
Abstract
The ability of a stimulus to capture visuospatial attention depends on the interplay between its bottom-up saliency and its relationship to an observer’s top-down control set, such that stimuli capture attention if they match the predefined properties that distinguish a searched-for target from distractors (Folk, Remington, & Johnston, Journal of Experimental Psychology: Human Perception & Performance, 18, 1030–1044 1992). Despite decades of research on this phenomenon, however, the vast majority has focused exclusively on matches based on low-level physical properties. Yet if contingent capture is indeed a “top-down” influence on attention, then semantic content should be accessible and able to determine which physical features capture attention. Here we tested this prediction by examining whether a semantically defined target could create a control set for particular features. To do this, we had participants search to identify a target that was differentiated from distractors by its meaning (e.g., the word “red” among color words all written in black). Before the target array, a cue was presented, and it was varied whether the cue appeared in the physical color implied by the target word. Across three experiments, we found that cues that embodied the meaning of the word produced greater cuing than cues that did not. This suggests that top-down control sets activate content that is semantically associated with the target-defining property, and this content in turn has the ability to exogenously orient attention.
Similar content being viewed by others


At any given point in time, the natural environment bombards the human brain with volumes of visual input, and this volume of input exceeds the capacity of the brain’s limited perceptual resources. Attention, therefore, can be seen as an adaptation that prioritizes certain stimuli for detailed processing, at the expense of others (Broadbent, 1958; Desimone & Duncan, 1995; Kahneman, 1973; Kastner & Pinsk, 2004). This means that it is crucial for spatial attention to be efficiently deployed to stimuli or locations that provide relevant information, given an observer’s task or goals. Furthermore, since attention has such a profound influence on determining what stimuli are ultimately consciously perceived, understanding the mechanisms that govern the allocation of attention in space is important in understanding how humans perceive the world around them.
The classic way of measuring reflexive attentional orienting (or “capture”) is cuing: a stimulus (e.g., abrupt change in luminance, the “cue”) is presented at a given location, and a subsequent target stimulus either appears at the same (valid) or a different (invalid) location to the cue. The task is then to detect or identify the target stimulus. Attentional capture is gauged by “cuing,” which is quantified as the difference in reaction time between valid and invalid trials (Posner, 1980; Posner & Cohen, 1984). The logic here is that if the cue captures attention, responses to the target are facilitated when the target subsequently appears at that location, compared with when it occurs elsewhere, because additional time is required to orient attention away from the cue and to the location of the target. One of the hallmarks of exogenous orienting, unlike endogenous or volitional orienting, is that such attentional capture occurs even when the cue does not predict the location of the target (i.e., the target is equally likely to occur at a cued vs. an uncued location) (Jonides & Yantis, 1988; Posner & Cohen, 1984).
Whether even a physically salient stimulus will capture attention, however, depends on the participant’s top-down control set or task-induced goals. Folk, Remington, and Johnston (1992) demonstrated that salient cues such as a luminance onset or a color singleton (one red item among multiple white items) only captured attention when they matched the feature that differentiated the target from the distractors in the subsequent target array. That is, when the target was a color singleton, color-singleton cues captured attention, whereas luminance-onset cues did not, and when the target was an abrupt onset, abrupt-onset cues captured attention whereas color singletons did not. This crucial relationship between the task-induced search strategy and the ability of particular physical properties to orient spatial attention is known as contingent capture (Folk et al., 1992).
Research has supported the contingent nature of attentional capture for a variety of physical properties, including color (Al-Aidroos, Harrison, & Pratt, 2010; Ansorge & Heumann, 2003; Folk & Remington, 1998), luminance (Most et al., 2001), shape (Bacon & Egeth, 1994), and motion (Folk, Remington, & Wright, 1994). However, given the way in which contingent capture should operate, contingent capture should extend beyond these low-level effects. That is, physiologically, processing of basic physical properties of stimuli occurs “earlier” in the brain (from the perspective of a feedforward sweep), in more posterior regions, whereas a more abstract or semantic appreciation of the identity of an object relies on “later” (more anterior) brain regions. Integration of these sources of information via top-down or feedback (reentrant) processing from anterior to posterior is critical to normal perception (Bar, 2003; Bar et al., 2006; Di Lollo, 2010; Dux, Visser, Goodhew, & Lipp, 2010; Kveraga, Boshyan, & Bar, 2007; Lamme & Roelfsema, 2000; Pascual-Leone & Walsh, 2001; Sillito, Cudeiro, & Jones, 2006; Wyatte, Curran, & O’Reilly, 2012). Since contingent capture is thought to be a “top-down” exertion over visual attention (from anterior to posterior brain areas), contingent capture should have access to semantic content, and therefore the ability of simple features to capture attention could depend on their relationship with currently activated semantic content in the observer’s mind. This, however, has not yet been established, and so here we sought to test this prediction. Note that this perspective would predict a unidirectional influence of semantics over whether features such as color capture attention (given the “top-down” nature of a control set). Such unidirectionality is also consistent with the fact that simple physical features are processed most efficiently (see, e.g., Treisman & Gelade, 1980), and thus it is more likely that their relationship with semantic concepts will govern attentional capture.
This prediction, which stipulates that stimuli that exemplify the features of an activated semantic control set is also consistent with the embodied cognition framework (see, e.g., Barsalou, 1999, 2005; Gallese & Lakoff, 2005), according to which abstract semantic concepts are grounded in sensorimotor mechanisms. That is, in the last decade or so there has been an emerging consensus that concept representation, far from being arbitrary and divorced from perceptual machinery, in fact draws on shared mechanisms for recognizing objects. This means that the brain relies on common mechanisms for representing the concept “apple” and for perceiving an apple as an object in the world. Consistent with this notion, there is evidence that activating a semantic category indeed coactivates the mechanism for perceiving physical color (Connell, 2007; Connell & Lynott, 2009; Simmons et al., 2007). For example, Connell (2007) visually presented participants with a sentence, followed by a picture, and their task was to decide as quickly as possible whether the picture was mentioned in the sentence. The key manipulation was the compatibility between the color of the object implied in the sentence (e.g., sentence mentions steak in a butcher shop = red steak) and the color displayed in the image (e.g., cooked steak = brown). Participants were faster to respond to the picture when the implied color and picture mismatched, compared with when they matched (see Gozli, Chasteen, & Pratt, 2013, for an investigation and discussion of facilitation vs. interference in such paradigms).
More recently, Yee, Ahmed, and Thompson-Schill (2012) tested for color-based priming with words referring to objects (e.g., “cucumber” primes “emerald” because both are green, but does not prime “pendant”). These authors found that such priming was observed when participants first completed a Stroop (color-naming) task, whereas when participants completed the priming task first, no object-color priming was observed (Yee et al., 2012). This suggests that while color is part of the representation of such concepts, it can be “primed” to have an effect on behavior or not, depending on the context (see also Connell & Lynott, 2009).
Thus, the embodied cognition framework stipulates that whenever a semantic concept is activated, the physical color that is associated with the concept will be coactivated. However, it remains to be determined whether the mere activation of this information is sufficient to govern whether a stimulus will capture visual attention in space. That is, studies such as Connell (2007) and Yee et al. (2012) found that the congruency between semantics and color affected reaction time for stimuli presented centrally, but it is yet to be determined whether this relationship influences the allocation of attention in space, and therefore contingent capture. The embodied cognition perspective predicts that these effects are substantive and far-reaching, and by inference should affect the fundamental cognitive process of spatial attentional orienting. This, then, should mean that in the presence of a semantically defined control set, cues that instantiate the physical color associated with this concept should capture attention. Importantly, however, given that semantic concepts are thought to call upon low-level sensorimotor mechanisms, this does not imply that the perception of basic features must draw upon semantic representations. That is, this framework does not necessarily predict the reverse: that in the presence of a control set for a particular color, stimuli that are semantically related to that color will capture attention.
To test these predictions arising from how top-down control sets must be instantiated via the physiology of the brain, and also the cognitive architecture of the embodied mind, we examined whether cues that reflect the physical color associated with an activated word meaning would produce contingent capture when compared against cues whose color mismatched this word meaning. It is known that when searching for a physically red target, red cues capture attention but green cues do not; but does this contingent attentional capture extend to when the target is instead defined by semantics? In other words, is it still physically red cues that exclusively capture attention when the goal is to find the word “red,” or does contingent capture fail in this situation, and so all stimuli, regardless of their features, produce equivalent cuing? To test this, rather than using objects that tend to be merely associated with a particular color, but can also be related to other colors (e.g., an apple is usually red, but can also be green or yellow), we chose stimuli with the most unambiguous color-semantic relationship: color words (e.g., red). We then had participants search for a target defined by word meaning. That is, the target was differentiated from distractors by semantics rather than color (e.g., the word “red” among other color-word distractors, all appearing in black). Adopting a top-down control set defined by semantics in this way produces a relatively difficult visual search task (Duncan & Humphreys, 1989; Treisman & Gelade, 1980; Wolfe, 1994), but it allows us to assess where attention was reflexively oriented in the presence of an activated word meaning.
In the present study, we orthogonally varied whether the cue that preceded the target array matched semantically and featurally (in terms of color) with the target. If stimuli that featurally embody an activated word meaning can only produce congruency effects and cannot reflexively orient attention, then there should be no differential contingent capture; that is, we should see equivalent cuing magnitudes for all cue types (another alternative would be to see contingent capture for the cues that semantically match the target, but given that semantics is an abstract property, this seemed unlikely). Alternatively, if such stimuli can orient the location of attention in space, then the cues that embody the meaning of the target word should capture attention (i.e., the physically red cues). We compared the pattern of cuing in this semantic condition against a more traditional featurally defined target (i.e., search for the red-colored target), in which the physically red cues would be predicted to capture attention and green cues would not. This provided an important demonstration that these cues in our experimental setup are indeed capable of capturing attention, and would allow us to directly compare the effect on attention of a semantically defined control set versus a featurally defined one.
Experiment 1
The purpose of Experiment 1 was to assess whether, in the presence of a semantically defined control set, cues that embody the physical features associated with this concept would contingently capture attention. To do this, we had participants search for a target word, and assessed the extent to which the physical color of a cue determined whether it reflexively captured attention. A condition in which participants searched for a target defined by features (color) was also included, for comparison.
Method
Participants
Twenty-one (15 female) undergraduate psychology students (Mean age = 20.67 years, SD = 8.67) at the University of Toronto participated in exchange for course credit. All participants reported normal color vision and provided written, informed consent prior to participation. The Research Ethics Board at the University of Toronto approved the experimental protocol.
Stimuli
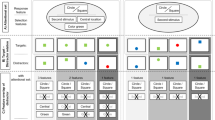
All stimuli were presented on a CRT monitor operating at an 85-Hz refresh rate. Viewing distance was fixed at 44 cm with a chin rest. Four black placeholders (8.5° × 7.8° of visual angle) were arranged in a plus-sign configuration around a central-fixation cross (6.2° of separation between cross and inner side of placeholder) on a gray background (see Fig. 1). Cues and targets were letters presented in the center of the placeholders (Courier New font, size 18). Cues could be colored either red or green, and the letters could spell the word RED or GREEN (always uppercase). Cue color and cue-word meaning were randomly determined on each trial. The cue appeared in the same location as the subsequent target on 25 % of trials. Importantly, this means that identical cues were used in both conditions. The two conditions instead differed in their task requirements and the construction of the target array. In the semantic condition, all targets and distractors were black. The target word always said “red,” either in upper - or lowercase, and the distractors were selected from among the words green, blue, yellow, pink, orange, and white. In the featural condition, the red-colored target was a randomly selected letter string that did not constitute a word. The distractors that appeared simultaneously with the target were colored green, blue, and yellow, and were also random letter strings (although never the same as the target). In both conditions, targets and distractors could appear in either upper- or lowercase (equiprobable, randomly determined on each trial), the location of the target was randomly selected, and the same distractor was never repeated in the target array on a single trial.

(a) A schematic illustration of a trial in the semantic condition. The task was to search for the word “red” and identify whether it is in upper- or lowercase as quickly and accurately as possible. (b) A schematic illustration of a trial in the featural condition. Possible cue options (equiprobable) are shown to the right of the cue array. The task was to search for the red-colored item and identify whether it is in upper- or lower case as quickly and accurately as possible
Procedure
Each trial began with a fixation display (cross + placeholders) presented for 1,000 ms; then a cue was presented for 106 ms, followed by another fixation display for 106 ms. This interstimulus interval was selected to be as close as possible to that in Folk et al., (1992) as the refresh rate of the monitor would allow. The target array was then presented until a response was registered. In the semantic condition, participants were told that the target was the word “red,” and in the featural condition, participants were told that the target was the red-colored item. In both cases, the participants’ task was to identify as quickly and accurately as possible whether the target was in upper- or lowercase (responses were made using the “z” and “?/” keys on a standard keyboard), and they were informed that any flashes in advance of the array were task-irrelevant. There was a 1,000-ms intertrial interval (during which the screen was blank gray). All participants completed two separate blocks of trials (one consisting of the semantic and one the featural condition), with order of block completion counterbalanced across participants. Each participant completed 480 trials (240 per target condition), with rest breaks scheduled every 120 trials (the length of which was at the discretion of the participant).
Results and discussion
Trials on which response times to identify the target (as upper- or lowercase) exceeded 2.5 SD above a given participant’s mean RT, or were less than 200 ms, were excluded from the analysis (average 2.22 % of trials excluded). The lower-bound cutoff was chosen, since responses times prior to 200 ms would most likely reflect anticipatory responses, rather than genuine task performance. Similarly, responses that exceeded the upper threshold likely reflected trials in which participants were not complying with the instruction to respond as quickly and accurately as possible.
Accuracy in identifying the target was high ( > 94 % for all combinations of target type, cue color, cue-word meaning, and validity). Correct response times were then used to compute cuing effects (response time for invalid minus valid condition; see Table 1 for these RTs). These cuing effects were then submitted to a 2 (Target Condition) × 2 (Cue Color) × 2 (Cue-Word Meaning) repeated-measures analysis of variance (ANOVA); see Fig. 2. This revealed a significant main effect of cue color on cuing magnitude [F(1,20) = 85.66, p < .001, ηp 2 = .811], such that the average cuing magnitude for red-colored cues (203 ms) was greater than the average cuing magnitude for green-colored cues (75 ms). None of the other main effects or interactions reached significance (ps >=.155 and ηp 2s <=.098).

(a) Cuing magnitude (correct RT for invalid minus valid trials) in the semantic condition in Experiment 1, in which participants searched for the word “red” among other color-word distractors. (b) Cuing magnitude in the featural condition in Experiment 1, in which participants searched for a red-colored target among other-color distractors. Error bars on both graphs represent standard errors of the means
The results from the experiment reveal that when searching for a target defined by the semantic property of a color word (“red”), the effectiveness of the cue in orienting attention was contingent on whether it embodied the physical properties of this word. In other words, the color associated with an activated semantic concept has the ability to systematically influence the location of attention in space. If this were not the case, then cuing magnitude should be equivalent for red- and green-colored cues. But instead, we observed a systematic effect of cue color on cuing magnitude, such that those that embodied the color of the target produced stronger cuing. It is noteworthy, moreover, that there was neither a main effect nor any interactions involving target condition (semantic vs. featurally defined target), indicating that in this experiment the semantic target condition produced effects on attention equivalent to those in a more conventional featural contingent-capture paradigm.
Given that previous research has demonstrated that context influences the relationship between color and semantics on a Stroop task (Yee et al., 2012), we also examined whether the effect of semantic control set on attentional capture by a particular color cue was affected by order of block completion. That is, was the effect of color contingent capture in the semantic control set affected by whether participants completed the semantic control-set condition before or after the featural control-set condition? In order to assess this, we entered order of block completion as a between-subjects factor in a 2 (Cue Color) × 2 (Cue-Word Meaning) ANOVA focused on cuing magnitudes in the semantic control-set condition. This revealed that there was no main effect of block order on cuing [F(1,19) = 2.37, p = .140, ηp 2 = .111], and block order did not significantly interact with any main effect or interaction (Fs < 2.04, ps >.169, ηp 2s < .098).
According to the contingent-capture perspective, the green-colored cues in this experiment should not have captured attention in the presence of a top-down control set for the color red (Folk et al., 1992). That is, contingent capture predicts a cuing effect equivalent to zero for the green-colored cues. Yet in both the featural control-set and semantic control-set conditions, both green-colored cues produced numerically a nonzero cuing effect, evidence that they captured attention to their location in space. When compared against zero with a single-sample t-test, however, in the featural control-set condition, only the green word “GREEN” produced significant cuing [t(20) = 2.84, p = .010], whereas the green word “RED” cues only trended toward significance [t(20) = 1.72, p = .100]. Although this nonzero cuing was also present in the semantic control-set condition, that is, both green-colored cues produced significant cuing [t(20) = 3.87, p = .001, and t(20) = 2.78, p = .011 for word “RED” and “GREEN” cues, respectively], this is less comparable with previous contingent-capture studies in which the top-down control sets have been defined by basic features. If we focus on the featural control-set condition, therefore, this presence of a cuing effect for at least one of the cues that did not match the top-down control could be indicative of rapid disengagement (Theeuwes, 1991, 1992, 1994, 2004). According to this framework, a control set does not completely eliminate all attentional orienting to stimuli that do not match the target-defining property. Instead, all stimuli, regardless of their relationship to the top-down control set, are briefly attended, but stimuli that do not match the control set are more efficiently disengaged from than stimuli that match the control set. This could explain why there was cuing for such nonmatching stimuli, albeit less than for matching stimuli: The control set influenced the speed of disengagement from the cues, rather than whether they were attended at all.
Another possible explanation, however, is that participants adopted a displaywide control set for the feature that defines the onset of the target array, rather than the feature that defines the location of the target within the array (“displaywide contingent orienting hypothesis”; Burnham, 2007; Gibson & Kelsey, 1998). That is, if the target display (both target and distractors) appears via an abrupt onset, then this feature (i.e., onset) can capture attention, even though it does not uniquely differentiate the target from distractors (Burnham, 2007; Gibson & Kelsey, 1998). In support of this notion, Gibson and Kelsey (1998) found that when the target array was an onset of red letters in multiple locations (so neither onset nor color uniquely identified the target location, only the appearance of the target array itself), both red color singletons and onset cues captured attention when they preceded this array. This implies that attentional capture can be determined by features that define the target array onset, rather than target location within the array. For the present experiment, this displaywide contingent orienting framework therefore correctly predicts the observed cuing produced by green cues that did not match the red-defined control set in Experiment 1. This is because these green cues shared two properties with the appearance of the target array: abrupt onset and the color green. That is, the target display was revealed via an onset, and all cues, both red and green, were unique onsets (i.e., they appeared alone in the array). Thus, with a control set for onsets, both types of cues (red and green) should have produced some attentional capture. Similarly, there could be green present (one of the nontarget colors) in the target display, and so the green cues could have captured attention because they shared this feature with the target array. Considered within the displaywide contingent orienting hypothesis framework, then, even the residual cuing produced by green cues here would be consistent with exclusively top-down control over spatial attention, that is, without requiring an explanation based on stimulus-driven capture and rapid disengagement. We address these possibilities in Experiment 3. The purpose of Experiment 2, however, was to replicate with a green-defined control set the effects obtained in Experiment 1.
Experiment 2
Experiment 1 demonstrated that physical color that is part of the representation of a word that is currently active in the participant’s mind can preferentially influence the allocation of attention in space. Specifically, red-colored cues produced greater cuing than green-colored cues when participants were engaged in a search for the semantically defined target (i.e., for the word “red”). The purpose of Experiment 2 was to ensure that this pattern of results was not dependent on the particular choice of red as a target color and therefore green as the non-control-set-matching color feature. In addition, Experiment 1 unexpectedly revealed evidence for attentional capture by stimuli that did not match the observer’s top-down control set, contrary to the contingent-capture framework (Folk et al., 1992). Thus, an additional purpose for Experiment 2 was to assess the reliability of cuing effects for cues that did not match the top-down control set. To do this, we now made the target the word “green” in the semantic condition and a green-coloured stimulus in the featural condition, with red the non-target-matching cue word (semantic condition) or color (featural condition). Furthermore, in Experiment 1, the color and word (green), against which cuing for red was contrasted, was sometimes present as a distractor in the target array. That is, the word “green” was a possible distractor option in the semantic condition, and the color green was a possible distractor color in the featural condition, whereas here the word and color red were eliminated as an option from the target array.
Participants
Twenty-one (11 female) undergraduate psychology students (Mean age = 19.43 years, SD = 1.72) at the University of Toronto participated in exchange for course credit. All participants reported normal color vision and provided written, informed consent prior to participation.
Stimuli
The stimuli were identical to those used in Experiment 1, with the following exceptions. In the semantic condition, all targets and distractors were black. The target word always said “green,” either in upper- or lowercase, and the distractors were selected from among the words teal, blue, pink, yellow, orange, and white. In the featural condition (control condition), the green-colored target was a randomly selected letter string that did not constitute a word. The distractors that appeared simultaneously with the target were colored pink, blue, and yellow, and were also random letter strings (although never the same as the target).
Procedure
The procedure was identical to that for Experiment 1, except now participants were searching for a target that was the word “green” (the semantic condition) or was green-colored (the featural condition).
Results and discussion
As before, trials on which response times to identify the target (as upper- or lowercase) exceeded 2.5 SD above the participant’s mean RT or were less than 200 ms were excluded from the analysis (average 1.73 % of trials excluded). Accuracy in identifying the target was high ( > 91 % for all combinations of target condition, cue color, cue-word meaning, and validity). Correct responses times were then used to compute cuing effects (response time for the invalid minus the valid condition; see Table 2 for these RTs). These cuing effects were then submitted to a 2 (Target Condition) × 2 (Cue Color) × 2 (Cue-Word Meaning) repeated-measures ANOVA (see Fig. 3). This revealed a significant main effect of cue color on cuing magnitude [F(1,20) = 41.45, p < .001, ηp 2 = .675], such that the average cuing for green-colored cues (M = 155 ms) was greater than that for red-colored cues (M = 22 ms). Conversely, neither the main effect of target condition nor of the meaning of the cue word was significant (ps >= .504 and ηp 2s <= .023). This indicates that cues that featurally embody a target color word produce greater cuing than those that do not match. In conjunction with the results of Experiment 1, this reveals that this effect is neither specific to a particular color word (red or green) serving as the target, nor the nonmatching color being present in the target array.

(a) Cuing magnitude (correct RT for invalid minus valid trials) in the semantic condition in Experiment 2, in which participants searched for the word “green” among other color-word distractors. (b) Cuing magnitude in the featural condition in Experiment 2, in which participants searched for a green-colored target among other-color distractors. Error bars in both graphs represent standard errors of the means
Furthermore, there was also a significant interaction between target condition and color [F(1,20) = 4.44, p = .048, ηp 2 = .182], whereas none of the other interactions were significant (ps >= .421 and ηp 2s <= .033). The source of the interaction between cue color and target condition was that the color contingent capture (difference in cuing between green and red cues) was larger in the featural (168 ms) than in the semantic condition (96 ms). This appeared to be partially owing to an order effect. That is, to assess the effect of order of block completion on the effect of cue color on attention in the presence of a semantically defined control set, we performed a 2 (Cue Color) × 2 (Cue-Word Meaning) ANOVA on cuing magnitudes in the semantic control-set condition, with order of block completion as a between-subjects variable. This revealed that there was a significant main effect of order of block completion [F(1,19) = 9.16, p = .007, ηp 2 = .325]; furthermore, the interaction between cue color and order of block completion approached but did not reach significance [F(1,19) = 3.95, p = .062, ηp 2 = .172] (none of the other interactions approached significance, Fs < 1.02, ps > .327, ηp 2s < .051). Although not statistically significant, given the trend toward an interaction between order of block completion and the effect of cue color, we conducted 2 (Cue Color) × 2 (Word Meaning) ANOVAs separately for those participants who completed each block type (featural vs. semantic control set). The only variable to change as function of block order was the effect of cue color: For those participants who completed the featural control-set condition first, there was a significant main effect of cue color in the semantic control-set condition [F(1, 10) = 13.22, p = .005, ηp 2 = .569], whereas for those participants who completed the semantic control set first, there was no main effect of cue color in the semantic control set condition (F < 1). For comparison, the nature of the effect of cue color on cuing magnitude was unchanged as a function of block order in the featural control-set condition (highly significant for both, ps <.002).
It is not clear why there was no effect of block order in the first experiment whereas there was here, but this effect of block order is likely the source of the weaker overall color contingent-capture effect in the semantic control-set condition. The fact that the semantically defined control set is susceptible to block order could be taken as evidence that it is a less robust attentional set than a featurally defined control set. Regardless, however, the influence of control set over the magnitude of cuing in the semantic condition was both substantial and statistically reliable, indicating that the physical color that matches the meaning of the word an observer is searching for is a more potent attentionally engaging stimulus than those stimuli that do not match.
In contrast to Experiment 1, in neither the featural nor the semantic control-set conditions in this experiment did cues that did not match the control set produce significant cuing (ts < 1.443, ps > .164). That is, there was no evidence for rapid disengagement of attention. However, one difference between Experiments 1 and 2 was the change in the control-set color, meaning that now the cues that did not match the control set were red, rather than green as they were in Experiment 1. It is possible that this change could account for absence of reliable cuing to the red cues here if green cues are intrinsically more salient, if stimulus-driven capture and rapid disengagement prevailed in Experiment 1. To our knowledge, however, no previous research has demonstrated that any particular color is more salient, in other words, more or less likely to produce contingent capture than another. Indeed, the very essence of contingent capture is that otherwise intrinsically salient stimuli (e.g., abrupt onset, motion) no longer capture attention when they do not match a control set. So it is not clear a priori why this change in control-set color should have had an effect.
Since bottom-up explanations did not offer a compelling explanation for the pattern of results across Experiments 1 and 2, we now turn to consider top-down control explanations. The present result could be considered consistent with the displaywide contingent orienting hypothesis, since now the color that did not match the control set (red) was no longer present as a distractor color in the target array and so the cue and target arrays no longer had this color feature in common. However, this framework would still predict that the fact that the cue is a unique onset should mean it should capture attention regardless of its color. The pattern of results in Experiment 2 was therefore more consistent with that predicted by standard contingent capture, in which only cues that share the property that defines the location of the target within the array capture attention (Folk et al., 1992). Most critically, however, the main purpose of this study was to establish the influence of a semantically defined control set and, specifically, whether color-matching cues would produce exogenous capture of spatial attention, an effect that was now robust across two separate experiments.
Experiment 3
The purpose of Experiment 3 was to resolve a question arising from the first two experiments: Why did the non-control-set matching cues produce reliable attentional capture in Experiment 1 but not Experiment 2? In order to address this, we need to better understand what drove the attentional capture in Experiment 1. There are two possible main explanations: stimulus-driven capture followed by rapid disengagement, or displaywide contingent orienting for onset and color. To disentangle these possibilities, we replaced the unique-onset cue with a color-singleton cue, such that now no particular location in the cue array was cued by unique onset. That is, the cue was either a red or green stimulus at one of the four locations (the cued location), and the other three locations (noncued locations) were occupied by neutral (white) stimuli. This means that even if participants had an onset-defined control set induced by this property predicting the onset of the target array, there was no longer a unique onset in the cue array to capture their attention. If the residual cuing in Experiment 1 was the result of displaywide contingent orienting for onsets, then this should be eliminated in the present experiment with the color-singleton cues, because there should not be any reliable cuing for cues that did not match the target-defined control set.
Furthermore, whereas Experiments 1 and 2 varied the presence or absence of the nonmatching cue in the target array, in Experiment 3 the nonmatching cue property was never included in the target array constant. Importantly, whereas Experiments 1 and 2 used different target-defining colors (red vs. green), Experiment 3 varied the color of the control set within-subjects in a single experiment. If the cuing produced by nonmatching cues in Experiment 1 (which was eliminated in Experiment 2) were due to salience differences, such that stimulus-driven capture was unique to green cues, then here in Experiment 3 this pattern should be observed for the non-control-set-matching cues when the target was defined by the color red (and thus the nonmatching cues were green), but not when it was defined by the color green (and thus the nonmatching cues were red).
In the previous experiments, the cues were words of different colors. There was no evidence in these experiments, however, that word meaning had any systematic effect or interaction with the semantically defined control set. Here, therefore, we replaced the word cues with squares. The target display still consisted of words, and the control set was still therefore semantically defined. The same overarching prediction holds: If cues that featurally embody a semantically defined control set can determine the location of attention in space, then the red-singleton cue should capture attention when the task is to identify the word “red” in the target display, whereas the green-singleton cue should capture attention when the task is to identify the word “green” in the target display.
Participants
Twenty-four (19 female) undergraduate psychology students (Mean age = 18.6 years, SD = 1.5) at the University of Toronto participated in exchange for course credit. All participants reported normal color vision and provided written, informed consent prior to participation.
Stimuli
The stimuli were identical to Experiment 2, with the following exceptions. In both the semantic and featural conditions, cues were colored squares occupying the “cued” location, with white squares occupying the other locations during the cue array (i.e., color-singleton cues). The red and green colors used in the experiment were matched for luminance using a photometer. The word and color “green,” which were used as distractors in Experiment 1, were replaced with the word and color “magenta” here.
Procedure
Participants completed four distinct blocks of the experiment, in which it was varied whether the participant’s task was to search for a word (semantic condition) or a color (featural condition), and within these conditions whether the target was defined as the word “red” or the word “green,” versus the color red or the color green. The 24 unique orders in which these blocks can be arranged were each assigned to 1 of the 24 participants. This means that order of block completion was fully counterbalanced. All other aspects of the procedure were identical to those used in the previous experiments.
Results and discussion
As before, trials on which response times to identify the target (as upper- or lowercase) exceeded 2.5 SD above the participant’s mean RT or were less than 200 ms were excluded from the analysis (average 1.91 % of trials excluded). Accuracy in identifying the target was reasonably high ( > 86 % for all combinations of target condition, cue color, cue-word meaning, and validity). Correct response times were then used to compute cuing effects (response time for invalid minus valid condition; see Table 3 for these RTs). These cuing effects were then submitted to a 2 (Target Condition) × 2 (Target Color) × 2 (Cue Color) repeated-measures ANOVA. This revealed a significant main effect of target color, such that cuing was on average greater with green targets (M = 53 ms) than with red (M = 18 ms) [F(1, 23) = 7.63, p = .011, ηp 2 = .249], but no significant main effects of either target condition (F < 1) or cue color [F(1,23) = 2.19, p = .152, ηp 2 = .087]. This main effect of target color was qualified by a significant interaction between target color and cue color [F(1, 23) = 20.91, p< .001, ηp 2 = .476], indicative of contingent capture. No other interactions reached significance (ps >= .2 & ηp 2s <= .070). This indicates that cuing depended on the relationship between the color of the target and the color of the cue, both when the target was differentiated from distractors by color, and when it was differentiated by semantics (see Fig. 4). Specifically, when the target was uniquely identified by the color red, then red cues captured attention whereas green cues did not, and when the target location was uniquely identified by the color green, then green cues captured attention but red cues did not. This replicates the core finding from Experiments 1 and 2; cues that embody the physical features of the concept to which the target word refers capture attention. It also extends on the previous experiments by showing that this effect generalizes to the circumstances in which the cues are geometric shapes, rather than words, and thus share little form similarity with the target.

(a) Cuing magnitude (correct RT for invalid minus valid trials) in the semantic condition in Experiment 3, in which participants searched for the words “red” and “green” among other color-word distractors. (b) Cuing magnitude in the featural condition in Experiment 3, in which participants searched for a red-colored and green-colored target among other-color distractors. Error bars in both graphs represent standard errors of the means
The use of the color-singleton displays in the present experiment eliminated any evidence for cuing from the cues that did not match the participant’s top-down control set (ts < 1). This indicates that the contingent nature of the attentional capture here was absolute: It determined the absence or presence of cuing, rather than merely modulating cuing magnitude. This absoluteness was not specific to either the red- or green-colored cues, suggesting that the cuing produced by green cues in the featural condition in Experiment 1 can be explained with a control set for onsets as predicted by the displaywide contingent orienting hypothesis, leading to the unique-onset cues capturing attention. It is possible that the fact that the nonmatching cue color (red) was eliminated as a distractor color from the target array in Experiment 2 reduced the amount of similarity between the nonmatching cues and the target-array onset, thereby reducing the reliability of the cuing for the green cues. Taken together, this means that all evidence for capture observed across these three experiments is consistent with either classic contingent capture and/or the displaywide contingent orienting hypothesis, without recourse to stimulus-driven explanations. Critically, this means that all the results observed in the present three experiments are consistent with exclusively top-down control over exogenous attentional capture.
General discussion
The results of the present three experiments converge on the conclusion that peripheral stimuli that instantiate the physical color of a semantically defined control set capture attention. That is, for example, when searching to identify an achromatic word, “green,” among distractors, physically green-colored cues capture attention, whereas red-colored cues do not. This is consistent with the notion of top-down influence of a control set: Anterior regions of the brain that have access to semantic and category-level content, via reentrant processing, influence which low-level features will exogenously orient attention. Despite decades of research on top-down control sets, this is, to our knowledge, the first demonstration that semantically defined targets determine which features capture attention, as predicted by the physiological mechanisms that would instantiate a top-down control set. This finding also complements the previous literature demonstrating that cognitive processing is sensitive to the association between physical color and semantic meaning (Connell, 2007; Richter & Zwaan, 2009; Simmons et al., 2007; Yee et al., 2012), but it also extends on it, by showing that this association exogenously affects the location of attention in space. We will now discuss the implications of our results for the field of visual attention, followed by their implications for the embodied cognition literature.
Our results extend on previous work demonstrating differential cuing for cues that match the physical properties of the target (Al-Aidroos et al., 2010; Ansorge & Heumann, 2003; Bacon & Egeth, 1994; Folk & Remington, 1998; Folk et al., 1994). That is, our results show that even more abstract associations, such as those associations between semantic targets and the stimuli that physically embody the meaning of these targets, also influence attention. Such a finding is consistent with other recent work showing that contingent capture also extends to the learned perceptual consequences of actions (Gozli, Goodhew, Moskovitz, & Pratt, 2013). This implies that the interaction between top-down attentional set and reflexive, bottom-up, exogenous orienting is flexible and far-reaching with regard to the properties that are capable of driving this interaction.
There are two major explanations for how top-down attentional sets are instantiated. The displaywide contingent orienting hypothesis (Burnham, 2007; Gibson & Kelsey, 1998) stipulates that participants adopt a top-down control set for the features that define the onset of the target array, rather than for the feature that identifies the target’s location within the array. This framework was able to predict the pattern for cuing produced by nonmatching cues across our experiments. However, it is important to point out that this mechanism did not appear to operate in isolation. For example, in Experiment 1, even though the displaywide contingent orienting hypothesis could explain why the green cues produced cuing when the target location was uniquely identified by the color red in the target array, there was still a substantial difference in the magnitude of cuing between the red and green cues, suggesting that a top-down control for the target-location-defining property was at play. Similarly, in Experiment 3, the displaywide contingent orienting hypothesis correctly predicted the absence of cuing for cues that did not match the control set, but the presence of a strong effect of the relationship between cue and target color (contingent capture based on color) could only occur if participants had a control set for the target’s color, in addition to, or instead of, a displaywide control set for onsets. Future research should work on delineating these two theoretical approaches to top-down control over exogenous attentional orienting.
Our results also have implications for the embodied cognition framework. The present findings unambiguously show that the association between a currently active semantic concept in the observer’s mind and the physical color of a stimulus in the environment reliably affects the allocation of attention in space. This dovetails nicely with the growing evidence for the relationship between concepts and attention (Chasteen, Burdzy, & Pratt, 2010; Connell, 2007; Goodhew, McGaw, & Kidd, 2014; Meier & Robinson, 2004). However, whereas these previous studies have shown that processing a single, centrally presented word could induce a subsequent shift of attention, here it was found that embodied stimuli in the visual scene could actually draw attention to their location in space. This is important given that attention serves as gatekeeper, preventing processing resources from being overwhelmed. The location of attention in space, therefore, is a critical determinant of what is processed, and ultimately what we are consciously aware of from the world around us.
Prior to this, one study examined the link between activation of a semantic concept and overt attention, but did so with auditory semantic stimuli. Huettig and Altmann (2011) presented participants with auditory object words, and examined to which of four pictures observers moved their eyes. It was found that participants were more likely to look at a target picture that was a particular physical color (e.g., a green blouse) after hearing a word for an object that prototypically has that particular color (e.g., “pea” = green) (Huettig & Altmann, 2011). However, in this paradigm, there was no specific task, in that participants were explicitly informed that they could look anywhere they wanted to on the screen. This means there was no disincentive to look at a particular image, and thus participants may have simply looked there without any strong underlying attentional orienting influences. The results of Huettig and Altmann (2011) cannot, therefore, be taken as evidence of exogenous or reflexive orienting of attention. Our results, in contrast, show that the effect of physical color does extend to exogenous attention in adaptation of classic contingent-capture paradigm (see Folk et al., 1992).
In conclusion, the congruency between a semantic concept activated in an observer’s mind and the physical color of an object in the visual scene reliably affects the location of attention in space. This is consistent with a neurophysiological instantiation of a top-down control set, according to which anterior regions with access to semantic content exert influence over posterior regions that encode more basic sensory information, and it is also consistent with an embodied cognitive perspective, according to which abstract cognitive processes are grounded in basic perceptual machinery.
References
Al-Aidroos, N., Harrison, S., & Pratt, J. (2010). Attentional control settings prevent abrupt onsets from capturing visual spatial attention. The Quarterly Journal of Experimental Psychology, 63, 31–41. doi:10.1080/17470210903150738
Ansorge, U., & Heumann, M. (2003). Top-down contingencies in peripheral cuing: The roles of color and location. Journal of Experimental Psychology: Human Perception and Performance, 29, 937–948. doi:10.1037/0096-1523.29.5.937
Bacon, W., & Egeth, H. (1994). Overriding stimulus-driven attentional capture. Perception & Psychophysics, 55, 485–496. doi:10.3758/BF03205306
Bar, M. (2003). A cortical mechanism for triggering top-down facilitation in object recognition. Journal of Cognitive Neuroscience, 15, 600–609. doi:10.1162/089892903321662976
Bar, M., Kassam, K. S., Ghuman, A. S., Boshyan, J., Schmidt, A. M., Dale, A. M., … Halgren, E. (2006). Top-down facilitation of visual recognition. Proceedings of the National Academy of Sciences, 103, 449–454. doi:10.1073/pnas.0507062103
Barsalou, L. W. (1999). Perceptual symbol systems. Behavioral and Brain Sciences, 22, 577–660. doi:10.1017/S0140525X99002149
Barsalou, L. W. (2005). Continuity of the conceptual system across species. Trends in Cognitive Sciences, 9, 309–311. doi:10.1016/j.tics.2005.05.003
Broadbent, D. E. (1958). Perception and communication. Elmsford: Pergamon Press.
Burnham, B. R. (2007). Displaywide visual features associated with a search display’s appearance can mediate attentional capture. Psychonomic Bulletin & Review, 14, 392–422. doi:10.3758/BF03194082
Chasteen, A. L., Burdzy, D. C., & Pratt, J. (2010). Thinking of God moves attention. Neuropsychologia, 48, 627–630. doi:10.1016/j.neuropsychologia.2009.09.029
Connell, L. (2007). Representing object colour in language comprehension. Cognition, 102, 476–485. doi:10.1016/j.cognition.2006.02.009
Connell, L., & Lynott, D. (2009). Is a bear white in the woods? Parallel representation of implied object color during language comprehension. Psychonomic Bulletin & Review, 16, 573–577. doi:10.3758/PBR.16.3.573
Desimone, R., & Duncan, J. (1995). Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18, 193–222. doi:10.1146/annurev.ne.18.030195.001205
Di Lollo, V. (2010). Iterative reentrant processing: A conceptual framework for perception and cognition (the blinding problem? No worries, mate). In V. Coltheart (Ed.), Tutorials in visual cognition (pp. 9–42). New York: Psychology Press.
Duncan, J., & Humphreys, G. K. (1989). Visual search and stimulus similarity. Psychological Review, 96, 433–458. doi:10.1037/0033-295X.96.3.433
Dux, P. E., Visser, T. A. W., Goodhew, S. C., & Lipp, O. V. (2010). Delayed re-entrant processing impairs visual awareness: An object substitution masking study. Psychological Science, 21, 1242–1247. doi:10.1177/0956797610379866
Folk, C. L., & Remington, R. (1998). Selectivity in distraction by irrelevant feature singletons: Evidence for two forms of attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 24, 847–858. doi:10.1037/0096-1523.24.3.847
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception & Performance, 18, 1030–1044. doi:10.1037/0096-1523.18.4.1030
Folk, C. L., Remington, R. W., & Wright, J. H. (1994). The structure of attentional control: Contingent attentional capture by motion, abrupt onset, and color. Journal of Experimental Psychology: Human Perception and Performance, 20, 317–329. doi:10.1037/0096-1523.20.2.317
Gallese, V., & Lakoff, G. (2005). The brain’s concepts: The role of the sensory-motor system in conceptual knowledge. Cognitive Neuropsychology, 22, 455–479. doi:10.1080/02643290442000310
Gibson, B. S., & Kelsey, E. M. (1998). Stimulus-driven attentional capture is contingent on attentional set for displaywide visual features. Journal of Experimental Psychology: Human Perception and Performance, 24, 399–706. doi:10.1037/0096-1523.24.3.699
Goodhew, S. C., McGaw, B., & Kidd, E. (2014). Why is the sunny side always up? Explaining the spatial mapping of concepts by language use. Psychonomic Bulletin & Review. doi:10.3758/s13423-014-0593-6
Gozli, D. G., Chasteen, A. L., & Pratt, J. (2013a). The cost and benefit of implicit conceptual cues for visual attention. Journal of Experimental Psychology: General. doi:10.1037/a0030362
Gozli, D. G., Goodhew, S. C., Moskovitz, J. B., & Pratt, J. (2013b). Ideomotor perception modulates visuospatial cueing. Psychological Research, 77, 528–539. doi:10.1007/s00426-012-0461-9
Huettig, F., & Altmann, G. T. M. (2011). Looking at anything that is green when hearing “frog”: How object surface colour and stored object colour knowledge influence language-mediated overt attention. The Quarterly Journal of Experimental Psychology, 64, 122–145. doi:10.1080/17470218.2010.481474
Jonides, J., & Yantis, S. (1988). Uniqueness of abrupt visual onset in capturing attention. Perception & Psychophysics, 43, 346–354. doi:10.3758/BF03208805
Kahneman, D. (1973). Attention and effort. New Jersey: Prentice-Hall.
Kastner, S., & Pinsk, M. A. (2004). Visual attention as a multilevel selection process. Cognitive, Affective, & Behavioral Neuroscience, 4, 483–500. doi:10.3758/CABN.4.4.483
Kveraga, K., Boshyan, J., & Bar, M. (2007). Magnocellular projections as the trigger of top-down facilitation in recognition. Journal of Neuroscience, 27, 13232–13240. doi:10.1523/jneurosci.3481-07.2007
Lamme, V. A. F., & Roelfsema, P. R. (2000). The distinct modes of vision offered by feedforward and recurrent processing. Trends in Neurosciences, 23, 571–579. doi:10.1016/S0166-2236(00)01657-X
Meier, B. P., & Robinson, M. D. (2004). Why the sunny side is up: Associations between affect and vertical position. Psychological Science, 15, 243–247. doi:10.1111/j.0956-7976.2004.00659.x
Most, S. B., Simons, D. J., Scholl, B. J., Jimenez, R., Clifford, E., & Chabris, C. F. (2001). How not to be seen: The contribution of similarity and selective ignoring to sustained inattentional blindness. Psychological Science, 12, 9–17. doi:10.1111/1467-9280.00303
Pascual-Leone, A., & Walsh, V. (2001). Fast backprojections from the motion to the primary visual area necessary for visual awareness. Science, 292, 510–512. doi:10.1126/science.1057099
Posner, M. I. (1980). Orienting of attention. The Quarterly Journal of Experimental Psychology, 32, 3–25. doi:10.1080/00335558008248231
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. Bouwhuis (Eds.), Attention & performance X (pp. 531–556). Hillsdale: Erlbaum.
Richter, T., & Zwaan, R. A. (2009). Processing of color words activates color representations. Cognition, 111, 383–389. doi:10.1016/j.cognition.2009.02.011
Sillito, A. M., Cudeiro, J., & Jones, H. E. (2006). Always returning: Feedback and sensory processing in visual cortex and thalamus. Trends in Neurosciences, 29, 307–316. doi:10.1016/j.tins.2006.05.001
Simmons, W. K., Ramjee, V., Beauchamp, M. S., McRae, K., Martin, A., & Barsalou, L. W. (2007). A common neural substrate for perceiving and knowing about color. Neuropsychologia, 45, 2802–2810. doi:10.1016/j.neuropsychologia.2007.05.002
Theeuwes, J. (1991). Exogenous and endogenous control of visual attention: The effect of visual onsets and offsets. Perception & Psychophysics, 49, 83–90. doi:10.3758/BF03211619
Theeuwes, J. (1992). Perceptual selectivity of color and form. Perception & Psychophysics, 51, 599–606.
Theeuwes, J. (1994). Stimulus-driven capture and attentional set: Selective search for color and abrupt onsets. Journal of Experimental Psychology: Human Perception and Performance, 20, 799–806. doi:10.1037/0096-1523.20.4.799
Theeuwes, J. (2004). Top-down search strategies cannot override attentional capture. Psychonomic Bulletin & Review, 11, 65–70. doi:10.3758/BF03206462
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. doi:10.1016/0010-0285(80)90005-5
Wolfe, J. M. (1994). Guided search 2.0: A revised model of visual search. Psychonomic Bulletin & Review, 1, 202–238. doi:10.3758/BF03200774
Wyatte, D., Curran, T., & O’Reilly, R. (2012). The limits of feedforward vision: Recurrent processing promotes robust object recognition when objects are degraded. Journal of Cognitive Neuroscience, 24, 2248–2261. doi:10.1162/jocn_a_00282
Yee, E., Ahmed, S. Z., & Thompson-Schill, S. L. (2012). Colorless green ideas (can) prime furiously. Psychological Science, 23, 364–369. doi:10.1177/0956797611430691
Author Note
This research was supported by an Ontario Government Postdoctoral Fellowship and an Australian Research Council (ARC) Discovery Early Career Researcher Award (DECRA DE140101734) awarded to S.C.G., Natural Sciences and Engineering Research Council (NSERC) discovery grants awarded to S.F. (261203-13) and J.P. (194537), and an Early Researcher Award and Canadian Institutes of Health Research (CIHR) grant awarded to S.F. (106436). The authors thank Nicole Fogel and Samuel Chen for assistance with the data collection.
Author information
Authors and Affiliations
Corresponding author
Additional information
Note
Two participants in Experiment 2 and two participants in Experiment 3 appeared to confuse the instructed assignment of the response keys (“z” and “/?” to upper- and lowercase), so their data were treated as if “/?” = lowercase and “z” = uppercase (which then meant that their accuracy was well above chance in all conditions).
Rights and permissions
About this article

Cite this article
Goodhew, S.C., Kendall, W., Ferber, S. et al. Setting semantics: conceptual set can determine the physical properties that capture attention. Atten Percept Psychophys 76, 1577–1589 (2014). https://doi.org/10.3758/s13414-014-0686-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-014-0686-3