
Abstract
Stimuli associated with monetary reward can become powerful cues that effectively capture visual attention. We examined whether such value-driven attentional capture can be induced with monetary feedback in the absence of an expected cash payout. To this end, we implemented images of U.S. dollar bills as reward feedback. Participants knew in advance that they would not receive any money based on their performance. Our reward stimuli—$5 and $20 bill images—were thus dissociated from any practical utility. Strikingly, we observed a reliable attentional capture effect for the mere images of bills. Moreover, this finding generalized to Monopoly money. In two control experiments, we found no evidence in favor of nominal or symbolic monetary value. Hence, we claim that bill images are special monetary representations, such that there are strong associations between the defining visual features of bills and reward, probably due to a lifelong learning history. Together, we show that the motivation to earn cash plays a minor role when it comes to monetary rewards, while bill-defining visual features seem to be sufficient. These findings have the potential to influence human factor applications, such as gamification, and can be extended to novel value systems, such as the electronic cash Bitcoin being developed for use in mobile banking. Finally, our procedure represents a proof of concept on how images of money can be used to conserve expenditures in the experimental context.
Similar content being viewed by others

The environment is abundant with rich information. Ideally, the visual system would faithfully represent all this information; however, cognitive processes are bounded by resource limitations. Consequently, only a privileged few sensory representations are selected for downstream processing. In vision, this bottleneck process is called visual selective attention (Desimone & Duncan, 1995). Visual attention spans several layers of the visual hierarchy, from the lateral geniculate nucleus (McAlonan, Cavanaugh, & Wurtz, 2008; O’Connor, Fukui, Pinsk, & Kastner, 2002) to the visual cortex (Luck, Chelazzi, Hillyard, & Desimone, 1997; Reynolds, Chelazzi, & Desimone, 1999). Visual attention pathways share mutual connectivity with reward areas (Serences, 2008), and endogenous reward signals modulate attentional processes in feedback loops (Stănişor, van der Togt, Pennartz, & Roelfsema, 2013). Learned visual cues evoke dopaminergic responses that are indistinguishable from primitive rewards, such as food and water (Bromberg-Martin & Hikosaka, 2009; Lauwereyns et al., 2002). For this reason, some cues are often sought and by virtue produce “wanting” behaviors. Such a cue is said to have incentive salience—a term that reflects the motivational and perceptual properties of a cue (Robinson & Berridge, 2008).
Rewarded attention
Rewards and reward-predictive cues become salient and potentiate behavior. Reward effects have been observed in overt attention (e.g., saccadic eye movements; Anderson & Yantis, 2012; Bucker, Belopolsky, & Theeuwes, 2015; Hickey & van Zoest, 2012; Schroeder & Holland, 1969; Theeuwes & Belopolsky, 2012), feature-based attention (Anderson, 2013; Della Libera & Chelazzi, 2006, 2009; Gottlieb, 2012; Hickey, Chelazzi, & Theeuwes, 2010; Krebs, Boehler, & Woldorff, 2010; Raymond & O’Brien, 2009), object-based attention (Lee & Shomstein, 2013; Shomstein & Johnson, 2013), intertrial attentional priming (Kristjánsson, Sigurjónsdóttir, & Driver, 2010), and attentional carryover (Hickey, Chelazzi, & Theeuwes, 2010, 2011; Itthipuripat, Cha, Rangsipat, & Serences, 2015; but see Ásgeirsson & Kristjánsson, 2014). Additionally, reward’s effect on the visual system is rapid and persistent (MacLean & Giesbrecht, 2015a, 2015b) and can contravene explicit goals (Le Pelley, Pearson, Griffiths, & Beesley, 2015; MacLean, Diaz, & Giesbrecht, 2016; Pearson, Donkin, Tran, Most, & Le Pelley, 2015). The clearest reward effect in feature-based attention comes from the value-driven attentional capture (VDAC) paradigm, which demonstrated attentional capture to distractors previously associated with reward (Anderson, Laurent, & Yantis, 2011). The VDAC paradigm provides an indirect method to assess motivated attention. VDAC is robust and can persist 7 to 9 months after initial training (Anderson & Yantis, 2013). The VDAC paradigm consists of training and testing phases. During training, participants search for a red or green target circle. These targets are correlated with either a high-value (10¢) or low-value (2¢) monetary reward, based on their color. During the testing phase, no rewards are delivered. Instead, participants search for a neutral-colored square. On a portion of trials, red and green circles appear as task-irrelevant distractors. Typically, participants’ response time (RT) is significantly larger when a previously rewarded distractor color is present than when it is absent. The VDAC effect is evidence that reward-predictive cues induce attentional approach behavior in the form of distraction. This, in turn, suggests that VDAC relies on Pavlovian conditioning (Le Pelley et al., 2015).
Motivated behavior
Animal behavior is naturally motivated by an organism’s needs and the availability of resources in the environment. When animals interact with the environment, they learn that (1) some behaviors are fruitful, and (2) some stimuli come to predict reward. Therefore, there is a distinction between response–reward (operant) and stimulus–reward (Pavlovian) mappings. This distinction is important and useful in order to describe motivated behavior.
When a behavior is closely followed by reward, it is common for that behavior’s frequency to increase relative to unrewarded behaviors. This observation has become established as the law of effect. The law of effect characterizes how animals are motivated to obtain rewards in order to satisfy basic needs (Thorndike, 1911). Under the law of effect framework, the response is paired with rewards. Response–reward mappings, as described by the law of effect, fall under the domain of operant conditioning (Skinner, 1938). In contrast, Pavlovian conditioning characterizes motivated behavior as a function of stimulus–reward mapping. The wealth of knowledge pertaining to Pavlovian conditioning tells us that an initially neutral stimulus can become a conditioned stimulus when it signifies the availability of reward (e.g., Hall, 2003; Mackintosh, 1975; Pavlov, 1927; Rescorla & Wagner, 1972; Rombouts, Bohte, Martinez-Trujillo, & Roelfsema, 2015).
Motivated-to-earn
Monetary rewards are powerful in shaping behavior. However, the effect of money on attention can be multifaceted because it can influence attention via response–reward or stimulus–reward mappings. In addition, the receipt of monetary reward increases overall arousal. Gambling addiction serves as testament to that fact. The pathways model of gambling describes how problem gamblers often chase the adrenaline rush that accompanies wins (Blaszczynski & Nower, 2002). Although the stakes are considerably less, the paid VDAC paradigm, as conducted in the laboratory, crudely resembles a video slot machine found in casinos. In both venues, actors are motivated to maximize rewards (monetary gains). Therefore, we introduce the motivated-to-earn hypothesis, which stipulates that in order to observe VDAC, participants must always anticipate earning or otherwise obtaining the rewards at stake.
The motivated-to-earn hypothesis is supported by empirical evidence showing that rewards can sometimes lead to better overall task performance. For example, performance-contingent monetary rewards reduced compatibility effects in a flanker task (Hübner, & Schlösser, 2010) and increased perceptual sensitivity (d′) to detect faces in a spatial cuing paradigm (Engelmann, Damaraju, Padmala, & Pessoa, 2009). In these studies, rewards are thought to impel participants to exert greater attentional effort. Because the VDAC paradigm usually incorporates monetary reward (but see Anderson, 2015), the rewarded attention effects in the VDAC paradigm are always observed when participants are motivated-to-earn rewards. This is problematic because it means that VDAC effects cannot be isolated from the motivation to earn.
Evidence has recently emerged that contradicts the motivated-to-earn hypothesis. In a series of gamified VDAC studies, Miranda and Palmer (2014) found that game points without monetary rewards failed to produce VDAC. Additionally, arousing sound effects produced attentional capture irrespective of whether the sounds were presented alone or simultaneous with points during training. Another study failed to observe VDAC when participants were paid, but rewards were not correlated with any specific target feature (Sali, Anderson, & Yantis, 2014). From Miranda and Palmer (2014), we know that sound effects stochastically paired with colors during training are sufficient to induce VDAC. Can any stimulus, when merely paired with colors during training, induce value-based capture? An example from animal training (described below) offers a complementary approach to address the motivated-to-earn hypothesis (Skinner, 1951).
Secondary reinforcement
Learned reward cues are valuable because they can convey predictive information about rewards in the environment. As a consequence, particularly reliable reward cues can act as rewards themselves. Such cues are known as secondary reinforcers. Unlike food or other basic biological needs that act as primary reinforcers, money merely symbolizes reward and must be exchanged before it may convey a benefit. Money is a secondary reinforcer and is rewarding by virtue of its association with primary reinforcers. How secondary reinforcers come to direct attention is not fully known.
In operant conditioning paradigms, primary reinforcers can be replaced by secondary reinforcers with little detriment to learning. For example, in animal training, trainers often reward a desired behavior with food. The use of food is effective but impractical because too much food can quickly lead to satiation. Satiation should be avoided because it contravenes training goals and limits the amount of training that can take place in a single session. To prevent satiation, a professional trainer can simultaneously present a neutral tone, such as a click or other tone, with food via the Pavlovian conditioning procedure. Over time, the tone acquires incentive salience, and serves as a secondary reinforcer. As long as the tone continues to periodically predict food, it will continue as an effective behavior-shaping tool (Skinner, 1951). This suggests that there are periods of time in which secondary reinforcers motivate behavior as much as primary reinforcers.
In the previous example, secondary reinforcers were helpful for the trainee because they provided predictive information that could be leveraged to eventually obtain food. Also, secondary reinforcers were helpful for the trainer as a practical operant conditioning tool that prevented satiation. We can analogize the animal training example to the VDAC paradigm by conceiving of the trainer as the computer-based task and the trainee as the participant. In animal training, the neutral tone becomes rewarding on its own. Therefore, by extension, monetary images, without financial remittance, should be rewarding in the VDAC paradigm. This analogy embodies the incentive salience hypothesis. In contrast to the motivated-to-earn hypothesis, the incentive salience hypothesis predicts that a particularly powerful secondary reinforcer should produce VDAC. If secondary reinforcers are delivered on a trial-by-trial basis, but in the absence of expected payout, then high-value secondary reinforcers should nevertheless have a larger impact on attention than low-value secondary reinforcers, even in the absence of the rewards themselves. Although this question has been answered in the affirmative with sound effects (Miranda & Palmer, 2014) and social rewards (Anderson, 2015), it is unknown whether purely visual representations of money are sufficient to induce VDAC. To test this, we asked whether images of U.S. dollar bills, as overlearned secondary reinforcers, were rewarding enough to produce VDAC in participants who were not motivated-to-earn actual monetary gains.
Experiments 1a and 1b
We modified the VDAC task by incorporating high-resolution images of U.S. dollar bills ($5 and $20) in lieu of monetary reward. Participants received course credit, and this credit was not related to our reward manipulation. Most importantly, participants did not receive any monetary reward (i.e., they were not paid to participate). Our procedure was similar to previous work (Anderson et al., 2011; Roper, Vecera, & Vaidya, 2014). During training, participants searched for either a green or a red target, and each target was associated with a monetary value (e.g., the green target was more likely to be followed by the $20 image than the $5, and opposite for the red target). The bill images replaced the usual monetary rewards, and we provided no feedback regarding any accumulation of earned value. During testing trials, participants searched for a newly defined target (i.e., a diamond shape) among distractors. Crucially, in some trials a distractor was presented in the same color that had been associated with money during training (i.e., red and green). These distractor-present trials allowed us to test the effect of the associations learned during the training phase by means of attentional capture to previously rewarded colors. Our procedure preserved the trial-by-trial characteristics needed for Pavlovian conditioning and removed the external motivation to obtain a monetary reward. Remarkably, we demonstrate that the mere sight of money, when associated with specific targets, can produce VDAC.
General method
Participants
Forty University of Iowa undergraduates participated for partial course credit. All had normal or corrected-to-normal vision. Twenty participants (17 female, mean age = 18.2 years, SD = .37 years, range = 18–19 years) took part in Experiment 1a, and 20 participants (13 female, mean age = 19.0 years, SD = 1.23 years, range = 18–23 years) took part in Experiment 1b. Participants in both experiments completed the training and testing phases of the computer-based task. In Experiment 1b, we additionally probed participants on their explicit knowledge of the reward contingencies by administering a postexperimental questionnaire (see below for detail). The questionnaire was the only difference between the studies.
Apparatus
An Apple Mac Mini computer displayed stimuli on a 17-in. CRT monitor and recorded keyboard responses and latencies. The experiment was controlled using MATLAB (The MathWorks, Natick, MA) and the Psychophysics Toolbox (Brainard, 1997). Participants were seated 60 cm from the monitor in a quiet, dimly lit room.
Distribution of trials
The experiment commenced with a 24-trial practice block in which performance feedback was given to help participants learn the stimulus–response mappings (described below). During practice, all stimuli were presented in white on a black background, and no rewards were presented. The following training phase consisted of 240 trials and was segmented into 60-trial blocks. Finally, the testing phase was composed of 288 trials and was segmented into 72-trial blocks.
Training phase
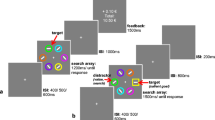
The stimulus display consisted of six colored rings arranged in a circular array (see Fig. 1a). Each ring was rendered in a different color, and the task was to report the orientation of a line segment within a red (RGB value: 255, 0, 0) or green (RGB value: 0, 255, 0) target ring, one of which was present on every trial. The target ring was equally likely to be red or green and equally likely to appear at any of the six locations along the circular stimulus array. Each ring subtended a visual angle of 2° with a line width of 5 pixels. The total stimulus array subtended a visual angle of 10° and was centered within the display. Distractor colors were randomly drawn without replacement from the following pool of values: blue (RGB value: 0, 0, 255), magenta (RGB value: 255, 0, 255), white (RGB value: 255, 255, 255), tan (RGB value: 237, 199, 114), yellow (RGB value: 255, 255, 0), and cyan (RGB value: 0, 255, 255).

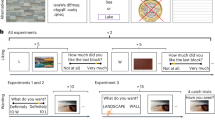
Trial schematics. (a) Training array: red and green rings, denoted here by the broken line, were associated with high-value ($20) and low-value ($5) stimuli during training. (b) Timing of training trials: Fix = fixation point, ITI = intertrial interval. (c) Testing array: Targets were blue diamonds, and previously rewarded distractors appeared on half of the trials. (d) Timing of testing trials: No bills were presented during the testing phase. Instead, feedback text (“Correct!” and “Wrong!”) was provided. These displays are for illustration only; in the experiment, white line segments appeared on black backgrounds (see Experiment 1, Method). (Color figure online.)
Each ring contained a white line segment (length = 1.2° visual angle; width = 0.2° visual angle) that was tilted either 45° or 135°. Importantly, the line inside the target ring was either vertically (0°) or horizontally (90°) aligned. Participants were instructed to report the orientation of the line within the target ring by pressing either the “z” or “?” key. The key–orientation mapping was counterbalanced.
Every trial commenced with a centrally presented fixation point that remained on-screen for 1,000 ms. After fixation, the stimulus array was displayed for 2,000 ms or until participants responded (see Fig. 1b). After an incorrect response, the text, “Wrong!” was displayed at the center of the screen in 24-point Helvetica font for 1,000 ms. After a correct response, an image of a U.S. bill ($5/$20) was centrally presented on-screen for 1,000 ms (see Fig. 2). These bill images corresponded to the veridical dimensions of a physical bill (19.72° visual angle wide × 4.75° visual angle tall). Specific feedback schedules were established such that one target color was highly rewarded and the other target color was less rewarded. For instance, for half of the participants, the high-value color was red and the low-value color was green. In this case, a correct response to a red target was followed by the presentation of a $20 bill in 80 % of trials and a $5 bill in 20 % of trials. In contrast, a green target was followed by a $5 bill in 80 % of trials and a $20 bill in 20 % of trials. These color–reward associations were counterbalanced across participants. Crucially, and in contrast to previous VDAC studies, participants knew in advance that the bill images did not reflect an actual payment of money at the current trial or at the conclusion of the experiment. Our questionnaire data from Experiment 1b confirmed that at no point did participants anticipate monetary compensation (see Supplemental Online Material).

Secondary reinforcers. High-resolution images of U.S. dollar bills (Experiments 1a & 1b), Monopoly money (Experiment 2), and cropped Monopoly money (Experiment 3) were presented after every correct training trial. Experiment 4 featured a between-category comparison ($20 U.S. dollar bill vs. cropped Monopoly 20 bill). The reinforcers in Experiment 5 were text with a dollar symbol. The word “SAMPLE,” seen here written across the U.S. bills, was not present during the experiment
Testing phase
To assess the impact of previously rewarded colors, participants completed testing trials immediately after the conclusion of training. The testing sessions were identical to the training sessions except that participants always searched for a diamond-shaped target among five colored distractor rings and reported the orientation of a line segment within the diamond. Every trial, the color of the diamond target was randomly chosen from the following pool of colors: blue, magenta, white, tan, yellow, and cyan. After participants responded, accuracy feedback (i.e., “Correct!” or “Wrong!”) was displayed for 1,000 ms (see Fig. 1c, d). Importantly, however, no images of dollar bills were presented during the testing phase. The critical manipulation in the testing phase is the color of the distractor rings. For one-half of testing trials, the distractors’ colors were randomly drawn without replacement from the aforementioned pool of colors (i.e., they were neutral with regard to reward). On the other half of testing trials, one of the distractors was presented either in red or in green (red in 25 % and green in another 25 % of testing trials), and thus in a color that was formerly rewarded during training. These previously rewarding colors were now poised to distract attention away from the diamond-shaped target.
Postexperimental questionnaire
At the experiment’s conclusion, the 20 participants in Experiment 1b were probed on their knowledge of the task and they were asked about the strategies they used to complete the task. The questionnaire was administered via paper and pencil and consisted of nine items: six open ended questions and three two-alternative forced-choice questions. Each question was administered on a separate sheet, one at a time. The questions and some representative responses are listed in the Supplemental Online Material.
Results
Training phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from analysis. This trimming cumulatively eliminated 5.9 % of the data from Experiment 1a and 6.8 % from Experiment 1b. Mean correct RT for training trials were separately computed for high- and low-value reward colors (see Table 1).
Experiment 1a
A t test revealed shorter mean response times (RTs) for high-value as compared to low-value colors, t(19) = 2.39, p = .0064, ηp 2 = .33. There was no significant effect for an analogous analysis of mean accuracy, t(19) = 0.20, p = .85, ηp 2 = .002 (compare Table 2).
Experiment 1b
There was neither a significant effect of reward on mean RT, t(19) = 0.82, p = .42, ηp 2 = .034, nor on mean accuracy, t(19) = 1.27, p = .22, ηp 2 = .078.
Testing phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from analysis. These trimming criteria cumulatively eliminated 6.0 % of the data from Experiment 1a and 7.7 % from Experiment 1b. Figure 3 plots mean correct RT for testing trials as a function of distractor value (neutral distractors only, low-value distractor present, and high-value distractor present).

Experiment 1a
A one-way repeated-measures ANOVA revealed a significant effect of distractor value, F(2, 38) = 3.80, p = .031, ηp 2 = 0.37. Pairwise analyses showed that high-value distractors produced larger RT compared to neutral distractors, t(19) = 3.26, p = .0041, ηp 2 = 0.36. The contrasts between high- versus low-value distractors and between low-value versus neutral distractors were not significant (all ps > .13). There was no significant effect of distractors on mean accuracy, F(2, 38) = 0.32, p = .73, ηp 2 = 0.084 (compare Table 3).
Experiment 1b
A one-way repeated-measures ANOVA revealed a significant effect of distractor value, F(2, 38) = 3.93, p = .028, ηp 2 = 0.31. Pairwise analyses showed that participants’ responses were slower when a high-value distractor was presented as compared to a low-value distractor, t(19) = 2.15, p = .045, ηp 2 = 0.20, or a neutral distractor, t(19) = 2.85, p = .010, ηp 2 = 0.30. The contrast between low-value and neutral distractors was not significant, t(19) = 0.50, p = .62, ηp 2 = 0.013. There was no significant effect of distractors on mean accuracy, F(2, 38) = 0.33, p = .72, ηp 2 = 0.04.
Discussion
When colored targets were implicitly associated with images of U.S. dollar bills during training, the same previously rewarded targets became powerful distractors during a subsequent transfer phase. Specifically, if distractors were presented in a previously highly rewarded color, participants were slower in searching for the diamond shape as compared to when distractors were presented in a neutral or low-rewarded color. Most importantly, the VDAC observed in Experiment 1 was induced by mere exposure to images of dollar bills and in the clear absence of any expected payout. In accordance with Miranda and Palmer (2014), this observation disconfirms the motivated-to-earn hypothesis and provides converging evidence that the VDAC paradigm primarily relies upon Pavlovian conditioning principles (Le Pelley et al., 2015).
We observed the effects of bills as facilitation during training (Experiment 1a) and critically as distraction during testing (Experiments 1a & 1b). Thus, our finding supports the incentive salience account; participants appeared to consistently seek the color that was associated with a high-value monetary amount. Apparently, VDAC does not directly rely on global motivation but instead automatically arises out of learned relationships between colors and overlearned secondary reinforcers (Miranda & Palmer, 2014; Sali et al., 2014).
We, of course, do not deny that participants can be motivated to earn cash by default, but the attentional system seems to not rely on monetary remittance to bias attention toward reward-predictive cues. Similar to Miranda and Palmer (2014), we observed a reliable VDAC although participants were not expecting to be monetarily paid. Our postexperimental questionnaire (see Supplemental Online Material) revealed that participants exerted no additional effort as a result of the bills, and they developed only superficial knowledge about the bills’ role in the experiment. Participants were at chance when asked to identify which color (red or green) was more likely to predict the $20 bill. We split the sample based on correct and incorrect guessers and found no performance differences in the VDAC task between the two groups (see Supplemental Figure 1). Although these data do not conclusively rule out the role of general stress and arousal, they do validate that participants were not routinely engaged in maximizing rewards in the task.
Money, even as an image divorced from value, is a powerful reward cue. The VDAC effect observed in Experiment 1 is a testament to a lifetime’s worth of learning about the transactional utility of money. Our frequent interactions with cash build upon each other to form robust reward associations for money. Based on a long history of these interactions, it is likely that the sight of money produces a strong reward signal in the brain (as inferred from Schultz, 2006). This putative reward signal helps us to pursue our goals by allowing us to learn about the cues in our environment. Our results provide novel evidence that attention automatically tracks the reward value of particularly potent representations of money.Footnote 1
Experiment 2
Money is endowed by its transactional utility. Early in life, we learn the value of bills and coins by exchanging them for goods and services. We frequently encounter money and are reminded of its utility at the checkout counter, vending machines, and ATMs. Regardless of whether we are aware, as adults, we have developed an understanding of the extrinsic value of physical money. Money has extrinsic value because it is universally accepted as a value-transfer vehicle. Without transactional utility, bills are merely colorful fabric.
The physical features of U.S. bills (e.g., rectangular shape, framed border, portrait, prominent numbers in the corners) make them highly recognizable as instruments of value transfer. Board-game currencies, such as Monopoly money, exhibit similar physical characteristics with U.S. bills (compare Fig. 2), and this physical similarity might allow the reward effects in Experiment 1 to generalize to Monopoly money. We asked whether Monopoly money, as a unit of value within the game, would produce VDAC in a nongamified context.
Method
Participants
Twenty undergraduates (11 female, mean age = 18.6 years, SD = .89 years, range = 18–20 years) from the University of Iowa psychology research participant pool completed the experiment for partial course credit. All participants reported having normal or corrected-to-normal visual acuity and no color blindness.
Stimuli and design
Participants viewed grayscale images of game money ($20 and $5 bill) from Hasbro’s Monopoly board game. The spatial dimensions of these bill images were identical to the U.S. bill images in the previous experiment. All other task parameters were kept the same as in Experiment 1a.
Results and discussion
Training phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from analysis (cumulatively eliminating 6.9 % of the data). Mean correct RT and mean accuracy for training trials were separately computed for high- and low-value reward colors (see Table 1). There was neither a significant effect of reward on RT, t(19) = 1.68, p = .11, ηp 2 = .13, nor on mean accuracy, t(19) = 1.12, p = .34, ηp 2 = .055.
Testing phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from analysis (cumulatively eliminating 7.0 % of the data). A one-way repeated-measures ANOVA revealed a significant effect of distractor value, F(2, 38) = 5.64, p = .007, ηp 2 = 0.23. Pairwise analyses indicated that high-value distractors produced larger RT compared to neutral distractors, t(19) = 3.56, p = .002, ηp 2 = .40. No other pairwise comparisons reached significance (all ps > .07). Likewise, there was no significant effect on mean accuracy (F < 1).
In Experiment 2, images of Monopoly money produced equivalent VDAC as the images of U.S. dollar bills in Experiments 1a and 1b. Monopoly money is likely rewarding because of its physical similarity to U.S. bills. It is also possible that Monopoly money is rewarding due to the socially reinforcing experience of winning at board games. However, this latter claim conflicts with Miranda and Palmer (2014), who found that game points alone failed to produce VDAC. Why, then, is Monopoly money valued but points are not in a gamified task?
Unlike novel generic game points, Monopoly money relies on visual similarity to U.S. bills, which possess a long history of learned value. We propose that this reward history is tied to the physical features of bills—a position that is the essence of incentive salience. The physical similarities between U.S. bills and Monopoly money appear to automatically invoke value-based feature weighting.
However, an alternative explanation for the VDAC effect reported here could rely on the sheer magnitude of the numbers presented on the bills. The value of money is conveyed by its denomination, and a manipulation of reward with the help of money (or its images) is confounded with a manipulation of nominal value itself. To isolate the role of nominal value, we designed Experiment 3, in which we cropped the images of Monopoly money to remove the contextual elements of the bills (e.g., framed border, prominent values depicted in the corners). As a result, only the number indicating the value of the bill was visible to participants. If the observed attentional capture effects are merely driven by the nominal value rather than by the implied monetary utility, then we would expect to observe attentional capture for cropped Monopoly money that is commensurate to standard Monopoly bills. However, if magnitude alone is not sufficient to set the context for value, then we expect to not observe VDAC. Drawing from Miranda and Palmer’s (2014) finding that high- and low-value point rewards did not produce VDAC, we hypothesized no VDAC with cropped bills.
Experiment 3
As in previous studies, the reported results so far were value dependent. Higher magnitude bills produced greater distraction. Experiment 3 was designed to rule out the alternative explanation for our results, according to which the nominal value of the bills alone, irrespective of the bills’ physical characteristics, modulates VDAC. To this end, we cropped the images of Monopoly money, removing the bills’ defining perceptual features and leaving only the nominal value of the bill visible.
Method
Participants
Twenty undergraduates (11 female, mean age = 18.7 years, SD = 1.42 years, range = 18–24 years) from the University of Iowa psychology research participant pool completed the experiment for partial course credit. All participants reported having normal or corrected-to-normal visual acuity and no color blindness.
Stimuli and design
Cropped images of Monopoly money appeared after every correct trial in the training phase. The images were cropped to a size of 5.37° × 1.51° visual angle, and they were displayed at the center of the screen. Only the prominent central values (5 and 20) were visible (see Fig. 2). All other procedures were identical to Experiment 1a.
Results and discussion
Training phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from RT analysis (this cumulatively eliminated 6.3 % of the data). A t test comparing mean RT for high- and low-value reward colors revealed no significant difference, t(19) = .91, p = .37, ηp 2 = .042 (see Table 1). A further t test on mean accuracy (compare Table 2) revealed that participants were on average more accurate for the low-value trials as compared to the high-value trials, t(19) = 2.62, p = .017, ηp 2 = .27.
Testing phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from RT analysis (eliminating 6.2 % of the data). Mean RT for testing trials were computed as a function of distractor value (see Fig. 3). These data were submitted to a one-way repeated-measures ANOVA. The effect of distractor value was not significant, F(2, 38) = .041, p = .99, ηp 2 = 0.001. Likewise, an analogous ANOVA on mean accuracy (compare Table 3) revealed no significant effect, F(2, 38) = .44, p = .65, ηp 2 = .022.
In contrast to Experiments 1a, 1b, and 2, no VDAC was observed in Experiment 3. Thus, there is no evidence for a VDAC based on nominal value alone. This finding strongly suggests that the VDAC observed in the previous experiments is based on reward rather than on sheer magnitude. As hypothesized, the bills’ perceptual features seem to be important to observe VDAC, implicating a strong and overlearned reward value of bills. We observed a slight accuracy advantage for the low-value condition in training, but accuracy was generally at ceiling, suggesting response accuracy trade-offs were minimal, if present at all.
Together, our results support the theme that attention can be biased in accordance with the principles of Pavlovian conditioning. Learned stimulus–reward associations turn mere images of U.S. dollar and Monopoly bills into powerful rewarding stimuli that can induce reliable attentional capture effects themselves. Moreover, those effects may emerge from the bills’ rich visual representation rather than magnitude alone. To further support this claim we designed Experiment 4, which directly tests the effects of monetary value vs. mere nominal value in a within-subjects design.
Experiment 4
In Experiment 4, we chose a slightly different approach. That is, we examined the rewarding effects of U.S. bills while holding nominal value constant. Participants viewed either an image of a $20 bill (compare Experiment 1a) or an image of the number 20, cropped from a Monopoly bill image (compare Experiment 3). This allowed us to directly test the effects of monetary value versus mere nominal value in a within-subjects design. Based on the results of Experiments 1–3, we expected to observe VDAC for distractor colors that were previously associated with the $20 bill image. In contrast, no VDAC should be obtained if the distractor color was previously associated with an image from a cropped Monopoly bill.
Method
Participants
Twenty undergraduates (12 female, mean age = 18.85 years, SD = 1.63 years, age range = 18–25 years) from the University of Iowa psychology research participant pool completed the experiment for partial course credit. All participants reported having normal or corrected-to-normal visual acuity and no color blindness.
Stimuli and design
Experiment 4 was virtually identical to Experiment 1a except for the low-reward condition. That is, while in the high-reward condition an image of a $20 dollar bill was shown (compare Experiment 1a and Fig. 2), in the low-reward condition the image of a cropped Monopoly 20 was presented (compare Experiment 3 and Fig. 2). Analogous to previous experiments, we employed a 20 %/80 % reward contingency assignment to target colors (red/green). In Experiment 4, this meant that both target colors were sometimes associated with U.S. bills and sometimes associated with nominal value.
Results and discussion
Training phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from analysis (eliminating 3.6 % of the data). There were no significant effects of reward, neither for mean RT, t(19) = 1.77, p = .093, ηp 2 = .14 (see Table 1) nor for mean accuracy, t(19) = .93, p = .37, ηp 2 = .043 (see Table 2).
Testing phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from analysis (eliminating 3.4 % of the data). Figure 3 depicts mean RT as a function of reward (neutral, low, high). A one-way repeated-measures ANOVA revealed a significant effect of distractor value, F(2, 38) = 4.48, p = .026, ηp 2 = 0.33. Pairwise analyses further showed that high-value distractors produced larger RT compared to neutral distractors, t(19) = 2.91, p = .0090, ηp 2 = .31. No other pairwise comparisons reached significance (all ps > .18). Likewise, there was no significant effect on mean accuracy (F < 1).
Participants were captured by the color previously associated with the $20 U.S. bill but not captured by the color previously associated with the nominal value. The results of Experiment 4 provide strong evidence that the capture effects observed in Experiments 1–3 are due to the physical features of bills and not monetary value. To support this claim further, we conducted Experiment 5.
Experiment 5
In Experiment 5, we addressed whether the richness of the visual representation matters at all in the secondary VDAC effect. We abstracted the bill images to their essential monetary characteristics by replacing them with plain text feedback consisting of a dollar symbol and an integer amount ($5 and $20). If the abstracted feedback is sufficiently rewarding, then we expect to observe greater attentional capture for the high reward ($20) compared to no reward.
Method
Participants
Twenty undergraduates (12 female, mean age = 19.5 years, SD = 1.70 years, age range = 18–23 years) from the University of Iowa psychology research participant pool completed the experiment for partial course credit. All participants reported having normal or corrected-to-normal visual acuity and no color blindness.
Stimuli and design
Experiment 5 was identical to Experiment 1a except that the bill images were replaced with the text ($5 or $20) written in 24-point Helvetica font at the center of the screen.
Results and discussion
Training phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from RT analysis (this cumulatively eliminated 9.6 % of the data). A t test comparing mean RT for high- and low-value reward colors revealed no significant difference, t(19) = .70, p = .50, ηp 2 = .024 (see Table 1). A further t test on mean accuracy (compare Table 2) revealed that participants accuracy did not significantly differ for the low-value trials as compared to the high-value trials, t(19) = 2.00, p = .060, ηp 2 = .17.
Testing phase
Incorrect trials and response latencies ±2.5 standard deviations of the mean were removed from RT analysis (eliminating 10.1 % of the data). Mean RT for testing trials were computed as a function of distractor value (see Fig. 3). These data were submitted to a one-way repeated-measures ANOVA. The effect of distractor value was not significant, F(2, 38) = .58, p = .46, ηp 2 = .03. Likewise, an analogous ANOVA on mean accuracy (compare Table 3) revealed no significant effect, F(2, 38) = .056, p = .95, ηp 2 = .003.
Between-subjects analysis
In a final test of the role of bills on VDAC we ran a 2 × 2 mixed-model repeated-measures ANONA on the testing phase RT data from Experiments 1a, 1b, 3, and 5. The within-subjects factor was reward with two levels (neutral and high), and the between-subjects factor was group. The first group consisted of the combined data from Experiment 1 (U.S. bill feedback), and the second group consisted of the data from Experiments 3 and 5 (nonbill feedback). The results of this analysis revealed a significant reward by group interaction, F(1, 78) = 5.11, p = .027, ηp 2 = 0.062, suggesting a reliable capture effect in the presence of U.S. bills (M = 17 ms) but not for the non-bill feedback (M = -4 ms).
General discussion
In the current experiments, we investigated the influence that money, as a reward-signaling stimulus, has on attention. Importantly, monetary income was not used as a reward because participants were never paid. Instead, money was visually presented as a 2-D image on a computer screen. Hence, we dissociated the sensory elements of money from the motivation to obtain cash. Remarkably, the bill images established reliable stimulus–reward associations. That is, target colors that were associated with images of dollar bills during training became reliable distractors during a transfer phase. Therefore, the sensory information conveyed by the image of money is rewarding. This supports Miranda and Palmer (2014), who found that the results from paid VDAC studies are not necessarily based on an expected cash payout (see also Anderson, 2015). In Experiment 2, we observed VDAC to images of Monopoly money, which suggests that participants generalize to game-issued money based on visual feature similarity to state-issued money. We found no evidence for VDAC based on sheer magnitude or monetary value per se. Instead, we observed VDAC only in the presence of the bills’ rich visual representation.
The rewarding influence of monetary images on attention and behavior seems to be automatic and independent of participants’ awareness of the target–bill pairing. That is, participants performed at chance levels when they were asked to indicate which of the two target colors (red or green) most often preceded high-value bills (see Supplemental Online Material). This indicates that participants are prone to value-driven attentional capture even when they are explicitly unaware of the underlying structure of stimulus–reward associations (for a similar conclusion, see Della Libera, Perlato, & Chelazzi, 2011; Miranda & Palmer, 2014; Seitz, Kim, & Watanabe, 2009). These results stress the role of automatic value judgements in attentional learning and downplay the motivational drive to obtain cash prizes (cf. Engelmann et al., 2009; Hübner & Schlösser, 2010). Similar to the arousing sound effects used by Miranda in Palmer (2014), our results show that VDAC operates incidentally without the need to engage participants by using explicit game-like tactics.
VDAC is highly Pavlovian
The concept of incentive salience was born out of the drug addiction literature to address the high incidence of relapse in recovering drug addicts (Robinson & Berridge, 2008). During treatment, recovering addicts do not have access to drugs. At the same time, they are not exposed to drug cues (e.g., paraphernalia, drug houses). After successfully completing treatment, a recovering addict must avoid drug use to have the best chances against relapse. Early models of addiction placed emphasis on posttreatment drug abstinence as the best method of preventing relapse. It was later discovered that when recovering addicts are exposed to drug cues, they often cannot resist the urge to use. Incentive salience was incorporated into addiction models to account for the strong cue–drug relationship in addition to the traditional response–drug association. Thus, incentive salience relies heavily on Pavlovian conditioning principles.
If VDAC is meant to measure incentive salience as described in drug addiction (Anderson, Faulkner, Rilee, Yantis, & Marvel, 2013), then we would expect VDAC to rely on Pavlovian conditioning. Whether or not VDAC can serve as a proxy for incentive salience is an open question, although some evidence has begun to accumulate (Le Pelley et al., 2015; Pearson et al., 2015). The results of our study provide converging evidence with a recent study that demonstrated that rewards can sometimes lead to attentional capture even when the rewarded features are always task irrelevant. Le Pelley and colleagues (2015) modified Anderson’s et al. (2011) original VDAC paradigm so that rewards were implicitly paired with the color of a salient distractor. Rather than employing a training phase and a testing phase, they used a single phase where participants searched for a gray square among gray circles. Participants were paid a small monetary amount (10¢ or 1¢) on a trial-by-trial basis for fast, correct responses to discriminate the orientation of a line within the target square. A salient color distractor was present on a proportion of trials. The color of this distractor was associated with either high-value or low-value reward. Critically, unlike the original VDAC design, these distractors never served as targets. Thus, the rewarded distractor was always task irrelevant. Because rewards were performance contingent, paying attention to the distractor resulted in reduced monetary gains. The authors argued that if VDAC relies on Pavlovian principles, then high-value distractors should produce greater attentional capture than low-value distractors. Alternatively, they argued if VDAC relies of operant principles, then attention should be indifferent to the specific color–reward associations. They observed better accuracy when the distractor was associated with low value than when the distractor was associated with high value. Therefore, participants were captured by the high-value distractor more than the low-value distractor despite these distractor colors never having been task relevant. This observation implies that VDAC results from Pavlovian rather than operant conditioning. Our results compliment this work by providing converging evidence that VDAC arises from the sheer statistical cooccurrence of colored targets and secondary reinforcers.
Extension to novel value systems
The interpretation set forth herein stresses the role of mere exposure to rewards. One interesting extension of our findings applies to electronic cash (e-cash) systems. Societies around the world are becoming increasingly cashless. For example, the government of Denmark aims to phase out physical cash for in-store payments by 2016 (Matthews, 2015). Sweden is on verge of abandoning physical money altogether and has reduced the supply of physical currency by as much as 50 % from 2008 to 2015 (KTH, 2015). Many consumers are already familiar with electronic banking. With the advent of blockchain technologies, such as the purely e-cash Bitcoin (Nakamoto, 2008), it will soon be possible to conduct any financial transaction from a mobile device. Despite these advantages over traditional cash, consumers have been sluggish to adopt e-cash. One cause of this reluctance may be due to our strong attachment with physical money, based partly on money’s status as a secondary reinforcer. We commonly handle money and have learned its value by conducting countless cash transactions. We are familiar with money, and there is comfort in its tangibility; however, there is every reason to expect that e-cash, despite its virtual nature, could also acquire such an elevated status. The present work demonstrated that mere images of money and even images of Monopoly money can be rewarding. This suggests that consumers could come to value e-cash as highly as physical cash provided they learn to associate reward with salient perceptual representations of e-cash (e.g., digital artwork in the form of a symbol, seal, emblem, logo). We posit that with frequent use and exposure, e-cash might someday become as relevant (psychologically speaking) as physical cash.
Gamification
Gamification is a growing trend in human factors research involving the process of adding an underlying point structure to otherwise mundane computer-based tasks (Deterding, Dixon, Khaled, & Nacke, 2011). Although most rewarded attention studies involve monetary payment, some investigators have introduced game-like features to motivate participant performance and to improve the overall quality of experience in experimental sessions (e.g., Washburn, 2003). Miranda and Palmer (2014) gamified the VDAC task and replaced monetary rewards with points that were doled out on a trial-by-trial basis. For good performance, participants were awarded points, and they competed with each other to obtain a place on the high-score leader board. Critically, one target color was associated with a high-value bonus modifier and the other was associated with a low-value bonus modifier. When gamified by points, participants reported higher levels of satisfaction and enjoyment, but crucially, no VDAC was obtained. This work compliments Experiments 1a and 1b and together they show that being motivated to acquire rewards is neither sufficient nor necessary for VDAC.
Information, pertinence, and arousal
When motivated to achieve a desired state, attention can be directed toward informative cues. This information gradient provides the basis for value representation in the brain (Gottlieb, 2012). Attention filters incoming information and allows only the most pertinent representations to carry on. Pertinence in turn is determined by the environmental context (e.g., Cosman & Vecera, 2013) and by internal states. For instance, street signs and traffic signals are pertinent when navigating an urban city, but rocks and rivers are pertinent when hiking in the wilderness. Food cues are pertinent when we are hungry, but water cues are pertinent when we are thirsty. We propose environmental events that are correlated with desirable outcomes become powerful cues that acquire pertinence, generate arousal, and thus influence attention and subsequent behavior. Classic studies on reinforcement learning (Skinner, 1938; Thorndike, 1911) and the contemporary sentiment on value-driven attention (Anderson, 2013; Gottlieb, 2012; Le Pelley et al., 2015; Sali et al., 2014) support this view.
Recently, Miranda and Palmer (2014) also showed attentional capture to colors paired with arousing sound effects during a training phase. One sound effect named, Electric Whip, was designated as the high reward and another sound effect, Sonic Hammer, was designated as the low reward. These designations were based upon significantly greater self-reported measures of arousal and pleasantness for the Electric Whip. In testing, there was a magnitude-based capture effect with greater RTs in the presence of a color associated with the Electric Whip compared to the Sonic Hammer compared to colors with no previous association. Therefore arousal certainly plays a role in inducing VDAC—it may even be vital. Sound effects are arousing, and many classes of images are arousing (e.g., money, food, drugs, pornography).
Money therefore is not special in its ability to induce VDAC; however, bill images are especially suited for experimental design because they come in several denominations that are roughly controlled for their physical features. Furthermore, as demonstrated herein, these denominations induce magnitude-based VDAC effects. Therefore, the use of money as a feedback device is practical because it conveys objective utility that can be leveraged to contrast reward effects across an external value dimension. The current work therefore confirms the face validity of bill images as a way to manipulate reward levels within a behavioral experiment.
In conclusion, U.S. bills exert noticeable effects on attentional processes. Moreover, this effect generalizes to board game bills (i.e., Monopoly money). We propose that VDAC is automatically set by mere exposure to rewarding stimuli and does not directly rely on the explicit motivation to earn those rewards (for a similar conclusion, see Anderson, 2015; Miranda & Palmer, 2014). Finally, our procedure demonstrates one example of how secondary reinforcers can be used to conserve limited financial resources in the experimental context. That is, researchers who are interested in studying the effect of money and reward on behavior can use images of bills to manipulate reward as VDAC can be induced gratis.
References
Anderson, B. A. (2013). A value-driven mechanism of attentional selection. Journal of Vision, 13(3), 1–16.
Anderson, B. A. (2015). Social reward shapes attentional biases. Cognitive Neuroscience. doi:10.1080/17588928.2015.1047823. Advance online publication.
Anderson, B. A., Faulkner, M. L., Rilee, J. J., Yantis, S., & Marvel, C. L. (2013). Attentional bias for nondrug reward is magnified in addiction. Experimental and Clinical Psychopharmacology, 21(6), 499.
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011). Value-driven attentional capture. Proceedings of the National Academy of Sciences, 108(25), 10367–10371.
Anderson, B. A., & Yantis, S. (2012). Value-driven attentional and oculomotor capture during goal-directed, unconstrained viewing. Attention, Perception, & Psychophysics, 74(8), 1644–1653.
Anderson, B. A., & Yantis, S. (2013). Persistence of value-driven attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 39(1), 6–9.
Ásgeirsson, Á. G., & Kristjánsson, Á. (2014). Random reward priming is task-contingent: The robustness of the 1-trial reward priming effect. Frontiers in Psychology, 5, 309. doi:10.3389/fpsyg.2014.00309.
Blaszczynski, A., & Nower, L. (2002). A pathways model of problem and pathological gambling. Addiction, 97(5), 487–499.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436.
Bromberg-Martin, E. S., & Hikosaka, O. (2009). Midbrain dopamine neurons signal preference for advance information about upcoming rewards. Neuron, 63(1), 119–126.
Bucker, B., Belopolsky, A. V., & Theeuwes, J. (2015). Distractors that signal reward attract the eyes. Visual Cognition, 23, 1–24.
Cosman, J. D., & Vecera, S. P. (2013). Context-dependent control over attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 39(3), 836.
Cousineau, D. (2005). Confidence intervals in within-participant designs: A simpler solution to Loftus and Masson’s method. Tutorials in Quantitative Methods for Psychology, 1, 42–45.
Della Libera, C., & Chelazzi, L. (2006). Visual selective attention and the effects of monetary rewards. Psychological Science, 17(3), 222–227.
Della Libera, C., & Chelazzi, L. (2009). Learning to attend and to ignore is a matter of gains and losses. Psychological Science, 20(6), 778–784.
Della Libera, C., Perlato, A., & Chelazzi, L. (2011). Dissociable effects of reward on attentional learning: From passive associations to active monitoring. PLOS ONE, 6(4), e19460.
Desimone, R., & Duncan, J. (1995). Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18(1), 193–222.
Deterding, S., Dixon, D., Khaled, R., & Nacke, L. (2011). From game design elements to gamefulness: Defining gamification. Proceedings of the 15th International Academic MindTrek Conference: Envisioning Future Media Environments, 9–15.
Engelmann, J. B., Damaraju, E., Padmala, S., & Pessoa, L. (2009). Combined effects of attention and motivation on visual task performance: Transient and sustained motivational effects. Frontiers in Human Neuroscience, 3.
Gottlieb, J. (2012). Attention, learning, and the value of information. Neuron, 76(2), 281–295.
Hall, G. (2003). Learned changes in the sensitivity of stimulus representation: Associative and nonassociative mechanisms. Quarterly Journal of Experimental Psychology, 56B, 43–55.
Hickey, C., Chelazzi, L., & Theeuwes, J. (2010). Reward guides Vision when it’s your thing: Trait reward-seeking in reward-mediated visual priming. PLOS ONE, 5(11), e14087.
Hickey, C., Chelazzi, L., & Theeuwes, J. (2011). Reward has a residual impact on target selection in visual search, but not on the suppression of distractors. Visual Cognition, 19(1), 117–128.
Hickey, C., & van Zoest, W. (2012). Reward creates oculomotor salience. Current Biology, 22(7), R219–R220.
Hübner, R., & Schlösser, J. (2010). Monetary reward increases attentional effort in the flanker task. Psychonomic Bulletin & Review, 17(6), 821–826.
Itthipuripat, S., Cha, K., Rangsipat, N., & Serences, J. T. (2015). Value-based attentional capture influences context dependent decision-making. Journal of Neurophysiology, 114, 560–569.
Krebs, R. M., Boehler, C. N., & Woldorff, M. G. (2010). The influence of reward associations on conflict processing in the Stroop task. Cognition, 117(3), 341–347.
Kristjánsson, Á., Sigurjónsdóttir, Ó., & Driver, J. (2010). Fortune and reversals of fortune in visual search: Reward contingencies for pop-out targets affect search efficiency and target repetition effects. Attention, Perception, & Psychophysics, 72(5), 1229–1236.
KTH. (2015). Cashless future for Sweden? KTH. Retrieved from https://www.kth.se/en/forskning/artiklar/cashless-future-for-sweden-1.597792
Lauwereyns, J., Takikawa, Y., Kawagoe, R., Kobayashi, S., Koizumi, M., Coe, … Hikosaka, O. (2002). Feature-based anticipation of cues that predict reward in monkey caudate nucleus. Neuron, 33(3), 463–473.
Le Pelley, M. E., Pearson, D., Griffiths, O., & Beesley, T. (2015). When goals conflict with values: Counterproductive attentional and oculomotor capture by reward-related stimuli. Journal of Experimental Psychology: General, 144, 158–171.
Lee, J., & Shomstein, S. (2013). The differential effects of reward on space-and object-based attentional allocation. The Journal of Neuroscience, 33(26), 10625–10633.
Loftus, G. R., & Masson, M. E. (1994). Using confidence intervals in within-participant designs. Psychonomic Bulletin & Review, 1, 476–490. doi:10.3758/BF03210951
Luck, S. J., Chelazzi, L., Hillyard, S. A., & Desimone, R. (1997). Neural mechanisms of spatial selective attention in areas V1, V2, and V4 of macaque visual cortex. Journal of Neurophysiology, 77(1), 24–42.
Mackintosh, N. J. (1975). A theory of attention: Variations in the associability of stimuli with reinforcement. Psychological Review, 82, 276–298.
MacLean, M. H., Diaz, G. K., & Giesbrecht, B. (2016). Irrelevant learned reward associations disrupt voluntary spatial attention. Attention, Perception, & Psychophysics. doi:10.3758/s13414-016-1103-x. Advance online publication.
MacLean, M. H., & Giesbrecht, B. (2015a). Irrelevant reward and selection histories have different influences on task-relevant attentional selection. Attention, Perception, and Psychophysics, 22, 222–223. doi:10.3758/s13414-015-0851-3
MacLean, M. H., & Giesbrecht, B. (2015b). Neural evidence reveals the rapid effects of reward history on selective attention. Brain Research, 1606, 86–94. doi:10.1016/j.brainres.2015.02.016
Matthews, C. (2015). This country wants to ban the use of cash in stores. Fortune. Retrieved from http://fortune.com/2015/05/22/denmark-paper-money/
McAlonan, K., Cavanaugh, J., & Wurtz, R. H. (2008). Guarding the gateway to cortex with attention in visual thalamus. Nature, 456(7220), 391–394. doi:10.1038/nature07382
Miranda, A. T., & Palmer, E. M. (2014). Intrinsic motivation and attentional capture from gamelike features in a visual search task. Behavior Research Methods, 46(1), 159–172.
Nakamoto, S. (2008). Bitcoin: A peer-to-peer electronic cash system. Retrieved from http://bitcoin.org/bitcoin.pdf
O’Connor, D. H., Fukui, M. M., Pinsk, M. A., & Kastner, S. (2002). Attention modulates responses in the human lateral geniculate nucleus. Nature Neuroscience, 5(11), 1203–1209.
Pavlov, I. P. (1927). Conditioned reflexes. Retrieved from DoverPublications.com
Pearson, D., Donkin, C., Tran, S. C., Most, S. B., & Le Pelley, M. E. (2015). Cognitive control and counterproductive oculomotor capture by reward-related stimuli. Visual Cognition, 23, 41–66.
Raymond, J. E., & O’Brien, J. L. (2009). Selective visual attention and motivation: The consequences of value learning in an attentional blink task. Psychological Science, 20(8), 981–988.
Rescorla, R. A., & Wagner, A. R. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In A. H. Black & W. F. Prokasy (Eds.), Classical conditioning II: Current research and theory (pp. 64–99). New York, NY: Appleton-Century-Crofts.
Reynolds, J. H., Chelazzi, L., & Desimone, R. (1999). Competitive mechanisms subserve attention in macaque areas V2 and V4. The Journal of Neuroscience, 19(5), 1736–1753.
Robinson, T. E., & Berridge, K. C. (2008). The incentive sensitization theory of addiction: Some current issues [Review]. Philosophical Transactions of the Royal Society of London Series B, Biological Sciences, 363(1507), 3137–3146.
Rombouts, J. O., Bohte, S. M., Martinez-Trujillo, J., & Roelfsema, P. R. (2015). A learning rule that explains how rewards teach attention. Visual Cognition, 23(1–2), 179–205. doi:10.1080/13506285.2015.1010462.
Roper, Z. J. J., Vecera, S. P., & Vaidya, J. (2014). Value-driven attentional capture in adolescence. Psychological Science, 25(11), 1987–1993. doi:10.1177/0956797614545654.
Sali, A. W., Anderson, B. A., & Yantis, S. (2014). The role of reward prediction in the control of attention. Journal of Experimental Psychology: Human Perception and Performance, 40(4), 1654. doi:10.1037/a0037267.
Schroeder, S. R., & Holland, J. G. (1969). Reinforcement of eye movement with concurrent schedules. Journal of the Experimental Analysis of Behavior, 12(6), 897–903.
Schultz, W. (2006). Behavioral theories and the neurophysiology of reward. Annual Review of Psychology, 57, 87–115.
Seitz, A. R., Kim, D., & Watanabe, T. (2009). Rewards evoke learning of unconsciously processed visual stimuli in adult humans. Neuron, 61(5), 700–707.
Serences, J. T. (2008). Value-based modulations in human visual cortex. Neuron, 60(6), 1169–1181.
Shomstein, S., & Johnson, J. (2013). Shaping attention with reward effects of reward on space-and object-based selection. Psychological Science, 24(12), 2369–2378.
Skinner, B. F. (1938). The behavior of organisms: An experimental analysis. New York, NY: Appleton-Century-Crofts.
Skinner, B. F. (1951). How to teach animals. Scientific American, 185, 26–29.
Stănişor, L., van der Togt, C., Pennartz, C. M., & Roelfsema, P. R. (2013). A unified selection signal for attention and reward in primary visual cortex. Proceedings of the National Academy of Sciences, 110(22), 9136–9141.
Theeuwes, J., & Belopolsky, A. V. (2012). Reward grabs the eye: Oculomotor capture by rewarding stimuli. Vision Research, 74, 80–85.
Thorndike, E. L. (1911). Animal intelligence. New York, NY: Macmillan.
Washburn, D. A. (2003). The games psychologists play (and the data they provide). Behavior Research Methods, Instruments, & Computers, 35(2), 185–193.
Author information
Authors and Affiliations
Corresponding authors
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(DOCX 191 kb)
Rights and permissions
About this article

Cite this article
Roper, Z.J.J., Vecera, S.P. Funny money: the attentional role of monetary feedback detached from expected value. Atten Percept Psychophys 78, 2199–2212 (2016). https://doi.org/10.3758/s13414-016-1147-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1147-y