
Abstract
When a series of three successive to-be-reported items (targets) is displayed in a rapid serial visual presentation (RSVP) stream of distractors, it has been shown that no attentional blink—a marked impairment in the report of the second of two targets, typically observed when the targets appear within 200–600 ms of one another—occurs in target accuracy. The present study examines three recently introduced computational models that provide different explanations of this protracted sparing effect. Using a standard RSVP design and these models, we provide empirical data and simulations that illustrate that structural limitations affect the processing of successive targets. In addition, we compare the candidate mechanisms that might underlie these limitations.
Similar content being viewed by others

When viewing a rapid serial visual presentation (RSVP) of stimuli, subjects typically experience a marked difficulty in identifying the second of two targets (T2) if it appears within 200–600 ms of a first target (T1), an effect termed the attentional blink (AB; Raymond, Shapiro, & Arnell, 1992). An interesting exception to the AB, termed lag-1 sparing (Potter, Chun, Banks, & Muckenhoupt, 1998), is observed when T2 is displayed within approximately 100 ms of T1, in which case T2 is often identified without difficulty. By embedding more than two targets in RSVP, recent work has shown that sparing effects can encompass an uninterrupted series of successive targets, whose number approximates the storage limit of visual short-term memory (VSTM; i.e., 3–4 targets; Di Lollo, Kawahara, Ghorashi, & Enns, 2005; Nieuwenstein & Potter, 2006; Olivers, van der Stigchel, & Hulleman, 2007; Wyble, Potter, Bowman, & Nieuwenstein, 2011). Hereafter, we call this effect protracted sparing.
Limited-capacity AB models (e.g., Chun & Potter, 1995; Jolicœur & Dell’Acqua, 1998) hinge on the idea that fleeting conceptual representations of targets must be consolidated in VSTM in order to be available for delayed report. Consolidation is thought to be a capacity-limited operation initiated shortly after T1 onset and lasting on average 250–300 ms. During this interval, consolidation of trailing targets cannot be accomplished, thereby causing an AB. Lag-1 sparing effects are explained in this framework by reference to a sluggish gate mechanism. An attentional gate is hypothesized to open promptly upon detection of T1 onset, but to close slowly after T1 offset, allowing T1 and T2 to be consolidated concurrently when they are displayed as successive items. These models, however, were not designed to provide a functionally detailed explanation of protracted sparing effects.
Importantly, the notion of capacity limitations in this context does not refer to limiting the overall number of items that can be stored in VSTM, but rather to limitations affecting functionally earlier stages of processing that generate stable VSTM traces. RSVP studies present sequential targets rapidly enough to test limits affecting these encoding stages prior to memory storage. Such structural limitations are, in this view, a form of capacity limitation, and they are structural in the sense that they are an inherent part of the system, rather than a strategic effect that can be eliminated via task manipulations/instructions.
Protracted sparing, which has proved difficult for limited-capacity models to explain (but see Dell’Acqua, Jolicœur, Luria, & Pluchino, 2009; Dux, Asplund, & Marois, 2008, 2009; Visser & Ohan, 2011), has recently been accounted for by three computational theories of temporal attention: the boost-and-bounce model (Olivers & Meeter, 2008), the threaded cognition model (Taatgen, Juvina, Schipper, Borst, & Martens, 2009), and the episodic simultaneous type/serial token model (i.e., eSTST; Wyble, Bowman, & Nieuwenstein, 2009). Though these are only a subset of a larger class of computational theories developed to account for AB phenomena (for reviews, see Bowman & Wyble, 2007; Dux & Marois, 2009; Martens & Wyble, 2010), our focus is on these models, as only they have been designed to address protracted sparing effects.
Olivers and Meeter (2008) proposed a neurally inspired computational model that accounts for several findings related to temporal attention, including the AB. As in several previous theories (Bowman & Wyble, 2007; Nieuwenhuis, Gilzenrat, Holmes, & Cohen, 2005), their boost-and-bounce model uses a temporal attentional mechanism that enhances the processing of visual input within a brief time window following detection of a target. In this account, a paired excitatory/inhibitory attentional mechanism is configured by attentional settings to trigger a boosting (excitatory) response to targets and a bouncing (inhibitory) response to distractors. These two attentional responses cause dramatic fluctuations in the state of attention in response to targets and distractors at the scale of about 200 ms, and these fluctuations in turn affect the probability that an item will be encoded into VSTM during an RSVP stream. In the RSVP paradigm, T1 triggers a boosting response that enhances both T1 itself and closely following items in the stream. If the following item is another target (i.e., T2), the boosting response is further amplified, leading to T2 sparing. If the following item is a distractor, the T1-ignited boosting response allows the distractor to be encoded into VSTM, and the boosting response will be counteracted by a bouncing response elicited by the distractor. This distractor-ignited bouncing response produces an AB for any targets that follow the distractor. Presenting sequential targets, however, produces protracted sparing, because the lack of intervening distractors means that no bouncing response is triggered until the onset of a distractor terminating the target sequence. Critically, the model has no inherent limit on the rate at which targets can be encoded into VSTM, apart from limitations imposed by masking. Thus, the model imposes an important distinction between the rate at which items can enter VSTM and the total number of items that can be stored in VSTM.
Taatgen et al. (2009) proposed an ACT-R (“adaptive control of thought–rational”; Anderson, 2007) based account of RSVP processing. In their threaded cognition model, visual processing and memory operations can be completed in parallel under the control of a procedural processing module. When a stimulus is presented to the model, the stimulus is compared against declarative memory to determine whether it is a target. Finding a match with the target set promotes that item to encoding in VSTM, while distractors are ignored. An attentional mechanism acts like an overzealous watchdog, enacting a protective inhibitory rule if a distractor is detected while a target is being encoded into VSTM. Once enacted, this rule blocks processing of all new stimuli until encoding is complete, which results in an AB. When targets are presented sequentially, this rule is not triggered until after the final target, which results in sparing of all of the targets. Like the boost-and-bounce model, this model does not describe an explicit limitation on the rate of encoding. However, as we will see below, encoding limitations are implicit in the ACT-R framework.
Finally, we consider the eSTST model (Wyble et al., 2009; Wyble et al., 2011), a neural network simulation in which targets are encoded into VSTM by being bound to tokens—that is, representational formats combining information about the identity (or type) of T1 with information about its temporal characteristics. This model incorporates a temporal attention mechanism that can enhance the processing of stimuli within a temporal window. Attention is under the control of a competitive circuit that pits bottom-up excitation against top-down suppression. The behavior of this competitive circuit is optimized to produce two distinct behaviors, depending on the temporal arrangement of the targets: Two targets presented in rapid succession (i.e., within about 100 ms) are encoded concurrently, within a single window of attention, whereas two targets that are separated in time (i.e., more than 100 ms apart) will produce rapid encoding of the first target and delayed encoding of the second, so as to emphasize the temporal gap between them. This attentional mechanism allows for the encoding of sequential targets. However, such concurrent encoding is associated with multifaceted costs: Repetitions are more difficult to encode, impaired type/token bindings surface in behavior as incorrect orderings of the reported targets, and concurrently active target types interfere mutually, preventing some targets from being encoded at all (Wyble et al., 2011).
In the eSTST model, presenting a target facilitates encoding of the next target, through activation of attention. However that target also causes an inhibitory effect, through suppression of attention and interference at the type level (see Wyble et al., 2011). Thus, the net effect of one target on trailing targets can be either facilitatory or inhibitory, depending on their relative durations and sensory strengths. With three or more sequential targets, mutual interference between concurrently active target types becomes even stronger. Hence, this model implements explicit structural limitations that affect the processing of successive targets prior to VSTM. These limitations are structural in that they are inherent properties of the model, reflecting lateral inhibition between target types.
A straightforward prediction emerges from the present overview. Under conditions in which the number of targets is kept within the storage limit of VSTM, the boost-and-bounce model (Olivers & Meeter 2008) and the threaded cognition model (Taatgen et al., 2009) appear to predict that report accuracy of successive targets should be no worse than that for targets separated from each other by a time/lag outlasting the AB (e.g., 700 ms). In contrast, the eSTST model (Wyble et al., 2009) explicitly predicts that report should suffer from mutual type interference prior to consolidation whenever targets appear in close temporal proximity. Hence, overall target report should be worse for successive targets than for those that are temporally separated. Here we provide experimental data and three simulations, using the original models described above, to test these alternative accounts. Importantly, the models’ parameters were not altered, relative to the original implementations, to fit the pattern of results obtained in the present experiment.Footnote 1 The RSVP design used here closely resembles that of Dell’Acqua et al. (2009), which minimized subjects’ expectancy about the presentation order of targets and the impact of memory load on perceptual processing.
Method
Subjects
A group of 28 students at the University of Padova (16 female, 12 male) participated. Each was paid or received course credit, and all had normal or corrected-to-normal visual acuity.
Stimuli
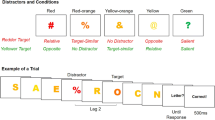
The stimuli were 22 letters of the English alphabet (all except B, I, O, and Z) and the digits 2–9. The stimuli were displayed at fixation in light gray (34 cd/m2) using a CRT monitor placed at a viewing distance of about 60 cm. The background was black (6 cd/m2). RSVP streams of stimuli were composed of distractor digits randomly selected from the available set, plus three different targets (T1, T2, and T3) positioned at varying lags in the stream. Identical distractor digits that appeared in the stream were separated by a minimum of two different stimuli. Each stimulus was displayed for 84 ms and was immediately replaced by the next item (interstimulus interval = 0 ms). The lags between T1 and T2 and between T2 and T3 were manipulated independently by interleaving zero (lag = 1), one (lag = 2), or seven (lag = 8) distractors between T1 and T2 and between T2 and T3. The number of distractors preceding T1 was varied randomly across trials from four to six, and two distractors always followed the presentation of T3. All characters in a given RSVP stream were displayed in either Romantri or Courier font. The two types of fonts were scaled so as to fit in a square portion of the monitor with a side of 1.0º.
Procedure
Each trial began with the presentation of three horizontally aligned plus signs at the center of the monitor. A spacebar press caused the plus signs to disappear and, after a fixed blank interval of 800 ms, the RSVP started. A question was displayed 800 ms after the end of the RSVP stream, inviting report of the three targets by pressing the corresponding keys on the keyboard. The instructions noted explicitly that target order and speed of response were not important. Feedback on an incorrectly reported target was provided at the end of each trial by replacing the plus sign in the position congruent with target order (from left to right: T1, T2, and T3) with a minus sign. Streams in Romantri or Courier font were equally likely to be displayed within each block of trials. Subjects performed 18 blocks of 36 experimental trials, preceded by one block of 36 practice trials.
Results
The analysis of the accuracy of report for a given target (T1, T2, or T3) considered only trials in which the other two targets were correctly identified, so as to adhere to the within-trial contingency principle (Dell’Acqua et al., 2009). The proportions of correct responses to each target were analyzed separately using an analysis of variance (ANOVA) in which T1 – T2 Lag and T2 – T3 Lag were treated as within-subjects factors. The order in which subjects indicated the identity of targets was not taken into account.
Single-target report
The ANOVA on the proportions of correct responses to T1 indicated a significant effect of T1 – T2 lag [F(2, 54) = 51.3, p < .001]. No other effect or interaction was significant (Fs < 1). The proportions of correct responses to T1 as a function of T1 – T2 and T2 – T3 lags are reported in Table 1.
The reduced report accuracy for T1 at T1 – T2 lag = 1, relative to the later lags, is consistent with prior studies showing a trade-off between consecutive targets (e.g., Potter, Staub, & O’Connor, 2002). The proportions of correct responses to T2 as a function of the T1 – T2 and T2 – T3 lags are plotted in Fig. 1a. The ANOVA indicated significant effects of T1 – T2 lag [F(2, 54) = 72.0, p < .001] and T2 – T3 lag [F(2, 54) = 19.9, p < .001], as well as a significant interaction between these factors [F(4, 108) = 10.4, p < .001].

(a) Mean proportions of correct responses to T2—p(T2|T1^T3)—as a function of the T1 – T2 and T2 – T3 lags. (b) Mean proportions of correct responses to T3—p(T3|T1^T2)—as a function of the T1 – T2 and T2 – T3 lags. Bars indicate ±1 standard error of the means
Figure 1a suggests that T2 report was affected by a sizable AB and by a pronounced sparing effect at T1 – T2 lag = 1 encompassing all T2 – T3 functions. The T2 – T3 functions overlapped at the two shorter T1 – T2 lags, with the exception of worse performance at T1 – T2 lag = 8 when T2 – T3 lag = 1 (green function in Fig. 1a)—namely, when T2 and T3 were consecutive targets. This pattern bears an obvious resemblance to the trade-off observed between consecutive T1 (.69) and T2 (.81) targets (i.e., at T1 – T2 lag = 1). The proportions of correct responses to T3 as a function of the T1 – T2 and T2 – T3 lags are plotted in Fig. 1b. The ANOVA indicated significant effects of T1 – T2 lag [F(2, 54) = 29.6, p < .001] and T2 – T3 lag [F(2, 54) = 148.2, p < .001], as well as a significant interaction between these two factors [F(4, 108) = 11.0, p < .001].
All-target report
Of primary importance for the present work was the pattern of results concerning the proportions of correct report for all three targets embedded in the RSVP streams—p(T1^T2^T3). Figure 2a plots p(T1^T2^T3) as a function of the T1 – T2 and T2 – T3 lags. The ANOVA indicated significant effects of T1 – T2 lag [F(2, 54) = 69.1, p < .001] and T2 – T3 lag [F(2, 54) = 84.7, p < .001], as well as a significant interaction between these two factors [F(4, 108) = 9.6, p < .001].

(a) Empirical results: Mean proportions of correct responses for reporting all three targets—p(T1^T2^T3)—as a function of the T1 – T2 and T2 – T3 lags. Bars indicate ±1 standard error of the means. (b) Results simulated by the three models considered in the present investigation. The strings of characters used as labels in the graph refer to the RSVP stream structures generating the corresponding values. The “D”s refer to digit distractors, and “T1,” “T2,” and “T3” refer to the three letter targets embedded in each RSVP stream. Symbols for distractors preceding T1 and following T3 are not reported in the labels
Pairwise comparisons involving the entire set of values plotted in Fig. 2a were conducted using t tests. The results of the set of comparisons are reported in Table 2 as the false-discovery-rate (Benjamini & Hochberg, 1995) corrected probabilities associated with each Student’s t test (not reported).
Figure 2a and Table 2 provide the necessary information to compare the distinct predictions made by the AB models outlined in the introduction, relating to the report of successive versus temporally separated targets.Footnote 2 Because none of the three models were fit to the data, their results deviate from the empirical results in several ways. For the purpose of the present study, we focused on the relative performance between the two conditions of interest. As is clear in Fig. 2a, the report of successive targets (i.e., when the T1 – T2 and T2 – T3 lags were both 1) was worse than the report of temporally separated targets (i.e., when the T1 – T2 and T2 – T3 lags were both 8). Figure 2b illustrates that this pattern of results is simulated correctly by only two of the three models compared in the present context—namely, those of Wyble et al. (2009) and Taatgen et al. (2009).
As detailed in the introduction, worse overall performance for successive targets relative to temporally separated targets was predicted explicitly by Wyble et al. (2009), and it is therefore not surprising that this model (Fig. 2b, left panel) simulates this particular aspect of the empirical results. The eSTST model (Wyble et al., 2009) provides an accurate depiction of an additional aspect of the results: The report of three successive targets was worse than when T1 and T2 were separated by the maximum number of distractors and T3 was the post-T2 item (i.e., at T1 – T2 lag = 8 and T2 – T3 lag = 1). However, this model overestimated the accuracy at T1 – T2 lag = 1 when T2 – T3 lag = 8, and underestimated the cost of competition between T2 and T3 at T2 – T3 lag = 1.
The subroutines described by Taatgen et al. (2009) do not include an attentional component whereby a target can impact the encoding of a trailing target without an intervening distractor. Furthermore, in their model there should be no competitive interaction between successive targets, as suggested by the simulation output illustrated in their Fig. 3 (p. 7), where no accuracy loss is evident in T1 report at T1 – T2 lag = 1. Unexpectedly, however, the threaded cognition model accurately simulates the decrement in performance associated with successive targets versus temporally separated targets (Fig. 2b, right panel).
In contrast to the eSTST and threaded cognition models, Olivers and Meeter’s (2008) boost-and-bounce model simulates higher accuracy for successive targets (i.e., when the T1 – T2 and T2 – T3 lags are 1) than for temporally separated targets (Fig. 1b, central panel). The complete inability to report all three targets at T1 – T2 lag = 1 when a single distractor is interleaved between T2 and T3 (i.e., at T2 – T3 lag = 2; blue function) is another significant discrepancy from the empirical findings. In addition, this model overestimates performance for two successive targets when they are followed, after a long interval, by a third target (i.e., at T1 – T2 lag = 1 and T2 – T3 = 8; leftmost point of red function) relative to temporally separated targets.
Discussion
Overall, the report accuracy of three consecutive targets was significantly lower than that for three targets separated by a sufficiently long delay (outside the AB range). This empirical finding demonstrates the influence of a significant limitation on the encoding of sequential targets into VSTM. This limitation was accurately simulated by two of three recent models specifically developed to account for protracted sparing effects.
The eSTST model (Wyble et al., 2009) posits that this limiting factor reflects mutual interference between concurrently active target types, along with suppression of attentional deployment to target types that grows proportionally with the number of sequential targets being tokenized at any given time point (Wyble et al., 2011). In the model, both of these mechanisms contribute to the decline in performance on identification of successive targets during protracted sparing. These limitations exert their combined effects prior to VSTM storage, through suppression of type activation and consequent loss of identity information. Numerous studies have supported the hypothesis that interactions occur between visual type representations prior to consolidation and memory storage. For instance, Potter et al. (2005) demonstrated conceptual interplay between successive targets at very short lags. Using conceptually related words as T1 and T2, these researchers observed priming that spread evenly to both targets, abating the trade-off between successive targets found in the present and prior studies.
It is less straightforward to isolate the components in the threaded cognition model (Taatgen et al., 2009) that allow it to accurately simulate the reduced accuracy for successive targets as compared to temporally separated targets. The threaded cognition model inherits a structural limitation from the broader class of ACT-R frameworks, arising from the minimum amount of time required to execute the production rules that initiate the encoding of a given target. This limitation is visible in the Gantt diagrams presented by Taatgen et al. (2009, their Fig. 2b), which depict the sequence of events triggered by two successive targets. The diagrams show that detecting T1 and issuing a command to store it require slightly more than 100 ms. This is observable by noting that the timing of the “Potential target B” rule execution is significantly delayed relative to the onset of the “B” target. This limitation does not substantially affect the ability to encode two consecutive targets, because T2 availability outlasts this delay with two to-be-stored targets. This limitation, however, does reduce the ability to report the third of three rapidly presented consecutive targets. Given that this limiting factor is hardwired into the ACT-R architecture, it appears that the threaded cognition model incorporates structural limitations that affect the rate of information acquisition under RSVP conditions.
This comparison is not aimed at disproving any of the candidate models. Rather, we are using the comparison between these models to highlight the important role played by encoding limitations in accurately describing the mechanisms underlying target report in RSVP. Other models could be modified to account for these effects and to provide more nuanced simulations of the patterns typically observed in RSVP experiments, which have been corroborated empirically in the present study.
Notes
The threaded cognition model (Taatgen et al., 2009) requires about 50 ms for production rules, and we therefore opted to perform these simulations at 100 ms rather than 84 ms, to allow for a closer fit. Simulations run at 84 ms per item also reproduced the reduced report of successive targets.
The Olivers and Meeter’s (2008) boost-and-bounce model does not explicitly simulate individual trials. Instead, the probabilities of reporting each target are described by the equations of the model. To simulate p(T1^T2^T3) with this model, we multiplied the individual probabilities of reporting each target for each combination of lags.
References
Anderson, J. R. (2007). How can the human mind occur in the physical universe? New York: Oxford University Press.
Benjamini, Y., & Hochberg, Y. (1995). Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B, 57, 289–300.
Bowman, H., & Wyble, B. (2007). The simultaneous type, serial token model of temporal attention and working memory. Psychological Review, 114, 38–70.
Chun, M. M., & Potter, M. C. (1995). A two-stage model for multiple target detection in rapid serial visual presentation. Journal of Experimental Psychology: Human Perception and Performance, 21, 109–127. doi:10.1037/0096-1523.21.1.109
Dell’Acqua, R., Jolicœur, P., Luria, R., & Pluchino, P. (2009). Reevaluating encoding-capacity limitations as a cause of the attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 35, 338–351.
Di Lollo, V., Kawahara, J., Ghorashi, S. M. S., & Enns, J. T. (2005). The attentional blink: Resource depletion or temporary loss of control? Psychological Research, 69, 191–200. doi:10.1007/s00426-004-0173-x
Dux, P. E., Asplund, C. L., & Marois, R. (2008). An attentional blink for sequentially presented targets: Evidence in favor of resource depletion accounts. Psychonomic Bulletin & Review, 15, 809–813.
Dux, P. E., Asplund, C. L., & Marois, R. (2009). Both exogenous and endogenous target salience manipulations support resource depletion accounts of the attentional blink: A reply to Olivers, Spalek, Kawahara, and Di Lollo (2009). Psychonomic Bulletin & Review, 16, 219–224.
Dux, P. E., & Marois, R. (2009). The attentional blink: A review of data and theory. Attention, Perception, & Psychophysics, 71, 1683–1700. doi:10.3758/APP.71.8.1683
Jolicœur, P., & Dell’Acqua, R. (1998). The demonstration of short-term consolidation. Cognitive Psychology, 36, 138–202. doi:10.1006/cogp.1998.0684
Martens, S., & Wyble, B. (2010). The attentional blink: Past, present, and future of a blind spot in perceptual awareness. Neuroscience and Biobehavioral Reviews, 34, 947–957.
Nieuwenhuis, S., Gilzenrat, M. S., Holmes, B. D., & Cohen, J. D. (2005). The role of the locus coeruleus in mediating the attentional blink: A neurocomputational theory. Journal of Experimental Psychology: General, 134, 291–307.
Nieuwenstein, M. R., & Potter, M. C. (2006). Temporal limits of selection and memory encoding: A comparison of whole versus partial report in rapid serial visual presentation. Psychological Science, 17, 471–475. doi:10.1111/j.1467-9280.2006.01730.x
Olivers, C. N. L., & Meeter, M. (2008). A boost and bounce theory of temporal attention. Psychological Review, 115, 836–863. doi:10.1037/a0013395
Olivers, C. N. L., van der Stigchel, S., & Hulleman, J. (2007). Spreading the sparing: Against a limited capacity account of the attentional blink. Psychological Research, 71, 126–139.
Potter, M. C., Chun, M. M., Banks, B. S., & Muckenhoupt, M. (1998). Two attentional deficits in serial target search: The attentional blink and an amodal task-switch deficit. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 979–992.
Potter, M. C., Dell’Acqua, R., Pesciarelli, F., Job, R., Peressotti, F., & O’Connor, D. H. (2005). Bidirectional semantic priming in the attentional blink. Psychonomic Bulletin & Review, 12, 460–465.
Potter, M. C., Staub, A., & O’Connor, D. H. (2002). The time course of competition for attention: Attention is initially labile. Journal of Experimental Psychology: Human Perception and Performance, 28, 1149–1162. doi:10.1037/0096-1523.28.5.1149
Raymond, J. E., Shapiro, K. L., & Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: An attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 18, 849–860. doi:10.1037/0096-1523.18.3.849
Taatgen, N. A., Juvina, I., Schipper, M., Borst, J. P., & Martens, S. (2009). Too much control can hurt: A threaded cognition model of the attentional blink. Cognitive Psychology, 59, 1–29.
Visser, T. A. W., & Ohan, J. L. (2011). Is all sparing created equal? Comparing lag-1 sparing and extended sparing in temporal object perception. Journal of Experimental Psychology: Human Perception and Performance, 37, 1527–1541.
Wyble, B., Bowman, H., & Nieuwenstein, M. (2009). The attentional blink provides episodic distinctiveness: Sparing at a cost. Journal of Experimental Psychology: Human Perception and Performance, 35, 787–807. doi:10.1037/a0013902
Wyble, B., Potter, M. C., Bowman, H., & Nieuwenstein, M. (2011). Attentional episodes in visual perception. Journal of Experimental Psychology: General, 140, 488–505.
Author Note
We are grateful to J. Hopfinger, V. Di Lollo, and two anonymous reviewers for their constructive comments on previous drafts of this article. We also thank N. Taatgen for providing simulations and comments regarding the function of his model. This research was supported by an Australian Research Council Discovery Grant and APD Fellowship awarded to P.E.D. (Grant DP0986387). The empirical data collected in the present study can be downloaded from http://colab.psy.unipd.it by following the link to R.D.A.’s personal page. The boost-and-bounce model (Olivers & Meeter, 2008) is available in Excel format at http://olivers.cogpsy.nl. The threaded cognition model (Taatgen et al., 2009) is available as LISP code at http://act-r.psy.cmu.edu/models. The eSTST model (Wyble et al., 2009) is available as MATLAB code at www.bradwyble.com/research/models/eSTST. Instructions on how to adjust the parameters of each model so as to generate simulated output based on the duration and sensory strength of RSVP items and on RSVP temporal structure can be found at the relevant Web sites.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Dell’Acqua, R., Dux, P.E., Wyble, B. et al. Sparing from the attentional blink is not spared from structural limitations. Psychon Bull Rev 19, 232–238 (2012). https://doi.org/10.3758/s13423-011-0209-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-011-0209-3