Given that distractor-target similarity was high in Experiments 1 and 4 but low in Experiments 2–3, we could test for the potential effects of this factor in a cross-experimental (nonregistered) analysis. The results, reported in the Supplementary Material (Tables S3 and S4, and Fig. S2), did not reveal any significant interaction between distractor–target similarity and learning for ignored or attended context in either stage.
General Discussion
Overall, our results suggest that selective attention is crucial both for the acquisition and the expression of contextual cueing. While repeated exposure to attended distractors made a large difference in search times during the learning stage, the repetition of ignored distractors elicited only a small and inconsistent search advantage, possibly due to the simple fact that our instructions did not prevent participants from paying some attention to stimuli presented in the irrelevant color. In this sense, the results of the learning stage are in perfect agreement with those of Jiang and Chun (2001) and Jiang and Leung (2005).
Crucially, swapping the colors of the attended and unattended sets did not uncover any evidence of latent learning for previously ignored items. When colors were switched during the transfer stage, so that previously ignored stimuli became fully attended, repeated stimuli in the ignored-old condition did not facilitate visual search over control trials. This null result holds even if one collates the original finding of Jiang and Leung (2005) with the present experiments in a meta-analysis (see Table 3). As mentioned in the introduction, Goujon et al. (2009, Experiment 4) conducted a conceptual replication of this finding in a somewhat different experimental paradigm (semantic cueing). Including this study in the general meta-analysis does not change the main conclusion either.
In fact, Fig. 2 suggests that swapping the colors of distractors abolished contextual cueing in all conditions, even those which had supported a robust visual search advantage during the learning stage. A nonregistered analysis of search times in color switch trials (reported in Table S5 of the Supplementary Materials) revealed no evidence of cueing in the both-old and attended-old conditions, with the only exception of a weak but significant cueing effect in the both-old condition in Experiment 1. These results suggest that, far from uncovering latent learning, reversing the color of distractors actually disrupts the expression of contextual cueing.
In general, our results suggest that previous studies might have underestimated the importance of selective attention in contextual cueing or, alternatively, that the necessary conditions to observe latent learning of ignored visual context are yet poorly understood. This notwithstanding, the idea that contextual cueing is relatively unconstrained by attentional resources has received additional support from an independent set of studies where learning seems to be unaffected by a cognitively demanding secondary task (Pollmann, 2019). Taken collectively, the evidence available so far suggests that contextual cueing may take place under conditions of limited attention, but it is less than clear that stimuli that have been completely ignored can support this type of learning.
Open Practices Statement
The data and materials for all experiments are available (https://osf.io/ew2vp/). All the experiments were preregistered (https://osf.io/g5w4n).
Author Notes
M.A.V. and T.G.F. were supported by Grant 2016-T1/SOC-1395 from Comunidad de Madrid (Programa de Atracción de Talento Investigador). M.A.V. was also supported by grant PSI2017–85159-P from Agencia Estatal de Investigación and Fondo Europeo de Desarrollo Regional. Correspondence concerning this article should be addressed to Miguel A. Vadillo, Departamento de Psicología Básica, Facultad de Psicología, Universidad Autónoma de Madrid, 28049 Madrid, Spain. E-mail: miguel.vadillo@uam.es
References
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36, 28–71.
Chun, M. M., & Turk-Browne, N. B. (2007). Interactions between attention and memory. Current Opinion in Neurobiology, 17, 177–184.
Cock, J. J., Berry, D. C., & Buchner, A. (2002). Negative priming and sequence learning. European Journal of Cognitive Psychology, 14, 27–48.
Fernandes, T., Kolinsky, R., & Ventura, P. (2010). The impact of attention load on the use of statistical information and coarticulation as speech segmentation cues. Attention, Perception, & Psychophysics, 72, 1522–1532.
Goujon, A., Didierjean, A., & Marmèche, E. (2009). Semantic contextual cuing and visual attention. Journal of Experimental Psychology: Human Perception and Performance, 35, 50–71.
Jiang, Y., & Chun, M. M. (2001). Selective attention modulates implicit learning. Quarterly Journal of Experimental Psychology, 54A, 1105–1124.
Jiang, Y., & Leung, A. W. (2005). Implicit learning of ignored visual context. Psychonomic Bulletin & Review, 12, 100–106.
Jiménez, L., & Méndez, C. (1999). Which attention is needed for implicit sequence learning? Journal of Experimental Psychology: Learning, Memory, and Cognition, 25, 236–259.
Pollmann, S. (2019). Working memory dependence of spatial contextual cueing for visual search. British Journal of Psychology, 110, 372–380.
Rouder, J. N., & Morey, R. D. (2011). A Bayes factor meta-analysis of Bem’s ESP claim. Psychonomic Bulletin & Review, 18, 682–689.
Rowland, L. A., & Shanks, D. R. (2006). Attention modulates the learning of multiple contingencies. Psychonomic Bulletin & Review, 13, 643–648.
Simonsohn, U. (2015). Small telescopes: Detectability and the evaluation of replication results. Psychological Science, 26, 559–569.
Tanaka, D., Kiyokawa, S., Yamada, A., Dienes, Z., & Shigemasu, K. (2008). Role of selective attention in artificial grammar learning. Psychonomic Bulletin & Review, 15, 1154–1159.
Theeuwes, J. (2018). Visual selection: Usually fast and automatic; seldom slow and volitional. Journal of Cognition, 1, 29.
Toro, J. M., Sinnett, S., & Soto-Faraco, S. (2005). Speech segmentation by statistical learning depends on attention. Cognition, 97, B25–B34.
Turk-Browne, N. B., Jungé, J. A., & Scholl, B. J. (2005). The automaticity of visual statistical learning. Journal of Experimental Psychology: General, 134, 552–564.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
ESM 1
(DOCX 438 kb)
Rights and permissions
About this article

Cite this article
Vadillo, M.A., Giménez-Fernández, T., Aivar, M.P. et al. Ignored visual context does not induce latent learning. Psychon Bull Rev 27, 512–519 (2020). https://doi.org/10.3758/s13423-020-01722-x
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-020-01722-x