
Abstract
Response inhibition is an important cognitive-control function that allows for already-initiated or habitual behavioral responses to be promptly withheld when needed. A typical paradigm to study this function is the stop-signal task. From this task, the stop-signal response time (SSRT) can be derived, which indexes how rapidly an already-initiated response can be canceled. Typically, SSRTs range around 200 ms, identifying response inhibition as a particularly rapid cognitive-control process. Even so, it has recently been shown that SSRTs can be further accelerated if successful response inhibition is rewarded. Since this earlier study effectively ruled out differential preparatory (proactive) control adjustments, the reward benefits likely relied on boosted reactive control. Yet, given how rapidly such control processes would need to be enhanced, alternative explanations circumventing reactive control are important to consider. We addressed this question with an fMRI study by gauging the overlap of the brain networks associated with reward-related and response-inhibition-related processes in a reward-modulated stop-signal task. In line with the view that reactive control can indeed be boosted swiftly by reward availability, we found that the activity in key brain areas related to response inhibition was enhanced for reward-related stop trials. Furthermore, we observed that this beneficial reward effect was triggered by enhanced connectivity between task-unspecific (reward-related) and task-specific (inhibition-related) areas in the medial prefrontal cortex (mPFC). The present data hence suggest that reward information can be translated very rapidly into behavioral benefits (here, within ~200 ms) through enhanced reactive control, underscoring the immediate responsiveness of such control processes to reward availability in general.
Similar content being viewed by others
Reward effects on cognitive functions have recently attracted much scientific attention, not least because they offer a controllable window into the neurocognitive effects of motivation in general, which is disturbed in a wide range of mental disorders (see, e.g., Barch & Dowd, 2010; Chau, Roth, & Green, 2004; Dalley, Everitt, & Robbins, 2011). This line of research has demonstrated that reward availability can influence numerous mental operations in a relatively specific fashion, including conflict processing and long-term memory (e.g., Adcock, Thangavel, Whitfield-Gabrieli, Knutson, & Gabrieli, 2006; Krebs, Boehler, & Woldorff, 2010; Padmala & Pessoa, 2011; Wittmann et al., 2005). An important concept in this context is the distinction between proactive and reactive control (Braver, 2012; Braver, Gray, & Burgess, 2007; see also Ridderinkhof, 2002), and how those might be affected by reward availability. Thus far, most studies have investigated reward effects in task contexts that allow for adjustments in proactive control, typically by using reward cues before a trial or block of trials. For such situations, it has been shown that reward benefits in the actual task can indeed be related to enhanced proactive preparation (e.g., Engelmann, Damaraju, Padmala, & Pessoa, 2009; Jimura, Locke, & Braver, 2010; Krebs, Boehler, Roberts, Song, & Woldorff, 2012; Padmala & Pessoa, 2011).
In contrast, the question of whether reactive control can also be enhanced by reward availability has received little attention thus far. Yet, investigating such mechanisms is important, because real-life situations often lack prior (i.e., cue-like) information about reward availability. Such effects can be investigated, for example, by communicating reward availability through features of the task-relevant stimuli themselves, with reward-related trials occurring unpredictably throughout a trial sequence. Critically, even in this situation, reward benefits for task performance can be found. This was demonstrated recently, for example, in a reward-modulated version of the Stroop task in which half of the stimulus colors were associated with reward, by showing accelerated response times and strongly diminished incongruency effects for reward-related trials (Krebs et al., 2010).
The present study tackles the topic above, and the underlying neural operations by using functional magnetic resonance imaging (fMRI) in the context of response inhibition with a rewarded stop-signal task. Response inhibition is considered a critical cognitive-control function, allowing for flexible interactions with a changing environment that might require rapid cancellation of already-initiated or habitual responses. This function is believed to be subserved by interactions between frontal cortical areas (particularly an area comprising the right dorsal anterior cingulate cortex and presupplementary motor area [dACC/pre-SMA], and/or an area around the anterior insula and inferior frontal gyrus [aI/IFG]) and parts of the basal ganglia (Chambers, Garavan, & Bellgrove, 2009; Munakata et al., 2011; Ridderinkhof, Forstmann, Wylie, Burle, & van den Wildenberg, 2011). Usually, response inhibition is considered a reactive control process that can only be implemented upon the presentation of a stop stimulus (e.g., Aron, 2011). Additionally, however, response inhibition has also been shown to profit from proactive control mechanisms, in that preparing to withhold a response indeed seems to facilitate ultimate inhibition (e.g., Cai, Oldenkamp, & Aron, 2011; Chikazoe et al., 2009).
In a previous behavioral study, we were able to demonstrate that response inhibition can be accelerated in a trial-by-trial fashion through reward associations (with one of two possible stop stimuli indicating the availability of a monetary reward upon successful response inhibition; Boehler, et al., 2012b). This is particularly remarkable, because stopping is implemented very rapidly (~200 ms), leaving little time for reward-related control enhancements to be implemented (Schall, Stuphorn, & Brown, 2002). Considering this short time window within which such reward-related effects would need to arise, one might call into question whether the behavioral benefits that we observed really relied on reactive control mechanisms. Alternatively, it is (for example) possible that some form of automatic mapping develops between stopping-related stimuli and response inhibition (Chiu, Aron, & Verbruggen, 2012; Lenartowicz, Verbruggen, Logan, & Poldrack, 2011; Manuel, Grivel, Bernasconi, Murray, & Spierer, 2010; Verbruggen & Logan, 2008), bypassing control rather than enhancing it, and that this happens more efficiently in the case of reward-related stimuli. Unfortunately, behavioral data are quite limited in helping to decide between these alternatives.
Therefore, the primary aim of the present study was to determine whether shorter stop-signal response times (SSRTs) in our reward-modulated stop-signal task indeed arise as a consequence of rapidly deployed enhanced reactive control. We aimed to do so by identifying typical response-inhibition-related brain areas and systematically comparing the resulting network to the set of brain areas that displayed enhanced activity for reward-related stop trials. Importantly, we reasoned that any reward-related enhancement that occurred in successful as well as unsuccessful stop trials (with the latter not actually yielding rewards) should be related to reward anticipation, and likely would take place before a response was finally canceled or not canceled, so that reward modulations found for both trial types would not be confounded by processes related to either positive or negative outcome evaluations.Footnote 1 Moreover, we planned to investigate this function in the wider context of neural processes evaluating the different behavioral outcomes, and by investigating how reward information enters the network of areas subserving response inhibition.
Material and method
Participants
In total, 18 participants were scanned. Of the resulting data sets, two were excluded from the analysis due to stability problems with the fMRI data (see below), so that the final sample consisted of 16 participants (15 female, one male; mean age 22.8 years, age range 19–24).
Task
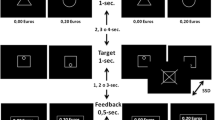
The task we employed was a reward-modulated version of the stop-signal task (Fig. 1). In the basic task (Logan, 1994; Logan & Cowan, 1984), participants usually have to rapidly perform a simple discrimination task on frequent go trials (here, left/right orientation of a green traffic light sign, mapped onto the right index and middle fingers). On a minority of trials, however, this stimulus is rapidly followed by a stop stimulus signaling that the response should be inhibited, yielding successful and unsuccessful stop trials. Importantly, we used two different stop-stimulus colors, one of which was associated with the availability of reward (see below). The overall stimulus duration was always 600 ms, and the trial-onset asynchronies were always 2 s (i.e., each fMRI volume onset coincided with a go or stop trial). Given the fact that go trials were more frequent than stop trials, this approach yielded a favorably long average onset asynchrony between stop trials, while simultaneously keeping the overall duration of the experiment low. As a consequence of this approach, however, go trials could not be modeled explicitly (see below), but rather represented the implicit baseline against which all stop trials were compared.Footnote 2 This general approach of modeling go trials as an implicit baseline has been successfully used in stop-signal tasks before (Chamberlain et al., 2009; Padmala & Pessoa, 2010a, 2010b).

Rewarded stop-signal task. In this task, the majority of go trials were randomly intermixed with reward-related (RR) and reward-unrelated (RU) stop trials (the RU and RR colors were counterbalanced across participants). Participants could earn a monetary bonus for withholding their response on RR stop trials
Before participants were positioned in the MRI scanner, they performed a short training session including 64 go trials and 36 stop trials. Half of the stop trials used pink stop stimuli, and the other half used blue ones. During stop trials, the go–stop delay was titrated using an adaptive staircase procedure aiming for 50 % stopping success. The staircase procedure increased the go–stop delay by 34 ms after each successful stop trial, and decreased it by the same amount after unsuccessful ones (initial value: 200 ms). Only after the training was one of the two colors assigned as being reward-predictive (counterbalanced across participants). Specifically, participants were told that they could earn 5 Euro cents (€0.05) for each successful reward-related (RR) stop trial, but none for reward-unrelated (RU) ones. For the main fMRI experiment, the above-mentioned staircase procedure was split into two independent staircases to reach 50 % stopping success for RR and RU trials, respectively. The fMRI experiment consisted of four runs, yielding a total of 512 go trials, 144 RR stop trials, and 144 RU stop trials. Importantly, RR and RU stop trials were intermixed randomly, so that participants could not predict their occurrence.Footnote 3 The amount earned in each run was displayed at the end of that run, and usually added up to a total bonus of about €4. Participants were instructed to respond rapidly and not to slow down their responses over the course of the experiment. As an additional precaution against such possible slowing, participants were told that they could lose the money that they had won in a given run if they responded too slowly or had a significant number of misses on go trials. This warning turned out to be effective in preventing putative response-time slowing (see the Results section), so that all participants received their respective rewards for all runs.
After the main stop-signal task, participants performed an additional run featuring randomly intermixed go stimuli in the three colors used in the main experiment (green/pink/blue; 28 trials each) in order to gauge lingering effects of the colors that we employed on response speed in a reward- and response-inhibition-free task context, as we had in our preceding behavioral study (Boehler, et al., 2012b). The stimulus duration and the discrimination task were identical to the stop-signal task described above, but this block consisted exclusively of nonrewarded go trials, which the participants were explicitly informed about. The trial-onset asynchrony was varied pseudorandomly following an exponential function, to allow for good separability of the hemodynamic responses in the different conditions (Kao, Mandal, Lazar, & Stufken, 2009). Importantly, however, the behavioral effect that we described in our earlier report was not replicated here. As a consequence, we do not report the corresponding fMRI data here, which were furthermore not included in any way in the analysis of the main fMRI data.
fMRI data acquisition
MRI data were acquired on a 3-T Magnetom Trio MRI scanner system (Siemens Medical Systems, Erlangen, Germany) using a 32-channel head coil. Participants were instructed to minimize head movements throughout the entire scanning session. The scanning protocol started with a high-resolution anatomical image (T1-weighted 3-D MPRAGE; TR = 1,550 ms, TE = 2.39 ms, TI = 900 ms, acquisition matrix = 256 × 256, FOV = 220 mm, flip angle = 9°, voxel size = 0.86 × 0.86 × 0.9 mm), which was later used for spatial coregistration and normalization. During the task, functional images were collected using a T2*-weighted EPI sequence, optimized for BOLD contrast (TR = 2,000 ms, TE = 30 ms, acquisition matrix = 64 × 64, FoV = 192 mm, flip angle = 80°, voxel size = 3 × 3 × 3 mm, no interslice gap, 33 axial slices yielding brain coverage from the vertex to the upper brainstem). Each of the four runs of the stop-signal task comprised 220 functional volumes.
Analysis
The behavioral key parameter indexing stopping efficiency in this task is the SSRT, which describes how long the brain needs to implement response cancellation. This parameter was estimated using the so-called integration approach (Verbruggen & Logan, 2009). In this approach, the go-trial RTs are rank-ordered, and the RT percentile value corresponding to the percentage of unsuccessful stop trials is determined on a per-participant basis (e.g., 61st percentile of the go-RT distribution for a participant with 61 % unsuccessful stop trials). The average go–stop delay is then subtracted from this RT value.Footnote 4 Statistical comparisons of the behavioral data were performed using repeated measures analysis of variance and paired t tests. Two-tailed p values are reported, except where specified otherwise (which was limited to tests for which explicit predictions could be clearly derived from earlier work).
Turning to the MRI data, in a first step, the first four scans of all EPI series were excluded from the analysis, to allow for steady-state magnetization. Subsequently, the fMRI data were subjected to basic quality control by using the outlier-volume routine of ArtRepair (http://cibsr.stanford.edu/tools/human-brain-project/artrepair-software.html). This procedure identified two participants who had considerable signal fluctuations across volumes in all four runs; as a consequence, they were excluded from all analyses. The main MRI data processing and analyses were performed using SPM8 (www.fil.ion.ucl.ac.uk/spm/software/spm8/). Anatomical images were spatially normalized to the SPM T1-template image, using the integrated segmentation/normalization routine of SPM, and resliced to a voxel size of 1 × 1 × 1 mm. All functional EPIs were slice-time corrected and realigned to the first-acquired EPI. Next, EPIs were spatially normalized on the basis of the parameters derived during the spatial normalization of the T1 image, and smoothed with an isotropic full-width-at-half-maximum Gaussian kernel of 8 mm.
A standard two-stage procedure was used for the statistical analysis of the fMRI data. On the first, participant-wise level, BOLD responses were modeled by delta functions at stimulus onset, which were then convolved with a standard hemodynamic response function, along with temporal and dispersion derivatives (Friston et al., 1998). As we mentioned above, only the four different types of stop trials were modeled explicitly (successful and unsuccessful RR stop trials; successful and unsuccessful RU stop trials), whereas go trials served as the implicit baseline. Additionally, the model included the six movement parameters derived from the realignment procedure as regressors of no interest. Simple contrasts versus baseline were advanced to the second level, using a random-effects within-participant flexible-factorial design, as implemented in SPM8. Analyses included conjunctions and disjunctions between different contrasts. The former were formulated as conjunction-null tests resulting in a minimum statistic that corresponds to a logical AND (Friston, Penny, & Glaser, 2005). For disjunctive analyses and some additional questions related to overlap between networks, masks were used that were based on a threshold of p < .05. Results are presented with reference to a cluster-level family-wise error correction for multiple comparisons, focusing on areas reaching a corrected p value of <.05. Additionally, any cluster reaching a corrected p value of <.1 are reported as trends. The auxiliary uncorrected p value for these analyses was p < .001. The results are displayed on slices of the “ch2” template anatomical image using MRIcron (www.mccauslandcenter.sc.edu/mricro/mricron/).
Finally, we performed a psychophysiological interaction (PPI) analysis to examine how brain regions related to reward that are outside of the network of stopping-related areas interact with areas within this network. To this end, we used the automated generalized PPI toolbox (gPPI; McLaren, Ries, Xu, & Johnson, 2012). On the basis of a seed cluster in the pregenual ACC (see the Results section), the PPI analysis aimed at identifying areas that displayed enhanced functional connectivity with this seed region when comparing RR with RU trials.
Results
Behavioral results
Table 1 summarizes the behavioral data. Go-trial performance was as desired, with high accuracy and fairly fast average RTs. Moreover, RTs did not change substantially over the course of the experiment (“progressive slowing” in Table 1), and it is important to avoid such slowing as a possible confounding factor for the SSRT estimation (Leotti & Wager, 2010; Verbruggen, Chambers, & Logan, 2013). Consistent with earlier evidence and theoretical models of the stop-signal task, responses for go trials were slower than those for RR and RU unsuccessful stop trials [both ts(15) > 10, ps < .001], with the latter not differing significantly from each other [t(15) = 1.67, p = .12].
Turning to the key parameters related to response inhibition, the fact that the stopping-success rates were identical (both 50.5 %) for RR and RU trials indicates the successful implementation of the two independent staircase procedures that adjusted the go–stop delay for each condition separately (each aiming for 50 % stopping success). Yet, importantly, the average go–stop delay was longer on RR than on RU trials [t(15) = 2.58, p = .01, one-tailed], indicating that during RR trials the same stopping-success rate was achieved as in RU trials, but with slightly longer go–stop delays. This finding implicates a faster stopping process, which was further corroborated by shorter SSRTs for RR than for RU trials [t(15) = 2.55, p = .011, one-tailed], which generally replicates our earlier report of this behavioral effect (Boehler, Hopf, et al., 2012). Moreover, we were interested in whether stopping performance changed over the course of the experiment due to training effects. Therefore, SSRTs were calculated separately for the first and second halves of the experiment. A first analysis that collapsed across RR and RU trials indeed indicated that SSRTs were slightly shorter during the second than during the first half of the experiment [by 11.4 ms; t(15) = 1.78, p = .047, one-tailed], replicating earlier reports (e.g., Manuel, Bernasconi, & Spierer, 2013). Importantly, however, the SSRT difference between RR and RU trials did not differ significantly between the first and second halves of the experiment [9.2 vs. 5.4 ms; t(15) = 0.63, p = .541].
Finally, we analyzed the data from the final short experimental run that was performed after the main experiment, which used exclusively go trials, drawn in the three colors used before (green = former go-stimulus color; blue/pink = former RR/RU stop-stimulus color, depending on counterbalancing). In our earlier study, we had observed for such a task that, despite the complete and explicit lack of a stopping context, responses were slightly slower for the former RR stop-stimulus color (Boehler, Hopf, et al., 2012). Although responses were again numerically slowest for stimuli drawn in the former RR stop-stimulus color (424.4 ms), as compared to the former RU stop-stimulus color (421.5 ms) and the go-stimulus color (423 ms), these RTs did not differ significantly from each other (p > .5). Given this failure to replicate our earlier finding, we will not report the respective fMRI data below.
fMRI results
The analysis of the fMRI data proceeded in a number of consecutive steps. First, we aimed to identify response-inhibition-related and reward-related brain activity in general. Next, we investigated whether stopping success was registered differently during RR and RU trials. Subsequently, disjunctive, conjunctive, and connectivity analyses were performed to determine where the networks related to response inhibition and reward anticipation overlapped, where they dissociated, and how reward-related activity outside of the stopping-related network interacted with regions that are part of it.
General stopping-related activity
In a first step, we set out to identify areas that are involved in response inhibition, in the broad sense of being more active during stop than during go trials. The comparison between stop trials (either all stop trials or only successful ones) and go trials is a commonly used approach, albeit one with obvious disadvantages; for instance, it prominently suffers from differences in sensory stimulation. Additionally, brain activity that is specific for either successful or unsuccessful stop trials can be picked up by such a contrast (e.g., error detection for unsuccessful stop trials, which is unrelated to response inhibition and should hence be excluded), which further limits this approach’s specificity (Boehler, Appelbaum, Krebs, Chen, & Woldorff, 2011). We have recently suggested that one way to increase the specificity of such analyses is through the use of the conjunction of successful stop trials versus go trials and unsuccessful stop trials versus go trials (Boehler, Appelbaum, Krebs, Hopf, & Woldorff, 2010). Since this conjunction corresponds to logical AND, it would only identify brain activity that is common to both types of stop trials.Footnote 5 Here, we again employed this conjunction approach. To avoid any influence of reward-related processes, we based our definition of stopping-related areas exclusively on the RU trials (“RU successful stop trials > go-trial baseline” AND “RU unsuccessful stop trials > go-trial baseline”; see Fig. 2A and Table 2A). As is typical, this analysis identified bilateral occipito-temporal and parietal areas, which is, however, likely related in large part to the sensory and attentional processing of the stop stimuli (Boehler, Appelbaum, et al., 2011). More importantly, the analysis furthermore identified typical stopping-related areas, including a right-lateralized network of frontal areas, comprising the anterior insula (aI; with activity estimates protruding into the frontal operculum of the IFG), along with additional regions in the lateral prefrontal cortex, and the dACC/pre-SMA. Similar, albeit weaker, activations were found in the left hemisphere, particularly in the anterior insula (see Swick, Ashley, & Turken, 2008; Swick, Ashley, & Turken, 2011). Subcortically, enhanced activity was observed in the right thalamus (on a trend level). Interestingly, no additional subcortical activations were found, which would have been suggestive of involvement of the indirect or hyperdirect pathway (through the striatum and/or the subthalamic nucleus [STN], respectively; e.g., Aron & Poldrack, 2006; Boehler et al., 2010). This absence, however, should not be taken as a strong indication that neither pathway was involved, in that technical reasons could have limited our capability to identify such structures. In particular, the STN is a very small structure that is hard to detect with standard whole-head fMRI (Forstmann et al., 2010). Additionally, our sample size was moderate, albeit similar to those of many earlier studies in this field, which raises the danger of false-negative results. All in all, however, our results replicate typical observations from previous work (e.g., Aron & Poldrack, 2006; Boehler et al., 2010).

Stopping-related and reward-related activity. (A) Results of the conjunction between RU successful stop trials versus the go-trial baseline AND RU unsuccessful stop trials versus the go-trial baseline (see Table 2A). (B) RR stop trials versus RU stop trials (averages for both across successful and unsuccessful stop trials; see Table 2B)
General reward-related activity
Next, we wanted to identify reward-related brain activity. In order to define this broadly, we used the contrast of all RR stop trials versus all RU stop trials (using the respective averages of successful and unsuccessful stop trials; Fig. 2B and Table 2B). This analysis yielded prominent activations bilaterally in the anterior insula and the ventral striatum (including ventromedial parts of both the caudate nucleus and putamen), further protruding into the midbrain. Additionally, a prominent cluster in the ACC was more active for reward-related trials, as was a cluster in the right inferior parietal lobule, and one in the posterior cingulate cortex. Note, however, that this analysis is rather unspecific. On the one hand, it simply averages successful and unsuccessful stop trials, so that a strong activation in only one condition would be sufficient to yield a significant effect. On the other hand, the present analysis does not distinguish between reward effects inside or outside of the stopping-related network. In the following sections, these aspects will be dissociated.
Activity related to registering reward outcome and stopping success
In order to identify activity that is specifically related to RR successful stop trials (which are the only ones that actually yield reward), we contrasted activity in these trials with the respective RR unsuccessful stop trials (matched for reward expectation, but not outcome), and conjoined this contrast with RR versus RU successful stop trials (matched for performance success but not reward outcome; Table 3A, red in online electronic version of Fig. 3). This contrast yielded two large activity clusters, one in and around the striatum, and one in the posterior cingulate cortex. These areas hence seem to be implicated in positive outcome evaluations of RR successful stop trials, as opposed to reward expectation or the mere registration of successful task performance (note that although participants did not receive trial-based feedback, successfully withholding a response is quite obvious, so that they were aware of having earned a reward in RR successful stop trials).

Dissociations in the striatum between reward processing and successful performance. Binary maps for activity specific to RR successful stop-trial activity (red in electronic version of figure, lighter gray in print; Table 3A), related to stopping success in general (blue in electronic version, darker gray in print; Table 3B), and their overlap (pink in electronic version)
In order to evaluate the influence of successful task performance, irrespective of reward, we compared these results to the conjunction of RR successful versus unsuccessful AND RU successful versus unsuccessful stop trials (Table 3B, blue in electronic version of Fig. 3; note that a slightly more liberal auxiliary threshold of <.0015 was used here, because our standard threshold of <.001 seemed to split a continuous cluster into two separate ones). Here, activity was mostly limited to the putamen, including lateral parts as well as more ventromedial portions that are part of the ventral striatum. As can be seen in Fig. 3, activity from these two contrasts largely overlaps in the ventral striatum (overlap shown in pink in electronic figure), indicating a general role in registering successful performance outcomes even in the absence of performance feedback (see also Han, Huettel, Raposo, Adcock, & Dobbins, 2010; Satterthwaite et al., 2012)—which, however, seems to be further enhanced when reward is at play.
To further dissociate the results of the two preceding contrasts, subsequent analyses used the respective other contrast as an exclusive mask (at p < .05 uncorrected). This analysis indicated that little activity was specific to successful task performance alone (i.e., none of the clusters shown in blue in electronic Fig. 3 survived the cluster-level p-value correction; all ps > .9). In contrast, after masking out activity related to stopping success in general, activity related to RR successful stop trials (red in electronic Fig. 3) was observed in a cluster comprising dorsal and posterior parts of the caudate nucleus extending into the thalamus (corrected cluster-level p < .001). Taken together, the present results indicate that parts of the ventral striatum respond to correct task performance even in the absence of reward. Still, parts of the striatum also specifically respond to being correct on reward-related trials (which ultimately yields reward).
Reward-related activity outside and inside the stopping-related network
Next, we turned to the question of which of the areas that display stronger activation during RR than RU stop trials are indeed related to response inhibition, and which lie outside of this stopping-related network. To this end, we defined RR stop-trial activity as the conjunction of both RR successful AND RR unsuccessful stop trials versus the respective RU trials. This represents an important difference to the analyses described above, because through the use of the conjunction, we turned our attention to processes that are enhanced during RR stop trials but are independent of the behavioral outcome. The resulting network was then dissociated concerning whether or not it overlapped with stopping-related activity.
First, we identified areas that were more active in both types of RR stop trials than in RU trials and that lay outside of the stopping-related network, by applying an exclusive mask derived from the conjunction of RU stop trials (representing the stopping-related network). This analysis yielded a single cluster in the pregenual ACC (Table 4A, Fig. 4A). Second, in order to identify the overlap between the reward-related network and the stopping-related network, we used the same contrast as above but used the stopping-related network as an inclusive mask. This analysis showed overlap with key parts of the general stopping-related network, indicating that those areas responded more strongly if reward was at stake (Table 4B, Fig. 4B). Crucially, the identified areas included the right aI/IFG and the dACC/pre-SMA, which are typically found in response-inhibition paradigms. Note that the right aI/IFG cluster was mostly focused on the aI, which was similar to the activation for the general stopping-related network described above (see Fig. 2A and Table 2; see also Swick et al., 2011, for the role of the aI in response-inhibition tasks). As such, it seems to represent a reward-based modulation of this general stopping-related activity (also, activity estimates spilled more into the IFG at slightly more lenient thresholds). Additionally, the left anterior insula was significantly activated.

Reward modulations common to successful and unsuccessful stop trials inside and outside of the stopping-related network, and functional connectivity between the two systems. (A) Areas dissociating between the general stopping-related network and a network that responds more strongly for both kinds of RR stop trials than for RU trials. (B) Areas overlapping between those two networks. (C) Reward-related enhancement of connectivity with the pregenual ACC (see panel A) within the stopping-related network was found in an area of the dorsomedial ACC/pre-SMA
Connectivity analysis
Since the analysis above identified one area outside of the general stopping-related network that was more active for RR stop trials, we investigated how it interacted with the stopping-related network during reward-related trials. To do so, we performed a PPI analysis seeded in the pregenual ACC area, and probed for enhanced functional connectivity during RR versus RU trials within the stopping-related network. This analysis yielded a single activity cluster in the dorsomedial ACC/pre-SMA.Footnote 6
Discussion
In the present fMRI study, we investigated the neural substrates of reward-driven trial-by-trial improvements in response inhibition in a stop-signal task. To our knowledge, this is the first investigation of the neural underpinnings of such reward-related benefits in response inhibition. Notably, a couple of studies have investigated this general topic before, but were limited to behavioral data that was furthermore gathered in a proactive block-based context (e.g., Scheres, Oosterlaan, & Sergeant, 2001; Sinopoli, Schachar, & Dennis, 2011; see also Locke & Braver, 2008). Concerning fMRI studies, we are only aware of one using reward in a stop-signal task. This study, however, contrasts sharply in scope with the present one, in that it investigated the influence of rewarding fast go-trial performance on response inhibition (Padmala & Pessoa, 2010a). Our main findings are threefold. First and foremost, we found that the right aI/IFG and the dACC/pre-SMA, which are considered to be critical stopping-related areas, displayed enhanced activity during reward-related stop trials. This suggests that reward associations indeed trigger enhanced reactive control, rather than bringing about the behavioral effect in a fashion that circumvents such control mechanisms. Importantly, this activity modulation was also present during unsuccessful (and hence unrewarded) reward-related stop trials, which implies that the observed reward effects are implemented before the behavioral outcome stage. More generally, this finding echoes earlier reports that have found reward-related enhancements to be expressed in those brain areas that are also responsible for the task at hand in the absence of reward (e.g., Engelmann et al., 2009; Pochon et al., 2002), albeit it in a different task (stop-signal task) and under a different reward scheme (reward information linked to the task-relevant stimuli themselves) than most earlier work. Second, as for outcome evaluation, we found that activity in the ventral striatum generally indexed successful task performance, which was further enhanced (and extended to additional more dorsal and posterior parts of the striatum protruding into the thalamus) in successful reward-related stop trials. Finally, a pregenual ACC area was the only region outside of the stopping-related network that displayed enhanced activity during successful and unsuccessful reward-related stop trials, implicating it in task- and outcome-independent reward expectation. Using this area as the seed region for a functional-connectivity analysis yielded enhanced coupling with a more posterior mPFC region (dorsomedial ACC/pre-SMA) during reward-related trials, consistent with reward information entering the inhibition-related network through this within-mPFC route.
Reward effects on reactive control
The main finding of the present study is that reactive control can likely be enhanced through reward very rapidly, by demonstrating that reward benefits are largely linked to enhanced activity in the same brain areas that are generally considered critical for response inhibition. Interestingly, the question of how fast reward can affect reactive control processes seems to have received little attention thus far. A recent set of studies from our group that used a similar paradigmatic setup in the context of a Stroop task suggests that reward can trigger enhanced reactive control within approximately 600 ms (potentially including the contribution of some automatic processing enhancements of reward-related colors), which is the time until a response is given in this task (Krebs, Boehler, Egner, & Woldorff, 2011; Krebs et al., 2010). Since cancelling a motor response in a stop-signal task occurs much more rapidly, the present data cut this upper limit down substantially (to ~200 ms). It should be noted that recent electroencephalographic (EEG) work of ours on the rewarded Stroop task has shown early reward effects, without however being able to clearly dissociate reward detection from the control processes it triggers (Krebs, Boehler, Appelbaum, & Woldorff, 2013). The present fMRI data, in contrast, link the reward-related benefits to enhancements in the very same brain areas that are responsible for response inhibition in the first place.
Within the proactive/reactive control framework it should be noted that the present experiment aimed at identifying reactive effects by paradigmatically excluding differential contributions of proactive control. In addition, however, it is quite possible that a reward-related context effect could have given rise to sustained enhancements of proactive control, which might have additionally enhanced response inhibition in a sustained fashion—that is, for all kinds of stop trials alike (Jimura et al., 2010; Locke & Braver, 2008). In line with this notion, our overall SSRT values were rather low (on average below 200 ms), and it is easily conceivable that participants generally displayed shorter SSRTs (also for RU trials) than they would have in a completely reward-free task (cf. Boehler, Appelbaum, Krebs, Hopf, & Woldorff, 2012a; Verbruggen et al., 2013).
Neural source of the reward influence on task-specific networks
Another important question that we addressed here was how reward information enters the network of areas related to response inhibition. This question is an important one for the field of reward effects on cognitive functions in general (see Pessoa & Engelmann, 2010), but has hitherto been addressed virtually exclusively in proactive task contexts. In such proactive contexts, it has been suggested that reward-related activity in the ventral striatum serves to energize processing in task-relevant modules through enhanced functional connectivity (Schmidt, Lebreton, Cléry-Melin, Daunizeau, & Pessiglione, 2012). Although we have recently reported for the reward-modulated Stroop task that the ventral striatum is more active for reward-related trials, and that this activity modulation generally correlated with behavioral benefits (Krebs et al., 2011), the question of how reward information enters task-specific networks in a reactive context has not been systematically addressed.
Importantly, in the present experiment the striatum appeared to play only an evaluative role, in that it failed to show enhanced responses to unsuccessful reward-related stop trials, which are also potentially rewarded until an (erroneous) response is given. Rather, the present reward effects appeared to rely on interactions between task-unspecific (reward-related) and task-specific (inhibition-related) areas in the mPFC. Specifically, a pregenual ACC area was found to be the only region outside of the stopping-related network that responded more strongly to reward-related than to reward-unrelated stop trials, irrespective of whether the response was successfully inhibited or not. A functional-connectivity analysis indicated that the connectivity between this region and a more posterior mPFC area within the stopping-related network (dorsomedial ACC/pre-SMA) was enhanced for reward-related trials. The ACC as a whole has been implicated in the processing of reward in general (e.g., Amiez, Joseph, & Procyk, 2006; Bush et al., 2002; Hayden, Pearson, & Platt, 2009; O’Doherty, Kringelbach, Rolls, Hornak, & Andrews, 2001; Shidara & Richmond, 2002), as well as in reward-related effects on a variety of cognitive functions (e.g., Kinnison, Padmala, Choi, & Pessoa, 2012; Kouneiher, Charron, & Koechlin, 2009; Padmala & Pessoa, 2011; Pochon et al., 2002; Rowe, Eckstein, Braver, & Owen, 2008; see also Rushworth, Walton, Kennerley, & Bannerman, 2004). Yet, the ACC is a very heterogeneous structure, seemingly subserving a variety of functions beyond reward processing (e.g., Etkin, Egner, & Kalisch, 2011), and the present experiment was not set up to dissociate between different functional accounts (see also Ide, Shenoy, Yu, & Li, 2013). Still, for the present experiment, it seems plausible that the pregenual ACC represented reward availability before the behavioral outcome occurred, and that its functional interaction with the task-specific parts of the mPFC energized task-specific processes, akin to the ventral striatum’s suggested role in a proactive context (Schmidt et al., 2012).
The distinction above raises the interesting, yet speculative, hypothesis that reward-related benefits are triggered in qualitatively different ways in proactive versus reactive task contexts. Crucially, the role of the striatum in driving reward-related effects in task-specific areas under proactive conditions is likely fueled by dopaminergic inputs, which is in line with the assumed role of the dopaminergic system in proactive control in general (Braver et al., 2007). In contrast, the reactive reward-related benefits in the present study seem to have been instigated by the pregenual ACC rather than by the striatum. Although the dopaminergic system might also play some role in this context (e.g., in shaping behavior over time; Holroyd & Coles, 2002; Montague, Hyman, & Cohen, 2004; Ridderinkhof, Ullsperger, Crone, & Nieuwenhuis, 2004), it is questionable whether its effects would arise fast enough to influence neural processing within a trial (Braver et al., 2007).
Finally, the concept of reward effects deserves some qualification concerning its mode of operation in the present experiment (and in many previous ones). Specifically, it is important to point out here that the reward modulation was perfectly aligned with the participants’ task goals, and as such it is impossible to say whether reward had a direct effect on the underlying task-related processes, whether its influence was indirect in a fashion that involved strategic top-down control (Maunsell, 2004), or whether it might have displayed some interactive pattern between such processes (Pessoa & Engelmann, 2010). The potential for reward effects to arise in an indirect fashion is naturally very large in task contexts that allow for preparation, such as in the typical monetary incentive delay task (Knutson, Adams, Fong, & Hommer, 2001; see also Boehler, Hopf, et al., 2011). Yet, noting the small amount of time that participants had here to bring about reward-related benefits, it is certainly not sufficient to claim that reward must have had a direct effect, in particular because preparatory effects could have played a contributing role; addressing such claims would require more elaborate paradigms that could, for instance, make reward information deleterious from a strategic standpoint (Hickey, Chelazzi, & Theeuwes, 2010). Here, we used reward similarly to how it had been in earlier, related studies—as a simple means to increase participants’ motivation—but it is quite likely that other ways of motivating participants would have had similar effects.
Alternative mechanistic accounts
We believe that the present reward effect was brought about by very rapid reward-related recruitment of reactive control, since the reward effect was found in key response-inhibition-related brain areas, and since response inhibition is usually considered a prototypical reactive control function. A possible alternative would have been a learning process that automatically mapped stop stimuli to response inhibition, which might have been more efficient for (or even exclusive to) reward-related trials. Although such learning mechanisms have been described before, they have usually only been reported for go–no-go tasks or variants of the stop-signal task with consistent mappings between the go stimuli and response inhibition (Chiu et al., 2012; Lenartowicz et al., 2011; Manuel et al., 2010; Verbruggen & Logan, 2008), which was not the case here.
Nevertheless, we recently observed some indications of an automatic mapping between stop-stimulus features (in contrast to go-stimulus features, as in the previous studies) and response inhibition, in the behavioral study that was the basis for the present work (Boehler, Hopf, et al., 2012). Specifically, we found that, in an additional experimental run performed after the main experiment that exclusively featured go trials (and no reward), response times were slightly longer if the go stimuli were drawn in the former reward-related stop-stimulus color. This effect was, however, very weak, and we were unsuccessful at replicating it here, which suggests that reward-related automatic stimulus-to-inhibition mappings did not play a major role.Footnote 7 More importantly, however, the stronger involvement of frontal control regions in reward-related trials in the present study supports the notion that the reward-related SSRT benefit indeed relied on enhanced reactive control. This is particularly interesting, since one would have expected the opposite under a training-related account based on recent empirical findings—that is, a weaker involvement after training (Manuel et al., 2013) and/or the involvement of lower-level areas (likely in parietal cortex) that implement a direct mapping between stimulus features and response inhibition (Manuel et al., 2010; Spierer, Chavan, & Manuel, 2013). Related to this point, it is important to note that, despite finding some behavioral evidence for a training effect on SSRTs in general (which were shorter in the second than in the first half of the experiment), the reward-related SSRT benefit did not change significantly over the course of the experiment.
Nevertheless, it is important to note that cognitive-control processes such as response inhibition usually do not operate independent of the operations that lead up to them, in particular sensory/attentional processes. For example, it has been shown that the outcome of a stop trial can depend on the speed/amplitude of the preceding sensory processing of the task-relevant stimuli (Bekker et al., 2005a; Bekker, et al., 2005b; Boehler et al., 2009; Duann, Ide, Luo, & Li, 2009; Knyazev, Levin, & Savostyanov, 2008; Overtoom et al., 2009; Padmala & Pessoa, 2010b). As such, it is in fact very difficult to define response inhibition in a fashion that is independent from the attentive processing of the task-relevant stimuli (Bari & Robbins, 2013; Boehler, Appelbaum, et al., 2011; Hampshire, Chamberlain, Monti, Duncan, & Owen, 2010; Sharp et al., 2010).Footnote 8 Given this intimate relationship between response inhibition and sensory attention, it is important to acknowledge that reward is known to have strong effects on the sensory/attentional processes (e.g., Anderson, Laurent, & Yantis, 2011; Della Libera & Chelazzi, 2006; Hickey et al., 2010). Hence, it is possible that rather than establishing a mapping between a stop-stimulus feature and response inhibition, reward could have “simply” enhanced the saliency of the respective stop-stimulus color. This could potentially also happen in interaction with an attentional set that participants established in order to more efficiently process reward-related stop stimuli whenever they occurred, thereby giving them an edge in the process dynamics underlying stop trials. In this regard, it is interesting to note that both clusters showing a reward modulation here (aI/IFG, dACC/pre-SMA) are not only considered key areas for response inhibition but have also both been argued to be part of a “saliency network” that detects salient events in the environment and interacts with control networks to initiate a response to these events (Seeley et al., 2007). It is possible that such a system could be tuned to respond more strongly to reward-related events.
Critically, this enhanced-saliency notion (as well as that of an automatic mapping between reward-related stop stimuli and response inhibition) could be argued to circumvent reactive control, if one assumes that more-salient stimuli are simply processed faster without concomitantly invoking control processes—hence, making successful inhibition more likely by speeding up sensory processing of the stop stimulus. Such an account would run counter to our interpretation of the data. Although this experiment was not designed to distinguish between these alternatives, a couple of reasons seem to speak against a saliency account. First, a simple increase in saliency would predict faster responses for stimuli drawn in the former reward color in an all-go-trial context, as we have found for the reward-related Stroop task (Krebs et al., 2010), which was not found here. Second, reward information seemed to enter the respective network through a within-mPFC route that does not seem typical for simple saliency-based processes, and no activity modulations were found in classical sensory areas. Finally, earlier experimental work employing direct electrical or transcranial magnetic stimulation (TMS; e.g., Filevich, Kuhn, & Haggard, 2012; Neubert, Mars, Buch, Olivier, & Rushworth, 2010; Zandbelt, Bloemendaal, Hoogendam, Kahn, & Vink, 2013) has identified these areas as having inhibitory influence on the motor system, which argues against a purely attentional role. On the basis of such findings and other literature to date, the dominant view holds that the dACC/pre-SMA and/or aI/IFG carry out a control-related function during response-inhibition tasks (although questions have arisen whether this function can easily be labeled “response inhibition,” see also next paragraph), and we think that this control function gets enhanced reactively during reward-related trials in the present task. Yet, a saliency-based account also cannot be fully excluded, certainly not as a contributing process. We would, however, suggest that if such processes played a role, they probably did so by nudging control processes along rather than circumventing them. Also from the general perspective of response-inhibition tasks, it is not clear whether it is possible to find a clear distinction between attentional and motor-inhibitory functions on the level of brain mechanisms. Although one could argue that attentional processes are the more basic ones (in the sense that task-relevant stimuli need to be processed first) and that, hence, activity in a “saliency network” should be ascribed just this function, a more integrated view is also possible. Specifically, a very recent EEG and TMS study showed that response inhibition might in fact be an integral part of most kinds of saliency processing (Wessel & Aron, 2013). This study documented strong similarities in the electrophysiological response to stop stimuli and task-irrelevant oddball stimuli. Importantly, those task-irrelevant oddball stimuli furthermore went along with reduced corticospinal excitability as probed by TMS, thus suggesting that saliency detection and response inhibition are inherently linked.
Irrespective of the considerations above, our data indicate that the reward-related benefits were associated with activity in exactly those brain areas that are usually considered most important for response inhibition (notably, the right aI/IFG and dACC/pre-SMA), whereas other prefrontal areas that are commonly identified in response-inhibition tasks (e.g., Boehler, Appelbaum, et al., 2011; Chikazoe, 2010) were not modulated by reward (see also Cai, Cannistraci, Gore, & Leung, 2013; Leung & Cai, 2007; Levy & Wagner, 2011; Sebastian et al., 2013; Swick et al., 2011).Footnote 9 Beyond this highlighting of particularly relevant areas within the inhibition-related network, however, the present data cannot speak with regard to some additional recent discussions of the specific division of labor between the different brain areas that are generally involved in response-inhibition tasks—in particular, where exactly response inhibition is implemented, and how it is related to more basic control processes such as context monitoring/updating and general response control (Chatham et al., 2012; Dodds, Morein-Zamir, & Robbins, 2011; Verbruggen, Aron, Stevens, & Chambers, 2010).
Summary and conclusions
The present data suggest that reward information can trigger very rapid control enhancements, even in task contexts that do not allow for differential proactive control. This is particularly interesting because the stop-signal task we employed provided an upper time limit of as little as 200 ms for the beneficial effect to be implemented. Despite this strict time constraint, strong overlap was found between a basic stopping-related network and the network of areas that showed enhanced activity in reward-related stop trials, thus indicating that reactive control is likely enhanced very rapidly if rewards are at stake. This effect seems to rely on enhanced connectivity between a task-unspecific (reward-related) area in the pregenual ACC and the task-specific (inhibition-related) dorsomedial ACC/pre-SMA, which might point to a general mechanism for reward effects on reactive control.
Notes
Note that theoretical models of the stop-signal task usually posit a race between a go and a stop process, with the outcome depending on their relative finishing times (Boucher, Palmeri, Logan, & Schall, 2007; Logan, 1994). Consequently, it is assumed that a stop process is also initiated during unsuccessful stop trials.
Moreover, each run ended with a stretch of 12 additional go trials, in order to sample the last hemodynamic stop-trial response with reference to the implicit go-trial baseline; note that these go trials were not used in the behavioral analysis, because it is possible that participants noticed that the ends of the runs only contained go trials.
Nevertheless, there is an elegant argument for why stop trials might still profit from participants correctly “guessing” that a given trial would turn into a stop trial (e.g., Aron & Poldrack, 2006). Such guessing would indeed lead to a higher chance of successfully inhibiting a response, if the participant slowed down the response to the go stimulus (or prepared for inhibition in some other fashion) and the trial turned out really to be a stop trial. Hence, guessing might play a role in whether or not a stop trial would be a successful one, despite the fact that the trials’ occurrence could not be predicted. Importantly, however, such guessing could not differentially affect RR and RU trials. Even if a participant guessed that a given trial would turn into an RR stop trial—thus, for instance, proactively slowing down the behavioral response—the trial would be equally likely to turn into an RR or RU stop trial, so that RU stop trials would profit equally from such a strategy.
Note that the SSRT estimates remained virtually unchanged when calculating the SSRT per run before averaging the resulting values. This approach has been suggested as a countermeasure to the influence of proactive response slowing on the SSRT estimation (Verbruggen, Chambers, & Logan, 2013). Such influences were, however, unlikely here—at least concerning the comparison between RR and RU trials—because RR and RU stop trials were presented in a random, equally probable fashion, so that any go-trial-related strategy would have affected both SSRTs alike. Also, more generally, participants were instructed not to slow down over the course of the experiment and monitored to ensure that they did not.
Importantly, as in our previous work (Boehler et al., 2010), we found only extremely limited differences between RU successful and RU unsuccessful stop trials. Specifically, this contrast identified a single cluster in the striatum (see Table 3B and the blue/pink cluster in electronic Fig. 3). Note that although the respective results in Table 3B and Fig. 3 result from a conjunction with an additional contrast, this result is in fact identical to the RU contrast alone (indicating that it represents the smaller and weaker cluster in the conjunction). This cluster likely relates to the outcome evaluation (see below). No other significant clusters were identified by this contrast, which supports the notion that the neural processes were similar during successful and unsuccessful stop trials, and hence that response inhibition (and related processes) was likely implemented in both kinds of trials.
It should be noted that although this analysis included an inclusive-masking procedure to limit the results to areas that we have broadly defined as the inhibition-related network, the mask actually had no effect on the results; that is, the identified cluster fell completely within the mask, and no significant clusters were found outside of it.
Note that this could partly be due to paradigmatic reasons, so that the absent behavioral effect alone cannot fully exclude possible contributions from a learning process. On the one hand, the general timing of events was much slower here than in the preceding behavioral study (in order to accommodate the needs of fMRI). On the other, the approach might not be very sensitive, since some recent work has indicated that for automatic inhibitory effects to be detectable, a general stopping context is required (Chiu & Aron, 2013).
For this reason, we have decided to use the broad term “inhibition-related network,” or the umbrella term “reactive control,” rather than “response-inhibition network” or other terms that imply a very specific mechanism.
Note, however, that our strict voxel-wise approach was quite conservative, so that interpretations about the absence of activity in any brain area need to be considered with some caution.
References
Adcock, R. A., Thangavel, A., Whitfield-Gabrieli, S., Knutson, B., & Gabrieli, J. D. E. (2006). Reward-motivated learning: Mesolimbic activation precedes memory formation. Neuron, 50, 507–517. doi:10.1016/j.neuron.2006.03.036
Amiez, C., Joseph, J. P., & Procyk, E. (2006). Reward encoding in the monkey anterior cingulate cortex. Cerebral Cortex, 16, 1040–1055.
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011). Value-driven attentional capture. Proceedings of the National Academy of Sciences, 108, 10367–10371. doi:10.1073/pnas.1104047108
Aron, A. R. (2011). From reactive to proactive and selective control: Developing a richer model for stopping inappropriate responses. Biological Psychiatry, 69, e55–e68. doi:10.1016/j.biopsych.2010.07.024
Aron, A. R., & Poldrack, R. A. (2006). Cortical and subcortical contributions to stop signal response inhibition: Role of the subthalamic nucleus. Journal of Neuroscience, 26, 2424–2433. doi:10.1523/JNEUROSCI.4682-05.2006
Barch, D. M., & Dowd, E. C. (2010). Goal representations and motivational drive in schizophrenia: The role of prefrontal-striatal interactions. Schizophrenia Bulletin, 36, 919–934.
Bari, A., & Robbins, T. W. (2013). Inhibition and impulsivity: Behavioral and neural basis of response control. Progress in Neurobiology, 108, 44–79.
Bekker, E. M., Kenemans, J. L., Hoeksma, M. R., Talsma, D., & Verbaten, M. N. (2005a). The pure electrophysiology of stopping. International Journal of Psychophysiology, 55, 191–198.
Bekker, E. M., Overtoom, C. C., Kooij, J. J., Buitelaar, J. K., Verbaten, M. N., & Kenemans, J. L. (2005b). Disentangling deficits in adults with attention-deficit/hyperactivity disorder. Archives of General Psychiatry, 62, 1129–1136.
Boehler, C. N., Appelbaum, L. G., Krebs, R. M., Chen, L. C., & Woldorff, M. G. (2011a). The role of stimulus salience and attentional capture across the neural hierarchy in a stop-signal task. PLoS ONE, 6, e26386. doi:10.1371/journal.pone.0026386
Boehler, C. N., Appelbaum, L. G., Krebs, R. M., Hopf, J.-M., & Woldorff, M. G. (2010). Pinning down response inhibition in the brain—Conjunction analyses of the stop-signal task. NeuroImage, 52, 1621–1632.
Boehler, C. N., Appelbaum, L. G., Krebs, R. M., Hopf, J.-M., & Woldorff, M. G. (2012a). The influence of different stop-signal response time estimation procedures on behavior–behavior and brain–behavior correlations. Behavioural Brain Research, 229, 123–130.
Boehler, C. N., Hopf, J.-M., Krebs, R. M., Stoppel, C. M., Schoenfeld, M. A., Heinze, H. J., & Noesselt, T. (2011b). Task-load-dependent activation of dopaminergic midbrain areas in the absence of reward. Journal of Neuroscience, 31, 4955–4961. doi:10.1523/JNEUROSCI.4845-10.2011
Boehler, C. N., Hopf, J.-M., Stoppel, C. M., & Krebs, R. M. (2012b). Motivating inhibition–reward prospect speeds up response cancellation. Cognition, 125, 498–503. doi:10.1016/j.cognition.2012.07.018
Boehler, C. N., Münte, T. F., Krebs, R. M., Heinze, H. J., Schoenfeld, M. A., & Hopf, J.-M. (2009). Sensory MEG responses predict successful and failed inhibition in a stop-signal task. Cerebral Cortex, 19, 134–145.
Boucher, L., Palmeri, T. J., Logan, G. D., & Schall, J. D. (2007). Inhibitory control in mind and brain: An interactive race model of countermanding saccades. Psychological Review, 114, 376–397. doi:10.1037/0033-295X.114.2.376
Braver, T. S. (2012). The variable nature of cognitive control: A dual mechanisms framework. Trends in Cognitive Sciences, 16, 106–113. doi:10.1016/j.tics.2011.12.010
Braver, T. S., Gray, J. R., & Burgess, G. C. (2007). Explaining the many varieties of working memory variation: Dual mechanisms of cognitive control. In A. R. A. Conway, C. Jarrold, M. J. Kane, A. Miyake, & J. N. Towse (Eds.), Variation in working memory (pp. 76–106). Oxford, UK: Oxford Univerity Press.
Bush, G., Vogt, B. A., Holmes, J., Dale, A. M., Greve, D., Jenike, M. A., & Rosen, B. R. (2002). Dorsal anterior cingulate cortex: A role in reward-based decision making. Proceedings of the National Academy of Sciences, 99, 523–528.
Cai, W., Cannistraci, C. J., Gore, J. C., & Leung, H. C. (2013). Sensorimotor-independent prefrontal activity during response inhibition. Human Brain Mapping. Advance online publication. doi:10.1002/hbm.22315
Cai, W., Oldenkamp, C. L., & Aron, A. R. (2011). A proactive mechanism for selective suppression of response tendencies. Journal of Neuroscience, 31, 5965–5969. doi:10.1523/JNEUROSCI.6292-10.2011
Chamberlain, S. R., Hampshire, A., Muller, U., Rubia, K., Del Campo, N., Craig, K., & Sahakian, B. J. (2009). Atomoxetine modulates right inferior frontal activation during inhibitory control: A pharmacological functional magnetic resonance imaging study. Biological Psychiatry, 65, 550–555.
Chambers, C. D., Garavan, H., & Bellgrove, M. A. (2009). Insights into the neural basis of response inhibition from cognitive and clinical neuroscience. Neuroscience & Biobehavioral Reviews, 33, 631–646. doi:10.1016/j.neubiorev.2008.08.016
Chatham, C. H., Claus, E. D., Kim, A., Curran, T., Banich, M. T., & Munakata, Y. (2012). Cognitive control reflects context monitoring, not motoric stopping, in response inhibition. PLoS ONE, 7, e31546. doi:10.1371/journal.pone.0031546
Chau, D. T., Roth, R. M., & Green, A. I. (2004). The neural circuitry of reward and its relevance to psychiatric disorders. Current Psychiatry Reports, 6, 391–399.
Chikazoe, J. (2010). Localizing performance of go/no-go tasks to prefrontal cortical subregions. Current Opinion in Psychiatry, 23, 267–272.
Chikazoe, J., Jimura, K., Hirose, S., Yamashita, K., Miyashita, Y., & Konishi, S. (2009). Preparation to inhibit a response complements response inhibition during performance of a stop-signal task. Journal of Neuroscience, 29, 15870–15877.
Chiu, Y.-C., & Aron, A. R. (2013). Unconsciously triggered response inhibition requires an executive setting. Journal of Experimental Psychology: General. Advance online publication. doi:10.1037/a0031497
Chiu, Y.-C., Aron, A. R., & Verbruggen, F. (2012). Response suppression by automatic retrieval of stimulus–stop association: Evidence from transcranial magnetic stimulation. Journal of Cognitive Neuroscience, 24, 1908–1918. doi:10.1162/jocn_a_00247
Dalley, J. W., Everitt, B. J., & Robbins, T. W. (2011). Impulsivity, compulsivity, and top-down cognitive control. Neuron, 69, 680–694.
Della Libera, C., & Chelazzi, L. (2006). Visual selective attention and the effects of monetary rewards. Psychological Science, 17, 222–227. doi:10.1111/j.1467-9280.2006.01689.x
Dodds, C. M., Morein-Zamir, S., & Robbins, T. W. (2011). Dissociating inhibition, attention, and response control in the frontoparietal network using functional magnetic resonance imaging. Cerebral Cortex, 21, 1155–1165.
Duann, J. R., Ide, J. S., Luo, X., & Li, C. S. (2009). Functional connectivity delineates distinct roles of the inferior frontal cortex and presupplementary motor area in stop signal inhibition. Journal of Neuroscience, 29, 10171–10179.
Engelmann, J. B., Damaraju, E., Padmala, S., & Pessoa, L. (2009). Combined effects of attention and motivation on visual task performance: Transient and sustained motivational effects. Frontiers in Human Neuroscience, 3(4), 1–17. doi:10.3389/neuro.09.004.2009
Etkin, A., Egner, T., & Kalisch, R. (2011). Emotional processing in anterior cingulate and medial prefrontal cortex. Trends in Cognitive Sciences, 15, 85–93.
Filevich, E., Kuhn, S., & Haggard, P. (2012). Negative motor phenomena in cortical stimulation: implications for inhibitory control of human action. Cortex, 48, 1251–1261.
Forstmann, B. U., Anwander, A., Schäfer, A., Neumann, J., Brown, S., Wagenmakers, E.-J., & Turner, R. (2010). Cortico–striatal connections predict control over speed and accuracy in perceptual decision making. Proceedings of the National Academy of Sciences, 107, 15916–15920. doi:10.1073/pnas.1004932107
Friston, K. J., Fletcher, P., Josephs, O., Holmes, A., Rugg, M. D., & Turner, R. (1998). Event-related fMRI: Characterizing differential responses. NeuroImage, 7, 30–40.
Friston, K. J., Penny, W. D., & Glaser, D. E. (2005). Conjunction revisited. NeuroImage, 25, 661–667. doi:10.1016/j.neuroimage.2005.01.013
Hampshire, A., Chamberlain, S. R., Monti, M. M., Duncan, J., & Owen, A. M. (2010). The role of the right inferior frontal gyrus: Inhibition and attentional control. NeuroImage, 50, 1313–1319.
Han, S., Huettel, S. A., Raposo, A., Adcock, R. A., & Dobbins, I. G. (2010). Functional significance of striatal responses during episodic decisions: Recovery or goal attainment? Journal of Neuroscience, 30, 4767–4775. doi:10.1523/JNEUROSCI.3077-09.2010
Hayden, B. Y., Pearson, J. M., & Platt, M. L. (2009). Fictive reward signals in the anterior cingulate cortex. Science, 324, 948–950.
Hickey, C., Chelazzi, L., & Theeuwes, J. (2010). Reward changes salience in human vision via the anterior cingulate. Journal of Neuroscience, 30, 11096–11103. doi:10.1523/JNEUROSCI.1026-10.2010
Holroyd, C. B., & Coles, M. G. (2002). The neural basis of human error processing: Reinforcement learning, dopamine, and the error-related negativity. Psychological Review, 109, 679–709. doi:10.1037/0033-295X.109.4.679
Ide, J. S., Shenoy, P., Yu, A. J., & Li, C. S. (2013). Bayesian prediction and evaluation in the anterior cingulate cortex. Journal of Neuroscience, 33, 2039–2047. doi:10.1523/JNEUROSCI.2201-12.2013
Jimura, K., Locke, H. S., & Braver, T. S. (2010). Prefrontal cortex mediation of cognitive enhancement in rewarding motivational contexts. Proceedings of the National Academy of Sciences, 107, 8871–8876. doi:10.1073/pnas.1002007107
Kao, M. H., Mandal, A., Lazar, N., & Stufken, J. (2009). Multi-objective optimal experimental designs for event-related fMRI studies. NeuroImage, 44, 849–856.
Kinnison, J., Padmala, S., Choi, J. M., & Pessoa, L. (2012). Network analysis reveals increased integration during emotional and motivational processing. Journal of Neuroscience, 32, 8361–8372. doi:10.1523/JNEUROSCI.0821-12.2012
Knutson, B., Adams, C. M., Fong, G. W., & Hommer, D. (2001). Anticipation of increasing monetary reward selectively recruits nucleus accumbens. Journal of Neuroscience, 21, RC159.
Knyazev, G. G., Levin, E. A., & Savostyanov, A. N. (2008). A failure to stop and attention fluctuations: An evoked oscillations study of the stop-signal paradigm. Clinical Neurophysiology, 119, 556–567.
Kouneiher, F., Charron, S., & Koechlin, E. (2009). Motivation and cognitive control in the human prefrontal cortex. Nature Neuroscience, 12, 939–945.
Krebs, R. M., Boehler, C. N., Appelbaum, L. G., & Woldorff, M. G. (2013). Reward associations reduce behavioral interference by changing the temporal dynamics of conflict processing. PLoS ONE, 8, e53894. doi:10.1371/journal.pone.0053894
Krebs, R. M., Boehler, C. N., Egner, T., & Woldorff, M. G. (2011). The neural underpinnings of how reward associations can both guide and misguide attention. Journal of Neuroscience, 31, 9752–9759.
Krebs, R. M., Boehler, C. N., Roberts, K. C., Song, A. W., & Woldorff, M. G. (2012). The involvement of the dopaminergic midbrain and cortico-striatal-thalamic circuits in the integration of reward prospect and attentional task demands. Cerebral Cortex, 22, 607–615.
Krebs, R. M., Boehler, C. N., & Woldorff, M. G. (2010). The influence of reward associations on conflict processing in the Stroop task. Cognition, 117, 341–347.
Lenartowicz, A., Verbruggen, F., Logan, G. D., & Poldrack, R. A. (2011). Inhibition-related activation in the right inferior frontal gyrus in the absence of inhibitory cues. Journal of Cognitive Neuroscience, 23, 3388–3399.
Leotti, L. A., & Wager, T. D. (2010). Motivational influences on response inhibition measures. Journal of Experimental Psychology: Human Perception and Performance, 36, 430–447.
Leung, H.-C., & Cai, W. (2007). Common and differential ventrolateral prefrontal activity during inhibition of hand and eye movements. Journal of Neuroscience, 27, 9893–9900.
Levy, B. J., & Wagner, A. D. (2011). Cognitive control and right ventrolateral prefrontal cortex: Reflexive reorienting, motor inhibition, and action updating. Annals of the New York Academy of Sciences, 1224, 40–62.
Locke, H. S., & Braver, T. S. (2008). Motivational influences on cognitive control: Behavior, brain activation, and individual differences. Cognitive, Affective, & Behavioral Neuroscience, 8, 99–112. doi:10.3758/CABN.8.1.99
Logan, G. D. (1994). On the ability to inhibit thought and action: A user’s guide to the stop signal paradigm. In D. Dagenbach & T. H. Carr (Eds.), Inhibitory processes in attention, memory, and language (pp. 189–239). San Diego, CA: Academic Press.
Logan, G. D., & Cowan, W. B. (1984). On the ability to inhibit thought and action: A theory of an act of control. Psychological Review, 91, 295–327. doi:10.1037/0033-295X.91.3.295
Manuel, A. L., Bernasconi, F., & Spierer, L. (2013). Plastic modifications within inhibitory control networks induced by practicing a stop-signal task: An electrical neuroimaging study. Cortex, 49, 1141–1147. doi:10.1016/j.cortex.2012.12.009
Manuel, A. L., Grivel, J., Bernasconi, F., Murray, M. M., & Spierer, L. (2010). Brain dynamics underlying training-induced improvement in suppressing inappropriate action. Journal of Neuroscience, 30, 13670–13678. doi:10.1523/JNEUROSCI.2064-10.2010
Maunsell, J. H. R. (2004). Neuronal representations of cognitive state: Reward or attention? Trends in Cognitive Sciences, 8, 261–265. doi:10.1016/j.tics.2004.04.003
McLaren, D. G., Ries, M. L., Xu, G., & Johnson, S. C. (2012). A generalized form of context-dependent psychophysiological interactions (gPPI): A comparison to standard approaches. NeuroImage, 61, 1277–1286.
Montague, P. R., Hyman, S. E., & Cohen, J. D. (2004). Computational roles for dopamine in behavioural control. Nature, 431, 760–767.
Munakata, Y., Herd, S. A., Chatham, C. H., Depue, B. E., Banich, M. T., & O’Reilly, R. C. (2011). A unified framework for inhibitory control. Trends in Cognitive Sciences, 15, 453–459. doi:10.1016/j.tics.2011.07.011
Neubert, F. X., Mars, R. B., Buch, E. R., Olivier, E., & Rushworth, M. F. (2010). Cortical and subcortical interactions during action reprogramming and their related white matter pathways. Proceedings of the National Academy of Sciences, 107, 13240–13245.
O’Doherty, J., Kringelbach, M. L., Rolls, E. T., Hornak, J., & Andrews, C. (2001). Abstract reward and punishment representations in the human orbitofrontal cortex. Nature Neuroscience, 4, 95–102.
Overtoom, C. C., Bekker, E. M., van der Molen, M. W., Verbaten, M. N., Kooij, J. J., Buitelaar, J. K., & Kenemans, J. L. (2009). Methylphenidate restores link between stop-signal sensory impact and successful stopping in adults with attention-deficit/hyperactivity disorder. Biological Psychiatry, 65, 614–619.
Padmala, S., & Pessoa, L. (2010a). Interactions between cognition and motivation during response inhibition. Neuropsychologia, 48, 558–565. doi:10.1016/j.neuropsychologia.2009.10.017
Padmala, S., & Pessoa, L. (2010b). Moment-to-moment fluctuations in fMRI amplitude and interregion coupling are predictive of inhibitory performance. Cognitive, Affective, & Behavioral Neuroscience, 10, 279–297. doi:10.3758/CABN.10.2.279
Padmala, S., & Pessoa, L. (2011). Reward reduces conflict by enhancing attentional control and biasing visual cortical processing. Journal of Cognitive Neuroscience, 23, 3419–3432. doi:10.1162/jocn_a_00011
Pessoa, L., & Engelmann, J. B. (2010). Embedding reward signals into perception and cognition. Frontiers in Neuroscience, 4, 17. doi:10.3389/fnins.2010.00017
Pochon, J. B., Levy, R., Fossati, P., Lehéricy, S., Poline, J. B., Pillon, B., & Dubois, B. (2002). The neural system that bridges reward and cognition in humans: An fMRI study. Proceedings of the National Academy of Sciences, 99, 5669–5674. doi:10.1073/pnas.082111099
Ridderinkhof, K. R. (2002). Micro- and macro-adjustments of task set: Activation and suppression in conflict tasks. Psychological Research, 66, 312–323. doi:10.1007/s00426-002-0104-7
Ridderinkhof, K. R., Forstmann, B. U., Wylie, S. A., Burle, B., & van den Wildenberg, W. P. M. (2011). Neurocognitive mechanisms of action control: Resisting the call of the Sirens. Wires: Cognitive Science, 2, 174–192.
Ridderinkhof, K. R., Ullsperger, M., Crone, E. A., & Nieuwenhuis, S. (2004). The role of the medial frontal cortex in cognitive control. Science, 306, 443–447. doi:10.1126/science.1100301
Rowe, J. B., Eckstein, D., Braver, T., & Owen, A. M. (2008). How does reward expectation influence cognition in the human brain? Journal of Cognitive Neuroscience, 20, 1980–1992.
Rushworth, M. F., Walton, M. E., Kennerley, S. W., & Bannerman, D. M. (2004). Action sets and decisions in the medial frontal cortex. Trends in Cognitive Sciences, 8, 410–417.
Satterthwaite, T. D., Ruparel, K., Loughead, J., Elliott, M. A., Gerraty, R. T., Calkins, M. E., & Wolf, D. H. (2012). Being right is its own reward: Load and performance related ventral striatum activation to correct responses during a working memory task in youth. NeuroImage, 61, 723–729. doi:10.1016/j.neuroimage.2012.03.060
Schall, J. D., Stuphorn, V., & Brown, J. W. (2002). Monitoring and control of action by the frontal lobes. Neuron, 36, 309–322.
Scheres, A., Oosterlaan, J., & Sergeant, J. A. (2001). Response inhibition in children with DSM-IV subtypes of AD/HD and related disruptive disorders: the role of reward. Child Neuropsychology, 7, 172–189.
Schmidt, L., Lebreton, M., Cléry-Melin, M.-L., Daunizeau, J., & Pessiglione, M. (2012). Neural mechanisms underlying motivation of mental versus physical effort. PLoS Biology, 10, e1001266. doi:10.1371/journal.pbio.1001266
Sebastian, A., Pohl, M. F., Klöppel, S., Feige, B., Lange, T., Stahl, C., & Tüscher, O. (2013). Disentangling common and specific neural subprocesses of response inhibition. NeuroImage, 64, 601–615. doi:10.1016/j.neuroimage.2012.09.020
Seeley, W. W., Menon, V., Schatzberg, A. F., Keller, J., Glover, G. H., Kenna, H., & Greicius, M. D. (2007). Dissociable intrinsic connectivity networks for salience processing and executive control. Journal of Neuroscience, 27, 2349–2356. doi:10.1523/JNEUROSCI.5587-06.2007
Sharp, D. J., Bonnelle, V., De Boissezon, X., Beckmann, C. F., James, S. G., Patel, M. C., & Mehta, M. A. (2010). Distinct frontal systems for response inhibition, attentional capture, and error processing. Proceedings of the National Academy of Sciences, 107, 6106–6111.
Shidara, M., & Richmond, B. J. (2002). Anterior cingulate: Single neuronal signals related to degree of reward expectancy. Science, 296, 1709–1711.
Sinopoli, K. J., Schachar, R., & Dennis, M. (2011). Reward improves cancellation and restraint inhibition across childhood and adolescence. Developmental Psychology, 47, 1479–1489.
Spierer, L., Chavan, C. F., & Manuel, A. L. (2013). Training-induced behavioral and brain plasticity in inhibitory control. Frontiers in Human Neuroscience, 7, 427. doi:10.3389/fnhum.2013.00427
Swick, D., Ashley, V., & Turken, A. U. (2008). Left inferior frontal gyrus is critical for response inhibition. BMC Neuroscience, 9, 102. doi:10.1186/1471-2202-9-102
Swick, D., Ashley, V., & Turken, U. (2011). Are the neural correlates of stopping and not going identical? Quantitative meta-analysis of two response inhibition tasks. NeuroImage, 56, 1655–1665. doi:10.1016/j.neuroimage.2011.02.070
Verbruggen, F., Aron, A. R., Stevens, M. A., & Chambers, C. D. (2010). Theta burst stimulation dissociates attention and action updating in human inferior frontal cortex. Proceedings of the National Academy of Sciences, 107, 13966–13971.
Verbruggen, F., Chambers, C. D., & Logan, G. D. (2013). Fictitious inhibitory differences: How skewness and slowing distort the estimation of stopping latencies. Psychological Science, 24, 352–362. doi:10.1177/0956797612457390
Verbruggen, F., & Logan, G. D. (2008). Automatic and controlled response inhibition: Associative learning in the go/no-go and stop-signal paradigms. Journal of Experimental Psychology: General, 137, 649–672. doi:10.1037/a0013170
Verbruggen, F., & Logan, G. D. (2009). Models of response inhibition in the stop-signal and stop-change paradigms. Neuroscience & Biobehavioral Reviews, 33, 647–661. doi:10.1016/j.neubiorev.2008.08.014
Wessel, J. R., & Aron, A. R. (2013). Unexpected events induce motor slowing via a brain mechanism for action-stopping with global suppressive effects. Journal of Neuroscience, 33, 18481–18491. doi:10.1523/JNEUROSCI.3456-13.2013
Wittmann, B. C., Schott, B. H., Guderian, S., Frey, J. U., Heinze, H. J., & Duzel, E. (2005). Reward-related FMRI activation of dopaminergic midbrain is associated with enhanced hippocampus-dependent long-term memory formation. Neuron, 45, 459–467.
Zandbelt, B. B., Bloemendaal, M., Hoogendam, J. M., Kahn, R. S., & Vink, M. (2013). Transcranial magnetic stimulation and functional MRI reveal cortical and subcortical interactions during stop-signal response inhibition. Journal of Cognitive Neuroscience, 25, 157–174. doi:10.1162/jocn_a_00309
Author Note
This research was supported by the Ghent University Multidisciplinary Research Platform (“The Integrative Neuroscience of Behavioral Control”), a postdoctoral fellowship from the Flemish Research Foundation (No. FWO11/PDO/016) to R.M.K., and a grant from the German Research Foundation (No. SFB 779/TPA1) to J.M.H.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Boehler, C.N., Schevernels, H., Hopf, JM. et al. Reward prospect rapidly speeds up response inhibition via reactive control. Cogn Affect Behav Neurosci 14, 593–609 (2014). https://doi.org/10.3758/s13415-014-0251-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13415-014-0251-5