
Abstract
An important, but as yet incompletely resolved, issue is whether spatial knowledge acquired during navigation differs significantly from that acquired by studying a cartographic map. This, in turn, is relevant to understanding the generalizability of the concept of a “cognitive map,” which is often likened to a cartographic map. On the basis of previous theoretical proposals, we hypothesized that route and cartographic map learning would produce differences in the dynamics of acquisition of landmark-referenced (allocentric) knowledge, relative to view-referenced (egocentric) knowledge. We compared this model with competing predictions from two other models linked to route versus map learning. To test these ideas, participants repeatedly performed a judgment of relative direction (JRD) and a scene- and orientation-dependent pointing (SOP) task while undergoing route and cartographic map learning of virtual spatial environments. In Experiment 1, we found that map learning led to significantly faster improvements in JRD pointing accuracy than did route learning. In Experiment 2, in contrast, we found that route learning led to more immediate and greater improvements overall in SOP accuracy, as compared to map learning. Comparing Experiments 1 and 2, we found a significant three-way interaction effect, indicating that improvements in performance differed for the JRD versus the SOP task as a function of route versus map learning. We interpreted these findings as suggesting that the learning modality differentially affects the dynamics of how we utilize primarily landmark-referenced versus view-referenced knowledge, suggesting potential differences in how we utilize spatial representations acquired from routes versus cartographic maps.
Similar content being viewed by others


Introduction
How we acquire spatial knowledge of our surrounding environment is critical to understanding how we navigate and orient ourselves within the world. During navigation, we often employ routes that we have learned during previous exploration of an environment to arrive at our intended goal, referred to as “route knowledge.” We may also employ a more “map”-like representation of the environment, often referred to as a “cognitive map,” allowing us to make inferences about the directions and distances of landmarks within the environment (O’Keefe & Nadel, 1978; Siegel & White, 1975; Tolman, 1948). We may acquire map-like knowledge either through extensive navigation of an environment or by studying a cartographic map, the result of which is often referred to as “survey knowledge” (Appleyard, 1970; Siegel & White, 1975; Thorndyke & Hayes-Roth, 1982; Wolbers & Büchel, 2005). This dichotomy between route and survey knowledge forms the underpinning of a number of different influential theoretical models in spatial cognition (O’Keefe & Nadel, 1978; Siegel & White, 1975) and in cognitive neuroscience (Hartley, Maguire, Spiers, & Burgess, 2003; Iaria, Petrides, Dagher, Pike, & Bohbot, 2003; Packard & McGaugh, 1996).
Although there is generally little debate that we can acquire spatial knowledge via multiple modalities (Montello, Waller, Hegarty, & Richardson, 2004), including via navigation and cartographic maps, whether and how knowledge acquired from these two different modalities differs remains unresolved (Chrastil, 2013; Evans & Pezdek, 1980; Montello et al., 2004; Shelton & Gabrieli, 2002; Shelton & McNamara, 2004; Taylor & Tversky, 1992; Wolbers & Büchel, 2005; Zhang, Copara, & Ekstrom, 2012).
Several behavioral studies have suggested that map learning may provide more direct access to survey knowledge than does navigation (Ruddle, Payne, & Jones, 1997; Thorndyke & Hayes-Roth, 1982). These findings also support the idea that the survey representation is the final element in a hierarchy of acquisition of spatial knowledge (Siegel & White, 1975). The model thus postulates three fundamental, hierarchical steps in spatial learning: (1) representation of landmarks, (2) representation of routes linked to landmarks, and (3) representation of the configurations of landmarks and routes with accompanying directional and metric information, referred to as the “survey representation.” However, it is unclear whether cartographic maps go through the same hierarchy as routes, or whether maps can provide more immediate access to survey knowledge than routes do.Footnote 1
The partially independent model: route and cartographic map learning lead to different forms of spatial knowledge
A modification to the Siegel and White (1975) model is that map learning may involve more immediate access to configural knowledge, bypassing the need for the representation of individual routes, whereas route learning provides more immediate representation of paths through an environment, with less configural knowledge (Moeser, 1988; Noordzij, Zuidhoek, & Postma, 2006; Shemyakin, 1962; Taylor, Naylor, & Chechile, 1999; Thorndyke & Hayes-Roth, 1982; Zhang et al., 2012). After sufficient exposure, however, spatial knowledge gained from the two modalities is generally comparable (Siegel & White, 1975; Thorndyke & Hayes-Roth, 1982). In one study supporting the partially independent model, Taylor et al. (1999) had participants study maps or navigate an unfamiliar campus building for 10–20 min. Participants who learned the environment by route navigation showed better estimates of route distances and worse estimates of Euclidean distances, whereas the opposite pattern emerged for map learners, who showed better estimates of Euclidean distance and worse estimates of route distance (see also Rossano, West, Robertson, Wayne, & Chase, 1999). The apparent double dissociations reported by Taylor et al., as well as those obtained by others (e.g., Noordzij, Zuidhoek, & Postma, 2006), suggest that cartographic maps may provide more immediate access to survey knowledge than navigation does, and thus that knowledge acquired via cartographic map learning may be more anchored to landmark configurations than is knowledge derived from route learning. The opposite may apply to routes, which may depend to a greater extent on memory for individual trajectories that are not particularly well integrated, even after extensive exposure to the environment (Hirtle & Hudson, 1991; Moeser, 1988). We term this the “partially independent model.”
The overlapping model: route and cartographic map learning result in the same forms of spatial knowledge
It has also been suggested that both route and map learning involve the same fundamental, visually based representational system (Kosslyn, 1996; Lee & Tversky, 2001; H.A. Taylor & Tversky, 1992; Tversky, 1992). Whereas early studies suggested that cartographic maps may involve preferential access to the original learned orientation, as compared to navigation (e.g., Evans & Pezdek, 1980), later studies suggested that both modes of learning involve orientation-dependent forms of representation (Roskos-Ewoldsen, McNamara, Shelton, & Carr, 1998; Shelton & McNamara, 2004). Alignment dependence, based on the angle from which the layout was originally encoded, has often been taken as evidence for the two modes’ fundamental similarity (Montello et al., 2004; Shelton & McNamara, 2004). Any costs observed in switching from a route to a map perspective (and vice versa) could be taken as a cost associated with changing the orientation of a single representation rather than with switching between two representations per se (cf. Lee & Tversky, 2001). Finally, several fMRI studies have reported largely overlapping brain areas following route and survey learning, with survey learning recruiting a subset of the brain regions involved in route learning (Latini-Corazzini et al., 2010; Shelton & Gabrieli, 2002; Shelton & Pippitt, 2007; but see Zhang et al., 2012). Thus, these studies suggest that route and cartographic map learning do not differ substantially in terms of their underlying representational structures, suggesting that they result in comparable “cognitive maps.” We term this the “overlapping model.”
The encoding specificity hypothesis and its relationship with the above models
A third possibility is that previously observed differences between route and map learning relate to encoding specificity. Specifically, the majority of behavioral studies on route and map learning have employed Euclidean distance and route estimation as measures for route and holistic knowledge, respectively (Ruddle, Payne, & Jones, 1999; Taylor et al., 1999; Thorndyke & Hayes-Roth, 1982). Thus, different types of knowledge may be selectively enhanced because of how they were encoded, rather than dues to differences in the representations (e.g., encoding specificity; Tulving & Thomson, 1973). For example, map learning, in particular, allows the participant to visualize distances between remote landmarks directly, and may thus provide an advantage with tests of spatial memory that provide a similar encoding perspective (Shelton & McNamara, 2004). Similarly, in cognitive neuroscience studies in which participants viewed information from either a route or a survey perspective, any differences in activations may have been influenced by the specific viewpoint encoded rather than by differences in the underlying representational structures of routes versus maps (Latini-Corazzini et al., 2010; Shelton & Gabrieli, 2002; Shelton & Pippitt, 2007). One way of dealing with this potential confound would be to employ measures not affected exclusively/primarily by how the original layout was encoded. We argue here that one way to do this involves comparing measures that access primarily scene- and orientation-dependent (egocentric) versus landmark-referenced (allocentric) knowledge.
Dual systems for spatial representation
In some studies, “allocentric” is assumed to mean the same thing as a survey representation, and “egocentric” the same as route knowledge (Noordzij et al., 2006). It is not clear, however, that these representations are, in fact, equivalent. For example, Igloi, Zaoui, Berthoz, and Rondi-Reig (2009) showed that when participants navigated a virtual environment, they employed both landmark referencing (allocentric) and memory for the number of turns (sequential egocentric), often using both in parallel or switching between the two forms of knowledge (Igloi et al., 2009). This finding suggests that route learning facilitates the development of both egocentric and allocentric knowledge, sometimes in parallel. Also, whereas learning a map would seem to involve coding landmarks relative to each other, and thus treating them in a largely allocentric fashion, utilizing a map to navigate requires some conversion into egocentric-based coding schemes, to allow alignment to the configuration of landmarks relative to the navigator (Sholl, 1987). Although some theoretical models have suggested ways in which route and map learning might relate to egocentric and allocentric knowledge (Poucet, 1993), the question of how and in what manner they might relate empirically remains generally unaddressed. Thus, we sought to assess the relative effects of route and cartographic map learning on view versus landmark-referenced knowledge, using two tasks employed in past literature to assess them: respectively, a scene- and orientation-dependent pointing task and judgments of relative direction (Mou, McNamara, Rump, & Xiao, 2006; Mou, McNamara, Valiquette, & Rump, 2004; Waller & Hodgson, 2006). To our knowledge, our article is the first to investigate how and in what manner route and map learning differentially affect performance in these two pointing tasks.
Assessing utilization of egocentric and allocentric knowledge
To address the effects of route and map learning on the two forms of spatial knowledge, we employed a recently developed paradigm by Waller and Hodgson (2006) that provided a means of dissociating view- and landmark-referenced representational systems (Waller & Hodgson, 2006). Specifically, we adapted two conditions from a paradigm used by Waller and Hodgson and others (Holmes & Sholl, 2005; Mou et al., 2004; Rieser, 1989) to differentially measure scene- and orientation-dependent (view-referenced) memory and landmark-referenced memory, respectively. The first task, which we term the scene- and orientation-dependent pointing (SOP) task, was primarily dependent on one’s position and orientation in the environment in terms of the perceptual details of the scene, employing the same questions as had been used in the Waller and Hodgson study (e.g., “Point to the Camera Store”). To ensure participant orientation, before the pointing judgments began, participants navigated to a position in the city at which they felt oriented. To further ensure their orientation, participants viewed background information during the pointing task (i.e., everything but the targets).Footnote 2 The second task, which we term the judgment of relative direction of landmarks (JRD) task (consistent with earlier terminology) was dependent primarily on knowledge of the relative positions of landmarks with respect to each other, and not on being oriented in the immediate environment with scene information. The lack of any orienting information on the screen in our version discouraged updating of their position from trial to trial and any use of information in the city that might conflict with their imagined position.Footnote 3
In the present study, the JRD task involved estimating spatial relations between targets, which would primarily tap knowledge of the angular and positional relationships of landmarks to each other. Thus, the JRD task, although initially involving some degree of self-orientation to perform the task, assayed participants’ knowledge of the relative positions of landmarks within the spatial configuration. The SOP task, in contrast, depended on knowledge of the relationship between the target and standing position and orientation in the virtual environment, which was more likely to be view-referenced and to involve egocentric knowledge. In contrast to the transient types of short-term representations for recent views (Waller & Hodgson, 2006), because participants chose their pointing position at the beginning of the SOP task, this task was more likely to involve enduring egocentric forms of knowledge (see Wang & Spelke, 2002) . Although both tasks could be conducted with reference to either egocentric or allocentric representations, or both (Igloi et al., 2009), both route and map learning likely also involve the two forms of representations (Moeser, 1988; Noordzij et al., 2006; Shemyakin, 1962; Taylor et al., 1999; Thorndyke & Hayes-Roth, 1982; Zhang et al., 2012). Given that the JRD task would involve mapping onto landmark interrelations in a way that the SOP task would not, whereas the SOP tasks would depend on position/orientation information, testing the improvements in pointing accuracy during route versus map learning would provide some insight into the relative development of view-/orientation-referenced knowledge via the SOP task, and knowledge of landmark interrelations via the JRD task.
We set up our experiments such that participants were repeatedly tested on either JRD pointing accuracy (Exp. 1) or SOP accuracy (Exp. 2) during route and map learning. This allowed us to test two novel and hitherto untested hypotheses: (1) that the dynamics of how SOP and JRD pointing accuracy improve would differ during route and map learning, and (2) that SOP and JRD pointing accuracy would differ following route and map learning. According to the partially independent model and the logic above, we would generally assume faster improvements in pointing accuracy for the JRD task after map as compared to route learning. In contrast, we would expect faster improvements in SOP pointing accuracy following route as compared to map learning. In contrast, from the overlapping model, we would expect no difference in pointing accuracy for the SOP versus the JRD task, since the two learning modalities would utilize the same knowledge. For the encoding specificity model, we might predict overall better performance in the SOP task during route than during map learning, with possibly the opposite result for the JRD task, although this model would not appear to explicitly predict differences in the dynamics of improvement for the SOP versus the JRD task.
General method
Stimuli
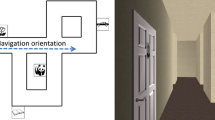
Two virtual cities were displayed separately on a 21-in. computer screen. The cities measured 304 × 304 m and 238 × 309 m, respectively, and were rendered with an ATI Radeon HD 2400 graphics accelerator. In each of the virtual cities a set of rectangular target stores (approximately 9.5 × 6.5 × 5.8 m, length × wide × height) were placed, located along virtual streets. In addition, we enriched the environment with additional buildings, trees, grass, trash cans, benches, fences, walls, sky, and clouds. The target stores were arranged in a such way that participants could only view one store at a time from the route view (Fig. 1a, right panel). The buildings served as background information to aid in localization and never served as targets. The 3-D models of all the items in the virtual cities were first constructed using Maya2008 (Autodesk Inc.) and presented using Panda3D software (Entertainment Technology Center, Carnegie Mellon University) and the panda_epl software (http://memory.psych.upenn.edu/PandaEPL). During testing, participants were seated in front of the computer screen; the distance between the participants and the computer screen was around 80 cm.

General experimental design. a Right panel, route-learning view of the environment; left panel, aerial view of the environment. b Left panel, judgment of relative direction (JRD) pointing task; right panel, egocentric pointing task
Maps of the city were constructed by taking an aerial-view snapshot from 300 m above the center of the virtual city (Fig. 1a, left panel). The resultant image was shown in the application Preview on the computer monitor. Each target store was clearly and visibly labeled with its name on the room (e.g., “Coffee Shop”).
Encoding via route or cartographic map learning
During route learning, participants were instructed to search for one of eight target stores. On each trial in which participants searched for a target store, a prompt in the upper left corner of the screen indicated which store was the target (e.g., “Find the Fast Food Restaurant”; Fig. 1a, right panel). Participants then freely navigated until they located the target. When participants arrived at the store, another prompt appeared (e.g., “Thank you. You found the Fast Food Restaurant”). Participants then pressed the Enter button, and the target name for the next trial appeared in the top left corner of the screen. Each round of searching for the eight target stores constituted one block of route learning. The sequence of searching for target stores during route learning within a block was fully randomized. While navigating, participants were encouraged to take as short a route as possible to the target store, and they could not travel through obstacles. Participants navigated using the arrow keys on the keyboard, which allowed for forward and backward movement and left and right turns. The full linear speed was 20 m/s, and the turning speed was 40°/s. The corresponding accelerations were 37.5 m/s2 and 25°/s2.
During map learning, participants viewed and drew the layout of the city from an aerial view (see the Stimuli section). The city was rendered identically to when it had been seen during navigation, with the exception that it was viewed from an aerial, or overview, perspective. Relevant details (target stores, store names, roads, buildings, etc.) were visible from the aerial perspective as well as the route perspective. Participants learned the map by viewing the map of the city on the computer screen and drawing a rendition of what they saw on a piece of paper.
SOP task
Participants began the SOP task by being placed at a random location within the environment. They then positioned themselves in the environment by navigating to a place at which they felt oriented (Fig. 1b, right panel). This was to ensure that participants were oriented within the visual scene when performing the task. All target stores were removed in this version of the environment, requiring participants to use other landmarks (buildings, roads, or other stimuli) to orient themselves. Following self-positioning, participants then began the SOP task. Each trial consisted of the participants seeing the name of the target store in the upper left corner of the screen (e.g., “Please point to the Camera Store”). A virtual compass was present on the bottom half of the screen, and the participant pressed leftward and rightward arrow keys to rotate the compass until it pointed to the correct direction of the target.
JRD pointing task
A trial began with participants viewing the ground and sky, and no other stimuli (Fig. 1b, left panel). We did this to avoid showing any stimuli that participants could use to orient themselves relative to the previous trial, while still maintaining orientation in the up–down direction. For each JRD pointing trial, instructions appeared in the top half of the screen (e.g., “Imagine you are standing at the Costume Shop, facing the Gym. Please point to the Camera Store”). These instructions required participants to imagine themselves in a comparatively novel position within the environment, to better assay their knowledge of the configuration of the stores.
During both pointing tasks, the full turning speed of the virtual compass was 117.6°/s, with a precision of 1 deg. The turning acceleration was 60°/s2.
Participants
All participants in the study were recruited from the general population in Davis, California, area and gave written informed consent to participate in the study, which was approved by the Institutional Review Board at the University of California, Davis. All participants were between the ages of 18 and 35.
Experiment 1
Here, we sought to understand how JRD pointing accuracy changes as a function of exposure to either direct navigation (route learning) or a map (cartographic map learning). This experiment provided a test of the three models by determining how and in what manner JRD pointing accuracy changes as a function of route versus map learning. One difficulty in testing how route and map learning affect spatial knowledge is that it is challenging to equate exposure between the two different learning modalities (e.g., Leiser, Tzelgov, & Henik, 1987). Repeated testing, although not a complete solution to this problem, would provide insight into whether the representations might evolve differentially following the two learning modalities, thus revealing when performance might diverge or converge. This approach would also allow us to potentially better equate exposure to the two modalities initially, by providing minimal exposure on the first learning block and then seeing whether performance in the JRD task differed in later trials.
Method
Participants
A group of 31 participants (16 female and 15 male) were recruited for this experiment; none of them had participated in the study before.
Materials
The layouts are shown in Fig. 1. Each JRD pointing block consisted of ten trials randomly selected from a pool of 336 possible questions. The JRD pointing task was otherwise identical to that described in the General Method section.
Experimental design and procedure
After receiving practice on the JRD pointing task, participants were assigned to encode one of the layouts either by route or map learning. During route learning, participants navigated to each of the eight target stores once in a random order, completing a full round of deliveries in each encoding block. For map learning, participants viewed the map of the layout for 30 s. Following a block of encoding, participants performed a block of the JRD pointing task. We selected 30 s of map learning because this was the minimal amount of time that participants needed to study and acquire the contents of the map. A pilot experiment employing longer degrees of exposure (60 s) resulted in substantial differences in pointing accuracy between route and map learning on the first block of the JRD task, with map learners performing significantly better. Providing 30 s of exposure thus allowed us to better balance their initial performance on the first block, and thus better investigate whether and how differences between the two forms of learning emerged.
For both route and map learning, the encoding/test procedure was repeated five times. Participants then studied the second layout, performing either route or map learning; the procedure for the second layout was identical to that for the first layout, except for the learning method. This again allowed us to employ a within-participants design.
The sequence of the two layouts and the encoding methods for two layouts were counterbalanced across participants. Participants were encouraged to respond as accurately as possible.
Results and discussion
The pointing error was calculated for each trial and then averaged for each testing block and participant, excluding trials with pointing errors two standard deviations above the mean. Using this criterion, 5.6 % of trials were rejected. The mean pointing error for each testing block was then analyzed in a 2 × 5 Encoding (route vs. survey learning) × Testing Block (five learning blocks) analysis of variance (ANOVA). We did not find any significant differences in pointing latencies. We also did not find any significant effect of gender on pointing errors [F(1, 29) = 1.48, p = .23]. Thus, we focused on significant differences in pointing errors collapsed across genders.
Mean pointing errors are plotted as a function of testing block and encoding method in Fig. 2. We found a main effect of learning block [F(4, 120) = 18.14, p < .001] and a significant interaction effect between encoding method and learning block [F(4, 120) = 3.94, p < .005]. Planned comparisons of JRD performance on all testing blocks showed that performance was better after map learning than after route learning for the second, third, and fourth testing blocks [ts(30) = 4.38, 2.12, and 2.86, and ps < .001, .05, and .01, respectively], but that there were no significant differences for the first and fifth blocks between route and map learning. These findings indicate that although pointing accuracy in the JRD task started at comparable levels following route and map learning on the first block, it diverged for Blocks 2–4, and then converged again at Block 5. We also compared the first block of learning against later blocks. For route learning, JRD pointing accuracy was significantly different between the first and third blocks [t(30) = 1.65, p < .05, one-tailed], the first and fourth blocks [t(30) = 2.81, p < .01], and the first and fifth blocks [t(30) = 3.98, p < .001]. No difference in pointing accuracy emerged for route learning between the first and second blocks. For map learning, pointing accuracy was significantly different for the first versus all subsequent blocks [ts(30) = 5.81, 4.79, 6.69, 6.59, respectively, all ps < .001]. We also performed paired t tests between adjacent blocks. For route learning, JRD pointing accuracy was significantly better for the third than for the second block [t(30) = 2.29, p = .029]. For map learning, JRD pointing accuracy was better for the second than for the first block [t(30) = 5.81, p < .001] and for the fourth block than for the third block [t(30) = 2.26, p = .031]. These results show that map learning produced a significant improvement in pointing accuracy by the second learning block, whereas this difference manifested later (after the third learning block) for route learning.

Results from Experiment 1: Mean JRD pointing accuracy as a function of testing block. Solid lines indicate the participant data, and dotted lines indicate the best-fitting models. (Errors correspond to ±1 standard error of the means, as estimated from the analysis of variance)
We then performed a function-fitting analysis to determine whether route and map learning were described better by similar or fundamentally different dynamics. Specifically, we might predict that if map learning provided more immediate access to landmark-referenced knowledge, we would see fast, nonlinear improvements in JRD pointing accuracy. In contrast, for route learning, assuming that acquisition of landmark-referenced knowledge is more gradual and takes time to accumulate, we might expect a more linear function for improvement in JRD pointing accuracy over blocks. Using least squares fitting, we found a difference between the functions that described changes in pointing accuracy over blocks for route versus map learning. Improvements in pointing accuracy resulting from route learning were described better by a linear (r 2 = .90) than by a power (r 2 = .76) function. In contrast, improvements in pointing accuracy resulting from map learning were described better by a power function (r 2 = .90) than by a linear function (r 2 = .76). The coefficients for these two best-fit functions (linear and power functions) were f(x) = –2.9x + 50.5, for route learning, and f(x) = 46.7x –.27 (\( \sim 46.7\sqrt[4]{x} \)), for map learning. Other function fits (power function with positive exponents, quadratic functions, and exponential functions) did not provide comparably significant fits of our data for either condition. These findings suggest that learning in the two conditions could be described better by different functions, further suggesting differences in the dynamics of acquisition of spatial knowledge: Route learning was best described by a gradual, linear process, whereas map learning was best described by a faster, nonlinear process. Some caution is necessary with this interpretation, however, because the exposures to route and map learning were difficult to equate, and were not necessarily matched in our experimental design. We will consider this issue in more depth, however, in our subsequent analysis of participant time spent navigating.
In addition to improvements in JRD pointing accuracy over blocks during route learning, an important issue to address is whether participants also showed improvements in the accuracy of their paths during route learning. For example, it could be that improvements in JRD pointing accuracy were task-specific—in other words, that they did not mirror actual improvements or utilization of these representations during active navigation. It could also be that participants attempted to gain additional knowledge during route learning by spending additional time navigating on later learning blocks to provide an advantage relative to map learning. To address this issue, for each block of virtual navigation, we calculated the total time spent navigating and the total excess path length, a measure of deviation from the ideal path on trips from one store to another (Newman et al., 2007). A 1 × 5 repeated measures ANOVA revealed a main effect of block on both total time spent navigating [F(4, 120) = 36.9, p < .001] and excess path [F(4, 120) = 58.4, p < .001], indicating that both decreased significantly over blocks (Fig. 3). These results showed that route learners, in addition to showing improvements in JRD pointing accuracy, also improved in terms of the speed and accuracy of their paths while navigating the environment—possibly because they could effectively utilize primarily landmark-referenced knowledge to guide their paths during navigation. These results also suggest that participants were not compensating for the increased difficulty involved in route learning by spending significantly greater amounts of time navigating in later blocks.

Results from Experiment 1 for time spent and excess path length per round of deliveries during route learning
Experiment 2
Overall, the faster improvement of JRD performance after map learning than after route learning, and specifically, the significant Modality × Learning Block interaction effect observed in Experiment 1, would appear to provide primary support for the partially independent model. The overlapping model generally would not predict any difference between the two learning modalities, which was at least not consistent with the findings here. Together, these results provide tentative support for the partially independent model, although stronger support—and a comparison with the encoding specificity model—awaits a comparison with the same setup using the SOP task.
Whereas Experiment 1 addressed the issue of changes in JRD pointing accuracy as a function of route or map learning, this experiment did not address how SOP error changed as a function of encoding method. This and the interaction between Experiments 1 and 2 are critical tests of the models, as we will outline below. Thus, in Experiment 2 we explored how the two different modes of learning the environment (route vs. map learning) affected SOP task performance, using the exact same design as in Experiment 1, but with the SOP rather than the JRD pointing task.
Method
Participants
A group of 36 participants (half female and half male) were recruited for this experiment; none of them participated in the other experiments.
Materials
The layouts were the same as in Experiment 1. Each SOP block consisted of 24 trials composed of three rounds of pointing to each of the eight target stores. The SOP task was otherwise identical to that described in Experiment 1.
Experimental design and procedure
The procedure was identical to that of Experiment 1, except that following a mini-block of encoding, participants performed a mini-block of the SOP task. The sequence of the two layouts and the encoding methods for two layouts were counterbalanced across participants. As in previous experiments, the participants were encouraged to respond as accurately as possible. We maintained the same presentation procedure for route and map learning (one round of deliveries and 30 s of map viewing in each block) to allow for a direct comparison between Experiments 1 and 2.
Results and discussion
The pointing error was calculated for each trial and then averaged for each testing block and participant, excluding trials with pointing errors two standard deviations above the mean. Using this criterion, 4 % of trials were rejected. The mean pointing errors for the testing blocks were then analyzed in a 2 × 5 Encoding (route vs. map learning) × Testing Block (five testing blocks) ANOVA. We did not find any significant effects of pointing latencies. We also did not find any significant effects of gender on pointing errors [F(1, 34) = 1.74, p = .20]. Thus, we focused on significant differences in pointing errors, collapsed across genders.
Mean pointing errors are plotted as a function of testing block and encoding method in Fig. 4. We found a main effect of encoding method [F(1, 35) = 7.51, p < .01], indicating that SOP accuracy was better overall following the route-learning condition than following the map-learning condition. We also found a main effect of learning block [F(4, 140) = 25.56, p < .001], indicating that SOP accuracy improved as a function of learning in both conditions. Additionally, we found a significant interaction effect between encoding method and learning block [F(4, 140) = 2.66, p < .05], indicating a differential improvement in SOP accuracy following route as compared to map learning. Planned comparisons showed that performance on the SOP task was better following route learning than following map learning for the first and second testing blocks [ts(35) = 3.66 and 2.49, respectively, ps < .001 and .05] but no differences emerged for the third, fourth, and fifth blocks between route and map learning. We also performed paired t tests between adjacent blocks. For route learning, SOP pointing accuracy was significantly better for the second than for the first block [t(35) = 3.70, p < .001]. Similarly, after map learning, SOP pointing accuracy was significantly better for the second than for the first block [t(35) = 3.98, p < .001], but also significantly better for the third than for the second block [t(35) = 3.45, p = .001]. Thus, comparing adjacent blocks indicated that SOP accuracy improvements stayed stable after the second learning block during route learning, whereas accuracy continued to improve until the third block during map learning.

Results from Experiment 2: Mean scene- and orientation-dependent pointing (SOP) accuracy as a function of testing block. (Errors correspond to ±1 standard error of the means, as estimated from the analysis of variance)
As in our analyses in Experiment 1, we performed a function-fitting analysis to determine whether changes in the SOP task following route and map learning were described better by similar or by fundamentally different dynamics. Using least squares fitting, we found no difference in the functions that described changes in pointing accuracy over blocks for route versus map learning. Improvements in pointing accuracy resulting from both route learning and map learning were described better by a power function (r 2 = .89, .90) than by a linear function (r 2 = .70, .72). Other function fits (exponential, quadratic) did not provide better accounts for the data.
The better performance of SOP after route learning than after map learning would appear to provide primary support for the partially independent model. The overlapping model, again, would not predict any difference between the two learning modalities, which was at least not consistent with the findings here as in Experiment 1. The encoding specificity hypothesis might argue for better performance in SOP pointing accuracy following route than following map learning; however, after the third learning block, we observed no difference between route and map learning on the SOP task.
To better compare how route and map learning differentially affected SOP and JRD performance, we conducted a between-experiment comparison of Experiments 1 and 2. We thus compared mean pointing errors for both SOP and JRD tasks in a 2 × 5 × 2 Pointing Task (SOP vs. JRD) × Learning Block (five blocks) × Encoding Method (route vs. map learning) ANOVA. All terms except pointing task, which was between participants, were analyzed within participants. This comparison is displayed graphically in Fig. 5.

Mean JRD and SOP accuracy during both route and map learning. Note the scaling of the two y-axes to accommodate the plotting of all four functions
We found a main effect of pointing task [F(1, 65) = 41.69, p < .001], suggesting that performance on the SOP task was better than performance on the JRD task. We also found a main effect of learning block [F(4, 260) = 38.76, p < .001], indicating that participants improved in pointing accuracy during both pointing tasks over learning blocks. We also found an interaction effect between encoding method and pointing task [F(1, 65) = 7.69, p < .01], suggesting that route and map learning affected the SOP and JRD tasks in different ways. Additionally, we found an interaction between pointing task and learning block [F(4, 260) = 3.93, p < .005], suggesting that SOP and JRD pointing accuracy changed differently across learning blocks, and an interaction between encoding method and learning block [F(4, 260) = 5.42, p < .001], suggesting that the two modes of learning resulted in different improvements in pointing accuracy over learning blocks. Finally, and perhaps most importantly, the three-way interaction was also significant [F(4, 260) = 2.62, p < .05], suggesting that the interaction effect between pointing task and learning block was affected differently by route than by map learning. No other effects were significant.
As can be seen in Fig. 5, the three-way interaction effect was driven, in part, by the fact that route learning resulted in clear differences in the dynamics of improvement for the JRD task relative to the SOP task. In contrast, map learning, while resulting in significant differences in JRD versus SOP pointing overall (note that the y-axes are scaled), displayed comparable dynamics in improvement over learning blocks. The faster improvement in SOP than in JRD pointing accuracy following route learning as compared with map learning provides primary support for the partially independent model. Overall, the three-way interaction effect is generally not congruent with the overlapping model, which would predict no difference in the SOP task after route versus map learning. Because the encoding specificity hypothesis does not appear to predict differences in dynamics of performance improvements for the SOP versus the JRD task during route versus map learning, the three-way interaction effect that we found also does not appear consistent with this model. We will return to these issues in the Discussion.
Summary and concluding discussion
In this article, we focused on how the dynamics of route and map learning affect two pointing tasks commonly used in the human spatial navigation literature: the SOP and JRD tasks (Mou, Fan, McNamara, & Owen, 2008; Mou et al., 2006; Waller & Hodgson, 2006). To better frame our ideas of how the two modalities might differentially affect the two representational systems, we tested the predictions of three different models of route and map learning. The partially independent model, articulated in various forms in the past literature (Moeser, 1988; Noordzij et al., 2006; Shemyakin, 1962; Taylor et al., 1999; Thorndyke & Hayes-Roth, 1982; Zhang et al., 2012), argues that map learning provides more immediate access to knowledge of landmark interrelations than does route learning, whereas route learning provides more access to viewpoint-/orientation-specific knowledge than does map learning. The overlapping model predicts that both route and map learning would tap primarily into the same underlying form of spatial knowledge (Lee & Tversky, 2001; Shelton & Gabrieli, 2002; Shelton & McNamara, 2004; Shelton & Pippitt, 2007; Taylor & Tversky, 1992). The encoding specificity hypothesis predicts that encoding modality should affect subsequent ease of retrieval, such that items encoded from a route perspective are easier to remember from the same perspective, and vice versa for maps (Lee & Tversky, 2001; Tulving & Thomson, 1973).
To attempt to test the three models, participants learned spatial environments by either route or map learning and then performed two different pointing tasks to assess their knowledge of the spatial layouts. The SOP task involved participants selecting a specific location in the city and pointing to each of the targets from this location. By selecting their position and maintaining scene information (in the absence of the targets), participants in this task utilized primarily a scene- and orientation-referenced (egocentric) form of knowledge. In contrast, during the JRD task, participants viewed a screen devoid of any objects other than the sky and the ground and were asked to imagine themselves at one target, facing another target, and to point to a third. In comparison with the SOP task, this task required participants to use their knowledge of landmark interrelations, while providing little or no orientation or positional information from trial to trial. The different models make contrasting predictions about performance on the two tasks following route and map learning, particularly when SOP and JRD testing are interleaved with the two encoding methods, as was the case in Experiments 1 and 2.
We employed interleaved JRD and SOP pointing tasks with repeated exposure (but equal amounts between the experiments) to route and map learning. We found that initial exposure to the route (one round of deliveries) and map (30 s of viewing and drawing) led to comparable levels of JRD pointing accuracy. More extensive exposure led to a divergence in these two functions by the second, third, and fourth trials. Route learning resulted in slower and linear changes in JRD pointing accuracy, whereas map learning resulted in nonlinear, more dramatic changes in JRD pointing accuracy. By the fifth trial, though, JRD pointing accuracy was equal between the two modalities. The most natural fit for these data would appear to be the partially independent representation model. This model allows for differences in the development of knowledge of landmark interrelations between route and map learning by suggesting that map learning provides more immediate access to this information than do routes. Yet, the data also suggest that, as postulated in the Siegel and White (1975) hierarchical model, the two modalities do eventually converge in terms of (measureable) spatial knowledge.
In contrast, improvements in pointing accuracy in the SOP task initially showed a pattern opposite to that in the JRD task, despite the equivalence in exposure between the two experiments. SOP pointing accuracy was higher initially following route than following map learning, although pointing accuracy was statistically indistinguishable between route and map learning by the third trial. This initial difference for SOP pointing, but not JRD pointing, may relate in part to the fact that SOP pointing accuracy was generally higher than JRD pointing accuracy. We speculate that this likely relates to the fact that the view- and position-referenced knowledge tested here were probably more readily acquired and utilized than primarily landmark-referenced knowledge acquired in the JRD task (see also Waller & Hodgson, 2006). Nevertheless, we also found a significant interaction effect for SOP accuracy improvements during route versus map learning, indicating that map learning took longer to result in improvements in SOP pointing accuracy than did route learning. These data support the idea that route learning results in faster improvements in view- and orientation-referenced knowledge than does map learning. Contrasting the two experiments, the three-way interaction supported the idea that the two modalities differentially affected landmark- versus view-referenced knowledge. Although the encoding specificity hypothesis supports differences in the two tasks following route and map learning, it does not appear to predict the differences in the dynamics of performance improvement that we observed. Together, these data would seem to provide the best support for the partially independent model.
In addition to their relevance to understanding cognitive models of route versus map learning, we believe that our data suggest additional constraints on how route and map learning affect underlying representational systems. One idea, discussed in previous work (Burgess, 2006; Byrne, Becker, & Burgess, 2007), is that both route and map learning involve not only egocentric and allocentric knowledge, but also the conversion of egocentric to allocentric, and allocentric to egocentric, knowledge (see also Chen, Byrne, & Crawford, 2011). Specifically, according to this conceptualization, route learning initially favors representation of the environment via scene- and orientation-dependent trajectories, likely largely egocentric in nature. As one repeatedly experiences different paths to the same locations, one can infer the locations of different objects relative to each other and build an allocentric representation of the environment (Ekstrom, 2010). Our data, and those of others (Igloi et al., 2009; Ishikawa & Montello, 2006), suggest that although knowledge of landmark interrelations develops early during navigation, it develops at a relatively gradually rate with experience. This could reflect, in part, the integration of different trajectories between different landmarks on the basis of experience, to build a more holistic representation of the environment. In contrast, viewing a map may allow one to skip some of this integration process, providing more immediate access to the geometric configuration of the layout.
Using a map to derive scene- and orientation-dependent knowledge likely involves somewhat of the reverse process. Participants must utilize knowledge primarily about the geometrical relationships of the landmarks, align this to their current bearing, and then derive their offset from the target (Sholl, 1987). This process is likely dependent on the participant experiencing sufficient numbers of views within the environment to “lock” in their bearing. Thus, this process of converting primarily landmark-referenced to view-dependent knowledge may occur in a more nonlinear, instantaneous manner than the egocentric-to-allocentric conversion following route learning, as is supported by our function-fitting findings from the SOP task. Further data will be needed to fully test this idea, including situations that require higher demands for egocentric-to-allocentric conversion versus allocentric-to-egocentric conversion.
One issue regarding our conclusions is the extent to which the results obtained from virtual navigation may extend to real-world navigation. Using a virtual version of the same layout used by Thorndyke and Hayes-Roth (1982), Ruddle et al. (1997) found that virtual navigators developed comparable levels of accuracy during route and Euclidean distance estimations, as had been found by Thorndyke and Hayes-Roth for navigators of the real building. Richardson, Montello, and Hegarty (1999) found that training with a virtual version of a real-world environment improved subsequent learning of the locations of landmarks within that environment. These findings argue that spatial representations acquired in virtual reality are generally comparable, and obey similar properties, to those acquired during real-world navigation (see also Valtchanov, Barton, & Ellard, 2010). Given the differences in vestibular and proprioceptive input for egocentric representation in real versus virtual reality (Bakker, Werkhoven, & Passenier, 1999), we may expect to find even greater differences in the acquisition of egocentric representation for route versus map learning in “real” environments.
In summary, our findings provide support for models of route and map learning that emphasize that the two modalities are partially dissociable. Thus, our findings emphasize that route and map learning involve different ways of utilizing spatial knowledge about the layout of objects within a spatial environment. These findings may potentially place in a new light an important debate: the extent to which learning a spatial layout by directly navigating versus studying it from a cartographic map involves similar or different underlying cognitive systems. Our results overall emphasize differences in how the two types of knowledge emerge during the two different modes of learning.
Notes
Although Siegel and White (1975) are not explicit as to whether routes and maps go through the same hierarchical steps, they state on page 43 that “Survey maps appear as coordinations of routes within an objective frame of reference . . . [and are] possible only after both routes and an object frame of reference exist.” This statement would seem to imply that both modes of learning involve the same steps.
Although kinesthetic and vestibular inputs contribute to egocentric representation and are degraded in virtual reality (Bakker, Werkhoven, & Passenier, 1999), because view and orientation are considered primary influences on egocentric representation (Klatzky, 1998), we consider the SOP task to be a measure primarily of egocentric representation. Certainly, allocentric representation may, in some instances, aid in solving the egocentric task. This should primarily be the case, though, during disorientation, as was suggested by Waller and Hodgson (2006). By ensuring participants’ orientation during the SOP task, we reasoned that participants would primarily employ egocentric representations during that task.
As was pointed out by Mou et al. (2004), the JRD pointing task has both egocentric and allocentric components (Mou et al., 2004). This is because interobject relations still must be mapped onto an egocentric frame (one’s current position) while, simultaneously, one must use external coordinates (the other landmarks) to make judgments about the relative positions of the three objects in the environment. Particularly in the absence of orienting information, and as compared with the SOP task, however, the JRD task provides insight primarily into landmark-referenced knowledge.
References
Appleyard, D. (1970). Styles and methods of structuring a city. Environment and Behavior, 2, 100–117.
Bakker, N. H., Werkhoven, P. J., & Passenier, P. O. (1999). The effects of proprioceptive and visual feedback on geographical orientation in virtual environments. Presence: Teleoperators and Virtual Environments, 8, 36–53.
Burgess, N. (2006). Spatial memory: How egocentric and allocentric combine. Trends in Cognitive Sciences, 10, 551–557. doi:10.1016/j.tics.2006.10.005
Byrne, P., Becker, S., & Burgess, N. (2007). Remembering the past and imagining the future: A neural model of spatial memory and imagery. Psychological Review, 114, 340–375. doi:10.1037/0033-295X.114.2.340
Chen, Y., Byrne, P., & Crawford, J. D. (2011). Time course of allocentric decay, egocentric decay, and allocentric-to-egocentric conversion in memory-guided reach. Neuropsychologia, 49, 49–60. doi:10.1016/j.neuropsychologia.2010.10.031
Chrastil, E. R. (2013). Neural evidence supports a novel framework for spatial navigation. Psychonomic Bulletin & Review, 20, 208–227. doi:10.3758/s13423-012-0351-6
Ekstrom, A. D. (2010). Navigation in virtual space: Psychological and neural aspects. In G. F. Koob, R. F. Thomspon, & M. LeMoal (Eds.), Encyclopedia of behavioral neuroscience (pp. 286–293). Amsterdam, The Netherlands: Elsevier.
Evans, G. W., & Pezdek, K. (1980). Cognitive mapping: Knowledge of real-world distance and location information. Journal of Experimental Psychology: Human Learning and Memory, 6, 13–24. doi:10.1037/0278-7393.6.1.13
Hartley, T., Maguire, E. A., Spiers, H. J., & Burgess, N. (2003). The well-worn route and the path less traveled: Distinct neural bases of route following and wayfinding in humans. Neuron, 37, 877–888.
Hirtle, S. C., & Hudson, J. (1991). Acquisition of spatial knowledge for routes. Journal of Environmental Psychology, 11, 335–345.
Holmes, M. C., & Sholl, M. J. (2005). Allocentric coding of object-to-object relations in overlearned and novel environments. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 1069–1087. doi:10.1037/0278-7393.31.5.1069
Iaria, G., Petrides, M., Dagher, A., Pike, B., & Bohbot, V. D. (2003). Cognitive strategies dependent on the hippocampus and caudate nucleus in human navigation: Variability and change with practice. Journal of Neuroscience, 23, 5945–5952.
Igloi, K., Zaoui, M., Berthoz, A., & Rondi-Reig, L. (2009). Sequential egocentric strategy is acquired as early as allocentric strategy: Parallel acquisition of these two navigation strategies. Hippocampus, 19, 1199–1211. doi:10.1002/hipo.20595
Ishikawa, T., & Montello, D. R. (2006). Spatial knowledge acquisition from direct experience in the environment: Individual differences in the development of metric knowledge and the integration of separately learned places. Cognitive Psychology, 52, 93–129. doi:10.1016/J.Cogpsych.2005.08.003
Klatzky, R. (1998). Allocentric and egocentric spatial representations: Definitions, distinctions, and interconnections. In C. Freksa, C. Habel, C. F. Wender (Eds.), Spatial cognition: An interdisciplinary approach to representation and processing of spatial knowledge (Vol. 1404, pp. 1–17). Berlin, Germany: Springer.
Kosslyn, S. M. (1996). Image and brain: The resolution of the imagery debate. Cambridge, MA: MIT Press.
Latini-Corazzini, L., Nesa, M. P., Ceccaldi, M., Guedj, E., Thinus-Blanc, C., Cauda, F., & Peruch, P. (2010). Route and survey processing of topographical memory during navigation. Psychological Research, 74, 545–559. doi:10.1007/s00426-010-0276-5
Lee, P. U., & Tversky, B. (2001). Costs of switching perspectives in route and survey descriptions. In J. D. Moore & K. Stenning (Eds.), Proceedings of the Twenty-Third Annual Conference of the Cognitive Science Society (pp. 574–579). Mahwah, NJ: Erlbaum.
Leiser, D., Tzelgov, J., & Henik, A. (1987). A comparison of map study methods—Simulated travel vs. conventional study. Cahiers de Psychologie Cognitive/Current Psychology of Cognition, 7, 317–334.
Moeser, S. (1988). Cognitive mapping in a complex building. Environment and Behavior, 20, 21–48.
Montello, D. R., Waller, D., Hegarty, M., & Richardson, A. E. (2004). Spatial memory of real environments, virtual environments, and maps. In G. L. Allen (Ed.), Human spatial memory: Remembering where (pp. 251–285). Mahwah, NJ: Erlbaum.
Mou, W., Fan, Y., McNamara, T. P., & Owen, C. B. (2008). Intrinsic frames of reference and egocentric viewpoints in scene recognition. Cognition, 106, 750–769. doi:10.1016/j.cognition.2007.04.009
Mou, W., McNamara, T. P., Rump, B., & Xiao, C. (2006). Roles of egocentric and allocentric spatial representations in locomotion and reorientation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32, 1274–1290. doi:10.1037/0278-7393.32.6.1274
Mou, W., McNamara, T. P., Valiquette, C. M., & Rump, B. (2004). Allocentric and egocentric updating of spatial memories. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30, 142–157. doi:10.1037/0278-7393.30.1.142
Newman, E. L., Caplan, J. B., Kirschen, M. P., Korolev, I. O., Sekuler, R., & Kahana, M. J. (2007). Learning your way around town: How virtual taxicab drivers learn to use both layout and landmark information. Cognition, 104, 231–253. doi:10.1016/j.cognition.2006.05.013
Noordzij, M. L., Zuidhoek, S., & Postma, A. (2006). The influence of visual experience on the ability to form spatial mental models based on route and survey descriptions. Cognition, 100, 321–342. doi:10.1016/j.cognition.2005.05.006
O’Keefe, J., & Nadel, L. (1978). The hippocampus as a cognitive map. Oxford, UK: Oxford University Press, Clarendon Press.
Packard, M. G., & McGaugh, J. L. (1996). Inactivation of hippocampus or caudate nucleus with lidocaine differentially affects expression of place and response learning. Neurobiology of Learning and Memory, 65, 65–72. doi:10.1006/nlme.1996.0007
Poucet, B. (1993). Spatial cognitive maps in animals: New hypotheses on their structure and neural mechanisms. Psychological Review, 100, 163–182. doi:10.1037/0033-295X.100.2.163
Richardson, A. E., Montello, D. R., & Hegarty, M. (1999). Spatial knowledge acquisition from maps and from navigation in real and virtual environments. Memory & Cognition, 27, 741–750
Rieser, J. J. (1989). Access to knowledge of spatial structure at novel points of observation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 15, 1157–1165. doi:10.1037/0278-7393.15.6.1157
Roskos-Ewoldsen, B., McNamara, T. P., Shelton, A. L., & Carr, W. (1998). Mental representations of large and small spatial layouts are orientation dependent. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 215–226. doi:10.1037/0278-7393.24.1.215
Rossano, M. J., West, S. O., Robertson, T. J., Wayne, M. C., & Chase, R. B. (1999). The acquisition of route and survey knowledge from computer models. Journal of Environmental Psychology, 19, 101–115.
Ruddle, R. A., Payne, S. J., & Jones, D. M. (1997). Navigating buildings in “desk-top” virtual environments: Experimental investigations using extended navigational experience. Journal of Experimental Psychology: Applied, 3, 143–159.
Ruddle, R. A., Payne, S. J., & Jones, D. M. (1999). The effects of maps on navigation and search strategies in very-large-scale virtual environments. Journal of Experimental Psychology: Applied, 5, 54–75. doi:10.1037/1076-898x.5.1.54
Shelton, A. L., & Gabrieli, J. D. E. (2002). Neural correlates of encoding space from route and survey perspectives. Journal of Neuroscience, 22, 2711–2717.
Shelton, A. L., & McNamara, T. P. (2004). Orientation and perspective dependence in route and survey learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30, 158–170. doi:10.1037/0278-7393.30.1.158
Shelton, A. L., & Pippitt, H. A. (2007). Fixed versus dynamic orientations in environmental learning from ground-level and aerial perspectives. Psychological Research, 71, 333–346.
Shemyakin, F. N. (1962). General problems of orientation in space and space representations. In B. G. Ananyev (Ed.), Psychological Science in the USSR (Vol. 1.). Tech. Rep. No. 11466. Arlington, VA: U.S. Office of Technical Reports. (NTIS No. TT62–11083).
Sholl, M. J. (1987). Cognitive maps as orienting schemata. Journal of Experimental Psychology: Learning, Memory, and Cognition, 13, 615–628. doi:10.1037/0278-7393.13.4.615
Siegel, A. W., & White, S. H. (1975). The development of spatial representations of large-scale environments. In H. W. Reese (Ed.), Advances in child development and behavior (Vol. 10, pp. 9–55). New York, NY: Academic Press.
Taylor, H. A., Naylor, S. J., & Chechile, N. A. (1999). Goal-specific influences on the representation of spatial perspective. Memory & Cognition, 27, 309–319. doi:10.3758/BF03211414
Taylor, H. A., & Tversky, B. (1992). Spatial mental models derived from survey and route descriptions. Journal of Memory and Language, 31, 261–292.
Thorndyke, P. W., & Hayes-Roth, B. (1982). Differences in spatial knowledge acquired from maps and navigation. Cognitive Psychology, 14, 560–589.
Tolman, E. C. (1948). Cognitive maps in rats and men. Psychological Review, 55, 189–208. doi:10.1037/h0061626
Tulving, E., & Thomson, D. M. (1973). Encoding specificity and retrieval processes in episodic memory. Psychological Review, 80, 352–373. doi:10.1037/h0020071
Tversky, B. (1992). Distortions in cognitive maps. Geoforum, 2, 131–138.
Valtchanov, D., Barton, K. R., & Ellard, C. (2010). Restorative effects of virtual nature settings. Cyberpsychology, Behavior and Social Networking, 13, 503–512. doi:10.1089/cyber.2009.0308
Waller, D., & Hodgson, E. (2006). Transient and enduring spatial representations under disorientation and self-rotation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32, 867–882.
Wang, R. F., & Spelke, E. S. (2002). Human spatial representation: Insights from animals. Trends in Cognitive Sciences, 6, 376–382. doi:10.1016/S1364-6613(02)01961-7
Wolbers, T., & Büchel, C. (2005). Dissociable retrosplenial and hippocampal contributions to successful formation of survey representations. Journal of Neuroscience, 25, 3333–3340. doi:10.1523/JNEUROSCI.4705-04.2005
Zhang, H., Copara, M. S., & Ekstrom, A. D. (2012). Differential recruitment of brain networks following route and cartographic map learning of spatial environments. PLoS ONE, 7, e44886. doi:10.1371/journal.pone.0044886
Author note
The authors thank John Beck and Evan Layher for assistance with the data. The authors also thank the Kahana lab for generously sharing software, and Colin Kyle for technical assistance. We also thank Weimin Mou and the UC–Davis Memory Group for helpful comments on an earlier draft of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhang, H., Zherdeva, K. & Ekstrom, A.D. Different “routes” to a cognitive map: dissociable forms of spatial knowledge derived from route and cartographic map learning. Mem Cogn 42, 1106–1117 (2014). https://doi.org/10.3758/s13421-014-0418-x
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-014-0418-x