
Abstract
When a test of working memory (WM) requires the retention of multiple items, a subset of them can be prioritized. Recent studies have shown that, although prioritized (i.e., attended) items are associated with active neural representations, unprioritized (i.e., unattended) memory items can be retained in WM despite the absence of such active representations, and with no decrement in their recognition if they are cued later in the trial. These findings raise two intriguing questions about the nature of the short-term retention of information outside the focus of attention. First, when the focus of attention shifts from items in WM, is there a loss of fidelity for those unattended memory items? Second, could the retention of unattended memory items be accomplished by long-term memory mechanisms? We addressed the first question by comparing the precision of recall of attended versus unattended memory items, and found a significant decrease in precision for unattended memory items, reflecting a degradation in the quality of those representations. We addressed the second question by asking subjects to perform a WM task, followed by a surprise memory test for the items that they had seen in the WM task. Long-term memory for unattended memory items from the WM task was not better than memory for items that had remained selected by the focus of attention in the WM task. These results show that unattended WM representations are degraded in quality and are not preferentially represented in long-term memory, as compared to attended memory items.
Similar content being viewed by others


Upon meeting a new group of people at a cocktail party, it is common to have difficulty remembering each person’s name as introductions continue and conversation ensues. As different people speak in turn, brief shifts of attention can cause the name of the current speaker to become more immediately relevant, whereas the recently acquired names of unattended persons may fade. “Short-term memory” (STM) refers to the transient retention of such information when it is no longer present in the environment (e.g., when there are no name tags); the related construct of “working memory” (WM) additionally invokes the active manipulation of such information (e.g., mentally updating the list of learned names if a person leaves the conversing group). Several influential “state-based” models of STM have suggested that the ability to transiently retain information can be understood as the selection, by attention, of representations from long-term memory (LTM) or perception (Cowan, 1988; McElree, 1998; Oberauer, 2002). A crucial aspect of these state-based models is that these representations need not be continuously held in the focus of attention. Even after attention shifts to select new information, recently attended information may be transiently retained as “activated long-term memory.” Note that these state-based models differ from memory-systems models, such as the multiple-component model (Baddeley & Hitch, 1974), in that they require neither representations nor processes that differ from those recruited for the perception and recognition of stimuli or for the retrieval of information from LTM (reviewed in Larocque, Lewis-Peacock, & Postle, 2014).
The notion that attention can be allocated to internal representations such as those in WM has been supported by numerous empirical studies. For example, Oberauer has explored the allocation of attention to WM items using a WM task with retrocues that signal the relevance of a subset of memory items. He has shown that the Sternberg effect, which is the scaling of reaction times in a WM task with the number of items concurrently remembered, only exists for remembered items that are prioritized by retrocues (Oberauer, 2001, 2002, 2005); remembering additional, nonretrocued items does not affect reaction time. The state of the WM representations prioritized by the retrocues has been termed the “broad focus of attention” (Oberauer & Hein, 2012), roughly corresponding to Cowan’s four-item focus of attention (Cowan, 1995). Several neural studies have also identified neural correlates of an internal selecting process among items in WM, revealing a set of neural processes that overlaps with, but is distinct from, those associated with externally allocated attention (Griffin & Nobre, 2003; Kuo, Stokes, & Nobre, 2012; Lepsien & Nobre, 2007; Nee & Jonides, 2008, 2013; Nobre et al., 2004).
Several studies have attempted to identify the neural correlates of these proposed states in WM. Neuroimaging studies have shown that the neural activity evoked by a memory probe differs according to where on a serially presented list of memory items it has appeared (Nee & Jonides, 2008, 2011, 2013). In these studies, the most recently presented stimuli were assumed to be in a more prioritized, attended state in memory. Most germane to the present work are two studies of delay-period neural activity (LaRocque, Lewis-Peacock, Drysdale, Oberauer, & Postle, 2013; Lewis-Peacock, Drysdale, Oberauer, & Postle, 2012). These studies employed a basic task design modeled after the studies of Oberauer (2001, 2002, 2005), in which each trial begins with the presentation of two target stimuli, followed by an initial delay, followed by a retrocue indicating which of the two memory items will be relevant for the subsequent memory probe. Crucially, the uncued item must still be retained in WM because, after the first memory probe, a second retrocue will indicate that either the originally cued or the originally uncued item will be the target of a second memory probe. Thus, in these conditions, it was assumed that the retrocue guided the allocation of attention so that subjects were considered to simultaneously hold one item in the focus of attention (as an “attended memory item”: AMI) and one item outside the focus of attention (an “unattended memory item”: UMI). Several behavioral (LaRocque et al., 2013; Oberauer, 2002) and neural (Kuo et al., 2012; Lepsien & Nobre, 2007; Lewis-Peacock et al., 2012; Trapp & Lepsien, 2012) studies support the distinction between these two proposed states. For example, in functional magnetic resonance imaging (fMRI) and electroencephalographic (EEG) studies using this design, multivariate pattern analysis (MVPA) has revealed evidence for an active neural representation for the AMI, but not for the UMI. This has led to the proposal that neural activation may reflect of attention, rather than of the short-term retention of information, per se (Lewis-Peacock et al., 2012).
Despite the clear dissociation of neural activity related to AMIs and UMIs, it is unclear what behavioral consequences result from retaining information in WM, but outside the focus of attention. The experiments that follow were designed to address two questions. The first is: What are the consequences for the fidelity of a mnemonic representation when it is held as a UMI? On one hand, studies that vary the number of items to be processed find that the precision of memoranda declines monotonically as a function of load (Emrich, Riggall, LaRocque, & Postle, 2013; Zokaei, Gorgoraptis, Bahrami, Bays, & Husain, 2011). On the other, a study using the retrocuing technique has found that there is no drop in short-term recognition accuracy for UMIs relative to AMIs (Rerko & Oberauer, 2013). Experiment 1, therefore, was designed to assess the mnemonic precision of items that had been held as UMIs versus items that had only been held as AMIs.
The second question is prompted by the complete absence of MVPA evidence for an active neural representation of UMIs following a brief elevation in evidence immediately following the retrocue. Because a UMI remains in memory (as evidenced by excellent recognition when it is subsequently retrocued), the challenge is to understand the mechanism by which it is retained. The hypothesis tested in Experiment 2 is that, upon presentation of the retrocue, UMIs might receive an additional boost in the strength of their encoding in LTM. The possibility of such a post-retrocue reencoding was first suggested to us by the patterns of neural results from Lewis-Peacock et al. (2012) and LaRocque et al. (2013). In these studies, MVPA evidence for the noncued categories was transiently boosted in response to the retrocue, before dropping down to baseline. One possible explanation for this pattern of results is that subjects may have engaged in strategic (re)encoding of the uncued item into LTM, because they knew that this item might be needed later in the trial. According to this account, the retrocue that prompts the selection of the AMI also prompts the hippocampus-dependent reencoding of the UMI into a more durable, structural trace, a process that is not required for success on more conventional tests of STM and WM.
An additional line of evidence that speaks to the plausibility of this hypothesis comes from behavioral studies that have shown a decrement in LTM encoding for attended, actively rehearsed items relative to unattended, non-actively-rehearsed items. For example, Rose, Buchsbaum, and Craik (2014) showed that items that had been transiently maintained outside of focal attention were subsequently recalled better on a final LTM test than were items continuously retained in the focus of attention. The idea that actively rehearsed items might be remembered better on a test of STM, but less well remembered on a later test of LTM, hearkens back to the negative recency effect. In a seminal study, the stimuli most recently viewed, which were remembered best in the short term (recency items), were nonetheless more poorly recollected at longer memory delays (Craik, Gardiner, & Watkins, 1970). Our Experiments 2 and 3, therefore, employed surprise tests of LTM recognition of items that had been administered one week (Exp. 2) or 40 min (after an effortful intervening task; Exp. 3) after the WM task. The reasoning was that if UMIs experienced enhanced reencoding into LTM during the WM task, items that had been UMIs would be recognized better in the subsequent test of LTM than would items that had only been AMIs.
Experiment 1
Recently, considerable research has focused on the fidelity with which items are retained in memory. This research has been spurred by a growing appreciation for the limitations of recognition tests of memory; specifically, studies have shown that differences in recognition memory do not necessarily indicate the absence of a maintained representation, but may instead reflect varying fidelities of mnemonic representations (Wilken & Ma, 2004). The fidelity of mnemonic representations can be estimated from the variance of a subject’s responses as to the correct response value when recalling a feature of a stimulus that can vary continuously along some metric dimension, such as the location, orientation, or color of visual stimuli. This estimate of response variability has been termed precision (Bays, Catalao, & Husain, 2009; Bays & Husain, 2008; Wilken & Ma, 2004; Zhang & Luck, 2008; Zokaei et al., 2011). Using a retrocuing design similar to those from previous work, our aim was to investigate the effect on mnemonic precision of shifting the focus of attention from a memory item. Following the simultaneous presentation of two moving-dot arrays, subjects were instructed, via a retrocue, to retain one item in the focus of attention; however, the uncued item still had to be retained, because a second retrocue and memory probe could target that originally uncued item. If there is a consequence for holding one item outside the focus of attention (as a UMI) while holding one item in the focus of attention (as an AMI), then UMIs would be retained with less mnemonic precision than AMIs. If, on the other hand, there is no consequence to maintaining mnemonic representations in these different states of accessibility, then their estimates of precision should not differ.
Method
Subjects
A group of 36 healthy subjects (21 male, 15 female; average age = 21.9 years) were recruited from the University of Wisconsin–Madison community. All subjects were right handed, had normal color vision and normal or corrected-to-normal visual acuity, and reported no history of neurological disease or trauma. All subjects provided informed consent according to the Health Sciences Institutional Review Board at the University of Wisconsin–Madison.
Materials
Subjects were tested individually, seated approximately 60 cm from a 21.5-in. iMac computer screen (1,920 × 1,200 resolution) at 60 Hz. Experimental stimuli were generated and presented by the Psychophysics Toolbox (http://psychtoolbox.org; Brainard, 1997) running in MATLAB 2012b (MathWorks, Natick, MA).
WM task procedure
A white fixation cross (~0.7° visual angle) was presented at the beginning of each trial on a black background for 2.5 s. The memory sample then appeared (2 s), comprising two arrays of coherently moving (~10°/s) dots (each ~0.1° in diameter) moving within two circular apertures (~12° diameter), one located ~8° above and one ~8° below the fixation cross. The direction of motion of each dot array was randomly determined, with the constraint that there was at least 45°, but no greater than 135°, of separation between the directions on each trial. After the sample offset, followed by a 1-s delay, two vertically centered white lines appeared (0.5 s in duration), either above or below (~8°) the fixation cross; these lines functioned as a retrocue (Griffin & Nobre, 2003; Oberauer, 2001). All retrocues accurately predicted which motion sample would be tested in the subsequent recall test. All trials began in this fashion, but after a 4-s delay, subjects either saw a recall probe (two-probe condition) or experienced an additional 3-s delay period (one-probe condition). The recall probe consisted of a centrally located aperture (~12° diameter), as well as the appearance of the standard mouse-pointer computer icon. Once subjects moved the pointer outside the aperture, a white line appeared, originating at the center of the aperture and terminating at the point on the circular aperture nearest the mouse pointer. During a 3-s response window, subjects were to adjust the orientation of the line until it matched the direction of motion of the cued motion sample and then to click either mouse button to register their response. Next, a second retrocue appeared for 500 ms, either in the same location as previously (cue-repeat condition) or in the alternative location (cue-switch condition). Following a 4-s delay, subjects saw a recall probe and indicated their response from the most recently cued motion sample.
Feedback was provided after each response. The fixation cross turned green for 1 s after responses that were within 10° of the cued motion sample, yellow for responses between 10° and 25°, and red for all responses greater than 25° from the correct direction. Subjects completed equal numbers (48) of all four trial types (two-probe/cue-switch, two-probe/cue-repeat, one-probe/cue-switch, and one-probe/cue-repeat; see Fig. 1). Sessions were divided into six 11-min blocks, with breaks in between. Each block contained 32 trials, for a total of 192 overall. Additional block-by-block feedback was also provided; subjects saw a summary of their responses, categorized by the response feedback (green, yellow, or red), in the form of a histogram.

Experiment 1 task. The first portions of all trials were identical, beginning with a fixation cross (2.5 s) followed by the stimuli (2 s), comprising two arrays of coherently moving dots. The retrocue (0.5 s) indicated which motion sample was relevant for the subsequent recall test. On half of the trials, subjects had to respond to a first recall probe (two-probe condition) by pointing a line in the remembered direction of motion; on the other half, they experienced an additional 3-s delay period (one-probe condition). Following the probe or delay, a second retrocue appeared, either in the same location as before (cue-repeat condition) or in the alternative location (cue-switch condition). Following a 4-s delay, subjects saw a final recall probe and indicated their response for the most recently cued motion sample. The key comparison of interest was between the precision of responses on one-probe/cue-repeat and one-probe/cue-switch trials, because on those trials there was no initial probe to confound responses on the final probe; the only difference was whether or not the probed memory item had been attended, on the basis of the first retrocue, during the second delay period.
Data analysis
The data were analyzed by calculating the angular difference between subjects’ responses and the true direction of motion of the probed dot array. The inverse of the circular standard deviation of these errors, across trials, was calculated, and this served as our primary measure of precision. The difference in precision between the one-probe/cue-repeat and one-probe/cue-switch trials was the primary measure of interest, because this was the one comparison between conditions that only differed in terms of the allocation of attention; the omission of the first probe ensured that there was no confound of number of times probed and no response interference, and the equal delay-period lengths ensured that there was no confound of retention interval. Because we hypothesized that the precision would be reduced for memory items that had been uncued, we used a one-tailed t test to assess the significance of this comparison only. All other comparisons, because we did not have specific hypotheses, were assessed with two-tailed t tests. The responses to the second probe on two-probe/cue-repeat trials were potentially confounded by the feedback provided after the response to the first probe; that is, subjects knew to adjust their response on the second probe if, after their first response, the fixation cross had turned red, and they knew to repeat the same response if it had turned green. Due to the confounding effect of this feedback, no analyses of responses to the second probe in the two-probe conditions were conducted.
In addition to the analysis described above, we also performed probabilistic model-based analyses of the response errors, using a three-factor mixed model (Bays et al., 2009; Zokaei et al., 2011). In this analysis, a model is fit in which the responses are assumed to be either “target,” “nontarget,” or “uniform” (guess) responses. By classifying responses in this way, it is assumed that on each response, the subject was responding to the cued motion sample (target response), the uncued motion sample (nontarget response; this can be considered a binding error), or neither of the sample directions (guess response). Precision estimates from this analysis are in the form of the “concentration” parameter, κ, which is extracted from the estimated probability density function and which increases with increasing precision. This estimate of precision therefore accounts for which target subjects intended to recall and is unaffected by the trials on which subjects may have guessed.
For both measures of response error variability (precision and concentration), the results for one particular subject were more than three standard deviations away from the group mean. We therefore excluded this subject from further analysis, though inclusion of this subject did not alter the pattern of results.
Results
Our primary aim was to determine whether mnemonic fidelity varied as a function of attentional state. We examined subjects’ responses (error distributions are plotted in Fig. 2) in each condition of interest either by calculating precision (the inverse of the distribution’s standard deviation) or by extracting the concentration parameter κ from the mixture model analysis described by Bays et al. (2009). We illustrate these two approaches by plotting probability density functions (Fig. 2); the probability density functions plotted from the concentration parameter appear to more closely approximate the peaks of the response error distributions because they excluded some “far error” responses that the mixture model labeled as “guesses.” We applied our hypothesis tests to the measures of mnemonic fidelity derived from each of the two procedures.

Experiment 1 response error probability density plots. Shown are probability density plots of response errors for the indicated response types, calculated across all subjects. Also plotted are Von Mises probability density functions illustrating two different methods of estimating variance in the response error distributions: precision (which is simply the inverse of the error distribution’s circular standard deviation) and concentration (which is a parameter extracted from the mixture model analysis of Bays et al., 2009, wherein a certain proportion of “far miss” responses are labeled as “guesses” and therefore do not affect the concentration parameter).
To determine whether precision varied as a function of attention, we compared responses on one-probe/cue-switch trials and one-probe/cue-repeat trials. On cue-switch trials, the first retrocue did not target the probed memory item; therefore, it was presumably not in the focus of attention during the ensuing delay period, whereas on cue-repeat trials, the probed memory item was selected by both the first and second retrocues, so that it was presumably in the focus of attention for the duration of the trial. As we hypothesized, mnemonic precision was lower on cue-switch trials (M = 2.36 radians–1, SD = 0.99) than on cue-repeat trials (M = 2.88 radians–1, SD = 0.91), t(34) = 2.76, one-tailed p = .005 (see Fig. 3). [Though testing this hypothesis was the primary aim of the study, we also compared precision in the other conditions that were unconfounded by feedback, and found that responses to the first probe (on two-probe trials: M = 2.22 radians–1, SD = 0.78) were less precise than responses on one-probe/cue-repeat trials, t(34) = 4.30, p = .0001, but did not differ from those on one-probe/cue-switch trials, t(34) = 0.78, p = .44.]

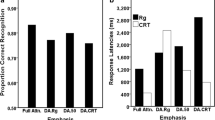
Performance on the Experiment 1 task. On the left, precision is plotted for each response type, corresponding to responses to the first probe on two-probe trials (collapsing across the cue-repeat and cue-switch conditions) and to the only probe on one-probe trials (cue-repeat and cue-switch). On the right, reaction times are plotted for the same response types.
In addition to this primary analysis, we also utilized a model-based approach to examine mnemonic precision without bias from binding errors or guessing (Bays et al., 2009). The concentration parameter κ is the model’s estimate of the variability of response errors, and this value was higher for one-probe, cue-switch trials (M = 16.9, SD = 6.0) than for one-probe, cue-repeat trials (M = 15.2, SD = 6.8), t(34) = 1.72, one-tailed p = .047. We also found significant differences in the proportions of response types on these trials, such that one-probe, cue-repeat trials produced more target responses (M = 97.6 %, SD = 3.3 %) and fewer guesses (M = 3.3 %, SD = 2.8 %) than did one-probe, cue-switch trials [M = 95.7 %, SD = 4.6 %, t(34) = 2.1, p = .044, for target responses; M = 3.3 %, SD = 4.5 %, t(34) = 2.0, p = .050, for guesses]. [Though testing differences between one-probe, cue-switch and one-probe, cue-repeat trials was the primary aim of this study, we also compared responses to the first probe to responses to the one-probe, cue-switch and one-probe, cue-repeat conditions. Briefly, we found a higher proportion of nontarget responses on Probe 1 of two-probe trials (M = 3.9 %, SD = 3.9 %) than on both one-probe, cue-repeat trials (M = 0.8 %, SD = 1.5 %), t(34) = 2.1, p = .0001, and one-probe, cue-switch trials (M = 1.0 %, SD = 1.8 %), t(34) = 3.73, p = .0007. There were also fewer target responses on Probe 1 of two-probe trials (M = 94.7 %, SD = 4.3 %) than on one-probe, cue-repeat trials, t(34) = 2.1, p = .0001, and fewer guesses on Probe 1 of two-probe trials (M = 1.5 %, SD = 2.6 %) than on one-probe, cue-switch trials, t(34) = 2.7, p = .01.]
Subjects responded faster on cue-switch than on cue-repeat trials, t(34) = 3.4, p = .002 (Fig. 3). On the first probe of the two-probe trials, when subjects were retaining two stimuli because the second cue and probe were still to come, responses were slower than both one-probe, cue-repeat and one-probe, cue-switch responses (all ts >3.2, all ps < .0001), when subjects needed to retain only one stimulus because they knew that the uncued stimulus was no longer relevant.
Discussion
Experiment 1 was designed to determine whether the precision of memory recall is reduced for information that is retained in WM but outside the focus of attention. By directly cuing subjects to actively shift their attention to one of two memory items, we were able to compare estimates of precision for items held as AMIs throughout the duration of the trial versus items held as UMIs for a portion of the trial. In line with our prediction, memory items that were moved out of the focus of attention were recalled with less precision than items that remained in the focus of attention throughout the delay period; this result was confirmed by a mixture model analysis (Bays et al., 2009) that accounted for binding errors and guesses. This finding suggests that there is a functional consequence of shifting memory items out of the focus of attention. We elaborate on the theoretical implications of these findings in the General Discussion section.
One might expect that repeated cuing of a memory item, and therefore its continuous retention inside the focus of attention, might result in quicker responses, but instead we saw the opposite effect: Subjects were faster to respond to items held as UMIs during a portion of the trial than to items held as AMIs throughout. We speculate that this reaction time discrepancy might be due to subjects taking more time to fine-tune their responses when they were able to access the higher-quality, more finely grained memory representations retained for AMIs relative to UMIs. Another interpretation, however, is that subjects might have altered their decision criteria between the two trial types, trading accuracy for speed. However, we instructed subjects to prioritize accuracy over speed, irrespective of trial type, and so we think this interpretation is less likely to be the case.
One limitation of our design is that we did not collect eyetracking data—therefore, it is impossible to rule out the possibility that subjects might have disregarded the task instructions and used a preemptive shift in gaze upon receiving the retrocue in order to prepare their responses. If this scenario were true, the observed pattern of results could conceivably be due to the interfering effects of the eye movement on the representation of the unattended memory item. However, we think that this possibility is unlikely, for the following reasons. Subjects were explicitly instructed to maintain central fixation, and in previous studies with very similar paradigms in which eyetracking data were collected, subjects were able to comply with the instruction to maintain fixation, and did not move their eyes in response to the cue (e.g., LaRocque, Riggall, Emrich, & Postle, submitted). Furthermore, in an EEG study with a similar two-step retrocuing paradigm, very few (<1 %) trials were thrown out due to delay-period eye movements (LaRocque et al., 2013).
In tests of visual WM, subjects can flexibly adopt different strategies to aid memory (Lewis-Peacock, Drysdale, & Postle, 2014); one such strategy is to reencode the visual information in a verbal code. We cannot rule out the possibility that subjects might have utilized such verbal reencoding in the present experiment, such as by covert articulation of words such as “up” or “down.” The possibility that subjects might have used verbal encoding, however, does not affect the primary result of this experiment, that there was a loss of mnemonic precision for the item that was not initially cued. Furthermore, many previous studies (Emrich et al., 2013; Ester, Anderson, Serences, & Awh, 2013; Riggall & Postle, 2012; Serences, Ester, Vogel, & Awh, 2009) have decoded remembered directions of motion or grating orientations from neural activity recorded during the delay periods of WM tasks, and have shown stable representations in visual cortex throughout the delay period. This was possible even when training the classifiers only on the stimulus presentation period (Emrich et al., 2013; Riggall & Postle, 2012), providing strong evidence for the persistence of sensory representations. Indeed, the quality of these representations in visual cortex predicted behavioral precision (Emrich et al., 2013; Ester et al., 2013), suggesting that even if subjects are using other coding strategies, a sensory representation persists and is consequential for subjects’ performance of the task.
Having established that UMIs do seem to be represented with reduced precision, we next sought to clarify the mechanisms by which these items are retained in WM. Specifically, we assessed the hypothesis that, upon presentation of the retrocue, subjects engage in strategic reencoding of the UMI because it is to be dropped from focal attention but may be needed for recall later on in the trial. That is, the subject may reencode the UMI in such a manner that it would be more effectively represented in LTM, and the benefit of such strategic reencoding should be observable on a subsequent test of LTM.
Experiment 2
As has been shown in previous studies (LaRocque et al., 2013; Lewis-Peacock et al., 2012; Nee & Jonides, 2008; Rerko & Oberauer, 2013), the short-term retention of UMIs remains high, despite a lack of evidence for their active neural representation. This has been seen with MVPA of fMRI (Lewis-Peacock et al., 2012) and EEG (LaRocque et al., 2013) data, as well as with event-related potentials, for which the contralateral delay activity (CDA) decreases in magnitude coincident with a retrocue prioritizing only a subset of the items being held in WM (Kuo et al., 2012). One possible explanation for these results is that information about UMIs, when they are to be dropped from the focus of attention, is reencoded via a strengthened, LTM-like, medial-temporal lobe (MTL)-dependent structural trace. If true, this privileged status in LTM (relative to AMIs) should be evident on a subsequent LTM test. According to this account, although all items presented as targets at the beginning of a WM trial would be expected to undergo incidental encoding into LTM, UMIs should experience an additional round of LTM encoding triggered by the retrocue. The possibility of such post-retrocue reencoding was first suggested to us by the pattern of neural results from Lewis-Peacock et al. (2012) and LaRocque et al. (2013), wherein evidence for the noncued categories was transiently boosted in response to the retrocue before dropping down to baseline. Strategic reencoding in LTM is one possibility that could account for this pattern of results. Support for this seemingly counterintuitive possibility of additional LTM encoding for UMIs has also emerged from behavioral studies that have shown a decrement in LTM encoding for attended items that were continuously rehearsed during the delay period of an initial WM task, as compared to unattended items that could not be continuously rehearsed (Rose et al., 2014). Any post-retrocue reencoding into LTM of the UMI should manifest as differential subsequent LTM for items maintained inside versus outside the focus of attention during the WM test.
To evaluate whether UMIs may be preferentially encoded in LTM, relative to AMIs, we compared subsequent LTM for AMIs and UMIs from an initial WM task. To that end, subjects first performed a two-step, delayed-recognition task with retrocues (similar to that in LaRocque et al., 2013), using pictures of common objects as the stimuli. Randomly interleaved were “no-test” trials that ended after the first delay period without any memory probe, to permit assessment of WM maintenance on subsequent LTM without the confound of additional cuing or probing during the WM task. To assess whether UMIs were preferentially retained via LTM mechanisms, a surprise, two-alternative forced choice recognition test was administered one week later. We reasoned that, if UMIs were initially retained by reencoding them in LTM more than AMIs are, LTM for UMIs should be superior to LTM for AMIs. This would provide behavioral evidence for the notion that UMIs are initially retained during the WM task because subjects have more effectively reencoded them in LTM than AMIs.
Method
Subjects
A group of 23 healthy subjects (15 female, eight male; average age = 20.3 years) were recruited from the University of Wisconsin–Madison community. Five of the subjects were excluded because they failed to show up for the second session, and one subject was excluded due to computer errors during the task, leaving a final analyzed data set comprising 17 subjects (11 female, six male; average age 20.4 years). All subjects were right handed, had normal or corrected-to-normal color vision, and reported no history of neurological disease or trauma. All subjects provided informed consent according to the Health Sciences Institutional Review Board at the University of Wisconsin–Madison.
We performed a power analysis using data from a pilot experiment on a separate sample of subjects, tested on LTM for items seen on a similar WM task 10 min earlier. We used the LTM accuracy difference between the AMI/AMI and UMI/UMI conditions to estimate the size of an effect that would be most sensitive for detecting differences between conditions. This power analysis indicated that a sample of 14 subjects would yield 90 % power to detect an effect of this size. We collected data from 17 subjects because, for three subjects, computer errors prevented us from collecting data on a psychometric test administered during the same session, but whose results are not reported here.
Materials
The short- and long-term memory tasks were implemented on a 21.5-in. iMac computer screen (1,920 × 1,200 resolution) at 60 Hz using Psychophysics Toolbox (http://psychtoolbox.org; Brainard, 1997) running in MATLAB R2012b (MathWorks, Natick, MA). Automated operation span (OSPAN) and Ravens Advanced Progressive Matrices (RAPM) tests were administered on a Dell laptop using E-Prime 2.0 (http://pstnet.com).
Images of common objects were chosen from a set of previously published stimuli (Brady, Konkle, Alvarez, & Oliva, 2008, 2013; Konkle, Brady, Alvarez, & Oliva, 2010) and from Internet searches using a Google image search. A set of 168 categorically distinct object types was selected, and for each, there were four tokens of that type: three exemplars for use during the WM task, and the fourth—a “state-change” variant of one of the first three—as a foil for the subsequent LTM task. State-change objects were the same as the exemplar objects, but were displayed from a different perspective or with a different configuration of parts (Fig. 4). These stimuli were selected because long-term recognition memory had previously been shown to be excellent after subjects had been shown stimuli in the context of a repeat-detection task (Brady et al., 2008); indeed, subjects could even distinguish subtle “state-change” foils from the original stimuli in a two-alternative forced choice recognition task like the one used in the present study (described below).

Experiments 2 and 3: Tasks and stimulus memory states. (a) Shown is the design for the WM task in Experiments 2 and 3. Subjects saw two object image targets. After a delay, a cue indicated one item to be held in the focus of attention for the first probe. After response feedback, another cue (repeat or switch) indicated the AMI for the second probe. On the no-test trials, the disappearance of the fixation cross indicated the end of the trial prior to the first probe. (b) Shown are the two trial types added for Experiment 3. These trials did not have any cues; the cue period was replaced by an additional delay, so that the probe on the cue-removed trials (Cr) would appear with a timing, with respect to the sample, identical to that for all the other initial probes. On some cue-removed trials, no probe appeared (cue-and-probe-removed trials: CPr); these were the crucial stimuli for the LTM comparison with the UMI/– stimuli. (c) Resultant memory states for the items presented in the each of the WM trial types shown in panels a and b. (d) Four trials from the surprise two-alternative forced choice LTM task. Subjects viewed an image from the WM task alongside a state-changed foil and were required to indicate which they recognized from the previous session.
Procedure
Session 1 (WM task)
The WM task was a two-item delayed-recognition task with two retrocues (Fig. 4a). The paradigm was similar to the task developed by Oberauer (2005) and used by Lewis-Peacock et al. (2012) and LaRocque et al. (2013). Each trial began with the appearance of a white fixation cross (2 s; ~0.5° visual angle). Two images from different categories were presented as to-be-remembered target items on each trial (1 s). One target item appeared on the top and one on the bottom of the screen (images ~12° × 12°, centered ~7° above or below fixation). After an initial delay period (2 s), two lines appeared equiprobably at either the top or the bottom position (0.5 s: ~7° above or below fixation) to cue which item would be tested by the first memory probe. After a second delay period (2 s), on the majority of trials (52 %, n = 44) a memory probe appeared in the cued position (cues were 100 % valid) for 1 s. Subjects were required to respond within 3 s of probe onset with a numeric keypress, either “1” to indicate a match or “2” to indicate a nonmatch. Matches were identical to the target, and nonmatches were a different exemplar from the same category as the target. Feedback was provided after each response by changing the color of the fixation cross to green, for correct responses, or red, for incorrect responses. If the subject did not respond within the time provided, the task progressed without feedback, and that response was excluded from further analysis. After the first response period, another cue (0.5 s) indicated which item the second memory probe would test. The originally cued item was again cued and probed on cue-repeat trials (26 %, n = 22); the initially uncued item was cued and probed on cue-switch trials (26 %, n = 22). The inclusion of cue-switch trials discouraged subjects from simply forgetting the initially uncued memory item, because it remained possible that it could be the target of the second probe.
The remainder of the trials (48 %, n = 40) ended after the second delay, before the first memory probe would be expected to appear (no-test trials). These trials were included so as to afford a cleaner test of the effect of maintaining cued versus uncued items in STM on subsequent LTM. These trials were identical to the other trials up to the point of the first memory probe. Terminating the trials before the first memory probe allowed us to control for any effect of initial testing on subsequent LTM. Thus, any difference between the subsequent LTM for cued and uncued items from no-test trials could be attributed to a difference in the way that the items were retained during the STM task.
Trials were separated by a 2-s ITI. The subjects performed four blocks of 21 trials each, and trials were counterbalanced for cue location (top vs. bottom). The stimulus presentation order was randomized across subjects, such that each object image had an equal chance to appear in either position (top vs. bottom) and in each trial type (cue repeat vs. cue switch vs. no test).
Together, these trial types created six possible “memory states” (one for each of the two items in the three different trial types), classified by whether and when they were cued. Because we assumed that a retrocued item is selected by the focus of attention, whereas an uncued memory item is not, we will refer to the status of the items in the STM task with the AMI/UMI terminology. An item in a cue-repeat trial could be an AMI/AMI or a UMI/UMI; an item in a cue-switch trial could be an AMI/UMI or a UMI/AMI; and an item in a no-test trial could be an AMI/– or a UMI/– (Fig. 4c).
Session 2 (Surprise LTM task)
Subjects were not informed of any subsequent LTM task during the study; they were asked to return seven to eight days later for what was simply described as a “second session.” First, the subjects completed the OSPAN and RAPM tasks for another purpose. The mean score for absolute OSPAN was 41.29 (SD = 18.54), and the mean score for RAPM was 9.28 correct (SD = 2.32) (RAPM was not obtained for three subjects due to a computer error). They were then informed that they would be tested on their recognition of objects that had been presented in the previous session, and this was done via a two-alternative forced choice recognition memory task (Fig. 4d). Each trial began with the appearance of a white fixation cross with object images on both its left and right sides. One of these two images was identical to a target from the WM task in Session 1, whereas the other image was a state-transformed version of the same object (e.g., antique phone with the earpiece on vs. off the hook; see Fig. 4 or Brady et al., 2013, for further details). Displaying images to the left and right of fixation prevented the images from receiving any benefit from appearing in the same location as during the STM task (top or bottom). Subjects indicated which object they recognized from the STM task with a numeric keypad. If subjects did not recognize either item, they were required to guess. Subjects could not advance to the next trial until they provided a response, at which time they received feedback in the same manner as the STM task. Trials were separated by a 1-s ITI; subjects completed two blocks of 84 trials each (one trial for each object from Session 1). The stimulus presentation order for the LTM task was randomized.
Results
Session 1 (WM task)
We used dependent-samples t tests to compare the STM performance on Probe 1, Probe 2 of cue-repeat trials, and Probe 2 of cue-switch trials. Although no significant differences in performance were observed, there was a trend for performance to be superior on Probe 2, cue-repeat responses (M = 89.3 %, SD = 8.5 %) relative to Probe 2, cue-switch responses (M = 85.3 %, SD = 10.2 %), t(16) = 1.65 p = .12. Reaction times for responses to the first probe were significantly faster for correct (M = 0.73 s, SD = 0.13 s) than for incorrect (M = 0.83 s, SD = 0.21 s) responses, t(16) = 2.95, p < .01.
Session 2 (LTM task)
The logic of this study was that if UMIs were retained in LTM during the WM task, one might expect to see better LTM performance in Session 2 for UMI/– stimuli than for AMI/– stimuli. In contrast to this prediction, however, LTM performance was actually greater for AMI/– stimuli (M = 61.9 %, SD = 11.4 %) than for UMI/– stimuli (M = 57.7 %, SD = 10.0 %). Our original plan was to use a one-tailed t test for UMI/– greater than AMI/–, in order to be maximally sensitive to any LTM benefit for UMIs; although we in fact saw the opposite pattern, we still include this test because it was planned, t(16) = 1.38, p = .91 (Fig. 5a).

Experiments 2 and 3: Performance on the surprise LTM task. (a) Experiment 2 LTM recognition accuracy for the six different memory states is plotted (Fig. 4a; legend at bottom right). Contrary to our hypothesis, no significant statistical difference emerged between AMI/– and UMI/– items. (b) Scatterplot of LTM performance illustrating the LTM benefit of cuing attention toward an item in the STM task. (c) Experiment 3 LTM recognition accuracy for nine possible memory states (Figs. 4a and b; legend at bottom right). Replicating Experiment 2, no significant statistical difference was apparent between LTM for AMI/– and UMI/– items. Additionally, LTM for UMI/– items was not significantly greater than that for CPr items.
Despite the null finding for the contrast of principal theoretical interest, LTM performance did differ as a function of WM-task status for other conditions. For example, we observed significant differences between AMI/AMIs (M = 71.9 %, SD = 8.1 %) and all other conditions: UMI/UMI (M = 55.6 %, SD = 8.3 %), t(16) = 6.10, p < .01; AMI/UMI (M = 64.2 %, SD = 10.3 %), t(16) = 2.42, p < .05; UMI/AMI (M = 66.8 %, SD = 9.3 %), t(16) = 2.12, p = .05; AMI/–, t(16) = 3.24, p < .01; and UMI/–, t(16) = 4.74, p < .01. Additionally, performance for UMI/UMIs was significantly lower than in all other conditions except UMI/– [AMI/UMI, t(16) = 2.68, p < .05; UMI/AMI, t(16) = 3.52, p < .01; AMI/–, t(16) = 2.28, p < .05]. Performance was significantly higher for UMI/AMIs than for UMI/–s, t(16) = 3.55, p < .01.
Discussion
In Experiment 2 we tested whether items that were initially maintained inside (AMIs) or outside (UMIs) the focus of attention during an STM task were differentially encoded in LTM. Were this the case, one might expect superior performance for UMI/– stimuli relative to AMI/– stimuli on a subsequent test of LTM recognition. However, despite excellent LTM recognition for all stimulus types, we found no evidence of superior LTM for UMIs. In fact, LTM performance was numerically higher for AMIs than for UMIs from the no-test condition. Thus, this experiment provides no evidence that, during the WM task, subjects simply transferred UMIs from WM and utilized a retrocue-induced recoding into LTM for their short-term retention. This interpretation requires caution, of course, because it derives from a null finding (albeit one generated in a study that was powered at greater than 90 %). This fact, combined with another aspect of the results from Experiment 2, prompted Experiment 3, as a replication and extension.
The factor in Experiment 2 that had the biggest effect on subsequent LTM was the number of times that an item was cued during the WM task (Fig. 5b). This is in general agreement with the notion that initial processing in WM (such as prioritization of memory items via retention in the focus of attention) leads to greater LTM encoding (Ranganath, Cohen, & Brozinsky, 2005). However, it also suggests an alternative account of the lack of a difference in LTM for UMI/– items and AMI/– items: It might be that the retrocue that led to the prioritization of AMIs also enhanced their LTM encoding relative to stimuli that were not cued. If true, this could explain the failure to observe enhanced LTM for UMIs relative to AMIs. Therefore, Experiment 3 included WM task conditions that would enable a comparison of LTM for UMIs to LTM for items from WM trials without any retrocues. This would remove any potential cue-induced LTM enhancement and would provide a cleaner test of the evidence for privileged LTM encoding for UMIs.
Experiment 3
Because the interpretation of Experiment 2 relied on the interpretation of a null result, and because of the possibly confounding effects of the differential cuing in that experiment, Experiment 3 was designed as a replication that would also include a contrast without cuing confounds. Therefore, we included trials in the initial WM task in which no retrocues were provided, in addition to all of the trial types from Experiment 2, and again tested subjects’ LTM with a surprise recognition test for the items from the WM task.
Method
Subjects
A group of 20 healthy subjects (10 female, 10 male; average age =24.2 years) were recruited from the University of Wisconsin–Madison community. Of these subjects, two were excluded because of computer errors during the task, and two were excluded due to failure to follow the task instructions, leaving a final analyzed data set comprising 16 subjects. All of the subjects were right-handed, had normal or corrected-to-normal color vision, and reported no history of neurological disease or trauma. All subjects provided informed consent according to the Health Sciences Institutional Review Board at the University of Wisconsin–Madison.
Materials
All tasks were implemented on a 21.5-in. iMac computer screen (1,920 × 1,200 resolution) at 60 Hz. The memory tasks were implemented using the Psychophysics Toolbox (http://psychtoolbox.org; Brainard, 1997) running in MATLAB R2012b (MathWorks, Natick, MA). The distraction task, Pictures Mania Deluxe (http://racoondigi.com), was downloaded via the App Store application (Apple Inc.). Subjects were tested individually, seated approximately 60 cm from the display screen. The images for the STM and LTM tasks were the same as those used in Experiment 2 (Fig. 4), and the size and shape of the stimuli, fixation crosses, and cues were identical to those used in Experiment 2.
Procedure
Adapted WM task
This experiment included trials identical to those from Experiment 2—cue-repeat (16 %, n = 11), cue-switch (16 %, n = 11), and no-test (32 %, n = 22) (see Fig. 4a)—plus two additional conditions (Fig. 4b). Several trials (18 %, n = 12) had an unfilled delay (4.5 s) after the offset of the target items and ended at the time that the first memory probe would be expected to appear. These trials had the cue and probe removed (“CPr” trials), and items from these trials would therefore provide an AMI comparison group that was unconfounded by any cue-induced gain in LTM performance. To ensure that the absence of the cue would not reveal to subjects that no test would occur, we included as a final trial type (18 %, n = 12) cue-removed (“Cr”) trials that included the same unfilled delay (4.5 s), but followed by a memory probe (1 s). Subjects had a total of 2 s to respond in the same fashion as in the cue-repeat and cue-switch trials. The similarities and differences between the trial types from Experiments 2 and 3 are illustrated in Fig. 4. There was a probability that at least one of the items would be tested (p = .5) or that both items would be tested (p = .32). Trials were separated by a brief ITI (2 s). Subjects performed a single block of 68 trials, which were counterbalanced for cue location (top vs. bottom). The presentation order of the target images was randomized across subjects, such that each object image had an equal chance to appear in either position (top vs. bottom) and in each trial type (cue repeat vs. cue switch vs. no test vs. CPr vs. Cr vs. dual task).
The adapted WM task created nine possible “memory states,” according to what trial type each stimulus was presented during, and whether it was cued or probed. (Note that CPr trials only had one state that a target item could be in, since neither target image was cued or probed.) As in Experiment 2, an item in a cue-repeat trial could be an AMI/AMI or a UMI/UMI, an item in a cue-switch trial could be an AMI/UMI or a UMI/AMI, and an item in a no-test trial could be an AMI/– or a UMI/–. Because only one memory state corresponded to the two stimuli on CPr trials, we simply label them by their trial names. Items on Cr trials could either be probed or unprobed (Fig. 4b).
Distraction task
Subjects were then informed that they would be playing a spot-the-difference game for 40 min (with an optional break at 20 min). In this task, subjects were required to examine two simultaneously presented images and identify differences between them by moving the mouse cursor to the differing spot and clicking. Subjects played the challenge mode of Pictures Mania Deluxe. A researcher remained in the testing room recording the score each time that the subject finished a game. The duration of the distraction was chosen to provide sufficient interference that performance on the subsequent surprise LTM task would be sufficiently below ceiling. We chose to have both the WM and LTM tasks in one session in order to reduce loss of data due to subjects not showing up for the LTM session 1 week later, as had been the case for five subjects in Experiment 2.
Surprise LTM task
Subjects completed a surprise two-alternative forced choice recognition memory task identical to the LTM task from Session 2 of Experiment 2 (Fig. 4d). Subjects completed two blocks of 84 trials each (136 of these trials included an object from the WM tasks). The stimulus presentation order for the LTM task was randomized. All subjects reported that they had not expected the LTM task.
Results
WM tasks
We used dependent-samples t tests to compare STM performance during the WM task. No statistically significant pairwise differences were shown in the performance between Probe 2, cue-repeat responses (M = 91.5 %, SD = 9.7 %), Probe 2, cue-switch responses (M = 88 %, SD = 12.2 %), or Probe 1 responses (M = 91.8 %, SD = 5.6 %; all ts < 1.11, all ps > .48). For correct responses, reaction times for Probe 2, cue-repeat responses (M = 0.71 s, SD = 0.12 s) were significantly faster than either Probe 1 responses (M = 0.76 s, SD = 0.15 s), t(15) = 2.79, p < .05, or Probe 2, cue-switch responses (M = 0.78 s, SD = 0.16 s), t(15) = 2.56, p < .05. All other pairwise comparisons (including those with the Cr trials (accuracy M = 88.0 %, SD = 10.1 %) were nonsignificant.
LTM task
The primary goal of this experiment was to test the hypothesis that UMIs may be represented in a privileged manner in LTM, while accounting for any effects that cuing might have on subsequent LTM performance. In a replication of the finding from Experiment 2, LTM performance was numerically lower with UMI/– items (M = 73.0 %, SD = 14.5 %) than with AMI/– items (M = 75.3 %, SD = 7.8 %); as in Experiment 2, we still report the planned one-tailed t test for UMI/– greater than AMI/– accuracy, t(15) = 0.70, one-tailed p = .75 (Fig. 5c). If this null finding were a result of the cue’s influence, we should observe enhanced LTM performance for UMI/– stimuli relative to CPr items (M = 72.1 %, SD = 10.3 %). However, this difference also failed to achieve significance, t(15) = 0.27, one-tailed p = .40.
We found significant differences between the performance for the AMI/AMI (M = 86.4 %, SD = 13.3 %) stimuli and several other memory states: UMI/UMI (M = 72.2 %, SD = 15.7 %), t(15) = 3.18, p < .01; AMI/– (M = 75.3 %, SD = 7.8 %), t(15) = 2.90, p < .05; UMI/– (M = 73 %, SD = 14.5 %), t(15) = 3.13, p < .01; and CPr (M = 72.1 %, SD = 10.3 %), t(15) = 3.64, p < .01. Performance for CPr items was also significantly worse than performance for both UMI/AMI items (M = 81.3 %, SD = 15.0 %), t(15) = 2.52, p < .05, and Cr, probed items (M = 78.7 %, SD = 12.9 %), t(15) = 3.65, p < .01. No significant pairwise differences were apparent in reaction times for correct responses in the LTM task, though for AMI/– items only, correct responses (M = 1.32 s, SD = 0.21 s) were significantly faster than incorrect responses (M = 1.54 s, SD = 0.42 s), t(15) = 2.85, p < .05.
Discussion
The results of Experiment 3 exactly replicated those of Experiment 2, in that LTM performance for UMIs was not greater than LTM performance for AMIs. We achieved this result with a procedure that did not confound attentional status with cuing. Thus, even when they were compared with stimulus items from those trials without any retrocues, UMIs did not show any LTM enhancement. This result strengthens the case that UMIs are not preferentially encoded in LTM during the retrocuing WM task.
General discussion
We have taken two approaches in our effort to better characterize memory items retained outside the focus of attention (UMIs). First, we have shown a loss in recall precision for UMIs relative to AMIs, using a task in which subjects had to recall the direction of motion of moving-dot arrays. Second, we have shown that there was no subsequent LTM benefit for stimuli that had been retained as UMIs in a prior STM task. Here, we consider the theoretical implications of these findings.
Unattended memory items are associated with reduced precision
The retrocue-controlled allocation of attention made explicit which of two detailed sensory representations subjects had to prioritize for the impending memory probe. It remains unclear whether (and to what extent) attention-driven prioritization of some memory items occurs in paradigms without such control (via retrocues) of attention. The present findings point to a tradeoff inherent in controlling the scope of the focus of attention. It has been shown many times that subjects experience a reaction time benefit when they can narrow the focus of attention by prioritizing a subset of remembered items as AMIs (Griffin & Nobre, 2003; Oberauer, 2001, 2002, 2005; Pertzov, Bays, Joseph, & Husain, 2013). The present results show that this benefit comes at the cost of reduced fidelity for the memory items that are not selected—the UMIs.
Our demonstration of a drop in precision for UMIs versus AMIs contrasts with recent results that have shown no drop in performance for UMIs in a color-in-location recognition task (Rerko & Oberauer, 2013).Footnote 1 There are several possible reasons for the discrepancy. First, we used an estimate of behavioral precision taken from a free recall response, as opposed to a match/nonmatch recognition judgment. It is very possible that the effect of retaining an item outside the focus of attention is to reduce the fidelity of the mnemonic representation, but not to a degree that would impair yes/no recognition performance. The timing of the experimental design also differed between the present study and that of Rerko and Oberauer. In the previous study, the condition most comparable to our UMI condition was a trial in which two sequential retrocues prioritized different items from an array of six items. The subsequent memory probe targeted the item indicated by the second retrocue. However, the time between the onsets of the first and second retrocues was only 0.6 s, whereas in our Experiment 1 it was 7.5 s. Previously, researchers have estimated that it takes approximately 1.25–1.75 s after the onset of a retrocue for the behavioral effect (Oberauer, 2001) and the neural evidence (LaRocque et al., 2013) of an uncued memory item to dissipate; in short, it may take longer than a second for an uncued memory item to become a UMI. In Rerko and Overauer’s design, because the second retrocue occurred only 0.6 s after the first, there may not have been time for the first retrocue to take effect before the onset of the second retrocue. Perhaps lengthening the intercue interval would unmask a recognition performance deficit for UMIs. However, it is also possible that only in tasks with a free recall response, and the consequent ability to assay the loss of fidelity, would one find behavioral consequences for an item being retained as a UMI.
A recent study revealed a similar effect on precision by using priming and the recency effect (Zokaei, Manohar, Husain, & Feredoes, 2014). In this study, subjects were asked to remember the direction of motion of two differently colored arrays of dots. In one experiment, the stimuli were positioned above and below the fixation cross, and in the subsequent delay period, subjects had to respond to whether the color of the fixation cross matched the color of the top or the bottom memory item. Precision was higher when the probed memory item had the same color as the fixation cross. In a second experiment, the stimuli were presented sequentially, and precision was higher when the most recently presented item was probed. The authors interpreted their manipulations (incidental color congruency and recency) as manipulations of attention, and, indeed, subjects may have always allocated their attention to the color-matched memory item and the most recently presented memory item. However, in contrast to our design, subjects were not explicitly instructed to allocate their attention in this manner. Therefore, it is difficult to know whether their results were due to differences in the allocation of attention or to more automatic processes (a color-priming effect and a recency effect). In our view, the present results are broadly consistent with those of Zokaei et al. (2014), but due to our explicit manipulation of attention with retrocues, the present results permit a more direct association between different attentional states in memory and mnemonic precision.
The primary question raised by these results is that of mechanism: What exactly causes the decrease in precision for UMIs? Candidate processes include the initial cue-induced deselection by the focus of attention, the retention of the items outside the focus of attention, or the reselection of the items by the focus of attention after the second retrocue, on cue-switch trials. Understanding how these different processes may affect the precision of subsequent recall remains an important topic for future study.
Unattended memory items are not differentially represented in LTM
The results of Experiment 2 are clear, in that they demonstrate no privileged encoding of UMIs into LTM relative to AMIs—a finding that argues against additional recruitment of LTM mechanisms (beyond incidental encoding) to support the short-term retention of UMIs. Experiment 3 replicated these results, and also showed that even when compared with never-cued memory items, UMIs do not exhibit enhanced encoding in LTM.
A substantial body of work has demonstrated that the depth of processing on an initial WM task has a strong effect on subsequent LTM (Craik, 1970; Craik et al., 1970; Lockhart, Craik, & Jacoby, 1976; Rose et al., 2014). Yet, even for the critical comparison from Experiment 3 (UMI/– vs. Cpr), we observed no difference in LTM performance. Thus, it seems that a retrocue is not sufficient to engage the sort of deeper processing that can enable UMIs to be subsequently remembered better than AMIs (Rose et al., 2014). We did observe that LTM performance increased with the number of times that an item was cued (Fig. 5b), which is broadly consistent with suggestions that the amount of time spent maintaining memory items during a WM task impacts subsequent LTM (Atkinson & Shiffrin, 1968; Ranganath et al., 2005; Rundus, Loftus, & Atkinson, 1970).
Notably, performance was reliably above chance for all of the stimulus types (Figs. 5a, c), indicating that incidental encoding in LTM occurred for all memory items in the initial WM task. Would such incidental encoding in LTM be sufficient to allow accurate short-term retention of UMIs, as has been shown here and in many previous studies (LaRocque et al., 2013; Lewis-Peacock et al., 2012; Oberauer, 2005)? We suspect that such incidental, long-lasting encoding may play a role, but that it is not the primary mechanism by which items are retained in STM, provided that STM capacity is not exceeded and maintenance of the memoranda is not subjected to interference. After all, in the context of an STM task, subjects must try to remember the stimuli presented on each particular trial while also trying to prevent the intrusion of items seen on previous trials. If all such items are incidentally encoded in LTM, there must be a complementary, trial-specific code that allows the correct selection of the UMI from the current trial, and not the incorrect selection of items from previous trials. Oberauer (2001) has shown that UMIs are more slowly rejected in a recognition paradigm than completely novel stimuli, up to 5 s after the retrocue. UMIs are therefore evident in reaction times but not in patterns of neural activity, and their encoding is sufficiently durable to allow subjects to reinstate category-specific neural activity patterns and to accurately respond to a recognition probe after a delay greater than 10 s (LaRocque et al., 2013; Lewis-Peacock et al., 2012). Collectively, these findings are suggestive of a passive mnemonic trace for UMIs.
Although passive mnemonic traces are most commonly associated with LTM, our results are more consistent with the possibility that the passive retention of UMIs may involve different physiological processes. It is well-established that long-term potentiation (LTP) is a primary molecular substrate of LTM (Morris, Anderson, Lynch, & Baudry, 1986). However, another form of synaptic potentiation, which lasts on the order of a minute, is appropriately named short-term potentiation (STP; Erickson, Maramara, & Lisman, 2009). At the systems level, STM by transient synaptic modification has been modeled with a “matched filter” mechanism, whereby the information stored in a network of transiently potentiated synapses could be reinstated as a pattern of neural activity by a subsequent sweep of activation. In this scheme, the transiently potentiated synapses can act as a matched filter, thereby providing an enhanced neural response to inputs matching the input that first instantiated the synaptic weights (Sugase-Miyamoto, Liu, Wiener, Optican, & Richmond, 2008). Evidence for a similar scheme has also come from a multivariate analysis of neuronal activity in prefrontal cortex, in which “implicit” changes in synaptic weights adaptively code moment-to-moment changes in behavioral context (Stokes et al., 2013). It is possible that such an STP-like mechanism may exist concurrently with LTP, and that this transient potentiation underlies the retention of UMIs—hence, our inability to see an LTM benefit for UMIs relative to AMIs. To address this hypothesis, it will be necessary to actually perturb the system—via transcranial magnetic stimulation, for example—while the potentiated weights are still present, and see if the response to the perturbation differs according to the information that is being passively retained (i.e., if the perturbation produces a UMI-specific response). Only with such methods will it be possible to pin down the neural fates of information represented in different states in WM.
References
Atkinson, R. C., & Shiffrin, R. M. (1968). Human memory: A proposed system and its control processes. In G. H. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 2, pp. 89–195). New York, NY: Academic Press. doi:10.1016/s0079-7421(08)60422-3
Baddeley, A. D., & Hitch, G. (1974). Working memory. In G. H. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 8, pp. 47–89). New York, NY: Academic Press. doi:10.1016/S0079-7421(08)60452-1
Bays, P. M., Catalao, R. F. G., & Husain, M. (2009). The precision of visual working memory is set by allocation of a shared resource. Journal of Vision, 9(10), 7.1–711.
Bays, P. M., & Husain, M. (2008). Dynamic shifts of limited working memory resources in human vision. Science, 321, 851–854. doi:10.1126/science.1158023
Brady, T. F., Konkle, T., Alvarez, G. A., & Oliva, A. (2008). Visual long-term memory has a massive storage capacity for object details. Proceedings of the National Academy of Sciences, 105, 14325–14329. doi:10.1073/pnas.0803390105
Brady, T. F., Konkle, T., Alvarez, G. A., & Oliva, A. (2013). Real-world objects are not represented as bound units: Independent forgetting of different object details from visual memory. Journal of Experimental Psychology: General, 142, 791–808. doi:10.1037/a0029649
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Cowan, N. (1988). Evolving conceptions of memory storage, selective attention, and their mutual constraints within the human information-processing system. Psychological Bulletin, 104, 163–191. doi:10.1037/0033-2909.104.2.163
Cowan, N. (1995). Attention and memory: An integrated framework. New York, NY: Oxford University Press.
Craik, F. I. M. (1970). The fate of primary memory items in free recall. Journal of Verbal Learning and Verbal Behavior, 9, 143–148. doi:10.1016/S0022-5371(70)80042-1
Craik, F. I. M., Gardiner, J. M., & Watkins, M. J. (1970). Further evidence for a negative recency effect in free recall. Journal of Verbal Learning and Verbal Behavior, 9, 554–560. doi:10.1016/S0022-5371(70)80101-3
Emrich, S. M., Riggall, A. C., LaRocque, J. J., & Postle, B. R. (2013). Distributed patterns of activity in sensory cortex reflect the precision of multiple items maintained in visual short-term memory. Journal of Neuroscience, 33, 6516–6523. doi:10.1523/JNEUROSCI. 5732-12.2013
Erickson, M. A., Maramara, L. A., & Lisman, J. (2009). A single brief burst induces GluR1-dependent associative short-term potentiation: A potential mechanism for short-term memory. Journal of Cognitive Neuroscience, 22, 2530–2540. doi:10.1162/jocn.2009.21375
Ester, E. F., Anderson, D. E., Serences, J. T., & Awh, E. (2013). A neural measure of precision in visual working memory. Journal of Cognitive Neuroscience, 25, 754–761. doi:10.1162/jocn_a_00357
Griffin, I. C., & Nobre, A. C. (2003). Orienting attention to locations in internal representations. Journal of Cognitive Neuroscience, 15, 1176–1194. doi:10.1162/089892903322598139
Konkle, T., Brady, T. F., Alvarez, G. A., & Oliva, A. (2010). Conceptual distinctiveness supports detailed visual long-term memory for real-world objects. Journal of Experimental Psychology: General, 139, 558–578. doi:10.1037/a0019165
Kuo, B.-C., Stokes, M. G., & Nobre, A. C. (2012). Attention modulates maintenance of representations in visual short-term memory. Journal of Cognitive Neuroscience, 24, 51–60. doi:10.1162/jocn_a_00087
LaRocque, J. J., Lewis-Peacock, J. A., Drysdale, A. T., Oberauer, K., & Postle, B. R. (2013). Decoding attended information in short-term memory: An EEG study. Journal of Cognitive Neuroscience, 25, 127–142.
LaRocque, J. J., Lewis-Peacock, J. A., & Postle, B. R. (2014). Multiple neural states of representation in short-term memory? It’s a matter of attention. Frontiers in Human Neuroscience, 8, 5. doi:10.3389/fnhum.2014.00005
Lepsien, J., & Nobre, A. C. (2007). Attentional modulation of object representations in working memory. Cerebral Cortex, 17, 2072–2083. doi:10.1093/cercor/bhl116
Lewis-Peacock, J. A., Drysdale, A. T., Oberauer, K., & Postle, B. R. (2012). Neural evidence for a distinction between short-term memory and the focus of attention. Journal of Cognitive Neuroscience, 24, 61–79. doi:10.1162/jocn_a_00140
Lewis-Peacock, J. A., Drysdale, A. T., & Postle, B. R. (2014). Neural evidence for the flexible control of mental representations. Cerebral Cortex. doi:10.1093/cercor/bhu130
Lockhart, R. S., Craik, F. I. M., & Jacoby, L. (1976). Depth of processing, recognition and recall: Some aspects of a general memory system. In J. Brown (Ed.), Recall and recognition (pp. 75–102). London, UK: Wiley.
McElree, B. (1998). Attended and non-attended states in working memory: Accessing categorized structures. Journal of Memory and Language, 38, 225–252. doi:10.1006/jmla.1997.2545
Morris, R., Anderson, A., Lynch, G., & Baudry, B. (1986). Selective impairment of learning and blockade of long term potentiation by an N-methyl-D-aspartate receptor antagonist, APV-5. Nature, 319, 774–776.
Nee, D. E., & Jonides, J. (2008). Neural correlates of access to short-term memory. Proceedings of the National Academy of Sciences, 105, 14228–14233. doi:10.1073/pnas.0802081105
Nee, D. E., & Jonides, J. (2011). Dissociable contributions of prefrontal cortex and the hippocampus to short-term memory: Evidence for a 3-state model of memory. NeuroImage, 54, 1540–1548. doi:10.1016/j.neuroimage.2010.09.002
Nee, D. E., & Jonides, J. (2013). Neural evidence for a 3-state model of visual short-term memory. NeuroImage, 74, 1–11. doi:10.1016/j.neuroimage.2013.02.019
Nobre, A. C., Coull, J. T., Maquet, P., Frith, C. D., Vandenberghe, R., & Mesulam, M. M. (2004). Orienting attention to locations in perceptual versus mental representations. Journal of Cognitive Neuroscience, 16, 363–373. doi:10.1162/089892904322926700
Oberauer, K. (2001). Removing irrelevant information from working memory: A cognitive aging study with the modified Sternberg task. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27, 948–957. doi:10.1037/0278-7393.27.4.948
Oberauer, K. (2002). Access to information in working memory: Exploring the focus of attention. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28, 411–421. doi:10.1037/0278-7393.28.3.411
Oberauer, K. (2005). Control of the contents of working memory—A comparison of two paradigms and two age groups. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 714–728. doi:10.1037/0278-7393.31.4.714
Oberauer, K., & Hein, L. (2012). Attention to information in working memory. Current Directions in Psychological Science, 21, 164–169. doi:10.1177/0963721412444727
Pertzov, Y., Bays, P. M., Joseph, S., & Husain, M. (2013). Rapid forgetting prevented by retrospective attention cues. Journal of Experimental Psychology: Human Perception and Performance, 39, 1224–1231. doi:10.1037/a0030947
Ranganath, C., Cohen, M. X., & Brozinsky, C. J. (2005). Working memory maintenance contributes to long-term memory formation: Neural and behavioral evidence. Journal of Cognitive Neuroscience, 17, 994–1010. doi:10.1162/0898929054475118
Rerko, L., & Oberauer, K. (2013). Focused, unfocused, and defocused information in working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 1075–1096. doi:10.1037/a0031172
Riggall, A., & Postle, B. R. (2012). The relationship between working memory storage and elevated activity as measured with functional magnetic resonance imaging. Journal of Neuroscience, 32, 12990–12998.
Rose, N. S., Buchsbaum, B. R., & Craik, F. I. M. (2014). Short-term retention of a single word relies on retrieval from long-term memory when both rehearsal and refreshing are disrupted. Memory & Cognition, 42, 689–700. doi:10.3758/s13421-014-0398-x
Rundus, D., Loftus, G. R., & Atkinson, R. C. (1970). Immediate free recall and three-week delayed recognition. Journal of Verbal Learning and Verbal Behavior, 9, 684–688.
Serences, J. T., Ester, E. F., Vogel, E. K., & Awh, E. (2009). Stimulus-specific delay activity in human primary visual cortex. Psychological Science, 20, 207–214. doi:10.1111/j.1467-9280.2009.02276.x
Stokes, M. G., Kusunoki, M., Sigala, N., Nili, H., Gaffan, D., & Duncan, J. (2013). Dynamic coding for cognitive control in prefrontal cortex. Neuron, 78, 364–375. doi:10.1016/j.neuron.2013.01.039
Sugase-Miyamoto, Y., Liu, Z., Wiener, M. C., Optican, L. M., & Richmond, B. J. (2008). Short-term memory trace in rapidly adapting synapses of inferior temporal cortex. PLoS Computational Biology, 4, e1000073. doi:10.1371/journal.pcbi.1000073
Trapp, S., & Lepsien, J. (2012). Attentional orienting to mnemonic representations: Reduction of load-sensitive maintenance-related activity in the intraparietal sulcus. Neuropsychologia, 50, 2805–2811. doi:10.1016/j.neuropsychologia.2012.08.003
Wilken, P., & Ma, W. (2004). A detection theory account of change detection. Journal of Vision, 4(12), 1120–1135. doi:10.1167/4.12.11
Zhang, W., & Luck, S. J. (2008). Discrete fixed-resolution representations in visual working memory. Nature, 453, 233–235. doi:10.1038/nature06860
Zokaei, N., Gorgoraptis, N., Bahrami, B., Bays, P. M., & Husain, M. (2011). Precision of working memory for visual motion sequences and transparent motion surfaces. Journal of Vision, 11(14), 2:1–18. doi:10.1167/11.14.2
Zokaei, N., Manohar, S., Husain, M., & Feredoes, E. (2014). Causal evidence for a privileged working memory state in early visual cortex. Journal of Neuroscience, 34, 158–162. doi:10.1523/JNEUROSCI. 2899-13.2014
Author note
We thank Rhodri Cusack for conversations that led to Experiment 2, Nelson Cowan and Emma Meyering for helpful suggestions implemented in Experiment 3, and an anonymous reviewer for helpful comments regarding the theoretical framing of Experiments 2 and 3. This work was supported by National Institutes of Health Grant Numbers MH064498 and MH095984, to B.R.P., and CNTP T32 EB011434 and MSTP T32 GM008692 funding, for J.J.L.
Author information
Authors and Affiliations
Corresponding author
Additional information
Adam S. Eichenbaum and Michael J. Starrett contributed equally to this work.
Rights and permissions
About this article

Cite this article
LaRocque, J.J., Eichenbaum, A.S., Starrett, M.J. et al. The short- and long-term fates of memory items retained outside the focus of attention. Mem Cogn 43, 453–468 (2015). https://doi.org/10.3758/s13421-014-0486-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-014-0486-y