
Abstract
Numerical distance and size effects (easier number comparisons with large distance or small size) are mostly supposed to reflect a single effect, the ratio effect, which is a consequence of activation of the analog number system (ANS), working according to Weber’s law. In an alternative model, symbolic numbers can be processed by a discrete semantic system (DSS), in which the distance and size effects could originate in two independent factors: the distance effect depending on the semantic distance of the units, and the size effect depending on the frequency of the symbols. Whereas in the classic view both symbolic and nonsymbolic numbers are processed by the ANS, in the alternative view only nonsymbolic numbers are processed by the ANS, but symbolic numbers are handled by the DSS. The present work contrasts the two views, investigating whether the sizes of the distance and size effects correlate in nonsymbolic dot comparison and in symbolic Indo-Arabic comparison tasks. If a comparison is backed by the ANS, the distance and size effects should correlate, because the two effects are merely two ways to measure the same ratio effect. However, if a comparison is supported by another system—for example, the DSS—the two effects might dissociate. In the present measurements, the distance and size effects correlated very strongly in the dot comparison task, but they did not correlate in the Indo-Arabic comparison task. Additionally, the effects did not correlate between the Indo-Arabic and dot comparison tasks. These results suggest that symbolic number comparison is not handled by the ANS, but by an alternative representation, such as the DSS.
Similar content being viewed by others

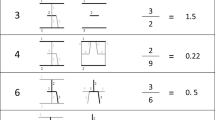

In their seminal work, Moyer and Landauer (1967) described that in an Indo-Arabic single-digit number comparison task, the performance is worse (i.e., reaction times are slower and error rates are higher) when the difference between the two numbers is relatively small (numerical distance effect) or when the numbers are relatively large (numerical size effect). They proposed that these two effects are the reflection of a single effect based on the ratio of the numbers: Number pairs with smaller ratio are harder to process (Fig. 1). This ratio-based performance was thought to be the result of a simple representation working according to Weber’s law, similar to the representations working behind simple physical-feature comparison tasks. This analog number system (ANS) is supposed to operate behind any number comparison, independent of the notation of the numbers (Dehaene, 1992; Eger, Sterzer, Russ, Giraud, & Kleinschmidt, 2003). The numerical cognition literature dominantly accepts the ANS interpretation of number comparison (Dehaene, 1992; Nieder, 2005; Piazza, 2010).

Sources of the symbolic distance and size effects according to the two models
However, an alternative account can also explain the numerical distance and size effects in symbolic number processing. It seems rather intuitive to imagine that symbolic numbers are stored in a discrete semantic system (DSS), similar to the mental lexicon or a semantic network. In this system, numbers are represented by nodes, and the connections of the nodes reflect their semantic relations. These relations might mainly be directed by the values of the numbers, but other properties might also have an effect, such as parity or primeness. The distance effect might be originated in the semantic relation of the nodes (Fig. 1). As a similar distance-based, nonnumerical example, in a picture-naming task it was found that naming times were influenced by the previous picture, and that this influence was proportional to the semantic distance of the priming and target pictures (Vigliocco, Vinson, Damian, & Levelt, 2002). This semantic distance effect is similar to the numerical distance effect: In both tasks, the performance was influenced by the semantic distance of the items. Although the cited distance effect in the picture-naming task is a priming distance effect, which has been proposed to be different from the comparison distance effect in the number comparison task (Reynvoet, De Smedt, & Van den Bussche, 2009), the current example points out that a discrete representation can also produce a distance-based gradual effect. The numerical size effect can also be explained by the DSS view. It is well-known that the frequencies of numbers are not uniform, but that smaller numbers are more frequent than larger numbers (Dehaene & Mehler, 1992). It is also known that stimulus processing is influenced by the stimulus frequency. On the basis of these starting points, one can imagine that larger numbers are harder to process because they are less frequent (Fig. 1). It has also been shown that in the comparison of artificial number symbols, in which the frequency of the digits could be arbitrarily manipulated, the size effect followed the frequencies of the numbers (Krajcsi, Lengyel, & Kojouharova, 2016a), reflecting that the numerical size effect is indeed a frequency effect. A combination of the semantic-based distance effect and the frequency-based size effect can predict the performance seen in comparison tasks, and this prediction correlates strongly with the ANS model prediction, revealing similar descriptions of comparison performance by the two models (Krajcsi et al., 2016a). To summarize, the DSS model can give simple explanations for the symbolic numerical distance and size effects (see additional examples of how further symbolic numerical effects can be explained in Krajcsi, Lengyel, & Kojouharova, 2016c). It is important to note that the DSS only accounts for symbolic number processing, whereas nonsymbolic number processing could still be supported by the ANS.
In the present study, the two models are contrasted by correlating the sizes of the numerical distance and size effects. According to the ANS model, the distance and size effects are merely two ways to measure the same ratio effect; therefore, the two effects should be closely related. To discuss this prediction in more detail, in the ANS model the sizes of the distance and size effects are influenced by scaling parameters, as in Moyer and Landauer (1967), and by the Weber ratio (Dehaene, 2007). Importantly, these parameters modify both the distance and size effects at the same time, because the equations describing performance handle only the ratio, and the distance and size effects are consequences of the ratio effect. Because of the ways that the sizes of the distance and size effects are calculated, it is not trivial to specify whether the relation between the effects is linear; however, the relation should at least be monotonic. It is also be important to note that the distance and size effects cannot correlate as an artifact of the ways that the two effects are calculated, because the distance effect relies on the difference of two numbers to be compared, whereas the size effect relies on the sum of the two numbers (see also the Results section). Therefore, the two effects form orthogonal dimensions in the stimulus space, resulting in no correlation between the distance and the size of number pairs. According to the DSS model, in symbolic comparison, the distance and size effects derive from different mechanisms, and potentially from different parameters; consequently, the two effects could be partly unrelated. At the same time, according to the DSS model, it is possible that some parameters are shared between the distance-based and frequency-based mechanisms (either as DSS-specific parameters or as some general states, as was recently discussed in Cantlon, 2015); thus, some correlation could be observed. Therefore, according to the DSS model, the correlation value might be found across a wide range. Because of the differing mechanisms behind distance and size effects, however, if the different mechanisms include different parameters that influence performance, then the correlation should be lower than the ANS-predicted high correlation.
The main question of the present study was whether the distance and size effects strongly correlate in symbolic notation, as is predicted by the ANS model, or whether the correlation is smaller, as is allowed by the DSS model. Correlation was also measured in nonsymbolic notation: Because both the ANS and DSS views suggest that nonsymbolic comparison is backed by the ANS, this nonsymbolic comparison correlation served as a baseline. Statistically, the main question was whether the correlation between the distance and size effects is smaller in symbolic Indo-Arabic comparison than in nonsymbolic dot comparison.
Method
The present study is based on the reanalysis of data from two previous studies: in one case, control group data from a neuropsychology study in preparation, and in the other, an investigation of the psychophysical properties of nonsymbolic and symbolic comparisons (Krajcsi, Lengyel, & Kojouharova, 2016b). Both the aims and the analyses of the previous studies are different from those of the present one. Two sets of data were used to ensure the reliability of the results through their replicability. The two studies mostly used the same methods, and only a few differences will be described.
The participants in one condition compared Indo-Arabic numbers, and in another condition they compared dot arrays. In each trial, two numbers were visible on the left and right sides of the screen, and participants had to choose the larger number by pressing one of the two response keys. The stimuli were visible until the keypress. A response was followed by an empty screen for 500 ms, then the next trial started.
In the Indo-Arabic condition, the numbers were between 1 and 9—that is, all single-digit numbers. Research has shown that the processing of multidigit numbers includes additional mechanisms to handle the different powers (Hinrichs, Berie, & Mosell, 1982; Poltrock & Schwartz, 1984); therefore, it was more appropriate to use only single-digit numbers. All possible pairings of those values were presented, except ties, resulting in 72 possible pairs. All pairs were presented either three times (Study 1) or ten times (Study 2), resulting in 216 or 720 trials, respectively. The order of the trials was randomized.
In the dots condition, it was not appropriate to use the same 1–9 range as in the Indo-Arabic condition, because sets with less than five objects can be enumerated quickly, which fast enumeration is termed subitizing (Kaufman, Lord, Reese, & Volkmann, 1949). Subitizing is not an ANS-directed process (Revkin, Piazza, Izard, Cohen, & Dehaene, 2008), but is most probably based on pattern detection (Krajcsi, Szabó, & Mórocz, 2013; Mandler & Shebo, 1982). Therefore, to measure ANS-based dot estimation, the 1–4 range should be avoided. To avoid this range and keep the critical ratio-based feature at the same time, all numbers between 1 and 9 were multiplied by 5, resulting in a number range between 5 and 45. According to the ANS model, because ratio is the primary source of the performance (Dehaene, 2007), transformations keeping the ratios should not change either the performance in general or the correlations specifically. In an array of dots, black and white dots in random positions were shown against a gray background (Dakin, Tibber, Greenwood, Kingdom, & Morgan, 2011); thus, the luminance of the stimuli was not informative about the numerosity. The dots of an array were drawn randomly in a 2 × 2 deg area, with a dot diameter of 0.2 deg, so that density and convex hull correlated with the numerosity. Although our stimuli did not control all perceptual features that might influence the perceived numerosity, perfect visual control might be impossible in some simple methods that have usually been utilized in the literature (Gebuis & Reynvoet, 2012). More importantly, in the present test, the nonnumerical influence of the decision process was less relevant, because the ANS model suggests that number comparison is handled by an analog system that could be used in any continuous physical-feature comparison (Dehaene, 2007; Moyer & Landauer, 1967). Hence, in a general sense, any continuous physical-feature comparison working according to the Weber’s law could be an appropriate task in our test. Additionally, a mixture of visual ratio-based performance and numerosity ratio-based performance should also produce approximately ratio-based performance, as reflected in the similar psychometric functions of visual and numerical comparison tasks. Therefore, the simple and limited visual control of the stimuli should be appropriate for the aim of the present test. As in the Indo-Arabic condition, all possible pairs were presented either three times (Study 1) or ten times (Study 2), resulting in 216 or 720 trials, respectively. The order of the trials was randomized.
In the first study, all sessions started with the Indo-Arabic condition and finished with the dot condition. In the second study, the order of the conditions was counterbalanced across participants. Presentation of the stimuli and measurement of the responses were managed by the PsychoPy software (Peirce, 2007).
In the first study, 19 university students participated for partial credit course. No participants were excluded from the analysis. The sample included 17 females and two males, with an age range of 18–24 and a mean of 20.1 years. In the second study, 24 university students participated for partial credit course. Four participants were excluded because of error rates higher than 1.5 standard deviation beyond the mean in at least in one of the conditions (6 % in the Indo-Arabic condition, 15 % in the dots condition). The remaining 20 participants included 16 females and four males, with an age range of 19–24 and a mean of 21.0 years.
Analysis
The slopes of the distance and size effects based on reaction times were calculated for all participants and both notations. For the slopes reported here, mean reaction times were calculated for all distance values (absolute values of the differences between the two numbers) or for all size values (sums of the numbers) for all participants and notations, and linear regression slopes were calculated on these mean values. The effects were alternatively calculated (a) with only the correct responses, (b) using the median instead of the mean, or (c) with the slope divided by the mean of the comparison time, to handle the slope change caused by general speed differences. These alternative calculation methods revealed the very same results as the first one (i.e., significant correlation in the nonsymbolic comparison, nonsignificant correlation in the symbolic comparison, and significant difference between the symbolic and nonsymbolic correlations); thus, their results are not reported here. In the dot comparison task, for the distance effect the slope was calculated as if the number of dots were between 1 and 9, although the dots were between 5 and 45, but this method reflected more appropriately the ANS model-driven consideration that the two notations cover the same ratio range. Importantly, this linear transformation of the slopes did not change the correlational coefficients.
For the correlational analysis, (1) Pearson’s product-moment coefficient was calculated, which makes the present results comparable with previous correlational studies. Additionally, (2) Spearman’s rank correlation coefficient was also calculated, because in contrast with the Pearson correlation, it is not sensitive to (a) outliers, (b) violation of normality, or (c) violation of homoscedasticity, and (d) it can measure nonlinear monotonic relation more sensitively. Finally, (3) the reliability of the variables in the correlation was handled. In any correlation the variables include both the signals to be measured and the noise. The noise decreases the reliability of the variables, which in turn constrains the maximum correlation that one might see. Because the ANS model predicts a high correlation between distance and size effects, it was essential to handle the potential unreliability of the variables to see whether the two variables measure the same mechanism. Also, it was possible that the distance effect–size effect correlation could be smaller in the Indo-Arabic comparison because it had a smaller signal-to-noise ratio (resulting in less reliability, and consequently a lower correlation), and not because symbolic comparison is processed by the DSS. Therefore, the critical difference in the correlations between the notations might be a bias of the different signal-to-noise ratios in those notations. Spearman’s method was applied to estimate the “real” correlation of the variables, removing the role of this unreliability (Spearman, 1904). The distance and size effects were calculated again, as in the main analysis, but as in an even–odd split-half method, even and odd trials were handled separately; thus, for all effects, even and odd versions were calculated. The corrected correlation was calculated as
where r is the Pearson correlation coefficient.
Results
In the main analysis, the correlations of the slopes of the two effects were investigated in both notations and in both studies. In the dot comparison task, the distance and size effects strongly correlated in both studies (Table 1, left side). Critically, the estimated correlation coefficients after removing the unreliabilities of the variables show values very close to 1,Footnote 1 reflecting a perfect correlation between the distance and size effects in nonsymbolic dot comparison. In the Indo-Arabic comparison task, the correlations are weak and not significant in either of the studies (Table 1, right side). These results are not the artifact of outliers, the nonnormality of the variables, or heteroscedasticity, because the very same results can be observed with both Pearson’s and Spearman’s correlation coefficients. The differences between the correlations were significant in both studies.
According to some former reports, nonsymbolic dot comparison performance and the mainly symbolic mathematical performance are related (e.g., Halberda, Ly, Wilmer, Naiman, & Germine, 2012; Halberda, Mazzocco, & Feigenson, 2008; Lourenco, Bonny, Fernandez, & Rao, 2012); therefore, it could be of interest how the symbolic and nonsymbolic comparisons are related in the present data. The correlations of the effects across the notations were calculated—for example, whether the Indo-Arabic distance effect and the dot distance effect correlated. None of the effects correlated across the notations: in the first study, for the distance effects, r(17) = .00, p = 1.00, 95 % CI of r = [–.45, .46], r s = .08; for the size effects, r(17) = .13, p = .59, 95 % CI of r = [–.34, .55], r s = .11; in the second study, for the distance effects, r(18) = .15, p = .52, 95 % CI of r = [–.31, .56], r s = .12; for the size effects, r(18) = .32, p < .17, 95 % CI of r = [–.15, .67], r s = .24.
Discussion
The present work investigated how strongly the numerical distance and size effect slopes correlate in Indo-Arabic and dot comparison tasks. (1) First, it was found that the distance and size effect slopes correlated strongly in the dot comparison task (Table 1, left side), and after correcting for the reliabilities of the variables, the correlation was very close to 1, reflecting perfect correlation between the two effects. This result is in line with the classic ANS model, which suggests that in a comparison task, the distance and size effects are the direct consequences of the ratio effect (Moyer & Landauer, 1967), and since both distance and size effects are modified by the same parameters, the two effects should correlate strongly. Additionally, the very strong correlation demonstrates that the method used in the present study is appropriate to reveal this strong relation between the distance and size effects. (2) Also, this study has revealed that the distance and size effects are barely related in the Indo-Arabic comparison task (Table 1, right side), and the correlation is clearly smaller than the correlation found in the dot comparison task. This result is in conflict with the classic ANS model, because according to that model the same strong correlation should have been found as in the dot comparison task, because the distance and size effects are directed by a single ratio-based effect. However, the result is in line with the DSS model, which suggests that the distance and size effects rely on different mechanisms, and probably partly on different parameters: The distance effect could be rooted in a mechanism based on the semantic relation of the units (as in Vigliocco et al., 2002), whereas the size effect might be related to the frequency of the symbols (Dehaene & Mehler, 1992; Krajcsi et al., 2016a). (3) Finally, this study has shown that the effects do not correlate between the notations: It seems that the size of the distance effect in the Indo-Arabic comparison is independent of the size of the distance effect in the dot comparison, and the same holds for the size effect. Although it was suggested that nonsymbolic performance correlates with mathematical achievement, suggesting that the ANS is one of the main roots of mathematical knowledge (e.g., Halberda et al., 2012; Halberda et al., 2008; Lourenco et al., 2012), the present data are not in line with these findings, but reflect the finding of a more systematic review revealing that only symbolic comparison correlates with children’s mathematical achievement, but nonsymbolic comparison and mathematical achievement mostly do not correlate (De Smedt, Noël, Gilmore, & Ansari, 2013). The present results also replicate the findings of studies that demonstrated that symbolic and nonsymbolic comparisons do not correlate in children (Holloway & Ansari, 2009; Sasanguie, Defever, Maertens, & Reynvoet, 2014), although in those reports nonsymbolic comparison set sizes in the subitizing range (i.e., 1–4) were also applied; thus, the validity of some of those data could be questioned.
The present results are not in line with the ANS model, which suggests that the same type of process handles both the symbolic and nonsymbolic numbers (Dehaene, 1992; Eger et al., 2003). Although there could be differences between symbolic and nonsymbolic number processing (e.g., different Weber fractions across notations; see Dehaene, 2007), the ANS model unequivocally states that performance is based on the ratio of the values, in a representation working according to Weber’s law, and that this feature is independent of the notation of the values, be it symbolic or nonsymbolic. Therefore, the present results cannot be explained by the differences between symbolic and nonsymbolic comparisons, because according to the ANS model, the distance–size effect correlation should be observable in any number comparisons.
Although the present results are in line with the DSS model and give some support to this alternative view, this single study clearly did not test the DSS model extensively. It is also possible that another alternative could be found. Still, the DSS seems a reasonable alternative at the moment, and it can explain not only the former data about symbolic number comparison, or number processing more in general, but also the present findings. Further research should reveal whether the DSS model is an appropriate explanation of symbolic number processing or whether another alternative should be found.
On the basis of present data, it may be possible that while comparing symbolic numbers, both the ANS and the DSS are activated, and that both of them influence the observed performance. It may be possible that the correlation of the effects is smaller in symbolic than in nonsymbolic comparison because the contribution of the DSS decreases the coefficient, but that part of the correlation still might originate in ANS processing. Although the very low coefficients seen in symbolic comparison hint at pure DSS processing, still, because of the uncertainties of the analysis methods, it is hard to precisely quantify the different predictions of explanations based on pure DSS activation and mixed DSS and ANS activations. Still, it is clear that the symbolic comparison results are not in line with a pure-ANS explanation.
These results and interpretations are in accord with some former results in the literature. A few studies have shown that effects that should be related according to the ANS model are actually independent. In an artificial new-number-symbol system, it was found that the size effect follows the frequencies of the symbols, independent of the ratios of the values (Krajcsi et al., 2016a). In a connectionist simulation, various symbolic numerical effects could be modeled coherently, and importantly, the size effect could be modeled with the introduction of the frequencies of the values, independent of the distance effect (Verguts, Fias, & Stevens, 2005). Similarly, in another connectionist model of number comparison, the distance and size effects emerge from independent components of the network (Zorzi & Butterworth, 1999). Finally, the comparison distance effect and the priming distance effect (in a priming task, the size of the priming effect depends on the distance between the prime and target numbers) were found to be independent (Reynvoet et al., 2009), although they should be related according to the ANS model. In a different group of works, it was found that symbolic and nonsymbolic number processing have differences where the ANS model would predict similarities. In a detailed analysis it was demonstrated that, contrary to the former analyses, although the ANS model can describe dot comparison performance relatively well, the model has systematic biases in describing Indo-Arabic comparison. Therefore, symbolic and nonsymbolic number comparisons might rely on two different representations (Krajcsi et al., 2016c). Also, as was mentioned above, according to several findings, symbolic and nonsymbolic comparisons do not correlate in children (Holloway & Ansari, 2009; Sasanguie et al., 2014), and nonsymbolic comparison mostly does not correlate with typically symbolic mathematical achievement (De Smedt et al., 2013).
The present work has investigated a fundamental prediction of the ANS model—whether the distance and size effects correlate in any number notations—and the results do not support the model for symbolic comparison. Although it is clear that the ANS model is supported by many empirical results and many theoretical considerations, the DSS can explain many phenomena that were formerly attributed to the ANS model, and in some contrasts the DSS can offer a better account of the former and new phenomena. To explore the status of the ANS and DSS models, further effort should be taken to clarify the scope of the former data, and new tests and considerations will be required in order to evaluate the competing models.
Notes
It is possible to have a value larger than 1 for the corrected correlation coefficient. Still, the corrected correlation coefficient of the dot comparison effects in the second study (–1.06) is very close to the value 1.
References
Cantlon, J. F. (2015). Analog origins of numerical concepts. In D. C. Geary, D. B. Berch, & K. Mann Koepke (Eds.), Evolutionary origins and early development of number processing (Vol. 1, pp. 225–251). London: Academic Press.
Dakin, S. C., Tibber, M. S., Greenwood, J. A., Kingdom, F. A. A., & Morgan, M. J. (2011). A common visual metric for approximate number and density. Proceedings of the National Academy of Sciences, 108, 19552–19557. doi:10.1073/pnas.1113195108
De Smedt, B., Noël, M.-P., Gilmore, C., & Ansari, D. (2013). How do symbolic and non-symbolic numerical magnitude processing skills relate to individual differences in children’s mathematical skills? A review of evidence from brain and behavior. Trends in Neuroscience and Education, 2, 48–55. doi:10.1016/j.tine.2013.06.001
Dehaene, S. (1992). Varieties of numerical abilities. Cognition, 44, 1–42. doi:10.1016/0010-0277(92)90049-N
Dehaene, S. (2007). Symbols and quantities in parietal cortex: Elements of a mathematical theory of number representation and manipulation. In P. Haggard, Y. Rossetti, & M. Kawato (Eds.), Sensorimotor foundations of higher cognition (Vol. XXII, pp. 527–574). Cambridge: Harvard University Press.
Dehaene, S., & Mehler, J. (1992). Cross-linguistic regularities in the frequency of number words. Cognition, 43, 1–29. doi:10.1016/0010-0277(92)90030-L
Eger, E., Sterzer, P., Russ, M. O., Giraud, A.-L., & Kleinschmidt, A. (2003). A supramodal representation in human intraparietal cortex. Neuron, 37, 719–725.
Gebuis, T., & Reynvoet, B. (2012). The interplay between nonsymbolic number and its continuous visual properties. Journal of Experimental Psychology: General, 141, 642–648. doi:10.1037/a0026218
Halberda, J., Ly, R., Wilmer, J. B., Naiman, D. Q., & Germine, L. (2012). Number sense across the lifespan as revealed by a massive Internet-based sample. Proceedings of the National Academy of Sciences, 109, 11116–11120. doi:10.1073/pnas.1200196109
Halberda, J., Mazzocco, M. M. M., & Feigenson, L. (2008). Individual differences in non-verbal number acuity correlate with maths achievement. Nature, 455, 665–668. doi:10.1038/nature07246
Hinrichs, J. V., Berie, J. L., & Mosell, M. K. (1982). Place information in multidigit number comparison. Memory & Cognition, 10, 487–495.
Holloway, I. D., & Ansari, D. (2009). Mapping numerical magnitudes onto symbols: The numerical distance effect and individual differences in children’s mathematics achievement. Journal of Experimental Child Psychology, 103, 17–29. doi:10.1016/j.jecp.2008.04.001
Kaufman, E. L., Lord, M. W., Reese, T. W., & Volkmann, J. (1949). The discrimination of visual number. American Journal of Psychology, 62, 498–525.
Krajcsi, A., Lengyel, G., & Kojouharova, P. (2016a). The source of the symbolic numerical distance and size effects. Manuscript submitted for publication.
Krajcsi, A., Lengyel, G., & Kojouharova, P. (2016b). Symbolic number comparison is not processed by the analogue magnitude system: Different symbolic and nonsymbolic numerical distance and size effects. Manuscript submitted for publication.
Krajcsi, A., Lengyel, G., & Kojouharova, P. (2016c). Symbolic number processing: Analogue number system or discrete semantic system? Manuscript submitted for publication.
Krajcsi, A., Szabó, E., & Mórocz, I. (2013). Subitizing is sensitive to the arrangement of objects. Experimental Psychology, 60, 227–234. doi:10.1027/1618-3169/a000191
Lourenco, S. F., Bonny, J. W., Fernandez, E. P., & Rao, S. (2012). Nonsymbolic number and cumulative area representations contribute shared and unique variance to symbolic math competence. Proceedings of the National Academy of Sciences, 109, 18737–18742. doi:10.1073/pnas.1207212109
Mandler, G., & Shebo, B. J. (1982). Subitizing: An analysis of its component processes. Journal of Experimental Psychology: General, 111, 1–22. doi:10.1037/0096-3445.111.1.1
Moyer, R. S., & Landauer, T. K. (1967). Time required for judgements of numerical inequality. Nature, 215, 1519–1520. doi:10.1038/2151519a0
Nieder, A. (2005). Counting on neurons: The neurobiology of numerical competence. Nature Reviews Neuroscience, 6, 177–190. doi:10.1038/nrn1626
Peirce, J. W. (2007). PsychoPy—Psychophysics software in Python. Journal of Neuroscience Methods, 162, 8–13. doi:10.1016/j.jneumeth.2006.11.017
Piazza, M. (2010). Neurocognitive start-up tools for symbolic number representations. Trends in Cognitive Sciences, 14, 542–551. doi:10.1016/j.tics.2010.09.008
Poltrock, S. E., & Schwartz, D. R. (1984). Comparative judgments of multidigit numbers. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 32–45. doi:10.1037/0278-7393.10.1.32
Revkin, S. K., Piazza, M., Izard, V., Cohen, L., & Dehaene, S. (2008). Does subitizing reflect numerical estimation? Psychological Science, 19, 607–614.
Reynvoet, B., De Smedt, B., & Van den Bussche, E. (2009). Children’s representation of symbolic magnitude: The development of the priming distance effect. Journal of Experimental Child Psychology, 103, 480–489. doi:10.1016/j.jecp.2009.01.007
Sasanguie, D., Defever, E., Maertens, B., & Reynvoet, B. (2014). The approximate number system is not predictive for symbolic number processing in kindergarteners. Quarterly Journal of Experimental Psychology, 67, 271–280. doi:10.1080/17470218.2013.803581
Spearman, C. (1904). The proof and measurement of association between two things. American Journal of Psychology, 15, 72–101. doi:10.2307/1412159
Verguts, T., Fias, W., & Stevens, M. (2005). A model of exact small-number representation. Psychonomic Bulletin & Review, 12, 66–80. doi:10.3758/BF03196349
Vigliocco, G., Vinson, D. P., Damian, M. F., & Levelt, W. (2002). Semantic distance effects on object and action naming. Cognition, 85, B61–B69. doi:10.1016/S0010-0277(02)00107-5
Zorzi, M., & Butterworth, B. (1999). A computational model of number comparison. In M. Hahn & S. C. Stoness (Eds.), Proceedings of the Twenty-First Annual Conference of the Cognitive Science Society (pp. 778–783). Mahwah: Erlbaum. Retrieved from http://eprints.ucl.ac.uk/91024/
Author note
I thank Krisztián Kasos, Petia Kojouharova, Ákos Laczkó, and Gábor Lengyel for their comments on an earlier draft of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Krajcsi, A. Numerical distance and size effects dissociate in Indo-Arabic number comparison. Psychon Bull Rev 24, 927–934 (2017). https://doi.org/10.3758/s13423-016-1175-6
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-016-1175-6