
Abstract
The main question examined in the present work was whether spatial attention can be deployed to an appropriate structural framework not only endogenously when the framework is displayed continuously, as in previous work, but also exogenously, when it is displayed transiently 100 ms before the target. The results of five experiments answered that question in the negative. We found that the onset transient triggered by a brief presentation of the structural framework did enhance the response to the upcoming target. That enhancement, however, was due not to the framework itself but to the alerting effect produced by its sudden onset, witness the finding that the same enhancement was produced by an onset transient triggered by a featureless stimulus (i.e., by a brief dimming of the entire screen, in the absence of a structural framework). We conclude that spatial attention can be deployed to the region demarcated by a structural framework when it is deployed endogenously but not when it is deployed exogenously. A theoretical account of the results is proposed in terms of the temporal dynamics of the locus cœruleus/norepinephrine neuromodulatory system.
Similar content being viewed by others
As we move about our world, we are exposed to a constantly-changing stream of information that often exceeds the processing capabilities of the visual system. Selective attention allows for the processing of stimuli that are relevant to the task at hand, while filtering out irrelevant information. A good deal is known about selective attention: its focus can be readily shifted from one object or location to another (Posner, 1980; Posner & Cohen, 1984; Weichselgartner & Sperling, 1987), and its spatial extent can be expanded or contracted so as to encompass larger or smaller objects or regions of space (Castiello & Umiltà, 1990; Eriksen & Yeh, 1985; Jefferies & Di Lollo, 2009; Jefferies, Gmeindl, & Yantis, 2014; Jefferies, Roggeveen, Enns, Bennett, Sekuler, & Di Lollo, 2015). Selective attention can also be divided into more than one focus (Bay & Wyble, 2014; Jefferies, Enns, & Di Lollo, 2014; McMains & Sommers, 2004).
Whether selective attention can be deployed in the form of an annulus depends on the context. We have shown that attention can indeed be deployed in the form of an annulus, but only when an appropriate structural framework is on view to which attention can be anchored (Jefferies & Di Lollo, 2015). In the present study we ask whether attention can be deployed to such a region not only endogenously in response to the continuous presentation of a structural framework, but also exogenously in response to the transient presentation of a framework.
As in the study of Jefferies and Di Lollo (2015), the present study made use of a finding by Visser, Bischof, and Di Lollo (2004) who employed the attentional blink (AB) paradigm, in which two sequential targets (T1, T2) are inserted in a rapid stream of digit distractors. The AB denotes impaired identification of T2 if it is presented less than about 500 ms after T1 (Potter, Chun, Banks, & Muckenhoupt, 1998; Raymond, Shapiro, & Arnell, 1992). Two conditions in the Visser et al. (2004) study are especially relevant. In one condition, a stream of digit distractors was presented at fixation; in the other condition, the central location contained only a fixation cross. T1 and T2 were letters presented in different locations either above, below, to the left, or to the right of center. Notably, neither target ever appeared in the central location. The key finding was that T2 identification was impaired when a central stream of distractors was present, even though the stream was task-irrelevant and the observers had been informed that no targets would ever appear in the central location. Based on this result, Visser et al. (2004) concluded that the observers were unable to deploy attention in the form of an annulus, so as to ignore the central stream of distractors. Had they been able to do so, the central stream would not have been processed and, therefore, would not have disrupted the identification of the peripheral targets.
This conclusion was qualified by Jefferies and Di Lollo (2015) who employed the basic paradigm of Visser et al. (2004) and used reaction time (RT) rather than accuracy as the response measure to index T2-impairment during the AB. Observers were required to make a speeded response to T2, and then identify T1 at leisure. RT has been used as the response measure in earlier studies of the AB (e.g., Jolicoeur & Dell’Acqua, 1998; Lagroix, Grubert, Spalek, Di Lollo, & Eimer, 2015; Zuvic, Visser, & Di Lollo, 2000) for two main reasons. First, RT is free from possible confounds arising from response-ceiling constraints inherent in the 100% limit of the accuracy scale (e.g., Ghorashi, Enns, Spalek, & Di Lollo, 2009). Second, RT is a more direct measure of the delay in T2 processing caused by the requirement to process T1 as postulated in bottleneck theories of the AB (Chun & Potter, 1995; Jolicoeur & Dell’Acqua, 1998; Wyble, Potter, Bowman, & Nieuwenstein, 2011).
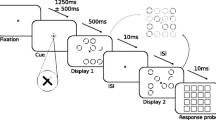
Having confirmed the results of Visser et al. (2004) with RT as the response measure, Jefferies and Di Lollo (2015) went on to show that attention could indeed be deployed in the form of an annulus, provided that an appropriate structural framework was present in the display. The framework consisted of four square outlines demarcating the four locations around the central stream where the targets could appear (see Figure 1, right-hand sequence). The main experiment comprised two conditions: in the Anchors condition, the four squares were present continuously throughout each trial, and the targets were displayed inside a random two of the squares. In the No-Anchors condition, the targets were presented in the corresponding locations on an otherwise blank screen (Figure 1, left-hand sequence). The results revealed faster RTs in the Anchors than in the No-Anchors condition, consistent with the idea that the structural framework facilitated the deployment of attention in the form of an annulus, thus reducing interference from the central stream of distractors. Jefferies and Di Lollo (2015) also concluded that attention was deployed to the annular region demarcated by the square outlines rather than to the individual square outlines themselves.

Display sequence in Experiment 1. The left-hand sequence illustrates the No-Anchors condition; the right-hand sequence illustrates the Transient-Anchors condition. In both cases, the central digits are distractors and the peripheral letters are targets. T1 is masked by a digit; T2 is not masked. The two targets never appeared in the same location, and never appeared in the central distractor stream.
Further support for this idea came from experiments in which the structural framework consisted of eight square outlines rather than four, or of an annular region bounded by two concentric circles (Jefferies & Di Lollo, 2015, Experiments 3 and 5). These, along with other similar experiments (e.g., Eimer, 1999; Juola, Bouwhuis, Cooper, & Warner, 1991), yielded equivalent results, consistent with the idea that attention can be deployed in the form of an annulus. From a broader perspective, the outcomes of all these studies, especially those in which the salient region of the display was bounded by two concentric circles, can be seen as instances of object-based attention (e.g., Egly, Driver, & Rafal, 1994). In this view, the structural framework can be thought of as forming a unitary object to which attention is deployed.
Exogenous and endogenous modes of attentional deployment
In a comprehensive review of the literature on covert attention, Carrasco (2011, page 1488) noted that
there are two covert attention systems that facilitate processing and select information: ‘endogenous’ and ‘exogenous’. The former is a voluntary system that corresponds to our ability to wilfully monitor information at a given location; the latter is an involuntary system that corresponds to an automatic orienting response to a location where sudden stimulation has occurred. Endogenous attention is also known as ‘sustained’ attention and exogenous attention is also known as ‘transient’ attention.
Carrasco also noted that the terms endogenous and sustained are used interchangeably in the literature, as are the terms exogenous and transient.
An important procedural detail in the study of Jefferies and Di Lollo (2015) in relation to the present work is that, in that study, the structural framework was displayed continuously throughout each trial, leading to a sustained attentional response. In the present work we investigate whether attention can still be deployed to the region demarcated by a structural framework when the framework is presented transiently. Namely, instead of being visible continuously throughout a trial, the four squares that comprised the framework were presented in a brief flash directly before T2 (see Figure 1). In essence, the present question is whether spatial attention can be deployed to the region demarcated by a structural framework not only when it is triggered endogenously (by the sustained presentation of the four squares throughout a trial), but also when it is generated exogenously (by the transient presentation of the squares just before T2).
There is general consensus that exogenous and endogenous modes of deploying attention are subserved by mechanisms that are at least partly independent of one another (e.g., Berger, Henik, & Rafal, 2005; Carrasco, 2011). For example, the two modes of attentional deployment follow markedly different time courses (e.g., Nakayama & Mackeben, 1989). As such, the two modes may differ in their ability to mediate the deployment of attention to the region demarcated by a structural framework.
Experiment 1
Experiment 1 was designed to determine whether spatial attention can be deployed exogenously when the supporting spatial framework is presented as a transient stimulus. To that end, the anchors were flashed briefly just before T2. The results revealed faster RTs with the transient presentation of the anchors relative to a no-anchors condition.
Methods
Observers
Fourteen undergraduate students at Griffith University and Simon Fraser University participated in the experiment for course credit. All were naïve as to the purpose of the experiment and reported normal or corrected-to-normal vision. There were two conditions – the No-Anchors and the Transient-Anchors conditions – and participants completed both conditions in counterbalanced order.
Apparatus and stimuli
All stimuli were presented on a computer monitor viewed from a distance of approximately 57 cm. A black fixation cross (0.25° × 0.25°) was displayed in the center of the light-gray background at the beginning of each trial. Observers initiated each trial by pressing the spacebar. After a brief delay, a stream of black distractor digits (0–9; 0.9° vertically) replaced the fixation cross. The digits were selected randomly with the restriction that the same digit could not be presented successively. The first target (T1) was a letter (0.9° vertically) selected randomly from the English alphabet, excluding the letters I, O, Q, Z, C, and G. The second target (T2) was the letter C on a random half of the trials and the letter G on the remaining trials.
The targets appeared randomly but with equal probability at separate locations 1.75° (center-to-center) above, below, to the left, or to the right of fixation, but never in the central location. Each digit and target was displayed for 50 ms, followed by a blank inter-stimulus-interval (ISI) of 50 ms. T1 was always followed in the same location by a single digit which served as a mask. T2 was not masked. Participants were instructed to respond to T2 as quickly as possible, and then to identify T1 by pressing the corresponding key on the keyboard at their leisure. They were further instructed to keep the index finger of their left hand on the ‘C’ key and the index finger of their right hand on the ‘G’ key in readiness to respond.
In the Transient-Anchors condition, the black outlines of four squares (1.2° ×1.2° each) were displayed. Each square was centered on one of the four potential target locations. The squares onset 100 ms prior to the onset of the second target and were displayed for 50 ms. The display sequence is illustrated in Figure 1.
Procedures
In the No-Anchors condition (Figure 1, left-hand panel), each trial began with the presentation of the fixation cross, followed by a 500-ms delay. The stream of distractor digits then replaced the fixation cross in the center of the screen. After a random 8 to 14 leading digits, T1 was presented above, below, to the left, or to the right of fixation. The target location was chosen randomly on each trial, with the restriction that each of the four locations was chosen an equal number of times. T2 never appeared at the same location as T1, and was therefore presented at one of the remaining three locations. Neither target was ever presented in the central RSVP stream. A mask, selected randomly from the digits 0–9, was presented 100 ms after T1; T2 was not masked. T2 followed T1 at one of three temporal lags: 100, 300, or 900 ms, presented randomly across trials, with the restriction that each lag appeared on an equal number of trials. When the lag was 100 ms, T2 appeared simultaneously with the T1 mask.
The sequence of events in the Transient-Anchors condition was identical to that in the No-Anchors condition with a single critical difference: the outlines of four black squares were displayed briefly above, below, to the left, and to the right of the central RSVP stream. The squares outlined the four locations at which the targets could occur. The squares onset 100 ms prior to the presentation of T2 and remained on display for 50 ms (Figure 1, right-hand panel).
Results and discussion
Mean percentages of correct identification of T1 were 73.7%, 77.9%, and 75.0% at Lags 1, 3, and 9 in the No-Anchors condition, and 70.8%, 83.6%, and 84.9% at Lags 1, 3, and 9 in the Transient-Anchors condition. The corresponding accuracy scores for T2 were 93.8%, 95.6%, and 96.5% at Lags 1, 3, and 9 in the No-Anchors condition, and 91.5%, 93.3%, and 94.4% at Lags 1, 3, and 9 in the Transient-Anchors condition.
Accuracy was consistently higher for T2 than for T1, reflecting the fact that, in the display sequence, T1 was masked but T2 was not. The accuracy scores for T2 were uniformly constrained by the ceiling imposed by the 100% limit of the response scale. Notably, no such constraint was in evidence in the corresponding RT scores (see below). Despite this constraint, the T2 accuracy scores revealed a significant AB (Lag) and a marginally significant effect of Condition (Anchor/No-Anchor), as shown by a 2 (Anchors) × 3 (Lag) repeated-measure ANOVA: Lag, F(2,26) = 8.47, p = .001, ƞp 2 = .395; Anchors, F(1,13) = 4.45, p = .055, ƞp 2 = .255. The interaction effect was not significant, F(2,26) < 1. Comparison of this analysis with the corresponding analysis of RT scores (see below) shows that similar patterns of results are obtained with accuracy and with RT response measures. However, because accuracy scores are obviously constrained by a response ceiling, and because RT was the explicit response measure in the present work, statistical analyses were restricted to RT scores in all further experiments.
Figure 2 shows the mean of the median RT scores as a function of Lag for the No-Anchors and the Transient-Anchors conditions. The results were analyzed in a 2 (Anchors) × 3 (Lag) repeated-measures ANOVA, which revealed significant main effects of Anchors, F(1,13) = 12.24, p = .004, ƞp 2 = .485, and Lag, F(2,26) = 22.56, p < .001, ƞp 2 = .634. The interaction effect was not significant, F(2,26) = 2.63, p = .091, ƞp 2 = .168.

Results of Experiment 1. The graph illustrates the mean of the median RTs to T2; error bars indicate one standard error.
The outcome of the statistical analysis confirms the graphical evidence in Figure 2 that transiently-displayed anchors led to faster RTs at all inter-target lags. On the face of it, this pattern of results is consistent with the proposition that spatial attention can be deployed to the region demarcated by a structural framework not only when the framework is presented in a sustained fashion throughout a trial, but also when it is displayed transiently.
Presenting the structural framework (the four squares) as a brief transient stimulus, however, entails a potential ambiguity for interpretation. On one hand, the enhanced performance could be attributed to the deployment of attention to the region defined by the four squares, as in studies of attentional capture by a sudden-onset stimulus (e.g., Egeth & Yantis, 1997). Alternatively, the enhancement may not be confined to that region. Rather, it could be spatially nonspecific, as in the case of alerting brought about by a sudden change in the display (e.g., Fernandez-Duque & Posner, 1997; Spalek & Di Lollo, 2011).
The term alerting refers to a state of heightened attention that follows the presentation of a warning signal. Unlike attentional orienting signals, alerting signals provide little or no spatial information regarding the location of the target (Fernandez-Duque & Posner, 1997). Alerting states can be tonic or phasic (e.g., Robertson, Mattingley, Rorden, & Driver, 1998). Tonic alerting denotes a temporally enduring state of heightened attention. Phasic alerting, on the other hand, denotes a short-lived change in attentional state that can boost performance over a period of about 200 ms (Bernstein, Rose, & Ashe, 1970; Nakayama & Mackeben, 1989; Schmidt, Gielen, & van den Heuvel, 1984; Spalek & Di Lollo, 2011). In the present work, the term “alerting” refers exclusively to phasic alerting.
Experiment 2
Experiment 2 was designed to determine whether the results of Experiment 1 arose from attention being deployed to the region specified by a structural framework or from spatially-nonspecific alerting. To this end, we employed three conditions. The first two, the No-Anchors and the Transient-Anchors conditions, were similar to the corresponding conditions in Experiment 1. In the third – Transient-Alerting – condition, the four anchors were replaced by an aggregate of 16 square outlines distributed over the display area, except for the region in which the targets were displayed, as illustrated in Figure 3C.

Stimulus displays in Experiment 2. Panel A: No-Anchors condition; panel B: Transient-Anchors condition; panel C: Transient-Alerting condition. Illustrated in the figure is the frame immediately preceding T2 in the RSVP stream.
We reasoned that: if the results of Experiment 1 were caused by attention being deployed to the region defined by the four anchors, then facilitation should occur in the Transient-Anchors but not in the Transient-Alerting conditions. This is because in the Transient-Alerting condition, no target was ever presented within any of the 16 squares, and thus they did not provide a framework to which attention could be anchored. In this case, RTs in the Transient-Alerting condition should be slower than RTs in the Transient-Anchors condition, and similar to those in the No-Anchors condition. If, on the other hand, the results of Experiment 1 were mediated by spatially-diffuse alerting, RTs in the present experiment should be about the same in the two transient conditions and faster than in the No-Anchors condition. This is because the responses in both transient conditions would be facilitated by the alerting response brought about by a sudden change in the display.
Methods
Observers
Fourteen undergraduate students at Simon Fraser University participated in the experiment for course credit. All were naïve as to the purpose of the experiment and reported normal or corrected-to-normal vision.
Apparatus, stimuli, and procedures
The apparatus, stimuli, and procedures in the No-Anchor and Transient-Anchors conditions were identical to the corresponding conditions of Experiment 1, with one exception: only two inter-target lags (300 and 900 ms) were employed in the present experiment instead of the three lags used in Experiment 1. Reducing the number of lags allowed a sufficient number of trials to be run within the time constraint of a session. The Transient-Alerting condition was the same as the Transient-Anchors condition with a single exception: the transient four-square display was replaced by sixteen squares (each 1.2° × 1.2°) distributed quasi-randomly within a square region subtending 10° × 10° (Figure 3, Panel C). Eight squares were always presented along the edges and corners of the square region; the remaining 8 squares were distributed randomly within the remainder of the square region. No square was ever displayed in the locations where the targets and distractors were presented. As in the Transient-Anchors condition, the sixteen-square display was presented 100 ms prior to the onset of the second target and remained on display for 50 ms.
Results and discussion
Mean percentages of correct identification of T1 were 93.4% and 92.6% at Lags 3 and 9 in the No-Anchors condition; 92.6% and 90.6% at Lags 3 and 9 in the Transient-Anchors condition; and 89.1% and 89.4% at Lags 3 and 9 in the Transient-Alerting condition. The corresponding accuracy scores for T2 were 96.8% and 97.4% at Lags 3 and 9 in the No-Anchors condition; 96.5% and 96.4% at Lags 3 and 9 in the Transient-Anchors condition; and 96.0% and 96.6% at Lags 3 and 9 in the Transient-Alerting condition.
Figure 4 shows the mean of the median RT scores as a function of Lag for the No-Anchors, Transient-Anchors, and Transient-Alerting conditions. The results were analyzed in a 3 (Condition) × 3 (Lag) repeated-measures ANOVA, which revealed significant effects of Condition, F(2,28) = 3.41, p = .047, ƞp 2 = .196, and Lag, F(1,14) = 26.74, p < .001, ƞp 2 = .656. The interaction effect was not significant, F<1.

Results of Experiment 2. Error bars indicate one standard error.
Critical to the objectives of the present experiment is the finding that the RTs in the Transient-Alerting condition were very similar to those in the Transient-Anchors condition, and faster than those in the No-Anchors condition. The important point is that, in the Transient-Alerting condition, T2 was presented in a blank area of the display, yet RTs were the same as in the Transient-Anchors condition in which T2 was presented inside an anchor. Clearly, what matters is not whether the target is presented within an attended region of the display but whether a transient event has occurred just before the target’s onset. This strongly suggests that, rather than mediating the deployment of attention to the region demarcated by the anchors, the transient event served a spatially non-specific alerting function.
Before reaching a definitive conclusion regarding the role of an alerting event, we should consider an alternative account based on summation of energies. Burr (1984) has shown that the visibility of a briefly-flashed test stimulus is enhanced when it is preceded by a brief, spatially non-overlapping, stimulus presented near-by and shortly beforehand. The enhanced visibility was attributed to temporal summation of energies between the contours of the two transient displays: the energy of the leading stimulus was said to summate spatiotemporally with that of the trailing test stimulus, enhancing the visibility of the latter.
There is an obvious parallel between the display sequence in Burr’s (1984) experiment and that used in the two transient conditions in the present experiment. This parallel prompts a possible interpretation of the present results in terms of energy summation. Namely, it is possible that the energy of the transient squares in the leading display summated with the energy of the brief trailing target, enhancing the visibility of the latter, and leading to faster RTs.
Experiment 3 was designed to decouple the “alerting” and the “energy summation” accounts of the enhanced RTs obtained in the two transient conditions in Experiment 2. The experiment comprised three conditions: the No-Anchors and the Transient-Anchors conditions were the same as in Experiment 2. The new Featureless-Alerting condition was the same as the No-Anchors condition except that the entire screen was dimmed briefly just before the presentation of T2. This introduced offset/onset transients, which could mediate an alerting effect in the absence of contours that might mediate summation of energy.
On the energy-summation account, RTs to T2 in the Featureless-Alerting condition should be the same as in the No-Anchors condition, and slower than in the Transient-Anchors condition. This is because in the Featureless-Alerting condition there would be no leading contours whose energy could be summated with the trailing T2. In contrast, on the alerting account, RTs in the Featureless-Alerting condition should be about the same as in the Transient-Anchors condition, and faster than in the No-Anchors condition. This is because the critical factor is held to be the occurrence of a transient event, regardless of how it is implemented. In Experiment 3, the transient event consisted of either a brief display of the four anchors (Transient-Anchors condition) or of a brief dimming of the entire screen (Featureless-Alerting condition).
Experiment 3
Methods
Observers
Fourteen undergraduate students at Simon Fraser University participated in the experiment for course credit. All were naïve as to the purpose of the experiment and reported normal or corrected-to-normal vision. Observers completed the No-Anchors, Transient-Anchors, and Featureless-Alerting conditions in counterbalanced order.
Apparatus, stimuli, and procedures
The apparatus, stimuli, and procedures in the No-Anchors and Transient-Anchors conditions were identical to the corresponding conditions of Experiment 2. In the Featureless-Alerting condition, the background color of the entire display changed from mid-gray (56.5 cd/m2) to dark gray (7.2 cd/m2) 100 ms prior to the onset of the second target. The color-change lasted for 50 ms.
Results and discussion
Mean percentages of correct identification of T1 were 90.6% and 91.2% at Lags 3 and 9 in the No-Anchors condition; 89.7%, and 89.6% at Lags 3 and 9 in the Transient-Anchors condition; and 89.9%, and 93.0% at Lags 3 and 9 in the Featureless-Alerting condition. The corresponding accuracy scores for T2 were 96.0% and 95.9% at Lags 3 and 9 in the No-Anchors condition; 94.9%, and 95.9% at Lags 3 and 9 in the Transient-Anchors condition; and 95.2%, and 97.0% at Lags 3 and 9 in the Featureless-Alerting condition.
Figure 5 shows the mean of the median RT scores as a function of Lag for the No-Anchors, Transient-Anchors, and Featureless-Alerting conditions. The results were analyzed in a 3 (Anchors) × 2 (Lag) repeated-measures ANOVA, which revealed significant main effects of Lag, F(1,13) = 28.6, p < .001, ƞp 2 = .688, and Anchors, F(2,26) = 4.86, p = .016, ƞp 2 = .272. The interaction effect was not significant, F(2,26) = 1.36, p = .275, ƞp 2 = .094.

Results of Experiment 3. Error bars indicate one standard error.
The results of Experiment 3 are unambiguous: RTs in the Featureless-Alerting condition were the same as in the Transient-Anchors condition, and both were faster than the RTs in the No-Anchors condition. This pattern of results is entirely consistent with an account based on alerting: performance was enhanced by a transient event, regardless of the way in which it was implemented. In light of the present results, it can be concluded that the enhancement in performance arose from spatially nonspecific alerting as distinct from energy summation between the leading and the trailing stimuli.
Experiment 4
One further issue needs to be considered before the enhanced performance in all three experiments reported thus far can be attributed unambiguously to spatially nonspecific alerting. The issue in question applies equally to all three experiments, but is best exemplified with reference to Experiment 3. That experiment contained two transient conditions: the Featureless-Alerting condition – in which the transient event consisted of a brief dimming of the entire blank screen – and the Transient-Anchors condition, in which the transient event consisted of a brief presentation of the four anchors. Figure 5 shows that the RTs in those two conditions were very similar to one another. We attributed that similarity to the effect of alerting, which was common to both conditions.
Similarity of outcomes, however, need not imply commonality of underlying mechanisms. It is possible, for example, that the faster RTs in Experiment 3 were mediated by spatially-nonspecific alerting in the Featureless-Alerting condition – in which no anchors were present on the screen – but by the deployment of attention to the region defined by the anchors in the Transient-Anchors condition, in which the targets were presented within the anchors.
Experiment 4 was designed to decouple these two options. There were three conditions: the No-Anchors and the Transient-Anchors conditions were the same as in Experiment 3. The new Spread-Anchors condition was the same as the Transient-Anchors condition except that the four squares were displayed at more eccentric locations relative to the squares in the Transient-Anchors condition. This means that, in the Spread-Anchors condition, the targets appeared not within the anchors, but in a more central blank area of the screen, as illustrated in Figure 6A. Thus, while serving as an alerting event, the squares could not serve as a structural framework to which attention could be deployed.

Panel A: stimulus display in the Spread-Anchors condition. Panel B: results of Experiment 4. Error bars indicate one standard error.
If the RT enhancement seen in Experiment 3 – and in the preceding experiments – was due to alerting, then the RTs in the Spread-Anchor condition should be about the same as in the Transient-Anchors condition, and both should be faster than the RTs in the No-Anchors condition. If, on the other hand, the enhancement in the Transient-Anchors condition arose from the deployment of attention to the region defined by the four anchors, the RTs in the Spread-Anchors condition should be slower than in the Transient-Anchors condition, and closer to the RTs in the No-Anchors condition. This is because in neither the Spread-Anchors condition nor in the No-Anchors condition were the targets presented within the region defined by the anchors.
Methods
Observers
Nineteen undergraduate students at Simon Fraser University participated in the experiment for course credit. All were naïve as to the purpose of the experiment and reported normal or corrected-to-normal vision. Observers completed the No-Anchor, Transient-Anchors, and Spread-Anchors conditions in counterbalanced order.
Apparatus, stimuli, and procedures
The apparatus, stimuli, and procedures in the No-Anchor and Transient-Anchors conditions were the same as the corresponding conditions of Experiment 2. The Spread-Anchors condition was the same as the Transient-Anchors condition with a single difference. Rather than the four squares being centered on the four potential target locations, the four squares were displayed in the four corners of an imaginary square 10° × 10° (see Figure 6, Panel A). The total amount of information in the Spread-Anchors display was therefore identical to that of the Transient-Anchors display; there was, however, no useful structural information to assist in the deployment of spatial attention.
Results and discussion
Mean percentages of correct identification of T1 were 92.1% and 90.9% at Lags 3 and 9 in the No-Anchors condition; 91.9%, and 90.9% at Lags 3 and 9 in the Transient-Anchors condition; and 92.7%, and 93.2% at Lags 3 and 9 in the Spread-Anchors condition. The corresponding accuracy scores for T2 were 96.4% and 96.2% at Lags 3 and 9 in the No-Anchors condition; 96.2%, and 96.3% at Lags 3 and 9 in the Transient-Anchors condition; and 96.3%, and 96.6% at Lags 3 and 9 in the Spread-Anchors condition.
Panel B of Figure 6 shows the mean of the median RT scores as a function of Lag for the No-Anchors, Transient-Anchors, and Spread-Anchors conditions. The results were analyzed in a 3 (Condition) × 2 (Lag) repeated-measures ANOVA, which revealed significant main effects of Lag, F(1,18) = 46.93, p < .001, ƞp 2 = .723, and Condition, F(2,36) = 3.65, p = .036, ƞp 2 = .169. The interaction effect was not significant, F(2,36) = 2.07, p = .14, ƞp 2 = .103.
Combined with the outcome of the statistical analysis, the results illustrated in Figure 6 are clearly consistent with the hypothesis that the enhanced performance in the Spread-Anchors and Transient-Anchors conditions was mediated not by the deployment of attention to the region defined by the anchors, but by spatially-nonspecific alerting triggered by the transient presentation of the anchors. Had the enhancement been mediated by the deployment of attention to the region defined by the anchors, faster RTs should have been in evidence in the Transient-Anchors than in the Spread-Anchors condition because, in the latter, T2 never appeared in the region defined by the anchors.
The important point is that, in the Spread-Anchors condition, T2 was presented in a blank region of the screen, yet the RTs were as fast as in the Transient-Anchors condition, in which T2 was presented within an anchor. Clearly, what matters is not where the target is presented relative to the anchors but whether a timely transient (alerting) signal has occurred, regardless of its spatial relationship to the target.
An alternative account needs to be considered and dismissed. It is possible that the onset-transient triggered by the presentation of the anchors caused an expansion of the attentional spotlight from fixation to a broader region encompassing all locations between the central stream and the peripheral anchors. In this case, comparable levels of identification accuracy might be expected in the Transient-Anchors and in the Spread-Anchors conditions because the target would fall within an attended region of the display in both conditions.
Such an account, however, runs afoul of the experimental evidence. The zoom-lens model of attentional deployment postulates that as the size of the attended area is increased, attention is correspondingly diluted, with consequent impairment in performance (e.g., Castiello & Umiltà, 1990; Eriksen & St. James, 1986; Eriksen & Yeh, 1985). Were attention to have been deployed in the form of a disc rather than being confined to the region defined by the anchors, the disc would have covered a larger area in the Spread-Anchors condition than in the Transient-Anchors condition. This means that performance should have been more impaired – RTs should have been slower – in the Spread-Anchors condition than in the Transient-Anchors condition, which was demonstrably not the case (Figure 6B). Thus, the results of Experiment 4 are inconsistent with the hypothesis that attention was deployed as a disc centered on fixation, and bounded by the peripheral anchors.
Experiment 5
A question now arises regarding the relationship between the sustained deployment of attention to the region defined by the anchors, as examined in our earlier work (Jefferies & Di Lollo, 2015), and the transient (alerting) effects studied in the present experiments. This issue was addressed in Experiment 5 by presenting the four anchors continuously throughout each trial (a sustained signal) and brightening them briefly just before the onset of T2 (a transient, alerting signal).
Predictions regarding the effect on performance of such a combined presentation are not entirely straight-forward. On one hand, it is possible that the transient brightening of the four anchors might act as a distractor or a mask to disrupt the endogenous deployment of attention, causing performance to be impaired (Sherrington, 1916). On the other hand, to the extent that the two modes are mediated by independent mechanisms, their concurrent activation might summate, thus enhancing performance in the experimental task.
Methods
Observers
Twelve undergraduate students at Simon Fraser University participated in the experiment for course credit. All were naïve as to the purpose of the experiment and reported normal or corrected-to-normal vision. Observers completed the two conditions in counterbalanced order.
Apparatus, stimuli, and procedures
Experiment 5 comprised two conditions. The Sustained-Anchors condition was the same as the Transient-Anchors condition in Experiment 1, except that the four anchors were presented along with the fixation cross, and remained on the screen until the end of the RSVP stream, thus supporting a sustained, endogenous mode of attentional deployment. The Sustained+Alerting condition was the same as the Sustained-Anchors condition except that, as well as being displayed throughout each trial, the four anchors were brightened (that is, they changed from black to white) for 50 ms, 100 ms before the onset of T2, thus incorporating an alerting component.
Results and discussion
Mean percentages of correct identification of T1 were 91.9%, 92.5% and 90.3% at Lags 1, 3, and 9 in the Sustained-Anchors condition; 85.9%, 91.9%, and 91.5% at Lags 1, 3, and 9 in the Sustained+Alerting condition. The corresponding accuracy scores for T2 were 85.2%, 88.9%, and 88.4% at Lags 1, 3, and 9 in the Sustained-Anchors condition; 85.8%, 85.2%, and 88.0% at Lags 1, 3, and 9 in the Sustained+Alerting condition.
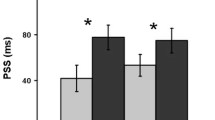
Figure 7 shows the mean of the median RT scores as a function of Lag for the Sustained-Anchors and the Sustained+Alerting conditions. The results were analyzed in a 2 (Condition) × 3 (Lag) repeated-measures ANOVA, which revealed significant effects of Lag, F(2,22) = 16.99, p < .001, ƞp 2 = .607, and Condition, F(1,11) = 5.70, p = .036, ƞp 2 = .341. The interaction effect was not significant, F(2,22) = 1.01, p = .38, ƞp 2 = .084.

Results of Experiment 5. Error bars indicate one standard error.
Adding a transient (alerting) signal to a sustained display of the anchors brought about an enhancement in performance. To wit, RTs in the Sustained+Alerting condition (Figure 7, filled circles) were faster than those in the Sustained-Anchors condition (open circles). This pattern of results is clearly consistent with the idea that sustained and alerting signals trigger processes that are at least partly independent of one another and, as such, summate in their effect on performance (c.f., Berger et al., 2005; Carrasco, 2011).
The sustained/alerting summation evidenced in the present experiment parallels the summation of sustained and transient attentional components hypothesized by Nakayama and Mackeben (1989, Figure 16). This parallel is of interest for at least two reasons. First, it underscores the correspondence between the processes indexed by the terms “transient attention” and “alerting”. Second, Nakayama and Mackeben employed a visual-search paradigm that differed substantially from the paradigm employed in the present work. The finding that the sustained and transient attentional components in Nakayama and Mackeben’s study summated in much the same way as the sustained and alerting components in the present experiment, speaks to the generality of the effect.
General discussion
The main objective of the present study was to determine whether attention can be deployed to a region demarcated by an appropriate structural framework not only when the framework is displayed continuously – as in earlier work – but also when it is displayed transiently. In Experiment 1, RTs to the relevant target were faster when the structural framework was flashed briefly just before target onset. Experiment 2 showed that RTs were also enhanced when task-irrelevant stimuli were flashed beyond the central region of the screen where the target was displayed. Experiment 3 demonstrated that the results of the previous two experiments were mediated by spatially-nonspecific alerting, as distinct from energy summation. Experiment 4 examined the possibility that performance in the two transient conditions in Experiment 3 may have been mediated by different underlying mechanisms. The results strongly suggested that a single mechanism – spatially-nonspecific alerting – mediated performance in all conditions. Finally, Experiment 5 showed that, consistent with the idea of independent mechanisms, sustained and alerting components of attention summate in their effects on performance.
Collectively, the present results strongly suggest that attention cannot be deployed to the region defined by a structural framework, if that framework is displayed transiently. To be sure, the onset transient triggered by the sudden presentation of the framework does enhance the response to the upcoming target. That enhancement, however, is due not to the framework itself but to the alerting effect produced by its onset, witness the fact that the same enhancement is produced by an onset transient triggered by a featureless stimulus (Experiment 3). From a general perspective, then, it can be said that spatial attention can be deployed to a region demarcated by a structural framework when it is deployed endogenously (Berger et al., 2005; Eimer, 1999; Jefferies & Di Lollo, 2015; Juola et al., 1991), but not when it is deployed exogenously, as in the present work.
This is not to say that attention cannot be deployed in response to a transient exogenous stimulus. Indeed, exogenous deployment of attention to a discrete spatial location is well-documented in the literature (see review by Carrasco, 2011), even in the context of the AB paradigm (Ghorashi, Enns, Klein, & Di Lollo, 2010). But that is not the case when the exogenous cue denotes not discrete spatial locations, but a spatial region demarcated by a structural framework. Rather, the present results, combined with the results of earlier investigations, indicate that the deployment of attention to a demarcated spatial region can be done only endogenously.
All the statistical analyses reported above were performed on T2 scores. A question arises whether T1 accuracy was also affected by the trailing anchors. To address this question, we performed five ANOVAs on the T1 accuracy scores in each of Experiments 1–5. Each ANOVA involved two main effects (Anchors, Lag) and one interaction (Anchors × Lag). Any effect of the anchors on T1 performance would be revealed by a significant main effect of Anchors and/or a significant interaction effect. In fact, none of the five ANOVAs revealed any significant effects involving Anchors (all ps>.05). Based on these outcomes, we can conclude that the anchors had no effect on T1 performance.
A procedural point should be noted. There is a close parallel between the present paradigm and the psychological refractory period (PRP) paradigm (e.g., Pashler, 1994; Pashler & Johnston, 1989). Both paradigms employ two sequential targets, the second of which is not masked, and use RT as the dependent measure. The main characteristic of the PRP paradigm is that, to the extent that the two targets engage the same underlying mechanisms, the processing of the second target is delayed until the first target has been processed. The parallels between the two paradigms have been noted by Jolicœur and Dell’Aqua (1998), who regard the AB as a special case of PRP. Whether the present paradigm is regarded as an AB or a PRP paradigm does not change the fundamental conclusion that attention can be deployed to a structural framework when it is displayed in a sustained fashion, but not in a transient fashion.
The possibility needs to be considered that a speed-accuracy trade-off might have been a factor in the present experiments. In Experiments 1–4, RTs in the No-Anchors conditions were reliably slower than RTs in the Transient-Anchors conditions. We attributed this difference to the alerting effect caused by the onset-transient of the anchors. However, it is also possible that this RT difference might have arisen, at least in part, from different strategies employed in the two conditions. Namely, observers might have adopted a strategy that optimised speed to the detriment of accuracy in the Transient-Anchors condition, and the converse strategy in the No-Anchors condition. It is worth noting, however, that observers were explicitly instructed to respond as quickly as possible (i.e., to prioritise speed) in both conditions and in all experiments. There is no obvious reason, therefore, why they should have adopted different strategies in the two conditions. In any case, we can test for a speed-accuracy trade-off by examining T2 accuracy in the No-Anchors and the Transient-Anchors conditions in each of Experiments 1–4. To this end, we performed separate 2 (Lag: 3, 9) × 2 (Condition: No-Anchors, Transient-Anchors) ANOVAs for each experiment. The statistic of interest in each case was the main effect of Condition, as follows: Experiment 1, F(1,13)=3.01, p=.106; Experiment 2, F<1; Experiment 3, F<1; and Experiment 4, F<1. The difference in accuracy between the No-Anchors and the Transient-Anchors conditions in Experiments 1–4, averaged over lag, was <1%, highlighting the similarity between the two conditions. This is not to deny the possibility that some speed-accuracy trade-off might have occurred, but the results obtained in Experiments 1–4 are clearly beyond what can be interpreted wholly on the basis of a speed-accuracy trade-off.
Underlying mechanisms
An essential attribute that any potential mechanism must possess in order to account for the alerting effects illustrated in the present work is the ability to enhance signal processing rapidly and transiently. One promising such candidate has been proposed by Posner and collaborators (e.g., Fernandez-Duque & Posner, 1997; Posner & Raichle, 1994) as the locus cœruleus-norepinephrine (LC-NE) neuromodulatory system whose activation is known to enhance performance for a brief period following a warning signal. Located in the brainstem, the locus cœruleus is regarded as the principal source of norepinephrine in the central nervous system, with widespread links to areas associated with attentional processing (Berridge & Waterhouse, 2003). Two components of LC-NE activity have been identified. Tonic activity: the spontaneous rate of discharge that occurs when the observer is engaged in an attention-demanding task, and phasic activity: a transient rapid boost in firing rate, above tonic baseline level, that occurs upon the presentation of a task-relevant stimulus. These, and other related notions, have been incorporated in the Adaptive Gain Theory of locus cœruleus functioning (Aston-Jones & Cohen, 2005).
In agreement with Posner’s proposals, we suggest that LC-NE phasic activity may provide a mechanism capable of accounting for the alerting effects observed in the present experiments. The temporal course of phasic LC-NE activation satisfies the basic requirements of speed and transiency: activity in monkey LC is known to peak about 100 ms after stimulus onset and to endure for about 100 ms before returning to baseline (Usher, Cohen, Servan-Schreiber, Rajkowski, & Aston-Jones, 1999).
An account of the outcomes of Experiments 1–4 in terms of LC-NE phasic activation can be given as follows. The transient event (e.g., a transient display of 4 anchors or a featureless flash of the background) that was part of the display sequence in each of those experiments, triggered a cycle of LC-NE phasic activity that enhanced the processing of stimuli presented in the ensuing 100 ms or so. In practice, this resulted in faster RTs to T2, which was presented 100 ms after the transient event.
LC-NE functioning can also account for the outcome of Experiment 5, in which the joint presentation of transient and sustained signals resulted in faster RTs than were obtained with transient signals alone. Critical to this account is the finding that tonic and phasic modes of LC activity can take place concurrently, with phasic responses occurring mostly when the level of tonic activity is in the moderate range (Aston-Jones, Rajkowski, & Cohen, 1999). Within that range, tonic and phasic activities summate in their effect on performance. This finding has a corresponding analogue in the present work: when tonic and phasic modes of LC-NE activity are engaged jointly – as was done in Experiment 5 – they lead to faster RTs than when the phasic mode is engaged in isolation.
It should be noted that the LC-NE account outlined above applies to the results of the present experiments but not to those of Jefferies and Di Lollo (2015), Eimer (1999), or Juola et al. (1991). This is because the structural framework in those studies was sustained and, therefore, there was no transient signal to trigger phasic LC-NE activity. If anything, the possibility might be pursued that the deployment of attention to a sustained display of a structural framework might be mediated by LC-NE tonic activity. Specifically, the requirement to attend to the framework might have been associated with a corresponding period of tonic LC-NE activity. This made it possible for attention to be deployed in a sustained fashion to the region demarcated by the framework and thus for attention to be deployed in the form of an annulus. The fundamental distinction, then, is between the phasic mode of LC-NE functioning exemplified in the present work and the tonic mode exemplified in our earlier work and in the work of Eimer (1999) and Juola et al. (1991).
References
Aston-Jones, G., & Cohen, J. D. (2005). An integrative theory of locus coeruleus-norepinephrine function: Adaptive gain and optimal performance. Annual Review of Neuroscience, 28, 403–450.
Aston-Jones, G., Rajkowski, J., & Cohen, J. (1999). Role of locus coeruleus in attention and behavioral flexibility. Biological Psychiatry, 46, 1309–1320.
Bay, M., & Wyble, B. (2014). The benefit of attention is not diminished when distributed over two simultaneous cues. Attention, Perception, & Psychophysics, 1–11.
Berger, A., Henik, A., & Rafal, R. (2005). Competition between endogenous and exogenous orienting of visual attention. Journal of Experimental Psychology: General, 134, 207–211.
Bernstein, I. H., Rose, R., & Ashe, V. (1970). Preparatory state effects in intrasensory facilitation. Psychonomic Science, 19, 113–114.
Berridge, C. W., & Waterhouse, B. D. (2003). The locus coeruleus–noradrenergic system: modulation of behavioral state and state-dependent cognitive processes. Brain Research Reviews, 42, 33–84.
Burr, D. C. (1984). Summation of target and mask metacontrast stimuli. Perception, 13, 183–192.
Carrasco, M. (2011). Visual attention: The past 25 years. Vision Research, 51, 1484–1525.
Castiello, U., & Umiltà, C. (1990). Size of the attentional focus and efficiency of processing. Acta Psychologica, 73, 195–209.
Chun, M. M., & Potter, M. C. (1995). A two-stage model for multiple target detection in rapid serial visual presentation. Journal of Experimental Psychology: Human Perception and Performance, 21, 109–127.
Egeth, H. E., & Yantis, S. (1997). Visual attention: Control, representation, and time course. Annual Review of Psychology, 48, 269–297.
Egly, R., Driver, J., & Rafal, R. D. (1994). Shifting visual attention between objects and locations: Evidence from normal and parietal lesion subjects. Journal of Experimental Psychology: General, 123, 161–177.
Eimer, M. (1999). Attending to quadrants and ring‐shaped regions: ERP effects of visual attention in different spatial selection tasks. Psychophysiology, 36, 491–503.
Eriksen, C. W., & Yeh, Y.-y. (1985). Allocation of attention in the visual field. Journal of Experimental Psychology: Human Perception and Performance, 11, 583–597.
Fernandez-Duque, D., & Posner, M. I. (1997). Relating the mechanisms of orienting and alerting. Neuropsychologia, 35, 477–486.
Ghorashi, S., Enns, J. T., Klein, R. M., & Di Lollo, V. (2010). Spatial selection and target identification are separable processes in visual search. Journal of Vision, 10, 1–12.
Ghorashi, S., Enns, J. T., Spalek, T. M., & Di Lollo, V. (2009). Spatial cuing does not affect the magnitude of the attentional blink. Attention, Perception & Psychophysics, 71, 989–993.
Jefferies, L. N., & Di Lollo, V. (2009). Linear changes in the spatial extent of the focus of attention across time. Journal of Experimental Psychology: Human Perception and Performance, 35, 1020–1031.
Jefferies, L. N., & Di Lollo, V. (2015). When can spatial attention be deployed in the form of an annulus? Attention, Perception & Psychophysics, 77, 413–422.
Jefferies, L. N., Enns, J. T., & Di Lollo, V. (2014). The flexible focus: Whether spatial attention is unitary or divided depends on observer goals. Journal of Experimental Psychology: Human Perception and Performance, 40, 465–470.
Jefferies, L. N., Gmeindl, L., & Yantis, S. (2014). Attending to illusory differences in object size. Attention, Perception & Psychophysics, 76(5), 1393–1402.
Jefferies, L. N., Roggeveen, A. B., Enns, J. T., Bennett, P. J., Sekuler, A. B., & Di Lollo, V. (2015). On the time course of attentional focusing in older adults. Psychological Research, 79, 28–41.
Jolicoeur, P., & Dell’Acqua, R. (1998). The demonstration of short-term consolidation. Cognitive Psychology, 36, 136–202.
Juola, J. F., Bouwhuis, D. G., Cooper, E. E., & Warner, C. B. (1991). Control of attention around the fovea. Journal of Experimental Psychology: Human Perception and Performance, 17, 125.
Lagroix, H. E., Grubert, A., Spalek, T. M., Di Lollo, V., & Eimer, M. (2015). Visual search is postponed during the period of the AB: An event‐related potential study. Psychophysiology, 52, 1031–1038.
McMains, S. A., & Somers, D. C. (2004). Multiple spotlights of attentional selection in human visual cortex. Neuron, 42, 677–686.
Nakayama, K., & Mackeben, M. (1989). Sustained and transient components of focal visual attention. Vision Research, 29, 1631–1647.
Pashler, H. (1994). Dual-task interference in simple tasks: Data and theory. Psychological Bulletin, 116, 220–244.
Pashler, H., & Johnston, J. C. (1989). Chronometric evidence for central postponement in temporally overlapping tasks. Quarterly Journal of Experimental Psychology, 41A, 19–45.
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology, 32, 3–25.
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. Attention and Performance X: Control of Language Processes, 32, 531–556.
Posner, M. I., & Raichle, M. E. (1994). Images of mind. Scientific American Library/Scientific American Books.
Potter, M. C., Chun, M. M., Banks, B. S., & Muckenhoupt, M. (1998). Two attentional deficits in serial target search: The visual attentional blink and an amodal task-switch deficit. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 979–992.
Raymond, J. E., Shapiro, K. L., & Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: An attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 18, 849–860.
Robertson, I. H., Mattingley, J. B., Rorden, C., & Driver, J. (1998). Phasic alerting of neglect patients overcomes their spatial deficit in visual awareness. Nature, 395(6698), 169–172.
Schmidt, R. A., Gielen, S. C., & van den Heuvel, P. J. (1984). The locus of intrasensory facilitation of reaction time. Acta Psychologica, 57, 145–164.
Sherrington, C. (1916). The integrative action of the nervous system. New York: Scribner’s.
Spalek, T. M., & Di Lollo, V. (2011). Alerting enhances target identification but does not affect the magnitude of the attentional blink. Attention, Perception & Psychophysics, 73, 405–419.
Usher, M., Cohen, J. D., Servan-Schreiber, D., Rajkowski, J., & Aston-Jones, G. (1999). The role of locus coeruleus in the regulation of cognitive performance. Science, 283(5401), 549–554.
Visser, T. A. W., Bischof, W. F., & Di Lollo, V. (2004). Rapid serial visual distraction: Task irrelevant items can produce an attentional blink. Perception & Psychophysics, 66, 1418–1432.
Weichselgartner, E., & Sperling, G. (1987). Dynamics of automatic and controlled visual attention. Science, 238(4828), 778–780.
Wyble, B., Potter, M. C., Bowman, H., & Nieuwenstein, M. (2011). Attentional episodes in visual perception. Journal of Experimental Psychology: General, 140, 488–505.
Zuvic, S. M., Visser, T. A., & Di Lollo, V. (2000). Direct estimates of processing delays in the attentional blink. Psychological Research, 63, 192–198.
Acknowledgements
This work was supported by a Sir Walter Murdoch Distinguished Collaborator Award to LNJ, by a Discovery Grant from the Natural Sciences and Engineering Research Council of Canada (NSERC) to VDL, and by a Discovery Accelerator Grant from NSERC to VDL. We thank Tom Spalek for constructive comments on an earlier version of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Jefferies, L.N., Di Lollo, V. Deployment of spatial attention to a structural framework: exogenous (alerting) and endogenous (goal-directed) factors. Atten Percept Psychophys 79, 1933–1944 (2017). https://doi.org/10.3758/s13414-017-1378-6
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-017-1378-6