
Abstract
Peripheral cues reduce reaction times (RTs) to targets at the cued location with short cue-target SOAs (cueing benefits) but increase RTs at long SOAs (cueing costs or inhibition of return). In detection tasks, cueing costs occur at shorter SOAs and are larger compared with identification tasks. To account for effects of task, detection cost theory claims that the integration of cue and target into an object file makes it more difficult to detect the target as a new event, which is the principal task-requirement in detection tasks. The integration of cue and target is expected to increase when cue and target are similar. We provided evidence for detection cost theory in the modified spatial cueing paradigm. Two types of cues (onset, color) were paired with two types of targets (onset, color) in separate blocks of trials. In the identification task, we found cueing benefits with matching (i.e., similar) cue-target pairs (onset-onset, color-color) and no cueing effects with nonmatching cue-target pairs (onset-color, color-onset), which replicates previous work. In the detection task, cueing effects with matching cues were reduced and even turned into cueing costs for onset cues with onset targets, suggesting that cue-target integration made it more difficult to detect targets at the cued location as new events. In contrast, the results for nonmatching cue-target pairs were not affected by task. Furthermore, the pattern of false alarms in the detection task provides a measure of similarity that may explain the size of cueing benefits and costs.
Similar content being viewed by others
Introduction
Many models of visual attention postulate that we cannot consciously perceive all objects at all locations in the visual field at once. Instead, our conscious perception is limited to one (or few) objects or locations at a time. How does the human visual system prioritize one object or location over others to determine the serial order of processing?
Contingent involuntary orienting theory and spatial inhibition
The contingent involuntary orienting theory proposes that the order of processing is determined by one facilitative and one filtering process (Folk & Remington, 1998, 2015; Folk, Remington, & Johnston, 1992). The central idea of the model is that observers establish a top-down control-set for the nonspatial properties of the sought-for target elements (e.g., the target’s stimulus class, color, motion, etc.). With a task-set established, items are prioritized through two attentional processes. First, attention is oriented to only those items (but also all those elements) that match the target properties. This orienting process is spatially specific and facilitates visual processing at the location to which it is oriented. Second, items that do not match the task-set are filtered out. This filtering process is spatially unspecific but delays overall processing time. Despite its simplicity, the model accommodates many empirical observations (for review, see Burnham, 2007). The frequently replicated finding is that peripheral distractors only capture attention when cue and target properties match, whereas nonmatching distractors fail to capture attention.
Folk et al. (1992), for instance, measured attentional orienting in a spatial cueing paradigm with peripheral cues that appeared equally often at the location of the subsequent target (valid cue trials) as at different locations (invalid cue trials). Despite the cues’ spatial irrelevance, onset cues (i.e., a single new item in the display) captured attention in search for onset targets, as indicated by faster RTs on valid than invalid cue trials, which we will refer to as cueing benefits. In contrast, onset cues did not capture attention in search for color singleton targets (i.e., items with a unique color among homogenously colored context elements). Analogously, color cues only captured attention with color, but not with onset targets.
Critically, the contingent orienting theory predicts that cues either result in cueing benefits or the absence of spatially specific effects. However, several studies reported cueing costs (slower RTs on valid than invalid trials) when cue and target properties did not match (Belopolsky, Schreij, & Theeuwes, 2010; Folk & Remington, 2008; Gibson & Amelio, 2000; Carmel and Lamy, 2014, 2015; Theeuwes, Atchley, & Kramer, 2000). According to one account, costs arise because attention is rapidly disengaged from a nonmatching cue and the cue location is subsequently suppressed (Theeuwes, 2010; Theeuwes et al., 2000). An alternative account proposes that costs arise because cue and target are integrated into the same object file, which demands time-consuming object file updating when cue and target have different features (Carmel and Lamy, 2014, 2015).
In summary, the contingent orienting hypothesis assumes a spatial orienting process that results in spatially specific facilitation and a filtering process that results in non-spatial delay of target processing. However, several studies reported that non-matching peripheral distractors resulted in cueing costs. To account for cueing costs, disengagement processes were proposed that result in spatially specific inhibition, or object file updating processes that result in a processing delay on valid trials.
Detection cost theory
Lupiáñez and coworkers (Lupiáñez, 2010; Lupiáñez, Martin-Arevalo, & Chica, 2013) proposed an alternative theory of visual attention. The theory aims to account for exogenous cueing effects in general and inhibition of return (IOR) in particular. The theory assumes two facilitative and one habituation process:
First, it assumes a spatial orienting process, which is exogenously controlled and results in short-lived increase of activation after cue presentation, similarly to other theories of visual attention (Theeuwes, 2010). Two further processes, however, are based on the idea that peripheral cues may activate the same object- or event-representation as the target (for the object file concept see Kahneman & Treisman, 1984; Kahneman, Treisman, & Gibbs, 1992; Treisman, Kahneman, & Burkell, 1983; Wolfe & Bennett, 1997). An object file does not necessarily correspond to a known object but may be an assembly of unrelated shapes that are grouped because of spatiotemporal proximity. For instance, a letter in a rectangle constituted an “object” in Kahneman et al. (1992). In spatial cueing paradigms, cue and target might be integrated in the same object file on valid cue trials, because they occur at the same location at about the same time.
Cue-target integration has different effects on detection and identification processes. First, because detection processes are already activated by the cue, they habituate and a target appearing at the same location elicits less activation (i.e., the target captures attention less), which delays detection of the integrated object file. These detection costs are assumed to be larger with matching than nonmatching cue-target pairs because integration of cue and target into the same object file is assumed to be stronger for similar stimuli (Lupiáñez, 2010, p. 27). That is, it becomes more difficult to detect the target as something different from the cue when the target is similar to the cue. Release from habituation is slow and does not occur in time intervals of up to 1,300 ms where cue-target integration is likely to appear. Therefore, differences between detection and identification tasks are present at all cue-target SOAs (Lupiáñez, 2010, p. 21; Lupiáñez, Milan, Tornay, Madrid, & Tudela, 1997). Second, cue-target integration aids spatial selection of the target location in advance, which facilitates identification of the target. This facilitation is assumed to be larger with matching than nonmatching cues and targets, because feature repetition is assumed to improve processing (similar to feature-priming).
The facilitation or inhibition of responses to peripherally cued targets is determined by the weighted sum of spatial orienting, spatial selection, and detection processes. The weight of each process is determined by task-demands. In detection tasks, the contribution of detection costs increases, predicting that reduced cueing benefits or even costs may be observed. In identification tasks, however, the contribution of spatial selection processes increases, predicting that cueing benefits are more probable. Consistent with the theory, Lupiáñez (2010; also Lupiáñez et al., 2013) showed in a number of studies that cueing benefits were reduced (or even turned into cueing costs) in detection compared with identification tasks, at all cue-target SOAs.
In sum, the detection cost theory proposes that smaller cueing benefits (or even cueing costs) arise when detection costs reduce (or even outweigh) facilitation by spatial orienting and spatial selection processes. Notably, these detection costs arise because detection processes habituate on valid trials, not because of inhibitory processes.
Present study
We examined contingent attentional capture under different task demands. Onset or color singleton cues were presented in combination with onset or color singleton targets. We are not aware of any study that has used tasks other than identification in the modified spatial cueing paradigm (Becker, Folk, & Remington, 2013; Belopolsky, et al., 2010; Carmel & Lamy, 2015; Folk, 2013; Folk et al., 1992; Lien, Ruthruff, Goodin, & Remington, 2008).
In the identification task (Experiment 1), participants had to indicate the target shape (X vs. =) by pressing one of two keys. In the detection task (Experiment 2), participants pressed a single key to indicate target presence. Onset or color singleton cues were presented in combination with onset or color singleton targets.
The contingent orienting theory predicts cueing benefits when cue and target properties match and the absence of effects when they do not match. Similarly, detection cost theory predicts that facilitation through spatial selection is larger with matching than nonmatching cue-target pairs. However, detection cost theory does not predict the absence of cueing benefits with non-matching cues. If the weight assigned to spatial orienting is large enough to compensate for the smaller spatial selection benefit, cueing benefits may result. In general, the absolute size of the cueing effects varies depending on the weight assigned to spatial orienting. Thus, the predictions of detection cost theory concerning the absolute size of cueing effects with nonmatching cue-target pairs are vague and we therefore do not test detection cost against contingent orienting theory. Rather, we focus on contributions of task demands that have not been considered in contingent orienting theory but are constituent parts of detection cost theory. Somewhat trivially, detection processes are assumed to be more prominent in detection tasks than in identification tasks. Therefore, detection costs with matching cues are expected to contribute to a larger degree in detection tasks than in identification tasks. In other words, the cueing benefit that is typically observed with matching cues should be reduced (or even negative) in detection compared to identification tasks.
Experiments 1 and 2
Method
Participants
In all experiments reported, undergraduate students at the University of Geneva participated to fulfill a course requirement. All participants reported visual acuity within normal limits and normal color vision. Eighteen students participated in Experiment 1 and 37 in Experiment 2. The final sample sizes are given in Table 1. All procedures were approved by the ethics committee of the “Faculté de Psychologie et des Sciences de l’Education” at the University of Geneva and were in accordance with the 1964 Declaration of Helsinki. Before the experiment, participants gave their written, informed consent.
Apparatus
The experiment took place in a dimly lit room. Stimuli were displayed on a 21-inch cathode ray tube monitor with a refresh rate of 85 Hz and a resolution of 1,280 x 1,024 pixels. The background was black. Participants placed their head on a chin and forehead rest at a viewing distance of 65 cm. Participants pressed the left or right button of a RB-530 response box (Cedrus, San Pedro, CA). The response box had four buttons arranged in a cross and one button in the center. The center-to-center distance between the four buttons was 6 cm.
Stimuli
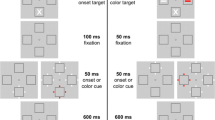
A single trial consisted of the sequential presentation of three types of displays: fixation display, cue display, and target display (Fig. 1). The fixation display consisted of a fixation cross, positioned in the center of the screen, and four circles, which served as placeholders for the target or distracters. The placeholders had a diameter of 1.2° and were placed at a distance of 5° above, below, left, or right to the fixation cross. All stimuli (placeholders, cues, targets) had a luminance of 24 cd/m2. In the onset cue condition, the cue display consisted of the fixation display and an additional set of four smaller circles, positioned left, right, above, and below one of the placeholder at a distance of 0.9°. The small circles had a diameter of 0.3° and were white. In the color cue condition, a set of four small circles was positioned around each of the four placeholders. One of the four sets was red and the remaining three sets were white. In the onset target condition, the target display consisted of the fixation display and a white target object inside one of the four placeholders. The target object was either the symbol = or X with a line length of 0.6°. In the color target condition, an = or X was presented inside each of the four placeholders. One of these four objects, the target, was red, whereas the remaining three objects were white.

A variant of the modified spatial cueing paradigm by Folk et al. (1992), which was used in the present study. The center of the placeholders was at 5° from fixation. Stimuli are drawn to scale. The background color was black
A trial started with the presentation of the fixation display for 700 ms. The fixation cross then blinked off for 100 ms to signal the beginning of a new trial. Then, the fixation display was presented for a randomly chosen time period ranging from 600 to 1,000 ms. Next, the cue display appeared for 47 ms. After an interstimulus interval of 94 ms, the target was presented for 47 ms and subsequently replaced by the fixation display.
On target absent trials in the detection task, the target display was replaced by the fixation display in blocks with onset targets. In blocks with color targets, only white shapes (X or =) were shown in the placeholder circles.
Design
There were eight experimental conditions resulting from crossing cue type (onset cue, color cue), cue validity (valid, invalid), and target type (onset target, color target). The four conditions resulting from crossing cue and target type were blocked, whereas the 32 conditions resulting from crossing cue position, target position, and target identity varied randomly from trial to trial. A cue was valid when it was presented on the same position as the target, which occurred in 25% of trials. The order of the four blocks was balanced across participants according to a Latin square. Each block was composed of 16 practice trials, followed by 3 sets of 32 trials for a total of 384 trials.
Procedure
Before data collection, participants worked through approximately ten practice trials for each of the four blocks. At the beginning of each of the four blocks, written instructions were presented on the screen. Participants were asked to keep fixation on the fixation cross and to respond as rapidly as possible without making too many errors. Furthermore, they were informed that the target would appear in only 25% of trials at the cued position. Therefore, they should ignore the cue. Also, the upcoming target type was shown. Participants were encouraged to rest between blocks. If a response was wrong, too early (RT shorter than 100 ms) or late acoustic error feedback and a text message with the error type were presented.
Tasks
In Experiment 1, participants were instructed to press the right button to = and the left button to X. Finger placement on the four buttons was at participants’ discretion. In Experiment 2, participants were asked to indicate the presence of a target as rapidly as possible and to withhold the response if it was absent. Participants responded by pressing a single button of the response box. They were free to choose the left or right response button according to their handedness, but participants were asked to not change their initial choice of hand position. In each block of the detection task, 32 catch trials without target were added (20% of all trials) for a total of 512 trials. Two different time-out criteria were used in two groups of participants (0.6 and 1 s). In Experiment 1, the timeout criterion was 0.8 s.
Results
We excluded participants with RTs or error rates that were 2.5 standard deviations above the sample mean. One participant in Experiment 2 with 1 s timeout criterion was removed because of long RTs (565 ms vs. 379 ms) and another because of high false-alarm rate (23% vs. 8%).
For each condition and participant, we excluded trials with reaction times that were 2.5 standard deviations longer than the respective condition mean. The mean proportion of choice errors, anticipations, late trials, and outliers is summarized in Table 1. We performed a 2 (target type: onset, color) x 2 (cue type: onset, color) x 2 (cue validity: valid, invalid) repeated-measures ANOVAs on mean RTs and proportion of choice errors.
We will first analyze the RTs and errors of the two tasks separately. Evidence for contingent capture is a three-way interaction of target type, cue type, and cue validity, indicating that an advantage of valid cues only occurred with matching cue types. After the analysis of individual experiments, we will present analyses where we focus on the differences between experiments for each combination of cue type and target type. Mean RTs for the two experiments are shown in Fig. 2, and mean differences between invalid and valid trials (cueing effects) for RTs and error percentages are shown in Fig. 3. For ease of exposition, we refer to the different combinations of cue type and target type by mentioning first the cue and then the target type (i.e., onset-onset condition for onset cue with onset target).

Mean reaction times (RT) for the experiment with identification and detection tasks as a function of target type, cue type, and cue validity (v = valid, iv = invalid). An asterisk near a line marks a significant cue validity effect. Error bars indicate the between-subjects standard error. If not visible, error bars are smaller than the respective symbol

Mean differences between invalid and valid conditions as a function of experiment and cue-target combination for reaction times and proportion error (C. = Cue, T. = Target). For the identification task, the proportion of errors refers to the difference between choice errors in invalid and valid trials. For the detection task, the percentage of errors refers to the false alarms in target absent trials (i.e., valid/invalid does not apply). Asterisks mark mean differences that are different from zero after Bonferroni correction at p = 0.0125 to correct for four comparisons per experiment. No t tests against zero were carried out for false-alarm rates, because they do not represent differences. Error bars show the standard error of the mean
Experiment 1: Identification
The ANOVA on RTs showed longer RTs with color than with onset targets (531 vs. 509 ms), F(1,17) = 11.95, p = 0.003, ηp 2 = 0.413, and with invalid than valid cues (523 vs. 516 ms), F(1,17) = 77.2, p < 0.001, ηp 2 = 0.82. The effect of cue validity was larger with color (536 vs. 526 ms) than with onset targets (511 vs. 506 ms), F(1,17) = 12.09, p = 0.003, ηp 2 = 0.416. Importantly, the effect of cue validity was modulated by the combination of cue and target type, F(1,17) = 51.5, p < 0.001, ηp 2 = 0.752. Separate t tests with a Bonferroni-adjusted critical p value of 0.0125 for four tests showed cueing benefits in the onset-onset (25 ms), t(17) = 3.38, p = 0.004, and color-color conditions (63 ms), t(17) = 8.44, p < 0.001. With nonmatching cue-target combinations, there was a tendency for cueing costs in the color-onset (−14 ms), t(17) = 1.99, p = 0.063, and no difference in the onset-color condition (5 ms) = t(17) = 1.13, p = 0.274. Overall, Experiment 1 replicates contingent attentional capture where cueing benefits occur with matching but not with nonmatching cues.
The ANOVA on the percentages of choice errors showed that more choice errors occurred with color targets than with onset targets (4.3% vs. 2.8%), F(1,17) = 6.25, p = 0.023, ηp 2 = 0.269. There was a tendency for more errors with invalid than valid cues (4.1% vs. 2.9%), F(1,17) = 4.20, p = 0.056, ηp 2 = 0.198. The interaction of target type and cue validity, F(1,17) = 9.19, p = 0.008, ηp 2 = 0.351, showed that the effect of cue validity was larger with color (5.2% vs. 2.2%) than with onset targets (3% vs. 3.6%). The three-way interaction of target type, cue type, and cue validity was significant, F(1,17) = 16.51, p = 0.001, ηp 2 = 0.493. Separate t-tests showed that cueing benefits occurred in the color-color condition (7.1% vs. 1.6%), t(17) = 3.89, p = 0.001.
Experiment 2: Detection
The experiment was run with two different timeout criteria. Eighteen participants had to respond within 0.6 s and 17 participants within 1 s. We included timeout criterion as between-subjects factor in the ANOVA. Surprisingly, there was no effect of timeout criteria on RTs, F(1,33) = 0.83, p = 0.369, ηp 2 = 0.025, and it was only involved in one minor interaction. RTs tended to be longer with color than onset cues (376 vs. 370 ms), F(1,33) = 2.89, p = 0.099, ηp 2 = 0.08. RTs were significantly longer with color than onset targets (385 vs. 360 ms), F(1,33) = 24.87, p < 0.001, ηp 2 = 0.43, but more so with a 1 s (397 vs. 362 ms) than with a 0.6 s (374 vs. 359 ms) timeout criterion, F(1,33) = 4.14, p = 0.05, ηp 2 = 0.112. Furthermore, the interaction of cue and target type, F(1,33) = 16.93, p < 0.001, ηp 2 = 0.339, the interaction of cue type and cue validity, F(1,33) = 76.23, p < 0.001, ηp 2 = 0.698, and the interaction of target type and cue validity, F(1,33) = 6.96, p = 0.013, ηp 2 = 0.174, reached significance. Importantly, all of the above effects were modulated by a three-way interaction, F(1,33) = 14.78, p = 0.001, ηp 2 = 0.309, that was not modulated by timeout criterion, p = 0.421. Separate t-tests found cueing costs in the onset-onset condition (−14 ms), t(34) = 2.71, p = 0.01, which is a novel finding. We found cueing costs in the color-onset condition (-22 ms), t(34) = 5.22, p < 0.001, and Fig. 2 reveals that a similar trend was already present in Experiment 1. We also confirmed cueing benefits in the color-color condition (28 ms), t(34) = 5.79, p < 0.001, and their absence in the onset-color condition (−3 ms), p = 0.286.
Further, we entered the false alarm rates into a 2 (timeout criterion: 0.6, 1 s) x 2 (target type: onset, color) x 2 (cue type: onset, color) ANOVA. False-alarm rates were higher with the short than with the long timeout criterion (15.1% vs. 8%), F(1,33) = 8.5, p = 0.006, ηp 2 = 0.205, with color targets than with onset targets (14% vs. 9%), F(1,33) = 20.52, p < 0.00, ηp 2 = 0.383, and with color cues than with onset cues (16.8% vs. 6.3%), F(1,33) = 29.86, p < 0.001, ηp 2 = 0.475. The interaction of cue type and timeout criterion, F(1,33) = 4.84, p = 0.035, ηp 2 = 0.128, showed that the effect of cue type was larger with the short (22.5% vs. 7.5%) than the long (11.1% vs. 4.9%) timeout criterion. Importantly, the interaction of cue type and target type was significant, F(1,33) = 44.74, p < 0.001, ηp 2 = 0.575, and not further modulated by timeout criterion, p = 0.105, ηp 2 = 0.078. Separate t tests for the nonmatching cue-target pairs showed that the false-alarm rate was higher in the color-onset than in the onset-color condition (9.6% vs. 3.9%), t(34) = 3.52, p = 0.686. More important for our present purpose, t tests on matching cue-target pairs showed that the false alarm rate in the color-color condition was higher than in the onset-onset condition (24.4% vs. 8.8%), t(34) = 5.51, p < 0.001.
Between-experiment analyses
Our main interest was a comparison between the two tasks. We first collapsed across the two time-out criteria in Experiment 2, because the pattern of contingent capture did not differ. Then, we performed a 2 (task: identification, detection) x 2 (target type: onset, color) x 2 (cue type: onset, color) x 2 (cue validity: valid, invalid) mixed-factors ANOVAs on mean RTs. Only two of the many results were of interest. First, there was a main effect of experiment, F(1,51) = 137.55, p < 0.001, ηp 2 = 0.73, showing that RTs were longer with identification (520 ms) than with detection (373 ms), reflecting the different task demands. Second, there was a four-way interaction of experiment, cue type, target type, and cue validity, F(1,51) = 10.73, p < 0.001, ηp 2 = 0.174, showing that the pattern of cueing effects differed across experiments.
To follow-up on the four-way interaction, we compared cueing effects between identification and detection tasks for each cue-target pair. In the onset-onset and in the color-color condition (i.e., matching cue-target pairs), cueing effects were larger with identification than with detection (onset-onset: 25 vs. −14 ms, t(51) = 4.38, p < 0.001; color-color: 63 vs. 28 ms, t(51) = 4.02, p < 0.001). In the color-onset and in the onset-color condition (i.e., nonmatching cue-target pairs), the cueing effect did not differ between identification and detection tasks (color-onset: −14 vs. −22 ms, p = 0.335; onset-color: 5 vs. −3 ms, p = 0.12). Thus, cueing benefits were reduced with matching cues in the detection compared with the identification task. In contrast, cueing effects with non-matching cues did not differ between tasks.
To evaluate whether the reduction of the cueing effect with detection was the same for the two matching cue-target pairs, we ran a 2 (task: identification, detection) x 2 (cue-target pair: onset-onset, color-color) mixed-factors ANOVAs. There was an effect of task, F(1,51) = 32.13, p < 0.001, ηp 2 = 0.387, confirming a cueing effect that was 37 smaller in the detection than in the identification task (7 vs. 44 ms). The effect of cue-target pair, F(1,51) = 47.47, p < 0.001, ηp 2 = 0.482, showed that the cueing effect was smaller in the onset-onset than in the color-color condition (5 vs. 46 ms). The interaction was not significant, p = 0.781, suggesting that the effect of task was of the same magnitude for the two matching cue-target pairs. Also, we note that cueing effect in the color-color condition was larger than in the onset-onset condition.
Discussion
We examined cueing effects in the contingent capture paradigm with identification and detection tasks. In the identification task, we replicated the typical cueing benefits when the cue type matched the target type and the absence of cueing effects when cue and target type did not match. The main result of the present study concerned the detection task. In the detection task, cueing benefits were obtained in the color-color condition, as in the identification task, but a significant cueing cost resulted in the onset-onset condition. Critically, we observed an overall reduction of the cueing effects for matching cue-target pairs with detection compared to identification, which is consistent with detection cost theory. The main point is not so much the occurrence of cueing costs but the reduction of the cueing benefit. The reduction with detection compared to identification was of similar size (approximately 37 ms) for the onset-onset and the color-color condition, but it resulted in cueing costs with onset-onset cues because the cueing benefit was smaller to begin with (25 vs. 63 ms for onset-onset vs. color-color in Experiment 1). In contrast, cueing effects were not affected by task with non-matching cue-target pairs.
Detection costs in the contingent capture paradigm
Our results support accounts referring to object file theory (Kahneman & Treisman, 1984; Kahneman et al., 1992; Treisman et al., 1983; Wolfe & Bennett, 1997). Lupiáñez and colleagues (Lupiáñez, 2010; Lupiáñez et al., 2013) explained the earlier onset and larger magnitude of IOR in detection compared to identification tasks with costs produced during detection processes. When a cue appears at the target location, it is more difficult to detect the target as a new event than when it appears at a different location. Because detection tasks increase the contribution of detection costs, the facilitative effect of the other processes may be reduced or outweighed. Identification tasks, in contrast, promote the contribution of spatial selection processes, with the result that their facilitative effect reduces or outweighs the impact of detection costs. Similar to previous findings in the literature on IOR, the present experiments revealed a reduction of cueing effects in detection tasks with onset cues and onset targets. Additionally, we observed that the reduction was limited to matching cue-target pairs. These findings are compatible with detection cost theory, which states that the stronger integration of cue and target into the same object with similar cue-target pairs increases the difficulty to detect the target as a new event.
Relation to previous studies
Previous work provided evidence for detection cost theory using non-spatial attributes such as color and shape (Hu, Fan, Samuel, & He, 2013; Hu & Samuel, 2011; Hu et al., 2011). In particular, it was demonstrated that cueing costs arose at late cue-target SOAs when the target color repeated the cue color. Detection costs were confined to conditions where the target appeared at the cued location (Hu et al., 2011). Generally, detection costs for the repetition of non-spatial features are consistent with the reduction in cueing benefits for matching cue-target pairs that we observed because a matching target in our paradigm repeats the non-spatial feature of the cue (color or onset).
However, there are also inconsistencies. First, the effect of color repetition in Hu et al. (2011) only emerged after an SOA of 700 ms, whereas we used an SOA of 141 ms. Possibly, the larger complexity of Hu et al.’s (2011) displays is responsible for the later occurrence. Also, we used a between-subject design to compare different tasks and avoid contamination by carry-over effects, whereas Hu et al. manipulated the SOA in the same tasks. Thus, differences in stimuli and design may explain the time when detection costs are observed. Second, Hu and Samuel (2011) showed that cueing benefits with color repetition in an identification task occurred at cued and uncued locations. However, cueing benefits for matching cues are spatially confined in the modified spatial cueing paradigm, that is, there is no general reduction for all locations when the cue color matches the target color (Folk & Remington, 1998). The difference may be explained by the different task requirements: Hu and Samuel (2011) asked observers to discriminate the target color and found that this was easier when a similar color preceded the target display. In contrast, participants do not report the color in the modified spatial cueing paradigm but discriminate the target’s shape.
Furthermore, one may wonder how cue-target SOA affects the difference between detection and identification tasks in the modified spatial cueing paradigm. For onset cues with onset targets, there is already a large literature showing that IOR occurs with shorter SOAs in detection than identification tasks and that cueing effects are more negative (Lupiáñez, 2010). In the color-color condition, it has been shown that IOR is absent at long cue-target SOAs in identification or saccadic tasks (Ansorge, Priess, & Kerzel, 2013; Gibson & Amelio, 2000). Less is known about the difference between identification and detection tasks in the color-color condition at long SOAs. Future research should clarify whether detection tasks would result in IOR at long SOAs in this condition.
False alarms, confusability, and similarity
In target-absent trials of the detection task, false alarm rate varied as a function of cue-target combination. Interestingly, there is some correspondence between the false alarm rates and the size of the cueing effects. False alarm rates were lower in the onset-onset condition than in the color-color condition and the cueing benefits also were smaller (Fig. 3). False alarms in the present paradigm arise when observers mistake the cue event for the target event (or in other words, when cue and target are integrated into the same object or event file). Therefore, the confusability between cue and target was higher in the color-color than in the onset-onset condition. Most probably, the larger confusion arose from the larger similarity. Thus, larger similarity between cue and target, as measured by false alarm rates, may result in larger cueing effects. Effects of similarity in the modified cueing paradigm are well-investigated (Anderson & Folk, 2012; Ansorge & Heumann, 2003; Becker et al., 2013) and support the conclusion that cueing benefits are larger with more similar cues. The new insight from the current detection task is that it offers a behavioral measure of similarity where physical measures are absent. In fact, it is difficult to compare the similarity of onset-onset events with color-color events. Therefore, previous research has mostly focused on single perceptual dimensions, where a physical description of similarity in color space or distance (for location) is possible. In contrast, the false alarm measure suggests that cue-target similarity was larger in the color-color than in the onset-onset condition, which perhaps accounts for the larger cueing effects.
Cueing costs in the color-onset condition
In the color-onset condition of the detection task, we observed faster RTs when the target was not presented at the cued location (cueing costs). In the other nonmatching cue-target combination (onset-color condition), no cueing effect was observed. Three different accounts of cueing costs with nonmatching cues will be discussed.
First, the context-selection hypothesis assumes that the context elements in the cue display were selected in the onset-color condition because they partly matched the target. That is, participants selected the small white circles in the color cue display when they were looking for the single white onset target because cue context and target had the same color (white). This explanation predicts faster RTs on invalid than valid trials (i.e., cueing costs), as observed. Selection of context elements did not occur in the onset-color condition because there were no context elements in the onset cue display. Consistent with this explanation, false alarm rates were higher in the color-onset condition than in the onset-color condition, suggesting that the similarity between cue context and target was higher. In line with the context-selection hypothesis, other studies also reported cueing costs when contextual cues and targets had the same color (Harris, Remington, & Becker, 2013; Lien, Ruthruff, & Cornett, 2010; Schönhammer, Grubert, Kerzel, & Becker, 2016).
Second, the disengagement hypothesis can account for the cueing costs in the color-onset condition by assuming that the color cues caused attentional capture, rapid disengagement, and spatially specific inhibition at the time the target appeared. The disengagement hypothesis is part of the salience-driven attentional capture theory, according to which onset cues in the onset-color condition should have also captured attention (Theeuwes, 2010; Theeuwes et al., 2000). The fact that these cues elicited zero cueing effects instead of cueing costs can be accounted for by different speeds of disengagement. Onset cues might have captured attention more than the color cues because onsets are more salient than other types of singletons (Belopolsky et al., 2010; Folk & Remington, 2015; Lamy & Egeth, 2003; White, Lunau, & Carrasco, 2014). Hence, disengagement might have been slower, and suppression had not yet been present when the color targets appeared.
Third, the updating hypothesis proposes that cueing costs arise when non-matching cues and targets are integrated into the same object file, affording time-consuming updating processes (Carmel and Lamy, 2014, 2015). The updating hypothesis starts from the assumption that a cue creates an object file when it is consciously perceived. When the subsequent target is presented at the same location, an update of the object file is necessary if cue and target properties do not match. As a consequence, nonmatching valid cues result in longer RTs than nonmatching invalid cues. However, when a cue captures attention, such as with matching cues, it facilitates processing at the cued location, which may cancel or outweigh the object-updating cost. To account for the occurrence of cueing costs in the color-onset and the absence of cueing effects in the onset-color condition, the updating hypothesis may claim that updating costs occurred in both conditions, but that attentional capture occurred only with onset cues. That way, the cueing costs were cancelled in the onset-color condition, resulting in zero cueing effect, whereas cueing costs persisted in the color-onset condition. As mentioned earlier, larger attentional capture by onset cues may result from their larger saliency (Folk & Remington, 2015; Lamy & Egeth, 2003; White, Lunau, & Carrasco, 2014).
Summary
While our experiments were not designed to test the context-selection, disengagement, and updating hypothesis directly, it is interesting to note that object-file theory may provide a unified account of Carmel and Lamy’s (2014, 2015) and our findings. While Carmel and Lamy’s data show that the disruption of object file integration by a nonmatching cue at the target location incurs a cost for selection processes, our data show that the integration of the matching cue into an object file at the target location incurs a cost for detection processes (Lupiáñez, 2010; Lupiáñez et al., 2013). Thus, there is evidence that both object file updating and object file integration may have detrimental effects on RTs depending on the attentional process (selection or detection) that is concerned. With respect to the contingent orienting hypothesis, these results show that behavior in the contingent capture paradigm is not only governed by spatial orienting and filtering but also by processes related to object-file integration or updating. However, these processes should be considered as operating simultaneously to spatial orienting and filtering so that evidence for object-filed theory does not compromise contingent orienting theory.
In summary, the current study shows that detection of a novel target event may be difficult when it appears at the cued location, which may cause detection costs. While detection costs may be small in the typical identification tasks, detection tasks highlight the difficulty of detecting target events, in particular when cue and target features match.
References
Anderson, B. A., & Folk, C. L. (2012). Dissociating location-specific inhibition and attention shifts: Evidence against the disengagement account of contingent capture. Attention, Perception, & Psychophysics, 74(6), 1183–1198. doi:10.3758/s13414-012-0325-9
Ansorge, U., & Heumann, M. (2003). Top-down contingencies in peripheral cuing: The roles of color and location. Journal of Experimental Psychology. Human Perception and Performance, 29(5), 937–948. doi:10.1037/0096-1523.29.5.937
Ansorge, U., Priess, H. W., & Kerzel, D. (2013). Effects of relevant and irrelevant color singletons on inhibition of return and attentional capture. Attention, Perception, & Psychophysics, 75(8), 1687–1702. doi:10.3758/s13414-013-0521-2
Becker, S. I., Folk, C. L., & Remington, R. W. (2013). Attentional Capture Does Not Depend on Feature Similarity, but on Target-Nontarget Relations. Psychological Science, 24(5), 634–647. doi:10.1177/0956797612458528
Belopolsky, A. V., Schreij, D., & Theeuwes, J. (2010). What is top-down about contingent capture? Attention, Perception, & Psychophysics, 72(2), 326–341. doi:10.3758/app.72.2.326
Burnham, B. R. (2007). Displaywide visual features associated with a search display's appearance can mediate attentional capture. Psychonomic Bulletin & Review, 14(3), 392–422.
Carmel, T., & Lamy, D. (2014). The Same-Location Cost Is Unrelated to Attentional Settings: An Object-Updating Account. Journal of Experimental Psychology. Human Perception and Performance, 40(4), 1465–1478. doi:10.1037/a0036383
Carmel, T., & Lamy, D. (2015). Towards a resolution of the attentional-capture debate. Journal of Experimental Psychology. Human Perception and Performance, 41(6), 1772–1782. doi:10.1037/xhp0000118
Folk, C. L. (2013). Dissociating Compatibility Effects and Distractor Costs in the Additional Singleton Paradigm. Frontiers in Psychology, 4. doi:10.3389/fpsyg.2013.00434
Folk, C. L., & Remington, R. W. (1998). Selectivity in distraction by irrelevant featural singletons: Evidence for two forms of attentional capture. Journal of Experimental Psychology. Human Perception and Performance, 24(3), 847–858. doi:10.1037/0096-1523.24.3.847
Folk, C. L., & Remington, R. W. (2008). Bottom-up priming of top-down attentional control settings. Visual Cognition, 16(2-3), 215–231. doi:10.1080/13506280701458804
Folk, C. L., & Remington, R. W. (2015). Unexpected Abrupt Onsets Can Override a Top-Down Set for Color. Journal of Experimental Psychology-Human Perception and Performance, 41(4), 1153–1165. doi:10.1037/xhp0000084
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology. Human Perception and Performance, 18(4), 1030–1044.
Gibson, B. S., & Amelio, J. (2000). Inhibition of return and attentional control settings. Perception & Psychophysics, 62(3), 496–504.
Harris, A. M., Remington, R. W., & Becker, S. I. (2013). Feature specificity in attentional capture by size and color. Journal of Vision, 13(3), 1–15. doi:10.1167/13.3.12
Hu, F. K., & Samuel, A. G. (2011). Facilitation versus inhibition in non-spatial attribute discrimination tasks. Attention, Perception, & Psychophysics, 73(3), 784–796. doi:10.3758/s13414-010-0061-y
Hu, F. K., Samuel, A. G., & Chan, A. S. (2011). Eliminating Inhibition of Return by Changing Salient Nonspatial Attributes in a Complex Environment. Journal of Experimental Psychology-General, 140(1), 35–50. doi:10.1037/a0021091
Hu, F. K., Fan, Z., Samuel, A. G., & He, S. (2013). Effects of display complexity on location and feature inhibition. Attention, Perception, & Psychophysics, 75(8), 1619–1632. doi:10.3758/s13414-013-0509-y
Kahneman, D., & Treisman, A. (1984). Changing views of attention and automaticity. New York: Academic Press.
Kahneman, D., Treisman, A., & Gibbs, B. J. (1992). The reviewing of object files: Object-specific integration of information. Cognitive Psychology, 24(2), 175–219.
Lamy, D., & Egeth, H. E. (2003). Attentional capture in singleton-detection and feature-search modes. Journal of Experimental Psychology-Human Perception and Performance, 29(5), 1003–1020. doi:10.1037/0096-1523.29.5.1003
Lien, M.-C., Ruthruff, E., Goodin, Z., & Remington, R. W. (2008). Contingent Attentional Capture by Top-Down Control Settings: Converging Evidence From Event-Related Potentials. Journal of Experimental Psychology. Human Perception and Performance, 34(3), 509–530. doi:10.1037/0096-1523.34.3.509
Lien, M. C., Ruthruff, E., & Cornett, L. (2010). Attentional capture by singletons is contingent on top-down control settings: Evidence from electrophysiological measures. Visual Cognition, 18(5), 682–727. doi:10.1080/13506280903000040
Lupiáñez, J. (2010). Inhibition of Return. In A. C. Nobre & J. T. Coull (Eds.), Attention and Time. Oxford, UK: Oxford University Press.
Lupianez, J., Milan, E. G., Tornay, F. J., Madrid, E., & Tudela, P. (1997). Does IOR occur in discrimination tasks? Yes, it does, but later. Perception & Psychophysics, 59(8), 1241–1254. doi:10.3758/Bf03214211
Lupiáñez, J., Martin-Arevalo, E., & Chica, A. B. (2013). Is Inhibition of Return due to attentional disengagement or to a detection cost? The Detection Cost Theory of IOR. Psicológica, 34(2), 221–252.
Schönhammer, J. G., Grubert, A., Kerzel, D., & Becker, S. I. (2016) Attentional guidance by relative features: behavioral and electrophysiological evidence. Psychophysiology, 53(7), 1074–1083.
Theeuwes, J. (2010). Top-down and bottom-up control of visual selection. Acta Psychologica, 135(2), 77–99. doi:10.1016/j.actpsy.2010.02.006
Theeuwes, J., Atchley, P., & Kramer, A. F. (2000). On the time course of top-down and bottom-up control of visual attention. In S. Monsell & J. Driver (Eds.), Attention and performance XVIII: Control of cognitive performance (pp. 105–124). Cambridge, MA: MIT Press.
Treisman, A., Kahneman, D., & Burkell, J. (1983). Perceptual objects and the cost of filtering. Perception & Psychophysics, 33(6), 527–532.
White, A. L., Lunau, R., & Carrasco, M. (2014). The Attentional Effects of Single Cues and Color Singletons on Visual Sensitivity. Journal of Experimental Psychology-Human Perception and Performance, 40(2), 639–652. doi:10.1037/A0033775
Wolfe, J. M., & Bennett, S. C. (1997). Preattentive object files: Shapeless bundles of basic features. Vision Research, 37(1), 25–43.
Acknowledgments
The authors were supported by the Swiss National Foundation (PDFMP1_129459 and 100014_162750/1).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Schönhammer, J.G., Kerzel, D. Detection costs and contingent attentional capture. Atten Percept Psychophys 79, 429–437 (2017). https://doi.org/10.3758/s13414-016-1248-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1248-7