
Abstract
Several studies support the psychological reality of a mental timeline that runs from the left to the right and may strongly affect our thinking about time. Ulrich and Maienborn (Cognition 117:126–138, 2010) examined the linguistic relevance of this timeline during the processing of past- and future-related sentences. Their results indicate that the timeline is not activated automatically during sentence comprehension. While no explicit reference of temporal expressions to the left–right axis has been attested (e.g., *the meeting was moved to the left), natural languages refer to the back–front axis in order to encode temporal information (e.g., the meeting was moved forward). Therefore, the present study examines whether a back–frontal timeline becomes automatically activated during the processing of past- and future-related sentences. The results demonstrate a clear effect on reaction time that emerges from a time–space association along the frontal timeline (Experiment 1). However, this activation seems to be nonautomatic (Experiment 2), rendering it unlikely that this frontal timeline is involved in comprehension of the temporal content of sentences.
Similar content being viewed by others

When we talk about time and temporal notions, we often use words that serve primarily to express spatial relationships; to look forward to welcoming you, to look back to the good old times, or to be years ahead are just a few illustrative examples. This kind of metaphoric time reference presumably indicates that we engage spatial representations in our minds when thinking about time. It has been argued that this mental reference to spatial representations is necessary because, in contrast to space, some aspects of time cannot be experienced but only imagined (Evans, 2006; Ornstein, 1969; Woodrow, 1951). For example, we can directly observe moving the car forward, yet we can only imagine moving forward the meeting (see Casasanto, Fotakopoulou, & Boroditsky, 2010). It has therefore been suggested that we draw on the mentally more accessible domain of space to enable our thinking about time (e.g., Boroditsky, 2000).
This idea that thinking about time is rooted in spatial representations has long been a subject of inquiry in philosophy, linguistics, and psychology (e.g., Boroditsky, 2000; Casasanto et al., 2010; Clark, 1973; Evans, 2006; Fraser, 1966; Haspelmath, 1997; Klein, 2009; Tversky, Kugelmass, & Winter, 1991). According to this view—also called the spatial metaphor of time (e.g., Clark, 1973, p. 50)—we heuristically use space to structure and conceptualize time. Spatial representations in our minds are most likely richer than temporal ones, because the former ones are built up through relatively concrete perceptuomotor experiences that we have when interacting with the environment (Talmy, 1988; see Kranjec & Chatterjee, 2010, for a critical review in the domain of cognitive neuroscience). In fact, several sources of converging evidence suggest that our representations of time depend on our representations of space. First, in natural languages across the world, the vocabulary of time has spatial roots (Haspelmath, 1997; Lakoff & Johnson, 1980; Núñez & Sweetser, 2006). For example, Haspelmath’s crosslinguistic survey of data from 53 different languages shows that the overwhelming majority of temporal expressions originate from spatial expressions. Second, young children acquire spatial expressions such as there and here earlier than the related temporal counterparts then and now (e.g., Clark, 1973; Graf, 2006; Weißenborn, 1988). This observation is consistent with the assumption that the domain of space has to be structured in children’s minds before they can process and express temporal relationships as effectively as spatial ones.
Furthermore, experiments with adults (Boroditsky, 2000; Casasanto & Boroditsky, 2008) and children (Casasanto et al., 2010) have shown that spatial information influences temporal judgments, but not the other way around. For example, the participants in Casasanto and Boroditsky’s study viewed a line on a computer screen and were asked to estimate either its duration of presentation on the screen or its spatial length. Although judgments about presentation duration were influenced by line length, judgments about line length were uninfluenced by presentation duration. Therefore, this asymmetrical influence between time and space not only emerges when people process linguistic stimuli, but is also found when people perform such a low-level psychophysical task. This indicates that the asymmetric linkage of time and space is established already at a nonlinguistic level of cognition, suggesting that it is a fundamental property of the human cognitive system. A variety of nonlinguistic tasks strengthen this view (e.g., Boroditsky, 2000; Fuhrman & Boroditsky, 2010; Ishihara, Keller, Rossetti, & Prinz, 2008; Lakens, Semin, & Garrido, 2011; Ono & Kawahara, 2007; Roussel, Grondin, & Killeen, 2009; Tversky et al., 1991; Vallesi, Binns, & Shallice, 2008; Xuan, Zhang, He, & Chen, 2007).
The claim that the linkage of time and space is a fundamental feature of our cognitive system has received strong support from recent reaction time (RT) studies (e.g., Santiago, Lupiáñez, Pérez, & Funes, 2007; Torralbo, Santiago, & Lupiáñez, 2006; Ulrich & Maienborn, 2010; Weger & Pratt, 2008). Torralbo et al. were the first to demonstrate a space–time congruency effect on RT. For example, in Experiment 1 of their study, participants viewed a face silhouette in side view looking to the right or to the left on a computer screen. A word referring either to the past or to the future (e.g., Spanish dijo, “he/she said” vs. dirá, “he/she will say”) was presented in front of or behind this face. Depending on the temporal reference of this word, participants were instructed to respond vocally either pasado (“past”) or futuro (“future”). A trial was front–back congruent when a future (past) word appeared in front of (behind) the face. The onset of the vocal responses was approximately 15 ms shorter on congruent than on incongruent trials. Their second experiment was identical to the first one, except that participants were now instructed to respond manually to the temporal content of the words. Specifically, participants responded with their left (right) hand to past (future) words. Surprisingly, the front–back congruency effect disappeared, and a left–right congruency effect appeared. This time, responses were about 15 ms shorter when participants responded with their left (right) hand to past (future) words than when the mapping of past and future to the two hands was reversed. Although the results of Torralbo et al.’s study clearly demonstrate a cognitive linkage between time and space, their results also indicate that space–time congruency effects may severely depend on the interaction of response modality and the conceptual projection of space to time (i.e., on front–back vs. left–right projection).
The front-back congruency effect originally reported in Torralbo et al. (2006) has been investigated with manual responses by Sell and Kaschak (2011). In this recent study, participants made sensibility judgments about sentences by moving their right hand either away from or toward their body. Sell and Kaschak presented their participants small texts consisting of three sentences, in which the second sentence expressed a time shift either to the past or to the future. In agreement with Torralbo et al.’s study, the temporal content of these critical sentences interacted with movement direction; RTs were shorter when past (future) was mapped on responses toward (away from) the body. This effect disappeared, however, when the time shift was small (e.g., 1 day versus 1 month) and when the responses were spatially arranged (i.e., one response hand located close to the body and the other one located farther away from the body).
Since the study of Torralbo et al. (2006), researchers have focused on the left–right congruency effect and have successfully replicated it for manual responses (Lakens et al., 2011; Santiago et al., 2007; Ulrich & Maienborn, 2010; Weger & Pratt, 2008). This space–time congruency effect on RT provides converging evidence for a left-to-right mental timeline, which seems to have its origin in the writing system of a culture (Fuhrman & Boroditsky, 2010; Ouellet, Santiago, Israeli & Gabay 2010b; Tversky et al., 1991). Consistent with such a left-to-right coding of time, sign languages make use of the left–right axis as well to refer to the temporal sequence of events (Emmorey, 2001). Furthermore, research employing event sequences in natural scenes has provided evidence that mental representations of such sequences unfold from left to right in our minds (Fuhrman & Boroditsky, 2010; Santiago, Román, Ouellet, Rodríguez, & Pérez-Azor, 2010). These additional results hint toward the assumption that this left–right mental timeline is involved in several cognitive functions and is not just an epiphenomenon without any cognitive purpose.
In their RT study, Ulrich and Maienborn (2010) examined the linguistic relevance of the mental timeline for the processing of sentences. Ulrich and Maienborn combined the methodology of previous RT studies with the sensibility judgment task employed by Glenberg and Kaschak (2002) and by Sell and Kaschak (2011). Their first experiment examined whether the left–right compatibility effect observed by Santiago et al. (2007) and by Torralbo et al. (2006) generalizes to the processing of complete sentences. On each trial, a sentence that referred either to the past (e.g., Mona and Diana danced the whole night through) or to the future (e.g., We will get off in Bonn in five minutes) was presented on a computer screen in front of the participant. In the congruent condition, participants responded with a left-hand (right-hand) keypress to sentences referring to the past (future). In the incongruent condition, this assignment was reversed. To make sure that participants processed the content of the sentence, nonsensical sentences (e.g., The fir trees have put on their coat while bathing) were presented on catch trials (see Glenberg & Kaschak, 2002), and participants were asked to refrain from responding in this case (i.e., sensibility judgment). Consistent with previous studies (i.e., Santiago et al., 2007; Torralbo et al., 2006; Weger & Pratt, 2008), RT was shorter for the left/past–right/future mapping than for the left/future–right/past mapping. This left–right congruency effect confirms the psychological reality of a left-to-right mental timeline even during the processing of whole sentences.
Experiments 2 and 3 in Ulrich and Maienborn’s (2010) study tested whether the temporal reference of a sentence produces automatic activation of the mental timeline. Participants in Experiments 2 and 3 judged the content of a sentence (i.e., sensible vs. nonsensical) but not its temporal relation to the past or the future. Therefore, the temporal information of the sentence was no longer task relevant. A space–time congruency in these experiments is usually seen in analogy to the SNARC effect (spatial numerical association of response codes; Dehaene, Bossini, & Gireaux, 1993) and the Simon effect (Simon & Rudell, 1967); both effects demonstrate that task-irrelevant information influences automatically the speed of a response. Thus, if sentence meaning were action based (e.g., Glenberg & Kaschak, 2002), it should be easier for participants to classify past-related sentences as sensible when they have to press the left key rather than the right key in response to sensible sentences. Analogously, processing of future-related sentences should be facilitated when they have to press the right rather than the left key in response to sensible sentences. Contrary to this prediction, the space–time congruency effect observed in Experiment 1 disappeared in these additional experiments, which argues against an automatic account.
The failure to find automatic response activation in Ulrich and Maienborn’s (2010) study could simply reflect the fact that a coding of time from left to right has no counterpart in natural languages. While virtually all languages have explicit spatial means to refer to time (see above), there seems to be no single language that employs the concepts of left and right for the expression of time. For instance, while one frequently encounters expressions like the day before Christmas, no case of an expression like *the day to the left of Christmas is attested across the languages of the world (e.g., Haspelmath, 1997; Radden, 2004). In his crosslinguistic survey of spatial metaphors of time, Radden (2004, p. 228) therefore concluded that “the lateral axis with a left–right orientation . . . does not seem to offer any sensible spatial basis for our understanding of time at all” (see also Haspelmath, 1997, p. 22). Yet expressions like the summer term lies behind us or the winter term lies before us are commonplace. Thus, in languages worldwide, there is a strong tendency toward the use of the back–front axis where the future is mapped onto the front and the past onto the back (see Haspelmath, 1997; Radden, 2004; Traugott, 1978; see, however, Núñez & Sweetser, 2006, for a reversed mapping of past and future along the back–front line in the Amerindian language Aymara).Footnote 1 In conclusion, if processing of temporal sentence information automatically activates the front-back axis, a front–back congruency effect should emerge even when the temporal content of the sentence is task irrelevant.
One might be inclined to assume that Sell and Kaschak (2011) and Torralbo et al. (2006) provided evidence for an automatic activation of the front–back axis. However, such a conclusion is premature. First, the study of Sell and Kaschak demonstrated a front–back congruency effect only when participants build up a discourse model. In this case, a sufficiently large time shift during the discourse may well activate spatial schemata—for example, when one tries to mentally integrate the temporal sequence of events of a narrative text. In this case, participants may organize these events along a mental timeline, which, in turn, may activate spatial schemata. This does not mean, however, that the processing of a single sentence itself would automatically activate the front–back timeline. Second, the front–back congruency effect reported by Torralbo et al. in their first experiment may be attributed to the linguistic nature of the vocal response, rather than to the linguistic stimulus that appeared before or behind the face silhouette. This account received support from the data of their second experiment with manual responses, because in this case, the front–back congruency was no longer observed (we will return to these points in the General discussion section).
The present RT study examined the linguistic relevance of a front–back mental timeline for the processing of whole sentences. The experimental design emulated the design in Ulrich and Maienborn (2010). Unlike in their design, responses were arranged along the frontal (back–front) line before the participants, instead of the lateral (left–right) line before the participants. A device was employed that required a hand movement to the back (i.e., a movement toward the participant) or to the front (i.e., a movement away from the participant) when a sentence referred to the past or to the future. Thus, we used a single-hand movement, as in the study of Sell and Kaschak (2011). In Experiment 1, we examined whether a space–time congruency effect on manual RT exists for the front–back axis. The existence of this effect has to be established to address the major objective of this study—namely, whether or not this effect is the sign of an automatic activation process. Experiment 2 was designed to test whether or not the mental timeline becomes automatically activated during sentence processing, by using a purely implicit RT task.
Experiment 1
In each trial of the present experiment, a sentence that referred either to the past or to the future was presented on a computer screen in front of a participant. In the congruent condition, the participant responded with a movement toward the back to past-related sentences and with a movement toward the front to future-related sentences. In the incongruent condition, this assignment was reversed; that is, participants responded with a backward movement to a future-related sentence and with a forward movement to a past-related sentence. As in Ulrich and Maienborn (2010, Experiment 1), nonsensical sentences were presented on one half of all trials, and participants were to refrain from responding to those. If the space–time congruency effect on RT reported by Ulrich and Maienborn generalizes to the back–front dimension, RT should be shorter for the back–past and front–future mapping than for the back–future and front–past mapping.
Method
Participants
Sixty volunteers participated in this 60-min experiment. All were native speakers of German and received either course credit or payment for their participation. Due to high error rates (fewer than 90% correct trials), 2 volunteers were excluded from the analysis, reducing the total number of participants to 14 men and 44 women (M = 25.9 years, SD = 7.9 years). All but 6 participants reported being right-handed. They reported normal hearing and normal or corrected-to-normal vision. Participants were naïve with respect to the experimental hypothesis.
Stimuli and apparatus
The experiment was run in a sound-attenuated, dimly illuminated room. Sentences were presented on a monitor at a viewing distance of 60 cm. Each sentence was displayed in black (0.23 cd/m²) against a white background (201 cd/m²) in the middle of a computer screen (standard VGA screen, 60 Hz), using 15-point Arial font.
The same sentences were used in this experiment as by Ulrich and Maienborn (2010). Sixty of them were sensible sentences referring to the future (SF), 60 were sensible sentences referring to the past (SP), 60 were nonsensical sentences referring to the future (NF), and 60 were nonsensical sentences referring to the past (NP) (see Table 1 for illustrations).
The response device recorded continuous movements of the manual response in the horizontal plane (Fig. 1). The device was 62.2 cm long and 12 cm wide. It consisted of a metal platform with a slider attached to a handle (2.9 cm in diameter). The handle could be used to move the slider horizontally in both directions along a straight track up to the respective end of the apparatus. The start position was the center position on the track; a spring kept the slider in that position. The device was located in front of the participant along the midsagittal plane, with the track being oriented in parallel to this plane. Participants operated the slider with their dominant hand.

Response device used for Experiments 1 and 2
Touch-sensitive devices registered the onset of the response (i.e., when the slider began to be moved from its start position) and the time when the slider reached one of the two endpoints of the track. We measured the RT required from the onset of the presentation of the sentence to the onset of the response, as well as the movement time (MT) required from response onset to one of the two endpoints.
Procedure and design
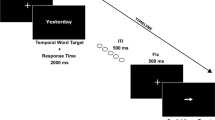
Participants were given written information about the task and the stimulus–response (S–R) mappings. The instructions emphasized that the response should be performed as quickly and accurately as possible. Each trial began with the presentation of a white screen for 2,000 ms. Then a fixation cross appeared for 200 ms in the center of the screen. After an interval of 500 ms, the sentence appeared in the middle of the screen for 4,000 ms or until response onset. With equal probability, the sentence presented was SF, SP, NF, or NP. Participants were instructed to respond if the presented sentence was a sensible sentence, but not to respond if it was a nonsensical sentence (no-go trials). They were asked to respond with a forward or a backward movement. A wrong response (i.e., incorrect response or no response if a sensible sentence was presented) was indicated by a 500-ms tone (440 Hz). Participants had 6,000 ms for the total response: 4,000 ms for the forward or the backward movement and 2,000 ms to move the slider back to the start position. Once the slider had returned to the start position, the next trial started. If no response occurred (i.e., nonsensical sentences were presented), the next trial started after the offset of the sentence.
The experiment consisted of two parts. Each part included 248 trials and started with a practice block of 8 trials (with 2 SP, 2 SF, 2 NP, and 2 NF sentences), which was followed by the experimental block consisting of 240 experimental trials (with 60 SP, 60 SF, 60 NP, and 60 NF sentences). A short rest separated the two parts. Participants initiated the second part by pressing the space key on the computer keyboard. The same set of sentences was used in both parts. In one part, participants performed a forward movement in response to SF and a backward movement in response to SP (congruent condition). In the other part, a forward movement was performed in response to SP, and a backward movement in response to SF (incongruent condition). Half of the participants (Group A) started with the congruent condition, and the other half (Group B) with the incongruent condition.
Results and discussion
Separate analyses of variance (ANOVAs) including the within-subjects factors of movement direction (back vs. front) and temporal reference (past vs. future) and the between-subjects factor of group (A vs. B) were performed on RT, MT, and the percentage of correct (PC) responses. Additionally, a separate by-item ANOVA including the same factors was conducted for all dependent variables. We adopt the common practice in psycholinguistics and report only those effects as being statistically reliable for which each of the two ANOVAs yielded a significant effect. Figure 2 depicts the mean of each variable as a function of movement direction and temporal reference, and Table 2 contains the means of RT, MT, and PC for all factorial combinations.

Mean reaction times (RTs; upper panel), mean movement times (MTs; middle panel), and mean percentages of correct responses (PCs; lower panel) as a function of movement direction and temporal reference in Experiment 1. The standard error (SE) of each mean was computed from the mean square error for the interaction of the factors movement direction and temporal reference as recommended by Loftus and Masson (1994) and by Masson and Loftus (2003). Note that this SE is particularly appropriate for assessing the interaction of these two factors. Each point shows mean ± 1SE

Mean reaction times (RTs; upper panels), mean movement times (MTs; middle panels), and mean percentages of correct responses (PCs; lower panels) as a function of movement direction and temporal reference in Experiment 2, separately for sensible sentences (left panels) and nonsensical sentences (right panels). The standard error (SE) of the mean was computed from the mean square error for the interaction of the factors movement direction and temporal reference as recommended by Loftus and Masson (1994) and by Masson and Loftus (2003). Note that this SE is particularly appropriate for assessing the interaction of these two factors. Each point shows mean ± 1SE
RT The overall mean RT by participant was 2,014 ms. Consistent with Ulrich and Maienborn (2010), shorter RTs were associated with SP sentences than with SF sentences (1,990 vs. 2,037 ms), F 1(1, 56) = 38.27, p < .001; F 2(1, 118) = 1.71, p = .193. Neither the main effect of group nor that of movement direction was significant.
Most important, a significant space–time congruency effect emerged, which is reflected in a significant interaction between movement direction and temporal reference, F 1(1, 56) = 4.39, p = .041; F 2(1, 118) = 56.38, p < .001.Footnote 2 More precisely, participants responded faster to SF sentences when they had to push the slider forward than when they had to pull it back (2,015 vs. 2,059 ms), whereas they responded faster to SP sentences when they had to pull the slider back than when they had to push it forward (1,967 vs. 2,013 ms).
There were further interaction effects on RT, which all can be attributed to practice effects. Note that the present experiment employed a counterbalanced design in order to control for practice effects, which are commonly observed in designs with repeated measures. In these designs, practice is necessarily confounded with order effects. Thus, in the present design, practice effects are captured by interactions that include the between-factor group. Correspondingly, three significant interactions involving group as a factor revealed such practice effects. First, there was a three-way interaction between movement direction, temporal reference, and group, F 1(1, 56) = 82.16, p < .001, F 2(1, 118) = 381.72, p < .001. This interaction can be attributed to an overall effect of practice on RT, because practice is confounded with this interaction rather than being a separate factor in the ANOVA design. Overall, RT decreased from 2,110 ms in the first half of the experiment to 1,916 ms in the second half. This practice effect counteracted the space–time congruency effect (i.e., movement direction × temporal reference interaction) when the congruent condition was performed in the first half and the incongruent one in the second half (i.e., Group A), whereas it inflated the space–time congruency effect (i.e., movement direction × temporal reference interaction) when these conditions were performed in the reverse order (Group B), creating a group × congruency interaction (i.e., group × movement direction × temporal reference interaction). An additional inspection of the data suggests that the congruency effect emerges in the second half of the experiment, which might be attributed to the influence of practice and, thus, depend on the overall response speed. Although this dependency is counterintuitive, such a dependency has also been observed in other paradigms (e.g., De Jong, Liang, & Lauber, 1994).
Second, a small yet statistically reliable interaction of movement direction and group revealed that SF sentences benefited more (about 30 ms) from practice than did SP sentences, F 1(1, 56) = 5.83, p = .019; F2(1, 118) = 4.36, p = .039. Finally, the interaction between temporal reference and group can be attributed to a larger practice effect for backward than for forward movements, F 1(1, 56) = 18.14, p < .001; F 2(1, 118) = 4.36, p = .039.
MT The overall mean MT by participant was 296 ms. MT was affected by movement direction, showing shorter MTs for movements toward the back than for movements toward the front (280 vs. 311 ms), which can be attributed to a biomechanical difference between these two types of movements, F 1(1, 56) = 46.10, p < .001; F2(1, 118) = 1,091.23, p < .001. There was a significant three-way interaction between movement direction, temporal reference, and group, again reflecting a practice effect, F 1(1, 56) = 15.50, p < .001; F 2(1, 118) = 512.87, p < .001, because MT was shorter in the first than in the second half of the experiment (307 vs. 284 ms).
PC Participants correctly refrained from responding when a nonsensical sentence appeared on the screen on 98.8% of all nonsensical trials. They correctly refrained from responding on 99.3% of the NP trials and 98.4% of the NF trials. When a sensible sentence was presented, participants moved the slider in the correct direction on 94.3% of the sensible trials.
A three-way interaction between movement direction, temporal reference, and group was the only significant effect, F 1(1, 56) = 23.28, p < .001; F 2(1,118) = 27.53, p < .001. This interaction reflects again a practice effect; that is, more responses that were correct were made in the second than in the first half of the experiment (95.5% vs. 93.1%).
In summary, the experiment clearly supports the existence of a back-to-front mental timeline, showing faster responses when the response mapping between temporal information and movement direction was congruent rather than incongruent. Specifically, when a past-related sentence required a movement toward the back and a future-related sentence required a movement toward the front, mean RT was shorter than when this response mapping was reversed. The additional finding that participants responded faster to SP than to SF sentences may simply reflect the fact that future-related sentences tend to be somewhat longer than past-related ones (cf. Ulrich & Maienborn, 2010); this effect, however, is not of particular theoretical interest here.
We have replicated the result pattern of Experiment 1 in another experiment which employed a new sample of 40 participants. In contrast to Experiment 1, this additional experiment used a set of sentences with subject–object–verb word order (SOV), as is typical for German subordinate clauses (instead of SVO order, as in Experiment 1). As in Experiment 1, a significant space–time congruency effect was obtained, F 1(1, 38) = 4.44, p = .04; F 2(1, 110) = 56.83, p < .001. In addition, a three-fold interaction between group, movement direction, and temporal reference emerged again, F 1(1, 38) = 85.14, p < .001; F 2(1, 110) = 884.56, p < .001. As in Experiment 1, an additional inspection of the data revealed that the congruency effect of temporal reference and movement direction was modulated by practice. Therefore, the results of this additional experiment show that the result pattern observed in Experiment 1 is stable and, thus, ensure the conclusions drawn from this experiment.
Experiment 2
The major result of Experiment 1 is consistent with a back-to-front mental representation of time, which can be attributed to a preexperimental cognitive linkage between the dimensions of space and time. The main goal of Experiment 2 was to investigate in more detail the nature of this congruency effect. More specifically, Experiment 2 examined whether the congruency effect obtained in Experiment 1 is the sign of an automatic activation process.
In Experiment 2, we merged two successful experimental paradigms of RT research. First, Experiment 2 emulated the design of a SNARC paradigm (Dehaene et al., 1993). If spatial schemata become automatically activated during the processing of temporal sentence information, the space–time congruency effect observed in Experiment 1 should also emerge in a task when temporal information is task irrelevant, analogous to the SNARC effect (Dehaene et al., 1993) or to the Simon effect (Kornblum, Hasbroucq, & Osman, 1990). Specifically, participants performed a judgment about the sense of the sentence, but not about its relation to the past or the future. Thus, the temporal information of a sentence was no longer a task-relevant dimension for selecting the correct response. If the mechanism underlying the space–time congruency effect, however, becomes active as soon as temporal information is processed, one should also observe a space–time congruency effect on RT under this SNARC-like paradigm. To be more accurate, one should still observe an RT benefit of responding to sensible SP sentences with a movement toward the back rather than toward the front. Analogously, processing of sensible SF sentences should be facilitated when they require a movement toward the front rather than toward the back.
Second, in order to make sure that participants did not merely read the sentence without processing their temporal meaning, we adapted the dual-task procedure in Ouellet, Santiago, Funes, and Lupiáñez (2010a). In their first experiment, for example, they investigated whether the temporal reference (past or future) of a word in working memory may orient visual attention (to left or right, respectively) and thus affect RT to a dot that appeared on the left or the right on a screen before the participant. Words were presented shortly before the appearance of the dot. After the dot localization task, participants were probed about the temporal reference of the word. The purpose of this secondary task was to ensure that participants paid attention to temporal reference of the word in working memory. We also included this secondary task in the design of Experiment 2 to make sure that participants explicitly processed the temporal content of the sentence, although the results of Sell and Kaschak (2011) suggest that this is not essential in order to elicit a congruency effect. Although the temporal content of the sentences is task relevant only for the secondary task, temporal sentence information cannot be ignored while the sentence is read. Therefore, if processing of this temporal information would automatically activate the mental timeline, it should elicit a congruency effect, as in Sell and Kaschak’s experiment.
Method
Participants
Sixty-two volunteers participated in this 75-min experiment. They all were native speakers of German and again received either course credit or payment for their participation. Due to high error rates (fewer than 90% correct trials), the data of 6 volunteers were excluded from the analysis, reducing the total number of participants to 15 men and 41 women (M = 22.9 years, SD = 2.7 years). All but 8 participants reported being right-handed. They reported normal hearing and normal or corrected-to-normal vision. None of these 56 volunteers had participated in the previous experiment.
Stimuli and apparatus
The stimuli and apparatus were the same as in Experiment 1. In addition, a standard keyboard was used.
Procedure and design
The procedure and design were the same as in Experiment 1, except for the following two changes. First, participants were asked to move the response slider in one direction if the content of a sentence was sensible (SP or SF) and in another direction if the content was nonsensical (NP or NF). In one part of the experiment, half of the participants (Group A) performed a forward movement in response to a sensible sentence and a backward movement in response to a nonsensical sentence. As soon as participants started to move the slider, the sentence disappeared. The S–R assignment was switched in the second part. The other half of the participants (Group B) proceeded in the reverse order. Note that there were no no-go trials in this experiment. Second and analogous to the design in Ouellet, Santiago, Funes, and Lupiáñez (2010a), after participants had completed the slider movement, a question concerning the temporal reference of the preceding sentence appeared in the center of the screen. The question consisted of one word and was with equal probability either “Zukunft?” (future) or “Vergangenheit?” (past). Participants were asked to press the space bar of the keyboard if the answer to this question would be yes and to refrain from responding otherwise. The next trial started after the keyboard response or 3,000 ms after the onset of the question if no response was made. A wrong response was indicated by a 500-ms tone (440 Hz).
Results
Separate ANOVAs containing the within-subjects factors of temporal reference (past vs. future), movement direction (back vs. front), and sentence content (sensible vs. nonsensical) and the between-subjects factor of group (A vs. B) were performed on mean RT, MT, and PC. As in Experiment 1, a separate by-item ANOVA including the same factors was also conducted for all dependent variables. Figure 3 depicts the mean of RT, MT, and PC as a function of movement direction and temporal reference, separately for sensible and nonsensical sentences. In addition, Table 3 contains the means of these variables for all factorial combinations.
RT The overall mean RT by participant was 1,818 ms. RT was again shorter for past-related than for future-related sentences (1,781 vs. 1,855 ms), F 1(1, 54) = 268.16, p < .001; F 2(1, 236) = 11.70, p < .001. There was no further significant main effect. Theoretically most important, however, the two-way interaction between movement direction and temporal reference was far from being statistically significant, F 1(1, 54) = 0.66, p = .42; F 2(1, 236) = 0.76, p = .38.
There were three interaction effects, and these were all due to practice. First, the significant interaction of sentence content, movement direction, and group shows that mean RT decreased from 1,939 ms in Block 1 to 1,707 ms in Block 2, F 1(1, 54) = 141.37, p < .001; F 2(1, 236) = 1,042.13, p < .001. The size of this practice effect is similar to the one in Experiment 1. Second, the four-way interaction between temporal reference, movement direction, sentence content, and group revealed, analogous to Experiment 1, a larger (by about 30 ms) practice effect for future-related than for past-related sentences, F 1(1, 54) = 16.28, p < .001; F 2(1, 236) = 6.44, p = .01. Finally, the significant two-way interaction of movement direction and group, F 1(1, 54) = 9.57, p = .003; F 2(1, 236) = 9.28, p = .002, shows that the sensible sentences benefited more (about 50 ms) from practice than did the nonsensical ones.
MT The overall mean MT by participant was 348 ms. MT was affected by sentence content, showing slightly shorter MTs for sensible sentences than for nonsensical ones (347 vs. 350 ms), F 1(1, 54) = 4.34, p = .04; F 2(1, 236) = 19.77, p < .001. As in Experiment 1, MT was also affected by movement direction, with shorter MTs for movements toward the back than for movements toward the front (338 vs. 358 ms), F 1(1, 54) = 46.06, p < .001; F 2(1, 236) = 1,074.86, p < .001. Also as in Experiment 1, there was a significant three-way interaction between movement direction, sentence content, and group, which was due to faster responses in the second part than in the first part of the experiment (340 vs. 353 ms ), F 1(1, 54) = 7.57, p = .008; F 2(1, 236) = 517.40, p < .001. Movement direction and sentence content produced a significant interaction in the by-item analysis, F 2(1, 236) = 123.1, p < .001, but only a marginally significant interaction in the by-participant analysis, F 1(1, 54) = 3.39, p = .07.
PC Participants moved the slider in the correct direction and responded correctly to the question on 95.7% of the trials. PC was affected by sentence content; that is, participants made more correct responses for sensible sentences than for nonsensical ones (96.4 vs. 95.0%), F 1(1, 54) = 22.36, p < .001; F 2(1, 236) = 7.90, p = .005. The three-way interaction between movement direction, sentence content, and group reflects a practice effect, showing that participants made more correct responses in the second part than in the first part of the experiment (96.3 vs. 95.1%), F 1(1, 54) = 10.00, p = .003; F 2(1, 236) = 16.87, p < .001. The interaction of sentence content and temporal reference yielded a significant effect for the by-participant analysis, F 1(1, 54) = 5.07, p = .03, yet no significant effect for the by-item analysis, F 2(1, 236) = 0.91, p = .34.
In sum, the results of Experiment 2 are consistent with the notion that the space–time congruency effect observed in Experiment 1 is not the sign of an automatic process. Therefore, the back-to-front mental timeline seems to facilitate the S–R coding for selecting the appropriate response, suggesting that it is easier to process this coding when future is mapped to the front and past is mapped to the back. However, as is shown in this experiment, this mapping seems not to be activated automatically.
These results were successfully replicated in a further experiment without the question at the end of the trial concerning the temporal reference of the sentence. Therefore, it seems unlikely that the additional question in Experiment 2 produced some interference effect, which might have concealed a space–time congruency effect. In this additional experiment, a new sample of 60 participants was tested. The experiment was identical to Experiment 2, with the exception that participants did not have to judge the temporal reference of the sentence at the end of a trial. As in Experiment 2, the interaction between the factors movement direction and temporal reference was far from being statistically significant, F 1(1, 58) = 0.05, p = .817; F 2(1, 236) = 0.01, p = .92. Therefore, the null result of this additional experiment confirms the outcome of Experiment 2.
General discussion
Previous RT studies have shown that people code time from right to left (e.g., Ouellet, Santiago, Funes, & Lupiáñez, 2010a; Ouellet Santiago, Israeli, & Gabay, 2010b; Santiago et al., 2007; Torralbo et al., 2006; Ulrich & Maienborn, 2010; Vallesi et al., 2008; Weger & Pratt, 2008), at least in cultures with a left-to-right writing system (Fuhrman & Boroditsky, 2010; Ouellet, Santiago, Israeli, & Gabay, 2010b). These studies have demonstrated that responses to past- and future-related linguistic information are generally faster when the response direction is compatible with the left-to-right mental timeline than when it is not. Strangely enough, this left-to-right coding has no counterpart in the inventory of temporal expressions in the languages all over the world. Instead, we quite frequently encounter an association of time with the back–front axis. Future is commonly associated with the front, and past with the back (see Haspelmath, 1997; Radden, 2004; Traugott, 1978; see also Núñez & Sweetser, 2006, for a discussion of the prominent exception Aymara). The present study investigated the linguistic relevance of this back–front mental timeline for the processing of past- and future-related sentences.
More precisely, the present study had two goals. First, it examined whether this conjectured back-to-front mental timeline is involved when people process complete sentences. Second and theoretically most crucially, the study assessed whether processing sentences automatically activates this back-to-front mental timeline. Such a result would provide strong evidence for the hypothesis that activation of a back–front timeline is involved in sentence processing and, thus, in the comprehension of a sentence’s content.
Experiment 1 was analogous to the first experiment reported in Ulrich and Maienborn (2010). Participants were asked to move a slider forward or backward in response to past- or future-related sensible sentences. A clear front–back congruency effect on RT was obtained, supporting the assumption that processing of temporal sentence information activates spatial schemata even for manual push and pull responses (cf. Torralbo et al., 2006). In contrast to RT, the time required to move the slider from its middle starting position to its proximal or distal goal was not significantly influenced by the spatial mapping of future and past to the front and to the back.Footnote 3 This indicates that the relevant spatial schema operates entirely on cognitive processes that precede the initiation of the response, rather than on late motor processes that are involved in guiding the overt response (cf. Ulrich, Giray, & Schäffer, 1990).
Experiment 2 examined whether understanding a temporally located sentence would automatically activate the back–front timeline. If spatial schemata are involved in the processing of temporal sentence information, the space–time congruency effect on RT should also emerge in a task when time–space association is task irrelevant, similar to the SNARC effect (Dehaene et al., 1993) or to the Simon effect (Kornblum et al., 1990). As in Ulrich and Maienborn’s (2010) study, however, the effect disappeared when participants classified the displayed sentences according to their meaning (sensible vs. nonsensical), rather than their temporal content (past or future related). It seems difficult to attribute this outcome to not paying attention to temporal sentence information, since participants had to process this information for the secondary task. It is also unlikely that the secondary task inferred with the primary one, because an additional experiment without the secondary task produced virtually identical results. Hence, this pattern of results suggests that a congruency effect does not emerge when the temporal reference of the sentence is not task relevant (see note 3).
The results of Experiment 2 are consistent with a nonautomatic account of the space–time congruency effect. This conclusion also fits in with the weak view of the metaphoric mapping hypothesis that was originally suggested by Boroditsky (2000, p. 4). This view holds that spatial schemata are needed only to establish temporal representations. Once these representations are available within the cognitive system, the spatial domain is no longer required to think about time, and thus the mental representation of time may be entirely separated from sensory and motor information (cf. Mahon & Caramazza, 2008). By contrast, the strong version of the metaphoric mapping hypothesis maintains that thinking about time always requires the activation of spatial schemata. Therefore, it seems possible that participants in the more implicit task of Experiment 2 did not need to activate spatial schemata in order to perform this task, whereas in Experiment 1, the activation of spatial metaphors or preexperimental time–space linkages may have helped to increase task performance.
For example, according to the memory account of Ulrich and Maienborn (2010), response selection in Experiment 1 is particularly efficient when salient features of the stimulus (i.e., past and future) and of the response (i.e., back and front) correspond to each other (Proctor & Cho, 2006). Thus, participants could employ the preexperimental cognitive linkage between space and time to memorize and, thus, enhance the mapping of temporal sentence information (past vs. future) onto the spatially arranged responses (left vs. right). Memorizing the S–R mapping would be more efficient and, thus, would involve especially fast responses when participants can build on the preexperimental linkage between space and time, as in the congruent condition in Experiment 1.
Although this memory account is consistent with the results of the present study, it is at variance with results reported by Torralbo et al. (2006, Experiment 1). As was reviewed in the introduction, participants responded vocally with the words “past” and “future” to the temporal meaning of words, instead of with spatially arranged responses, as in most other RT studies investigating this topic. Therefore, participants in the study of Torralbo et al. did not need to memorize any S–R mapping that involved a spatial S–R relation. Nevertheless, participants’ responses were faster when future (past) words were presented in front (back) of the silhouette than when this mapping was reversed. This result argues against a memory account of the space–time congruency effect on RT. One must bear in mind that several experimental differences exist between the study of Torralbo et al., the present one, and the study of Ulrich and Maienborn (2010). For example, the vocal responses “past” and “future” may activate spatial schemata rather than the temporal reference of the target word. Therefore, the front–back congruency effect obtained in their first experiment might be attributed to the temporal content of the vocal responses (similar to a Stroop effect), rather than to the temporal reference of the target words. Consistent with this view, the front–back congruency effect disappeared in their second experiment, when participants made manual rather than vocal responses.
In addition, the results of Experiment 2 seem at variance with the results of Sell and Kaschak (2011). In their study, participants made categorical sensibility judgments about sentences that did not require participants attending explicitly to the temporal information of a sentence, as in Experiment 1. The task in Experiment 2 of the present study was less implicit, because participants had to process a sentence’s temporal information for performing the secondary task. These results are not contradictory but, rather, reflect task context. The results of Sell and Kaschak’s study indicate that the back–front axis becomes activated during text comprehension when a sentence like (2) is processed, which expresses a sufficiently large time shift in a narrative text such as in the following three-sentence story (adapted from Sell & Kaschak, 2011):
-
(1)
Jackie is taking a painting class.
-
(2)
Next month, she will learn about paintbrushes.
-
(3)
It is important to learn paintbrush techniques.
Spatial schemata may help to build up a discourse model, for example, by ordering the temporal events in this text along a mental timeline. By contrast, comprehending the content of a single, isolated sentence may not involve such excessive ordering of temporal events. Therefore, the results of Sell and Kaschak are not at variance with our major conclusion—namely, that the understanding of isolated sentences (i.e., the processing of grammatically and lexically supplied temporal information at sentence level) does not require the activation of spatial schemata. Future research is required to test this hypothesis—namely, that spatial schemata may be activated during the buildup of a discourse model, but not during the processing of a single sentence.
Furthermore, the present results rule out an alternative account of the left–right congruency effect observed in previous RT studies.Footnote 4 This alternative assumes that the space–time congruency effect on RT can be attributed to a mapping of space to emotional valence, instead of to a direct metaphoric mapping of space to time. For example, Casasanto (2009) found that right-handers tend to draw “good” animals on the right, whereas left-handers prefer to draw them on the left. Accordingly, the left (right) side tends to be associated with negative (positive) valence. Assume that participants link future with positive stimuli and the past with negative ones. In this case, the space–time congruency effect would be mediated by the mapping of space to emotional valence, rather than to space directly. A linkage between temporal connotation and emotional valence predicts, however, a front–back congruency effect of time that is opposite to the one observed in Experiment 1. Specifically, performance is usually better when positive stimuli are linked to a movement toward the body and negative stimuli are linked to a response away from the body (e.g., Chen & Bargh, 1999; Duckworth, Bargh, Garcia, & Chaiken, 2002). According to this alternative account, responses should be especially fast when future is linked to a movement toward the body and past away from it. This prediction was, however, disconfirmed by the results of Experiment 1, rendering it unlikely that the space–time congruency effect is mediated by emotional valence. In addition, this alternative account seems also to be at variance with RT results that show that the writing system of a culture determines direction of the mental time line (Fuhrman & Boroditsky, 2010; Ouellet, Santiago, Israeli, & Gabay, 2010b). This would imply that the writing direction of a culture modulates the association of future and past with positive and negative valence. This, however, seems unreasonable, because valence is not linked to body side for right- and left-handers alike (de la Vega, De Filippis, Lachmair, Dudschig, & Kaup, 2011).
In summary, our study demonstrated a clear space–time congruency effect during online processing of sentences. In contrast to previous studies (Ouellet, Santiago, Funes, & Lupiáñez, 2010a; Santiago et al., 2007; Weger & Pratt, 2008), a back–front response dimension was used, rather than a left–right dimension, for classifying temporal sentence information. From a psycholinguistic point of view, the back–front dimension is particularly relevant because almost all languages of the world associate future (past) with front (back). Therefore, if the association with a mental timeline were functional for the comprehension of temporal expressions, the back–front orientation of the mental timeline would be better suited than the left–right orientation to detect its activation during online sentence processing.Footnote 5 Consistent with the notion of a back–front mental timeline, faster responses occurred for the past–back and future–front mapping than for the reverse mapping. As in Ulrich and Maienborn’s (2010) study, this space–time congruency effect on RT disappeared when temporal sentence information was no longer task relevant for classifying the meaning of sentences. This particular result suggests that the back–front timeline may not be involved when people process the temporal meaning of a sentence.
In addition to this conclusion of the psycholinguistic relevance of the mental timeline, we strongly believe that null effects in experiments with high statistical power (i.e., small SEs, such as in Experiment 2) are of particular theoretical importance in the field of embodied cognition. Such effects help to demonstrate the limits of the tasks conforming to the predictions of the embodied cognition approach. This is especially true if experiments employ a design analogous to the one that has produced clear RT effects for a related issue (SNARC) in previous research. Not taking into account such null effects would bias research and create the exaggerated view that embodied effects are ubiquitous phenomena (see also Fiedler, 2011). Our research clearly casts doubt on such a view.
Notes
Boroditsky and Gaby (2010) examined the cognitive representation of time in Pormpurraaw, which is a remote Australian Aboriginal community. This community uses predominantly an absolute spatial representation system, and, accordingly, it represents time from east to west and, thus, not with respect to the body, as is the case in the representation of time in other cultures.
The lmer function of the lme4 package (Bates, Maechler, & Bolker, 2011) in the open source statistical programming environment R (R Development Core Team, 2011) was used to fit a mixed-effects model to the data set. The model contained the within-subjects factors direction of movement (back vs. front) and temporal reference (past vs. future), as well as the between-subjects factor order of conditions (congruent–incongruent vs. incongruent–congruent). Participants as well as items were treated as random variables. Consistent with the F 1/F 2 analysis, a highly significant space–time congruency effect emerged also in this mixed-effects model, t = 5.02, p < .001.
We carried out a further ANOVA that included experiment (Experiment 1 vs. Experiment 2 plus the control experiment without the secondary task) as an additional between-subjects factor. This analysis revealed a significant three-way interaction of factors experiment, movement direction, and temporal content, F 1(1, 170) = 5.60, p = .02; F 2(1, 472) = 13.03, p < .001.
We thank Diane Pecher for pointing out this alternative account.
We conducted an additional study (n = 44) to compare the space–time congruency effect between the back–front axis and the left–right axis. This experiment revealed again a highly significant space–time congruency effect on RT. However, movement axis did not modulate the size of the congruency effect. Consequently, this additional experiment showed that the size of the congruency effect is not more pronounced for the front–back direction than for the left–right direction, as one might expect, because German uses the back–front axis in metaphoric speech.
References
Bates, D., Maechler, M., & Bolker, B. (2011). lme4: Linear mixed-effect models using S4 classes. R package version 0.999375-39.
Boroditsky, L. (2000). Metaphoric structuring: Understanding time through spatial metaphors. Cognition, 75, 1–28.
Boroditsky, L., & Gaby, A. (2010). Remembrances of times east: Absolute spatial representations of time in an Australian Aboriginal community. Psychological Science, 21, 1635–1639.
Casasanto, D. (2009). Embodiment of abstract concepts: Good and bad in right- and left-handers. Journal of Experimental Psychology: General, 138, 351–367.
Casasanto, D., & Boroditsky, L. (2008). Time in the mind: Using space to think about time. Cognition, 106, 579–593.
Casasanto, D., Fotakopoulou, O., & Boroditsky, L. (2010). Space and time in the child's mind: Evidence for a cross-dimensional asymmetry. Cognitive Science, 34, 387–405.
Chen, M., & Bargh, J. A. (1999). Consequences of automatic evaluation: Immediate behavioral predispositions to approach or avoid the stimulus. Personality and Social Psychology Bulletin, 25, 215–224.
Clark, H. H. (1973). Space, time, semantics and the child. In T. E. Moore (Ed.), Cognitive development and the acquisition of language (pp. 27–63). New York: Academic Press.
Dehaene, S., Bossini, S., & Gireaux, P. (1993). The mental representation of parity and number magnitude. Journal of Experimental Psychology: General, 122, 371–396.
De Jong, R., Liang, C., & Lauber, E. (1994). Conditional and unconditional automaticity: A dual-process model of effects of spatial stimulus–response correspondence. Journal of Experimental Psychology: Human Perception and Performance, 20, 731–750.
de la Vega, I., De Filippis, M., Lachmair, M., Dudschig, C., & Kaup, B. (2011). Emotional valence and physical space: Limits of interaction. Journal of Experimental Psychology: Human Perception and Performance . Advance online publication.
Duckworth, K. L., Bargh, J. A., Garcia, M., & Chaiken, S. (2002). The automatic evaluation of novel stimuli. Psychological Science, 13, 513–519.
Emmorey, K. (2001). Space on hand: The exploitation of signing space to illustrate abstract thought. In M. Gattis (Ed.), Spatial schemas and abstract thought (pp. 147–174). Cambridge, MA: MIT Press.
Evans, V. (2006). The structure of time: Language, meaning, and temporal cognition. Amsterdam: Benjamins.
Fiedler, K. (2011). Voodoo correlations are everywhere—not only in neuroscience. Perspectives on Psychological Science, 6, 163–171.
Fraser, T. J. (1966). The voices of time: A cooperative survey of the man's view of time as expressed by the sciences and the humanities. New York: Braziller.
Fuhrman, O., & Boroditsky, L. (2010). Cross-cultural differences in mental representations of time: Evidence from an implicit nonlingustic task. Cognitive Science, 34, 1–22.
Glenberg, A. M., & Kaschak, M. P. (2002). Grounding language in action. Psychonomic Bulletin & Review, 9, 558–565.
Graf, E. M. (2006). The ontogenetic development of literal and metaphorical space in language. Tübingen: Narr.
Haspelmath, M. (1997). From space to time: Temporal adverbials in the world's languages. München: Lincom Europa.
Ishihara, M., Keller, P. E., Rossetti, Y., & Prinz, W. (2008). Horizontal spatial representations of time: Evidence for the STEARC effect. Cortex, 44, 454–461.
Klein, W. (2009). Concepts of time. In W. Klein & P. Li (Eds.), The expression of time (pp. 5–38). Berlin: Mouton de Gruyter.
Kornblum, S., Hasbroucq, T., & Osman, A. (1990). Dimensional overlap: Cognitive basis for stimulus–response compatibility: A model and taxonomy. Psychological Review, 97, 253–270.
Kranjec, A., & Chatterjee, A. (2010). Are temporal concepts embodied? A challenge for cognitive neuroscience. Frontiers in Psychology, 1, 1–9.
Lakens, D., Semin, G. R., & Garrido, M. V. (2011). The sound of time: Cross-modal convergence in the spatial structuring of time. Consciousness and Cognition, 20, 437–443.
Lakoff, G., & Johnson, M. (1980). Metaphors we live by. Chicago: University of Chicago Press.
Loftus, G. R., & Masson, M. E. J. (1994). Using confidence intervals in within-subjects designs. Psychonomic Bulletin & Review, 1, 476–490.
Mahon, B. Z., & Caramazza, A. (2008). A critical look at the embodied cognition hypothesis and a new proposal for grounding conceptual content. Journal of Physiology, 102, 59–70.
Masson, M. E. J., & Loftus, G. R. (2003). Using confidence intervals for graphically based data interpretation. Canadian Journal of Experimental Psychology, 57, 203–220.
Núñez, R. E., & Sweetser, E. (2006). With the future behind them: Convergent evidence from Aymara language and gesture in the crosslinguistic comparison of spatial construals of time. Cognitive Science, 30, 401–450.
Ono, F., & Kawahara, J. I. (2007). The subjective size of visual stimuli affects the perceived duration of their presentation. Perception & Psychophysics, 69, 952–957.
Ornstein, R. E. (1969). On the experience of time. Harmondsworth, U.K.: Penguin Books.
Ouellet, M., Santiago, J., Funes, M. J., & Lupiáñez, J. (2010a). Thinking about the future moves attention to the right. Journal of Experimental Psychology: Human Perception and Performance, 36, 17–24.
Ouellet, M., Santiago, J., Israeli, Z., & Gabay, S. (2010b). Is the future the right time? Experimental Psychology, 57, 308–314.
Proctor, R. W., & Cho, Y. S. (2006). Polarity correspondence: A general principle for performance of speeded binary classification tasks. Psychological Bulletin, 132, 416–442.
Radden, G. (2004). The metaphor TIME AS SPACE across languages. In N. Baumgarten, C. Böttger, M. Motz, & J. Probst (Eds.), Interkulturelle Kommunikation, Spracherwerb und Sprachvermittlung—das Leben mit mehreren Sprachen: Festschrift für Juliane House zum 60. Geburtstag (pp. 225–239). Bochum: Aks-Verlag.
R Development Core Team. (2011). R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing. Available at http://www.R-project.org
Roussel, M. E., Grondin, S., & Killeen, P. (2009). Spatial effects on temporal categorisation. Perception, 38, 748–762.
Santiago, J., Lupiáñez, J., Pérez, E., & Funes, M. J. (2007). Time (also) flies from left to right. Psychonomic Bulletin & Review, 14, 512–516.
Santiago, J., Román, A., Ouellet, M., Rodríguez, N., & Pérez-Azor, P. (2010). In hindsight, life flows from left to right. Psychological Research, 74, 59–70.
Sell, A. J., & Kaschak, M. P. (2011). Processing time shifts affects the execution of motor responses. Brain & Language, 117, 39–44.
Simon, J. R., & Rudell, A. P. (1967). Auditory S–R compatibility: The effect of an irrelevant cue on information processing. Journal of Applied Psychology, 51, 300–304.
Talmy, L. (1988). Force dynamics in language and cognition. Cognitive Science, 12, 49–100.
Torralbo, A., Santiago, J., & Lupiáñez, J. (2006). Flexible conceptual projection of time onto spatial frames of reference. Cognitive Science, 30, 745–757.
Traugott, E. C. (1978). On the expression of spatio-temporal relations in language. In J. Greenberg (Ed.), Universals of human language: Vol. 3. Word structure (pp. 369–400). Stanford: Stanford University Press.
Tversky, B., Kugelmass, S., & Winter, A. (1991). Cross-cultural and developmental trends in graphic productions. Cognitive Psychology, 23, 515–557.
Ulrich, R., Giray, M., & Schäffer, R. (1990). Is it possible to prepare the second component of a movement before the first one? Journal of Motor Behavior, 22, 125–148.
Ulrich, R., & Maienborn, C. (2010). Left–right coding of past and future in language: The mental timeline during sentence processing. Cognition, 117, 126–138.
Vallesi, A., Binns, M. A., & Shallice, T. (2008). An effect of spatial–temporal association of response codes: Understanding the cognitive representations of time. Cognition, 107, 501–527.
Weger, U. W., & Pratt, J. (2008). Time flies like an arrow: Space–time compatibility effects suggest the use of a mental timeline. Psychonomic Bulletin & Review, 15, 426–430.
Weißenborn, J. (1988). Von der demonstratio ad oculos zur Deixis am Phantasma: Die Entwicklung der lokalen Referenz bei Kindern. In A. Eschbach (Ed.), Karl Bühler's Theory of Language (pp. 257–276). Amsterdam: Benjamins.
Woodrow, H. (1951). Time Perception. In S. S. Steven (Ed.), Handbook of experimental psychology (pp. 1224–1236). New York: Wiley.
Xuan, B., Zhang, D., He, S., & Chen, X. (2007). Larger stimuli are judged to last longer. Journal of Vision, 7, 1–5.
Author note
We thank Arthur Glenberg, Barbara Kaup, Jeff Miller, Janina Rado, and two anonymous reviewers for helpful comments. This work was supported by the Deutsche Forschungsgemeinschaft (SFB 833, Project B7 Ulrich/Maienborn). Correspondence concerning this article should be sent to Rolf Ulrich, Department of Psychology, University of Tübingen, Schleichstr. 4, 72076 Tübingen, Germany; email: ulrich@uni-tuebingen.de.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Ulrich, R., Eikmeier, V., de la Vega, I. et al. With the past behind and the future ahead: Back-to-front representation of past and future sentences. Mem Cogn 40, 483–495 (2012). https://doi.org/10.3758/s13421-011-0162-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-011-0162-4