
Abstract
In multisensory research, faster responses are commonly observed when multimodal stimuli are presented, as compared to unimodal target presentations. This so-called redundant-signals effect can be explained by several frameworks, including separate-activation and coactivation models. The redundant-signals effect has been investigated in a large number of studies; however, most of those studies have been limited to the rejection of separate-activation models. Coactivation models have been analyzed in only a few studies, primarily using simple response tasks. Here, we investigated the mechanism of multisensory integration underlying go/no-go and choice responses to redundant auditory–visual stimuli. In the present study, the mean and variance of response times, as well as the accuracy rates of go/no-go and choice responses, were used to test a coactivation model based on the linear superposition of diffusion processes (Schwarz, 1994) within two absorbing barriers. The diffusion superposition model accurately describes the means and variances of response times as well as the proportions of correct responses observed in the two tasks. Linear superposition thus seems to be a general principle in the integration of redundant information provided by different sensory channels, and is not restricted to simple responses. The results connect existing theories of multisensory integration with theories on choice behavior.
Similar content being viewed by others

Everyday perception simultaneously involves several senses. The sensory information relayed by different perceptual subsystems has to be integrated in order to take advantage of redundant and ancillary multisensory information, as well as to solve the problem of contradictory information. In speech perception, for example, lip reading can substantially improve the intelligibility of speech, especially in a noisy environment (Sumby & Pollack, 1954). Contradictory information from audition and vision, on the other hand, can evoke a percept presented neither verbally nor visually (McGurk & MacDonald, 1976).
Elementary multisensory perception is often studied with redundant signals from different senses—mostly audition, vision, and/or touch (Diederich, 1995; Giray & Ulrich, 1993; Miller, 1982, 1986). In redundant-signals experiments, the stimuli are presented either alone (unimodal conditions) or together (bimodal condition), and observers are usually asked to respond as quickly as possible to either signal (simple response task). A common observation is that response times (RTs) are, on average, lower in bimodal than in unimodal conditions. Different theoretical accounts can explain this so-called redundant-signals effect; these make different assumptions about the possible mechanism of integration of information from the different senses. The simplest form of multisensory “integration” for redundant signals is the separate- or parallel-activation account: Information from different sensory modalities is processed in separate channels, and the channel that first detects the stimulus triggers the response. According to this model, the redundant-signals effect is due to statistical facilitation; that is, RTs to redundant signals are, on average, lower because prolonged detection times in one channel are compensated for by the other channel (Raab, 1962).
Miller (1982, 1986) derived an upper bound for the redundancy gains that can be explained by separate-activation models. If the channel-specific processing time distributions are invariant across experimental conditions (i.e., context invariance; see, e.g., Luce, 1986), Miller showed that the cumulative response time distribution [CDF; F(t) = P(T ≤ t)] for redundant audiovisual (AV) stimuli can never exceed the sum of the CDFs for the unimodal auditory (A) and visual (V) stimuli:
If Inequality 1 (the “race model inequality”) is violated for any t, context-invariant separate processing is ruled out (see, e.g., Mordkoff & Yantis, 1991; Townsend & Nozawa, 1995, for a thorough discussion of alternatives). In multisensory studies on the redundant-signals effect, violations of Inequality 1 have often been reported (e.g., Diederich & Colonius, 1987; Miller, 1982, 1986; Mordkoff & Yantis, 1993).
In contrast to separate-activation models, coactivation models assume that information from different sensory systems is pooled into a common channel (e.g., Diederich, 1995; Miller, 1982, Appx. A; Miller, 1986; Miller & Ulrich, 2003; Schwarz, 1989, 1994). Detection is finished when activation in this common channel exceeds a certain level. Because coactivation models assume true intersensory facilitation rather than statistical facilitation, they can explain redundancy gains that exceed the upper bound imposed by the race model inequality (see Colonius & Townsend, 1997, for a theoretical framework of coactivation models).
A prominent framework of coactivation models is based on diffusion processes. The basic idea of diffusion models is that information accrual following stimulus presentation can be described by a noisy stochastic (diffusion) process in the presence of one absorbing barrier (Diederich, 1995; Schwarz, 1994). As soon as this barrier is reached, a response is initiated (Fig. 1a). Diffusion models are also used to describe human two-choice decisions (e.g., Busemeyer & Townsend, 1993; Diederich, 1997). To this end, diffusion processes between two absorbing barriers are assumed, and absorption at one barrier corresponds to the choice of one of two alternatives (Fig. 1b). An important feature of diffusion models is that they predict not only the choice probability, but also the time that it takes to reach that decision. Also, trial-to-trial variability can be elegantly explained, because the accumulation process is inherently noisy. Diffusion models have been successfully demonstrated to explain data from experiments on memory retrieval (Ratcliff, 1978), lexical-decision tasks (Gomez, Ratcliff, & Perea, 2007), temporal-order judgments (Schwarz, 2006), numerical distance effects (Schwarz & Ischebeck, 2003), and decision making (Ratcliff & McKoon, 2008).

a Wiener process (μ = 0.6, σ 2 = 81) between two absorbing barriers (u = 100, –ℓ = –100) starting at X(0) = 0. The curves at the top and bottom represent the first-passage densities f u (t) and f –ℓ(t) for these parameters (on same arbitrary scale, for the purpose of comparison). The curves between the barriers represent random instances of the process. Due to positive drift, the probability of reaching the upper criterion first is greater than that of reaching the lower criterion. Absorption at either criterion corresponds to one of two response alternatives. b Wiener process (μ = 0.6, σ 2 = 81) between two absorbing barriers (u = 100, –ℓ = –100) starting at X(0) = 0, with changing drift (μ = 1.8) after time τ. The average position of a random process is displayed as a straight line to illustrate the increasing drift after τ. At time τ, a process may have already been absorbed or may still continue. The increasing drift affects the first-passage densities f u (t) and f –ℓ(t) after time τ. The position density for processes that are not absorbed prior to time τ is displayed vertically
In the present study, we examined the performance of a two-choice diffusion model to explain choice behavior in a redundant-signals task. To this end, we combined the modeling approaches for the redundant-signals experiment (Diederich, 1995; Schwarz, 1994) with two diffusion models that have been proposed to describe human two-choice decisions (Busemeyer & Townsend, 1993; Diederich, 1997; Ratcliff, 1978). We present a model that can explain multisensory integration in tasks that are more complex than simple responses, but also, more generally, behavior in two-choice decisions, if stimuli are presented with an onset asynchrony. In two ways, this is a generalization of existing models for choice behavior and the processing of redundant targets. First, choice models are generalized by adding a second stimulus component that is relevant for the decision and that is possibly presented with a stimulus asynchrony. Second, existing models of multisensory integration with redundant signals are generalized for two response alternatives, so that multisensory integration can be tested with more complex, and arguably more ecologically valid, tasks than the mere detection of a stimulus.
Diffusion superposition model
The existing diffusion superposition models (DSM) for the redundant-signals effect have been used to explain data from simple response tasks (Diederich, 1995; Schwarz, 1994), and, more precisely, tasks with one response alternative (Gondan, Götze, & Greenlee, 2010). In this model, the information accrual process is assumed to be a time-homogeneous diffusion process (i.e., a Wiener process). In a diffusion model for a binary choice response task, the absorbing barriers u and –ℓ represent the response criteria for the two response alternatives (Diederich, 1997; Ratcliff, 1978). Reaching one of the barriers corresponds to the choice between the possible alternatives (Busemeyer & Townsend, 1993).
In the context of the multisensory integration of audiovisual redundant signals, the channel-specific activity is described by diffusion processes with the parameters μ A, σ 2A and μ V, σ V 2 for the auditory and the visual channels, respectively. Those parameters denote the drift and variance of both processes. This process evolves within two absorbing barriers that represent the response criteria for the two response alternatives. In the unimodal conditions, only one modality contributes to the accumulation of evidence. In the bimodal condition, the contributions of both stimuli superimpose additively; thus, when stimuli are simultaneously presented, the drift is µ AV = µ A + µ V, and the variance is σ AV 2 = σ A 2 + σ V 2 + 2ρ AV σ A σ V. The parameter ρ AV represents the correlation between activation in the sensory channels (Miller, 1991). In bimodal conditions, the drift is thus increased, so that the absorbing barrier u > 0 is, on average, reached earlier than in the unimodal case. This is most obvious in the case of simultaneously presented redundant signals, but the same principle applies to redundant signals presented with a stimulus onset asynchrony (SOA). If the targets are presented asynchronously, the process changes to a Wiener process with a new drift and new variance when the second stimulus is presented (Ratcliff, 1980; Schwarz, 1994). Again, the new drift is the sum of the single stimulus drifts (additive superposition). The process is then a compound of a first part, in which only the first stimulus is active, and a second part, in which the underlying buildup of evidence is governed by both stimuli (Fig. 1b), as in the case of simultaneous presentation. A detailed description of the model is given in the Method section, and explicit expressions are provided in Appendix A.
Most publications on the redundant-signals effect have used complex tasks but tested for violations of the race model inequality only. For example, neurophysiological studies have made frequent use of more-complex tasks, such as the go/no-go task (e.g., “oddball detection”; e.g., Senkowski, Talsma, Grigutsch, Herrmann, & Woldorff, 2007; Teder-Sälejärvi, McDonald, Di Russo, & Hillyard, 2002), and demonstrated that the race model cannot explain the redundancy gain, but they have not tested alternative models that could explain the redundancy gains observed in the data. The limited number of studies that have actually tested alternative models have focused on simple response tasks (e.g., Diederich, 1995; Miller, 1982, Appx. A; Miller, 1986; Miller & Ulrich, 2003; Schwarz, 1994; but see Gondan et al., 2010).
In the present study, we investigated redundancy gains in choice and go/no-go tasks, and explicitly tested whether a coactivation model can account for the RTs and accuracy observed in these tasks. We then present a DSM with two absorbing barriers to test whether this model can account for the RTs and response accuracy observed in redundant-signals experiments with a go/no-go task (Exp. 1) and a two-alternative choice RT task (Exp. 2).
Method
In Experiment 1, participants made speeded responses in an audiovisual go/no-go task; in Experiment 2, they made speeded responses in a perceptual choice task. The visual stimuli were three different Gabor patches; the auditory stimuli were tones of three different frequencies. In addition to our go and no-go stimuli, we employed noninformative stimuli that contained no task-relevant information, but allowed for bimodal combinations of the stimuli without response conflicts. In Experiment 2, the experimental setup was largely the same as in Experiment 1, with a slight modification of the visual stimuli. The participants were given the task to choose between two response alternatives instead of refraining from responding on some trials.
Participants
Eight right-handed students from the University of Regensburg (all female; mean age 23.3 years) and one author participated in Experiment 1. Seven students (six female, one male; mean age 22.5 years) of the University of Regensburg and one author participated in Experiment 2. All of the participants had normal or corrected-to-normal vision and reported normal hearing. Students were naive with respect to the purpose of the experiment and the employed stimulus conditions, and they were either paid (€7/h) or received course credit for participation. Prior to the start of the experiment, the participants gave their informed consent, and the experiment was conducted according to the Declaration of Helsinki.
Apparatus and stimuli
The experiments took place in a light- and sound-attenuated room (Industrial Acoustics Company GmbH, Niederkrüchten, Germany), which was dimly illuminated from behind and above. The participants sat on a chair in front of the computer screen, which was placed on a desk at a distance of 60 cm. Loudspeakers were placed at the left and right of the screen. Stimulus presentation was controlled with a standard IBM-compatible PC running Presentation software (Neurobehavioral Systems, Albany, California).
In Experiment 1, the visual stimuli were Gabor patches (sigma = 0.8 deg, 1.8 cycles/deg) presented centrally on a gray background (18 cd/m2). These Gabor patches (26 cd/m2) were either horizontal (left-to-right grating) or tilted by 45 deg to the left or the right. In Experiment 2, we used three Gabor patches (sigma = 0.8 deg) with different spatial frequencies (1.1, 1.8, and 2.5 cycles/deg). Tones of three different frequencies were employed as auditory stimuli [370, 392, and 415.3 Hz at 35 dB(A), representing the tones F4#, G4, and G4# on a chromatic scale]. The Gabor patches and tones were presented alone (V, A) or together (AV). The intertrial interval (ITI) between two successive trials was randomly chosen from an exponential distribution with an expected value of 1,000 ms. To avoid either too-short or too-long ITIs, a fixed time interval (600 ms) was added to each randomly assigned ITI and the longest 5 % of intervals in the exponential distribution were truncated, respectively. Participants responded to these stimuli by pressing a response button placed at their dominant hand (Exp. 1) or buttons at both hands (Exp. 2).
Experimental tasks
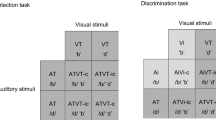
In Experiment 1, the participants were asked to respond as quickly as possible if the high-frequency tone (A+), the right-tilted Gabor patch (V+), or both together (A+V+) were presented (go stimuli). The participants had 1.5 s to respond before the program proceeded with the next trial. Alternatively, the participants were asked to withhold a response if the low-frequency tone (A–), the left-tilted Gabor-patch (V–), or both together (A–V–) were presented (no-go stimuli). To avoid response conflicts in the bimodal stimulus conditions, the go-stimulus components were never presented together with no-go components (Table 1). Instead, we combined go and no-go components only with an intermediate-frequency tone (A0) or a horizontal Gabor patch (V0). These were regarded as noninformative or neutral stimuli, since they contained no information for the decision of whether to press the button or withhold a response in a given trial (see Grice, Canham, & Boroughs, 1984, for a similar experimental setup). Critically, noninformative stimuli with go targets were presented with the same probability as noninformative stimuli paired with no-go stimuli (Table 1). All bimodal go stimuli were therefore either redundant (e.g., high-pitch tone and right-tilted Gabor patch) or nonredundant (a visual or auditory noninformative stimulus together with an auditory or visual go stimulus: A+V0 or A0V+). Together with the corresponding no-go trials (A–V–, A–V0, and A0V–) and four unimodal conditions (A+, V+, A–, and V–) there were ten different target conditions (cf. Table 1). Regardless of redundancy, bimodal stimuli consisted of one visual and one auditory stimulus component. All bimodal combinations V(τ)A were presented with the following SOAs: V33A, V67A, V100A, AV, A33V, A67V, and A100V (e.g., A67V means that the tone preceded the Gabor patch by 67 ms). In the following presentation, negative τ shall denote conditions A(τ)V.
In Experiment 2, participants were asked to choose as quickly as possible which of two buttons to press, depending on the stimulus. They should press the left button if a low-spatial-frequency Gabor patch (VL) or a low-frequency tone (AL) was presented. If the high-spatial-frequency Gabor patch (VR) or the high-frequency tone (AR) was presented, the participant should press the right response button. As in Experiment 1, left-response stimulus components were never combined with right-response stimulus components, but on some trials with noninformative stimulus components instead. The target stimuli (AL, VL, AR, and VR) were combined with Gabor patches (V0) or tones (A0) of intermediate frequency that were not associated with any alternative, and all combinations were equally likely. Bimodal stimuli for each side were either redundant (ALVL or ARVR) or contained either a noninformative auditory stimulus (A0VL or A0VR) or a noninformative visual stimulus (ALV0 or ARV0). Together with the unimodal conditions, we thus had ten different response relevance classes, five for each response alternative. Again, the intermediate stimuli (A0, V0) were regarded as noninformative, since they contained no information about the required response and were uncorrelated with the correct response. Due to SOA variation, bimodal stimulus trials were more frequent than unimodal stimulus trials, but the frequencies of trials with bimodal stimuli were the same for all possible combinations of response relevance (Table 1). The same SOA variation as in Experiment 1 was used for the bimodal stimuli.
Procedure
Each participant was tested in nine sessions, each of which lasted about an hour. At the beginning of each session, all six stimulus components were presented, and the participants were reminded of the relevance of the stimuli for the respective tasks. A single session consisted of 12 blocks, with a break after the first six blocks. Each block was preceded by a task instruction and contained one trial of each bimodal condition [V(τ)A in the go and no-go combinations] and one trial of each of the unimodal conditions, resulting in a total of 46 trials. For Experiment 1, each participant was tested in 102 blocks, so that the number of replications was 102 in all 46 stimulus conditions.
The procedure in Experiment 2 was roughly the same as in Experiment 1. Each block comprised one repetition of each condition [VL(τ)AL, VL(τ)A0, V0(τ)AL, VR(τ)AR, VR(τ)A0, V0(τ)AR, AL, VL, AR, and VR], and thus, also 46 trials. The trial frequencies can be deduced from Table 1, if one replaces “go” and “no-go” with “left” and “right”, respectively. Each condition had 108 replications. We ran a test block at the beginning of each experiment to ensure that the required task had been understood, especially the response relevance of our bimodal targets. In this test block, participants had more time to respond and were given visual feedback (“correct” or “false” displayed on the screen). The data from this block were discarded.
Tests of race model predictions
We tested the race model predictions on two grounds: the race model inequality (Eq. 1) and capacity considerations. The latter involved testing an index for process capacity C(t) that had been introduced by Townsend and colleagues (e.g., Houpt & Townsend, 2012; Townsend & Altieri, 2012; Townsend & Nozawa, 1995). The capacity index is a measure that provides a time-dependent assessment of processing capacity and can be calculated from the estimated cumulative hazard function H(t),
If the assumption of parallel first-terminating processing with unlimited capacity and independent racers holds, this measure (Eq. 2) equals unity. In other words, the independent race model serves as a benchmark to which the observed performance is compared. If C(t) > 1 (supercapacity), capacity increases with increasing load. According to the same reasoning, Townsend and Altieri (2012) recently generalized the capacity index for more-complex tasks, such as the two-choice task used in Experiment 2. Hence, this generalized assessment index A(t) was used as the capacity measure in Experiment 2.
In both experiments, erroneous responses might occur because the participant made guesses instead of informed responses. The test of the race model has been shown to be refined if the “twins” of these guessing times are subtracted from the RT distribution (Eriksen, 1988; Gondan & Heckel, 2008). We determined the “twins” separately for each SOA and response condition. For Experiment 1, this meant that for each response to a redundant V(τ)A no-go trial (guess), one response to a redundant V(τ)A go was cancelled out (set to infinity). The correspondence was established by choosing the response that was as close as possible to that of the guess, regarding its latency. For auditory unimodal targets, twins were determined by the auditory no-go condition, and for the visual unimodal target condition by the visual unimodal no-go condition. For condition V(τ)A, the race model then predicts
In Experiment 2, the RT distributions of one alternative were corrected by incorrect responses to the other alternative. Thus, for example, “left” RT distributions were corrected for (incorrect) “left” responses to stimuli for which a “right” response would have been correct.
Miller (1986) suggested quantifying the amount of violation of this inequality by the positive area Δ τ enclosed by the observed AV distribution and the sum of the observed A and V distributions. We pooled data from all sessions so that 108 responses were included in each CDF. The violation areas of all SOA conditions were measured and aggregated to a single violation area Δ by a weighted sum. The weights denote a triangular weighting function; we assigned weights of 1, 2, 3, 4, 3, 2, and 1 to conditions A100V, A67V, A33V, AV, V33A, V67A, and V100A, respectively (a “symmetric umbrella”; Gondan, 2009). This means, for example, that the violation area in condition A33V was weighted three times as much as that of condition A100V. Though many studies have reported redundancy gains to be most pronounced when the visual precedes the auditory signal by some moderate SOA (e.g., Miller, 1986; Senkowski et al., 2007), we used a symmetric function because according to the average RTs to unimodal A and V trials, we expected violations of the race model inequality to be most pronounced in the synchronous stimulus presentation condition. We then applied Miller’s (1986) bootstrap test to assess whether the violation area for a given participant reflected coactivation or was due to sampling error. Bootstrap samples of the unimodal RTs were drawn from the observed RT distributions; bimodal RTs were bootstrapped from the distribution of minima of the unimodal RTs, adjusted for SOA and assuming a maximally negative channel correlation between A and V (Ulrich & Giray, 1986). In each simulation, the aggregate violation area Δ* was determined, and this simulation was repeated 10,001 times, resulting in a reference distribution of Δ under the race model assumption. The race model is significantly violated at α = .05 (one-tailed) if the observed Δ is greater than 95 % of the simulated Δ*.
The average amount of race model violation (supercapacity) was quantified by the capacity index (Exp. 1) and the assessment index (Exp. 2). The statistical significance of race model violations and supercapacity was tested at the group level using a permutation test (Gondan, 2010). For these tests, we used the 5th through 30th RT percentiles, in steps of 5 %. Since the respective indices should be one for all time points, under standard race model assumptions, the capacity estimates of the RT percentiles were aggregated using a T max statistic (cf. Gondan, 2010).
The diffusion superposition model with two absorbing barriers
Standard diffusion models on choice behavior assume that the information accumulation process can be described by a time-homogeneous diffusion process (i.e., Wiener process) X(t) between two absorbing barriers u and –ℓ. The process has drift μ and variance σ 2 > 0 and starts at X(0) = 0. Absorption at the upper barrier and the lower barrier corresponds to the mutually exclusive events C = 1 and C = 0, respectively. For redundant signals, additive superposition of channel activity is assumed: X AV(t) = X A(t) + X V(t), resulting in a new Wiener process with drift µ AV = µ A + µ V and variance σ 2AV = σ 2A + σ 2V + 2ρ AV σ A σ V. The decision time D corresponds to the first-passage time; that is, as soon as either barrier is reached, a response is produced. To predict the mean detection times and response accuracy, thus, six parameters are needed (–ℓ, μ A, σ 2A , μ V, σ 2V , and ρ AV). The upper barrier u can be fixed (e.g., at 100) because it is only a scaling parameter. Model predictions for mean and variance of detection time can be derived from the first-passage distributions and moments of a Wiener process between two absorbing barriers (e.g., Cox & Miller, 1968). Expressions for the expected values of D are summarized in Horrocks and Thompson (2004, their Eqs. 6–10), and those for the variance in Grasman, Wagenmakers, and van der Maas (2009, their Eq. 14). Reaching the upper criterion occurs with some probability P(C = 1), and the complementary event—that is, reaching the lower criterion—occurs with a probability of P(C = 0) = 1 – P(C = 1). Expressions for the probabilities of reaching the lower and upper criteria are also summarized in Horrocks and Thompson (2004, their Eqs. 5 and 9). It is commonly assumed (Luce, 1986) that the observed response time T is the sum of the signal detection D and condition-invariant residual processes M (e.g., finger movement). Thus, another parameter (μ M) is necessary, which represents the mean latency of all residual processes M (Townsend & Honey, 2007). The prediction of the RT variance requires two additional parameters—namely, the variance of the latency of residual processes (σ M 2) and the correlation between residual processes latency M and detection time D (ρ DM). The correlation parameter ρ DM did not substantially improve the model fits, so it was fixed at zero in the models presented.
With all parameters specified, the two-barrier model predicts mean RTs (i.e., E[T | C = 1] and E[T | C = 0]), variance (Var[T | C = 1] and Var[T | C = 0]) and response probabilities (P[C = 1] and P[C = 0]) in a go/no-go or a binary choice RT task. For stimuli presented with onset asynchrony τ, the probability of reaching the upper criterion first, P(C = 1 | τ), the expected value of the time of first passage E(T | C = 1, τ) and its variance Var(T | C = 1, τ), have to be calculated conditional on the SOA. The derivations of SOA-dependent expected values E(T | C = 1, τ) and E(T | C = 0, τ), of the variances Var(T | C = 1, τ) and Var(T | C = 0, τ) of the first-passage times, and of the probabilities P(C = 1 | τ) and P(C = 0 | τ) of reaching either barrier first are described in Appendix A. This two-choice diffusion model, even though it is able to predict also response accuracy, needs only one parameter more than the original DSM (Schwarz, 1994)—namely, the second absorbing barrier –ℓ. In the case of an unbiased model, the barriers are equidistant from the origin. On the other hand, by setting this parameter far apart from the origin (ℓ > > u), the probability of absorption at the upper barrier tends to unity, and the two-barrier model predictions for the expected value and variance of D correspond to those of the one-barrier DSM.
Test of the diffusion model
We employed the two-barrier model to predict mean and variance of go trials and the amount of incorrect responses observed in the no-go stimulus conditions of Experiment 1 and both response alternatives of Experiment 2. In a go/no-go task, the lower barrier is assumed to be implicit, because absorption at the lower barrier does not lead to an observable response. An observable response is only initiated if the upper barrier is hit. On this note, a false-positive response to a no-go stimulus corresponds to reaching the upper barrier u in a no-go trial (i.e., π = P[C = 1 | u, –ℓ, μ A–, σ A– 2, μ V–, σ V– 2, ρ AV]). To predict the mean and standard deviation of RTs of the nonredundant stimuli with a noninformative auditory or visual component, additional diffusion parameters were necessary for the noninformative components (μ A0, σ 2 A0 and μ V0, σ 2 V0 for the noninformative auditory and visual components, respectively). In order to obtain predictions for the number of false alarms in (redundant and nonredundant) no-go trials, diffusion parameters for these stimuli were also needed: μ A–, σ A– 2 for the auditory no-go component, and μ V–, σ 2 V − for the visual no-go component. Note that, contrary to the test of the race model inequality, no false alarms were removed from the set of observed RTs, because false alarms can be explicitly predicted by the model. This is a direct consequence of the noise in the diffusion processes, which is also responsible for trial-to-trial variation. With ρ DM set to zero, 16 parameters are needed to derive 69 predictions for the mean and variance of RTs of all go trials and the percentage of responses to no-go trials.
The model fit for Experiment 2 was analogous, except that we added two parameters for the residual process mean latency and its variance of the second response alternative (μ ML, σ ML 2). The parameter for the lower criterion turned out to be approximately the same as that for the fixed upper barrier in most participants of Experiment 2, so it was also fixed at –ℓ = –100, yielding equal decision criteria for left and right responses (unbiased model; Wagenmakers, van der Maas, & Grasman, 2007). This resulted in a model with 17 parameters to predict the mean and variance of RTs and the response accuracy of both response alternatives—that is, 138 predictions in total.
The model fits were assessed by a goodness-of-fit statistic that was the sum of squares of the normalized differences between the DSM model predictions and the observed data—that is, the observed mean and variance of RTs, as well as the observed response frequencies in no-go trials (Exp. 1) and for both response alternatives (Exp. 2):
Negative τ denotes conditions A(τ)V, and τ = ±∞ denotes the unimodal visual and auditory stimuli. Thus, the goodness-of-fit statistic X 2 = X 2 m + X 2 s + X 2 p was the unweighted sum of normalized differences between predicted and observed means and the standard deviations of RTs for go trials (Eqs. 4 and 5), plus the normalized differences between the predicted and observed response probabilities (Eq. 6). We fitted the model to the means and standard deviations of RTs and not to the complete distribution, because the distribution of residual processes M was not known. Fitting the first moments of this distribution, on the other hand, only required the first moments of the base time distribution, which we included as free parameters.
If the model holds, the goodness-of-fit statistics (Eqs. 4–6) asymptotically follow χ 2 distributions. Note that the distribution of the sum of Eqs. 4–6, though it is a sum of squared normalized differences, does not correspond to a standard χ 2 statistic, because the means (Eq. 4), variances (Eq. 5), and response accuracy (Eq. 6) are not independent. For Experiment 1, using the proportion of responses to no-go stimuli extracted the best information available from go and no-go trials, since the accuracy rate in go trials was at 100 % in most participants. However, in order to prevent implausible predictions for the numbers of correct responses in go trials, we included the percentage of responses in go trials as a side condition. Though the percentages of responses to go trials do not contribute to the X 2 statistics reported in Table 3 below, they were added as a further constraint in the fitting procedure. In order to fit the model to response frequencies predicted to be one or zero, the variance was calculated as if the response frequency were .01 or .99, respectively. In this way, we prevented the variance from becoming zero in the extreme cases. The functions were implemented in MATLAB (MathWorks, Natick, MA), and the parameters were estimated using the optimizer fminsearchbnd (downloadable from MATLAB Central) to search for the minimum X 2 value.
The diffusion race model with two absorbing barriers
The DSM can be directly compared to a diffusion race model (DRM). In the DRM, the assumption of time-homogeneous channel-specific diffusion processes is kept, but the combined activity X AV(t) does not correspond to X A(t) + X V(t). Rather, it is assumed that the first process to reach the criterion initiates the response—that is, a parallel independent race model. The resulting RT distribution is then a mixture distribution determined partly by the auditory and partly by the visual channel. The derivation is outlined in Appendix B. The DRM was fitted analogously to the DSM by minimizing the same goodness-of-fit statistic X 2—that is, the sum of Eqs. 4 to 6.
Experiment 1
In Experiment 1, participants made speeded responses in an audiovisual go/no-go task with redundant signals. Response latencies and task performance were measured and used to test whether separate-activation models or the diffusion superposition model could better account for the observed data.
Results
Response times and task performance
The SOA-dependent mean RTs exhibited the typical wing-shaped pattern, with the mean RTs to synchronous stimuli being lower than those to any stimuli presented with an SOA (Fig. 2, upper panel). Task performance, as measured by false alarms to no-go stimuli, varied substantially between participants. Four participants (i.e., 2, 3, 4, and 9) made very few errors. Responses to no-go stimuli were less than 10 % in these participants, regardless of the stimulus combination (redundant or nonredundant no-go) and SOA. In the remaining participants, we observed effects of SOA and the modality of the target stimulus component (A+V+, A0V+, A+V0) on the observed error rates in bimodal nonredundant trials (for participant-specific results, please see Supplemental Fig. 1 in the online supplemental materials). If the noninformative stimulus preceded the no-go stimulus, higher SOAs led to higher response frequencies. Error rates were also lower for bimodal redundant signals than for nonredundant signals, with no visible effect of SOA. The observed standard deviations were largely independent of SOA, but they differed between response conditions (bimodal redundant, bimodal nonredundant). A speed–accuracy trade-off was also evident: Regarding their mean RTs, Participants 1 and 8 were fastest, and both showed the highest error rates, which amounted to 30 % and more in some conditions. On the other hand, four participants (2, 3, 4, and 9) did not show any, or only very few, errors, and three of those four participants have the slowest mean RTs of all participants (i.e., Participants 2, 3, and 4). Participant 9 made very few errors together with relatively fast mean RTs. Errors (lapses) in go trials were rare, amounting to about 2 % for all participants, with the exception of Participants 2, who missed 9 % of the targets in one condition, and 4, who shows frequent misses (up to 15 %) in the auditory go conditions (unimodal and bimodal nonredundant targets).

Averaged mean response times and standard deviations of go trials (upper panel), as well as proportions of responses to go and no-go trials (lower panel), together with model predictions from the diffusion superposition model for all nine participants in Experiment 1. The curves represent averaged model predictions for unimodal/bimodal redundant, nonredundant auditory-target, and nonredundant visual-target stimulus conditions. Data from the redundant bimodal conditions and unimodal conditions are displayed as circles, and data from the bimodal nonredundant conditions with either visual or auditory noninformative stimuli are displayed as upward-pointing triangles or downward-pointing triangles, respectively. On the x-axis, conditions are ordered from left to right according to stimulus onset asynchrony, and error bars denote 95 % confidence interval based on averaged standard errors. Participant-specific data and model fits are available as online supplemental materials (Supplemental Fig. 1)
Tests of race model predictions
In a first analysis, we calculated the violation area Δ as the weighted sum of the violation areas of all SOA conditions (Gondan, 2009) and determined the participant-specific p values by the bootstrap procedure described in Miller (1986). The race model inequality was significantly violated in every single participant, thereby ruling out the classical race model (i.e., context-invariant parallel processing) as an explanation of the redundancy gains in the go/no-go task (Table 2).
In line with this finding, the capacity coefficient C(t) indicated supercapacity over a large range of t (Supplemental Fig. 2A). The group test for the capacity index C(t) at early t yielded significant supercapacity (T max = 7.96, T 0.95 = 2.27; p < .001). The individual time courses of processing capacity are available in the supplemental material (Supplemental Fig. 2A). Average violations of the standard race model inequality across all participants (cf. Mordkoff & Danek, 2011) are displayed in Supplemental Fig. 2B.
Diffusion superposition model
A diffusion superposition model with two absorbing barriers (u fixed at 100) and 16 free parameters was fitted to the mean RTs and variances of RTs in a go/no-go task (69 predictions in total). Figures that display participant-specific performance and DSM predictions are available as supplemental materials (Supplemental Fig. 1). Except for one participant, the model fit was acceptable to excellent in all participants. The diffusion superposition model captured all aspects of the go/no-go data well. This was primarily the wing-shaped pattern of the SOA-dependent mean RTs (Fig. 2 circles) in the redundant-signals conditions. Additionally, the model had to explain the data of the nonredundant bimodal conditions with a noninformative stimulus. This included the rising mean RTs in the nonredundant noninformative stimulus-first conditions (Fig. 2; auditory targets shown by upward-pointing triangles, visual targets by downward pointing triangles). Responses to redundant no-go stimuli were rare (lower panel of Fig. 2; circles). Responses to no-go stimuli accompanied by noninformative stimuli were more frequent in most participants (e.g., Participants 1, 4, 5, 6, 7, and 8; see Supplemental Fig. 1) and were generally increased with the delay of the no-go stimulus (Fig. 2; auditory no-go stimuli shown by upward pointing triangles, visual no-go stimuli by downward pointing triangles). Standard deviations, which were rather constant across all conditions, were also predicted well by the model. This was also true for the numbers of correct responses in all go conditions, which attained 100 % in most participants and conditions (Fig. 2, top of the lower panel). Only the model fit for the data of Participant 9 exhibited frequent deviations from the observed mean RTs and standard deviations, especially in the bimodal nonredundant conditions V+(τ)A0 and V0(τ)A+.
As can be seen in Table 3, the drifts of both noninformative stimulus components (μ A0, μ V0) were generally lower than those of the target stimulus components (μ A+, μ V+). The reverse is true for the drifts of the no-go stimuli (μ A–, μ V–), which were negative in all participants and generally below the noninformative target drifts. The parameter estimates for the lower barrier differed considerably from those for the upper barrier (100) in most participants, suggesting a response bias in those participants. This is also evident in estimates for drifts of the noninformative stimuli; when these were fixed to zero, the model fit was considerably worse. In three participants, the estimate for the lower barrier is farther away from the origin than that for the upper barrier (Participants 1, 5, and 7), and in five participants, the estimated lower barrier is closer to the origin than the upper barrier (Participants 2, 3, 4, 6, and 8).
Diffusion race model
The diffusion race model (DRM) failed to explain the mean and standard deviation of the observed RT (Fig. 3). This is evident in the conditions with noninformative stimuli, and especially in the comparison of redundant and unimodal conditions. One theoretical premise is that redundant targets’ mean RTs approach the unimodal RT means when the SOA becomes infinite. This is the case for both models, and the DSM nicely fits the observed mean RTs. However, the DRM clearly cannot explain the observed redundancy gain, even on the level of mean RTs.

Averaged mean response times and standard deviations of go trials (upper panel) and proportions of error responses on no-go trials (lower panel), together with averaged model predictions from the diffusion race model, for all nine participants in Experiment 1. The data are the same as in Fig. 2, but the model predictions are derived from the diffusion race model. The coding of conditions is the same as in Fig. 2
Like those for mean RTs, the DRM predictions for response frequencies in the nonredundant no-go conditions were overestimated (Fig. 3, lower panel). Thus, the observed mean RTs in go conditions with noninformative stimuli and the response frequency to no-go stimuli with the same noninformative stimuli were faster and more accurate, respectively, than those predicted by the DRM.
Discussion
The goal of Experiment 1 was to investigate the mechanism of integration in a redundant-signals experiment with a task more complex than a simple response task (e.g., Miller, 1986). For this purpose, we tested nine participants in a go/no-go task and asked them to respond as quickly as possible to predefined audiovisual target stimuli and to refrain from responding to no-go stimuli (Miller, 1982). A diffusion superposition model with two absorbing barriers was fitted to the means and variances of the RTs of 23 go conditions, as well as to the accuracy rates of 23 no-go conditions. The race model inequality was significantly violated in all participants; thus, the standard race model with independent channels and unlimited capacity does not seem to be a plausible candidate to explain the observed data. Likewise, the capacity coefficient (Townsend & Nozawa, 1995) indicated supercapacity across multiple time points in all participants. Processing was considerably faster than was predicted by standard parallel processing (race model), suggesting interactive channels or coactive processing. On the other hand, the diffusion superposition model with two absorbing barriers could explain the mean RTs, standard deviations, and accuracy rates well in all but one participant; the fit of the model was acceptable to excellent in most participants (Table 3). The parameter estimates for the lower barrier suggest that the participants adopted two different strategies in the go/no-go task. This is indicated by a response bias, represented by the relative distances of the upper and lower barriers from the origin. In Participants 5 and 7, the lower criterion is farther away from the origin than the (fixed) upper criterion. This, in turn, implies that those participants were prepared to respond and withheld the response if a no-go stimulus was presented. Participants 2, 3, 4, 6, and 8 seem to have chosen a different strategy: These participants expected a no-go stimulus and, thus, tended not to respond. The parameter estimates for the lower barrier lie closer to the origin than the upper criterion. The other two participants do not seem to have adopted a strategy with any response bias at all.
That the model explained the observed data has two interesting implications. First, we provided evidence that the same principles that govern multisensory integration in simple RTs also apply to a more complex task, such as the go/no-go task. To this end, we not only tested separate-activation models, but also an alternative model. This has been done before (Gondan et al., 2010), but the results of that study were subject to response conflicts that participants might have had problems resolving. We avoided response conflicts by adding nontargets: Rather than directly combining go and no-go audiovisual stimulus components, we used a third class of noninformative stimulus that could be presented with go and no-go stimulus components (Grice et al. 1984). Whereas in Gondan et al. (2010) it seemed that some participants resolved possible response conflicts by serial processing of the stimuli, the present results suggest coactive processing of the bimodal information when the provided information is free of response conflicts.
Second, using a DSM with two absorbing barriers allowed for description not only of the mean RTs and variance, but also of response accuracy in the go/no-go task (Rach, Diederich, & Colonius, 2011). This approach is not new (Gomez et al., 2007), but for the first time we used it to model the data of a go/no-go task in an experiment with redundant signals presented with an SOA. There is also a conceptual difference between our diffusion-modeling approach and that based on Ratcliff’s (1978) diffusion model. The models based on Ratcliff’s diffusion model allow for different modulations of the parameters—for example, a randomly distributed starting point or trial-to-trial variations in drift rates. The diffusion superposition models for the redundant-signals effect (Diederich, 1995; Schwarz, 1994) and the model that we outlined here currently do not allow for these variations. Instead, the diffusion process is divided into two (or possibly more) parts that may have different drifts and variances (see Fig. 1b). This approach is analytically tedious for two parts (Ratcliff, 1980; Schwarz, 1994) and requires numerical approximation for three or more subdivisions (Diederich, 1995), but it has proven to be successful in modeling the mean RTs and variances of a redundant-signals task with stimuli presented with onset asynchronies. Therefore, we followed the same approach in the derivation of the diffusion model with two absorbing barriers. Note that the application of such a compound model is not restricted to the redundant-signals task. Similar models have been used to explain temporal-order judgments (Schwarz, 2006) and could be applied to data from any experimental setup in which the rate of accumulation of information is expected to change at some time. This includes not only stimuli presented with an onset asynchrony, but any experimental setup with an interstimulus interval (e.g., a sequential comparison task or cueing experiments).
Experiment 2
In Experiment 2, participants made choice responses to audiovisual redundant targets in a speeded response task with two alternatives. Analogously to Experiment 1, we compared the model fits of the two diffusion models to the two-choice data and investigated process capacity in a two-choice task.
Results
RTs and task performance
The mean RTs of redundant stimuli exhibited a roughly symmetric wing-shaped pattern for both alternatives and in all participants (Fig. 4; circles in upper panels). Responses to the bimodal redundant targets (A+V+) were the fastest in all conditions. For the bimodal nonredundant stimuli (A+V0 and A0V+), a similar pattern was observed, but the shape was clearly asymmetric: The mean RTs of the conditions in which the noninformative stimulus followed the target stimulus were nearly constant across SOA conditions (Fig. 4; left half of upward-pointed triangles and right half of downward triangles). If the noninformative stimulus preceded the target by some SOA, we found an increase in mean RTs that was dependent on the SOA (right half of upward triangles and left half of downward triangles). Similar patterns can be observed for the numbers of correct responses. The frequency of correct responses was highest for the bimodal redundant and unimodal conditions (lower panels of Fig. 4, same condition-coding as above) and lower for the bimodal nonredundant signals. This was especially evident in conditions in which the noninformative stimulus was presented before the target stimulus. In some participants, task performance approached chance level with increasing SOAs between the noninformative and target stimuli. That is, some participants tended to guess the correct response, but nevertheless, the mean response latency increased with decreasing performance. Standard deviations, on the other hand, were largely constant across all conditions in all observers (Fig. 4, upper panels). Figures of the participant-specific results are available as supplemental materials (Supplemental Fig. 3).

Averaged mean response times and standard deviations of choice responses (upper panels) and the corresponding proportions of correct responses (lower panels), together with averaged model predictions from the diffusion superposition model for all eight participants in Experiment 2. For each observer, the left panels display the data and model predictions from one response alternative (left buttonpress), and the right panels display the data and model predictions from the other response alternative (right buttonpress). The curves represent the averaged model predictions for unimodal/bimodal redundant, nonredundant auditory-target, and nonredundant visual-target stimulus conditions. Data from the redundant bimodal conditions and unimodal conditions are displayed as circles, and data from the bimodal nonredundant conditions with either visual or auditory noninformative stimuli are displayed in contrasting ways (auditory target: upward-pointing triangles; visual target: downward-pointing triangles. On the x-axis, conditions are ordered from left to right according to stimulus onset asynchrony, and error bars denote 95 % confidence interval based on averaged standard errors. Participant-specific data and model fits are displayed in Supplemental Fig. 3
Tests of the race model predictions
The race model was tested for the redundant-stimulus conditions of both response alternatives by calculating the observed violation areas for each response alternative. The race model inequality for the redundant-stimulus conditions was significantly violated in six participants (i.e., 1, 3, 4, 5, 6, and 8), for either left or right responses. The remaining two participants do not show significant violations of the race model inequality in either left or right responses (Table 4).
In Experiment 2, the generalized assessment index (Townsend & Altieri, 2012) was used to estimate processing capacity. Again, under the canonical parallel independent race model A(t) = 1, we tested the assessment index against unity and focused on the correct and fast case. Contrary to the capacity index and standard race model tests, the generalized capacity index A(t) also explicitly takes into account the observed erroneous responses. This yields four cases, depending on response correctness (correct/incorrect) and response speed (fast/slow). In the correct and fast case, capacity was significantly greater than was predicted by parallel independent processing in the right-response conditions (T max = 5.66, T 0.95 = 2.26, p < .001), and, to a similar extent in the left-response conditions (T max = 5.69, T 0.95 = 3.05, p = .003). The assessment index showed supercapacity for either left or right responses in all but one participant (Participant 5), whose data for both response alternatives were largely consistent with parallel independent processing (Supplemental Fig. 4A). The lower boundary was violated only in Participant 3, whose left responses showed severely limited capacity. The time course of A(t), together with the upper and lower capacity bounds, are displayed in Supplemental Fig. 4A. Violations of the race model inequality for all participants are shown in Supplemental Fig. 4B. In general, race model inequality tests seem to be less sensitive than capacity analyses regarding violations of race model predictions for two-choice response data.
Diffusion superposition model
A two-barrier DSM was fitted to the mean RTs and proportions of correct responses for both alternatives. Except for Participant 5, the model fit was acceptable in all participants (see Fig. 4 and Table 5); some participants (i.e., 1 and 8) showed excellent model fit. Again, drift estimates are ordered; thus, drifts for stimuli requiring a left buttonpress direct the process to the upper barrier associated with this response. By contrast, drifts for stimuli requiring a right buttonpress tend toward the lower barrier, and parameter estimates for drifts for the noninformative stimuli are intermediate and vary around zero. The estimates for the lower barrier were very close to those for the upper barrier, so we fitted a model to the data in which the parameter –ℓ was fixed to –100. This unbiased model (Wagenmakers et al., 2007) fit approximately as well as the more liberal model in all but one participant (Participant 3). In this participant, the model fit of the more restrictive model was considerably worse, so we kept the liberal model. In the remaining participants (i.e., 2, 4, 6, and 7), the model fit well to the observed means and standard deviations of RTs and the proportions of correct responses. Systematic deviations between model predictions and the data were obtained in only one participant (Participant 5). This is evident in the proportion of correct responses, which are systematically overestimated by the model, and in the mean RTs of the unimodal stimuli, which are also overestimated (Supplemental Fig. 4). Further systematic deviations are observable in standard deviations; thus, for this participant the model had to be rejected. In the majority of participants, however, the model yielded a good approximation of the mean and variance of their RTs and numbers of correct responses in the perceptual-choice task.
Diffusion race model
By contrast, a race of independent diffusion processes (DRM) again failed to make adequate predictions in most participants (Table 5). Interestingly, the deviations were most pronounced in the response accuracy of the unimodal and redundant conditions, whereas predictions of the means and standard deviations of RTs were generally acceptable (Fig. 5, lower panel). In particular, the model was not able to explain response accuracy in the unimodal and redundant conditions for the right response alternative. The decrease in the accuracy rate of the unimodal visual-target condition (Fig. 5, lower panels) is not captured by the model, and the accuracy rates in the right-response redundant-target conditions are generally overestimated (Fig. 5, lower right panel). Because the mean RT and response accuracy for the right response alternative share the same parameters (μ A–, σ A– 2, μ V–, and σ V– 2), the responses are again either faster or more accurate than the DRM would predict. On a quantitative basis, the DRM fit worse than the DSM in all but one participant (Table 5), if one disregards Participant 5, whose data were not explained satisfactorily by either model. But in Participant 2, the model fit is better than that of the DSM, and in line with this observation, this is also the participant with the fewest violations of the race model inequality (Table 4). So, although the DRM is certainly only one instance of all possible race models, the fact that the same assumptions, differing only with respect to how information is integrated across channels, lead to such differences in quantitative and qualitative model comparisons further endorses the DSM.

Averaged mean response times and standard deviations of both response alternatives (upper panels) and proportions of correct responses for both response alternatives (lower panels), together with averaged model predictions from the diffusion race model (curves), for all eight participants in Experiment 2. The data are the same as in Fig. 4, and the same coding of conditions was used as in that figure
Discussion
The goal of Experiment 2 was to test separate-activation models and to test whether a diffusion superposition model with two absorbing barriers can also be applied to the mean and variance of RTs and the proportions of correct responses from a perceptual-choice task with redundant stimuli. To this end, we fitted the DSM to the data of eight participants. For the first time, we demonstrated that a DSM can describe well the mean RTs observed in a redundant-signals experiment with a perceptual-choice task. The DSM itself is rather restrictive; with only two additional parameters (relative to the model for the go/no-go task), we were able to derive accurate predictions for the mean and variance of RTs and the response accuracy of both response alternatives. Each diffusion parameter contributed to the predictions of mean RTs, standard deviations, and proportions correct, and, albeit using different stimulus parameters, the data from both response alternatives could be explained by a single model. This includes the observed decrease in performance with increasing SOAs in the nonredundant distractor-first conditions, which is also captured well by the model. Apart from one participant, the model fit was acceptable to excellent; thus, the model fits support the idea of an additive superposition of channel-specific activity also in a perceptual two-choice RT task. Given the stimulus materials and parameter estimates, it seems safe to conclude that the diffusion process in the DSM represents stimulus information, not stimulus energy. Hence, the same principles that underlie models for human decision making (Busemeyer & Townsend, 1993; Diederich, 1997) can be applied to a multisensory choice RT task in a redundant-signals experiment.
As an alternative model, we used a diffusion race model so as to compare the model fits of very similar models that differ with respect to the type of channel integration (parallel first-terminating vs. parallel coactive). With that in mind, it is striking to see the differences in the abilities of both models to make predictions for the observed data. We are aware that the DRM is just one of many possible race models, but it is in closest correspondence to the DSM, which in turn provides an adequate model fit. Apart from small deviations, both mean RTs and choice probabilities could be explained well by the DSM. The observed standard deviations of some conditions deviated from model predictions, probably because the estimate for standard deviation was highly susceptible to outliers. We also tested for violations of the race model inequality and found frequent violations, which seemed to be less pronounced in Experiment 2 than in Experiment 1. This result is in line with previous studies on the redundant-signals effect with choice RT tasks (e.g., Grice et al. 1984; Grice & Canham, 1990; Grice & Reed, 1992) For instance, the base time seems to be increased and more variable in the two-choice task (Townsend & Honey, 2007), as can be inferred from the DSM parameter estimates (Table 5). It has been demonstrated that base time can play a critical role in tests of race model violations (Townsend & Honey, 2007). However, using the assessment index as a benchmark for parallel independent processing, we found strong evidence for supercapacity—that is, violations of the parallel-independent-processing assumption. A tentative explanation would be that by taking response accuracy into account, the assessment index provided a more sensitive measure of parallel independent processing in a two-choice task than did the race model inequality. At any rate, erroneous responses seem to play a critical role when testing race model assumptions in a choice RT task. This can be seen in both the results of our capacity analysis and the model comparison of the DSM with the DRM, which differed mostly in their ability to explain the observed response accuracy. Altogether, parallel race models did not seem to provide a good explanation for the observed results in the majority of participants.
General discussion
Multisensory integration
The question of which cognitive architecture underlies the processing of redundant multisensory signals has been thoroughly addressed, sometimes with mixed results, and often on theoretical grounds. Although the empirical evidence seems to favor the coactivation account if tests of the race model inequality are used, ongoing discussion concerns whether the race model inequality is an appropriate tool to decide this question at all. Specifically, the validity of race model tests relies on the assumption of selective influence, which might or might not hold in a given experiment (e.g., Luce, 1986; Townsend & Nozawa, 1995). Alternative measures have been proposed to decide this question, but selective influence is a silent or explicit assumption in all of these measures.
In this study, we tested whether a model with a simple additive superposition of diffusion processes could also be applied to data from a redundant-signals experiment with tasks more complex than simple RT. For this purpose, we conducted two experiments with different response requirements: In Experiment 1, participants were asked to perform an audiovisual go/no-go task, and in Experiment 2, a multisensory choice task. So far, most studies on multisensory integration with go/no-go (Miller, 1982) and choice RT tasks have only tested for violations of the race model inequality (and frequently found them), but have not tested alternative models. On the other hand, explicit models for the redundant-signals effect have been presented and tested mainly using data from simple response experiments (Diederich, 1995; Miller, 1986; Schwarz, 1994). By contrast, most neurophysiological studies have made use of the go/no-go, or oddball, task and of choice RT tasks (e.g., Talsma, Kok, Slagter, & Cipriani, 2008; Woldorff et al., 1993). It has also been put into question whether the simple RT task is suitable to study certain multisensory aspects at all (Spence & Driver, 1997). We provided explicit model predictions for diffusion models based on channel superposition (DSM) or the race-type integration of information (DRM) for two-choice data obtained in multisensory redundant-signals experiments. The integration mechanism according to the DSM is the additive superposition of modality-specific activation. This is in line with studies that have reported approximately additive neural responses to bimodal stimuli (Stanford, Quessy, & Stein, 2005).
In the two experiments reported here, we not only employed unimodal and bimodal audiovisual stimuli, but also used noninformative (“neutral”) stimuli to combine the two tasks with a redundant-signals experiment (Grice et al. 1984). Apart from solving possible response conflicts, the noninformative stimuli gave rise to additional bimodal conditions. The bimodal conditions could therefore be either redundant or nonredundant, depending on whether a noninformative stimulus was presented in one channel or both channels contained targets. The results show that the DSM can make adequate predictions for those conditions, also under the assumption of additive superposition, if the respective stimuli are modeled with separate parameters (Tables 3 and 5). The estimates suggest that these stimuli were indeed conceived as neutral, since the drift rates for the noninformative stimuli were approximately zero in all participants. In general, the estimates were smaller in absolute values than the estimates for the two response-relevant stimuli (Exp. 2) or the go/no-go stimuli (Exp. 1). Therefore, the diffusion process of the DSM is likely to represent the response tendency associated with a stimulus, and not simply stimulus energy. This distinction is hard to make in simple RT tasks.
RT and response accuracy
One major advantage of two-choice diffusion models is the joint analysis of RT data (mean, variance, or distribution) and response accuracy (e.g., Rach et al., 2011). Most publications on the redundant-signals effect have involved testing the race model inequality—that is, RT distributions. But comparing the results of the two experiments reported here, we can observe a striking difference regarding response accuracy: In the choice experiment, the numbers of correct responses were roughly symmetric across the two response alternatives in all participants (Fig. 4 and Supplemental Fig. 3). In the go/no-go task, however, omissions in go stimuli (i.e., lapses) were far less frequent than false alarms to no-go stimuli (Fig. 2 and Supplemental Fig. 1). This could be explained by differences between the estimates for the lower barrier in both experiments. In the choice response task, the estimates for the lower barrier are identical or roughly identical to the fixed value of the upper barrier. Therefore, we further restricted the model so that both barriers had to be equally distant from the origin (i.e., u = ℓ = 100). This model fit nearly as well as the model with the lower barrier as a free parameter in all but one participant (Participant 3). However, in the go/no-go task, the estimates differed considerably in most participants. Therefore, a considerable response bias seemed to be present in Experiment 1 (go/no-go task), but not in Experiment 2 (binary choice task). Note that slightly different visual stimuli were used in the two experiments, which could confound comparison of the two experiments. However, a response bias in go/no-go but not in two-choice tasks as a reason for the different results in the two tasks has also been discussed earlier (Gomez et al., 2007). Also note the clear difference between the estimates for the channel correlation ρ AV in both experiments (Tables 3 and 5). In the DSM, the ρ AV parameter reflects the correlation of the buildup of evidence in the two modality-specific channels. Overall, fluctuations of attention might result in a positive ρ AV (Exp. 1) because the buildup of evidence in both channels is then either high in both channels (if the participant concentrates on the task) or low in both channels (if the participant is distracted). On the other hand, attentional fluctuations between channels might result in a negative channel correlation and negative ρ AV (see, e.g., the discussion in Miller, 1982): In certain trials, attention might be focused on the auditory modality, so that the buildup of evidence occurs faster in the auditory channel but slower in the visual channel, and vice versa when attention is focused on the visual channel. Especially in the more-demanding task of Experiment 2, the latter fluctuations might be prompted by unimodal stimuli (including bimodal stimuli with long SOAs) that lead to a single percept and direct attention to a certain modality. Except for the response criterion in Experiment 1, the estimates of most parameters for the DSM are largely consistent within each data set, even though the participants’ data varied considerably in both response latency and response accuracy (Tables 3 and 5, Supplemental Figs. 1 and 3). The greatest variations of parameter estimates are consequently found in the estimates of μ M and σ M 2. This implies that the variability between our participants (e.g., motivation) largely affected the residual, or motor, component.
Apart from the aforementioned asymmetry, error rates seem to be generally lower in the go/no-go task than in the two-choice task (Perea, Rosa, & Gómez, 2002). The DRM exhibited difficulties in explaining the error rate of Experiment 2, whereas the mean RTs were relatively well predicted by the model. As opposed to Experiment 1, responses were less correct (or slower) than the DRM predicted. In Experiment 2, lesser violations of the race model inequality were observed, and the DRM showed considerably better fits to the RT data. Response accuracy, however, could not be explained by the model. This fits nicely with the results of the test of the assessment index for supercapacity (Townsend & Altieri, 2012). The assessment index explicitly takes errors into account and reveals strong evidence for violations of parallel-independent-processing assumptions. In Experiment 1, on the other hand, frequent violations of standard parallel-processing assumptions were observed, and the DRM largely failed to predict RT measures. The DSM, on the other hand, could adequately describe both RTs and response accuracy and allowed for interesting implications. According to our data, a considerable increase in mean RTs and a decrease in response accuracy take place between bimodal redundant and bimodal nonredundant-signal trials, and the decrease is clearly more pronounced in the choice RT task. All of these aspects are captured well by the DSM. This demonstrates the necessity to analyze and, in this case, model response accuracy along with response latency (Rach et al., 2011; Townsend & Altieri, 2012).
Possible applications of the two-choice diffusion model
Using go/no-go and two-choice RT tasks, we demonstrated that the scope of the DSM (Schwarz, 1994) is not restricted to simple response tasks. This is not only interesting for modeling purposes; rather, two important implications arise from this result. First, many studies on multisensory perception make frequent use of the tasks that we used here—that is, the go/no-go, or oddball, task and the choice RT task. Second, and more importantly, the results of the bimodal response conditions support the notion that not energy summation, but the coactivation of response tendencies, accounts for the observed redundancy gains. According to recent neuroscience studies (e.g., Angelaki, Gu, & DeAngelis, 2009; Ma, Beck, Latham, & Pouget, 2006; Stanford et al., 2005), the additive superposition of channel-specific activation seems to be a more general principle in the human brain. With purely visual stimuli, several studies have also successfully linked behavioral diffusion models to neuropsychological data (e.g., Ratcliff, Cherian, & Segraves, 2003; Ratcliff, Philiastides, & Sadja, 2009). On this note, an accumulation of evidence in the prefrontal cortex seems to be consistent with the predictions of the two-barrier diffusion model, as has been confirmed with electroencephalographic data (Ratcliff et al., 2009).
Diffusion processes, thus, seem to be a promising approach to model a variety of human behaviors (Smith, 2000). This encompasses not only the integration of evidence from multisensory sources (Diederich, 1995; Gondan et al., 2010), but also attentional effects (Gondan, Blurton, Hughes, & Greenlee, 2011), memory retrieval (Ratcliff, 1978), masking effects (Ratcliff & Rouder, 2000), and simple two-choice decisions (e.g., Krajbich, Armel, & Rangel, 2010; Usher & McClelland, 2001). Here, we showed that the abundant research on diffusion models of decision making might be connected to diffusion models that account for the redundant-signals effect (Diederich, 1995; Schwarz, 1994). The same principles that underlie models for decision making in other experimental tasks, such as the numerical-distance effect or perceptual masking, are also applicable to model the redundant-signals effect with more-complex tasks than the simple RT task. Even more general, the model itself can be applied to any experimental data from a decision task in which the rate of information processing is assumed to change after some time τ.
References
Angelaki, D. E., Gu, Y., & DeAngelis, G. C. (2009). Multisensory integration: Psychophysics, neurophysiology and computation. Current Opinion in Neurobiology, 19, 452–458.
Blurton, S. P., Kesselmeier, M., & Gondan, M. (2012). Fast and accurate calculations for cumulative first-passage time distributions in Wiener diffusion models. Journal of Mathematical Psychology, 56, 470–475.
Busemeyer, J. R., & Townsend, J. T. (1993). Decision field theory: A dynamic-cognitive approach to decision making in an uncertain environment. Psychological Review, 100, 432–459. doi:10.1037/0033-295X.100.3.432
Colonius, H., & Townsend, J. T. (1997). Activation-state representation of models for the redundant signals effect. In A. A. J. Marley (Ed.), Choice, decision, and measurement: Essays in honor of R. Duncan Luce (pp. 245–254). Malwah, NJ: Erlbaum.
Cox, D. R., & Miller, H. D. (1965). The theory of stochastic processes. New York, NY: Wiley.
Diederich, A. (1995). Intersensory facilitation of reaction time: Evaluation of counter and diffusion coactivation models. Journal of Mathematical Psychology, 39, 197–215.
Diederich, A. (1997). Dynamic stochastic models for decision making under time constraints. Journal of Mathematical Psychology, 41, 260–274.
Diederich, A., & Colonius, H. (1987). Intersensory facilitation in the motor component? A reaction time analysis. Psychological Research, 49, 23–29.
Eriksen, C. W. (1988). A source of error in attempts to distinguish coactivation from separate activation in the perception of redundant targets. Perception & Psychophysics, 44, 191–193. doi:10.3758/BF03208712
Giray, M., & Ulrich, R. (1993). Motor coactivation revealed by response force in divided and focused attention. Journal of Experimental Psychology: Human Perception and Performance, 19, 1278–1291.
Gomez, P., Ratcliff, R., & Perea, M. (2007). A model for the go/no-go task. Journal of Experimental Psychology: General, 136, 389–413. doi:10.1037/0096-3445.136.3.389
Gondan, M. (2009). Testing the race model inequality in redundant stimuli with variable onset asynchrony. Journal of Experimental Psychology: Human Perception and Performance, 35, 575–579.
Gondan, M. (2010). A permutation test for the race model inequality. Behavior Research Methods, 42, 23–28. doi:10.3758/BRM.42.1.23
Gondan, M., Blurton, S. P., Hughes, F., & Greenlee, M. W. (2011). Effects of spatial and selective attention on basic multisensory integration. Journal of Experimental Psychology: Human Perception and Performance, 37, 1887–1897.
Gondan, M., Götze, C., & Greenlee, M. W. (2010). Redundancy gains in simple responses and go/no-go tasks. Attention, Perception, & Psychophysics, 72, 1692–1709. doi:10.3758/APP.72.6.1692
Gondan, M., & Heckel, A. (2008). Testing the race inequality: A simple correction procedure for fast guesses. Journal of Mathematical Psychology, 52, 322–325. doi:10.1016/j.jmp.2008.08.002
Grasman, R. P. P. P., Wagenmakers, E.-J., & van der Maas, H. L. J. (2009). On the mean and variance of response times under the diffusion model with an application to parameter estimation. Journal of Mathematical Psychology, 53, 55–68. doi:10.1016/j.jmp.2009.01.006
Grice, G. R., & Canham, L. (1990). Redundancy phenomena are affected by response requirements. Perception & Psychophysics, 48, 209–213.
Grice, G. R., Canham, L., & Boroughs, J. M. (1984). Combination rule for redundant information in reaction time tasks with divided attention. Perception & Psychophysics, 35, 451–463.
Grice, G. R., & Reed, J. M. (1992). What makes a target redundant? Perception & Psychophysics, 51, 437–442.
Horrocks, J., & Thompson, M. E. (2004). Modeling event times with multiple outcomes using the Wiener process with drift. Lifetime Data Analysis, 10, 29–49.
Houpt, J. W., & Townsend, J. T. (2012). Statistical measures for workload capacity analysis. Journal of Mathematical Psychology, 56, 341–355.
Krajbich, I., Armel, C., & Rangel, A. (2010). Visual fixations and the computation and comparison of value in simple choice. Nature Neuroscience, 13, 1292–1298.
Luce, R. D. (1986). Response times: Their role in inferring mental organization. New York, NY: Oxford University Press.
Ma, W. J., Beck, J., M., Latham, P. E., & Pouget, A. (2006). Bayesian inference with probabilistic population codes. Nature Neuroscience, 9, 1432–1438.
McGurk, H., & MacDonald, J. (1976). Hearing lips and seeing voices. Nature, 264, 746–748. doi:10.1038/264746a0
Miller, J. (1982). Divided attention: Evidence for coactivation with redundant signals. Cognitive Psychology, 14, 247–279. doi:10.1016/0010-0285(82)90010-X
Miller, J. (1986). Timecourse of coactivation in bimodal divided attention. Perception & Psychophysics, 40, 331–343. doi:10.3758/BF03203025
Miller, J. (1991). Channel interaction and the redundant-targets effect in bimodal divided attention. Journal of Experimental Psychology: Human Perception and Performance, 17, 160–169. doi:10.1037/0096-1523.17.1.160
Miller, J., & Ulrich, R. (2003). Simple reaction time and statistical facilitation: A parallel grains model. Cognitive Psychology, 46, 101–151.
Mordkoff, J. T., & Danek, R. H. (2011). Dividing attention between color and shape revisited: Redundant targets coactivate only when parts of the same perceptual object. Attention, Perception, & Psychophysics, 73, 103–112.
Mordkoff, J. T., & Yantis, S. (1991). An interactive race model of divided attention. Journal of Experimental Psychology: Human Perception and Performance, 17, 520–538. doi:10.1037/0096-1523.17.2.520
Mordkoff, J. T., & Yantis, S. (1993). Dividing attention between color and shape: Evidence of coactivation. Perception & Psychophysics, 53, 357–366.
Navarro, D. J., & Fuss, I. G. (2009). Fast and accurate calculations for first-passage times in Wiener diffusion models. Journal of Mathematical Psychology, 53, 222–230.
Perea, M., Rosa, E., & Gómez, C. (2002). Is the go/no-go lexical decision task an alternative to the yes/no lexical decision task? Memory & Cognition, 30, 34–45. doi:10.3758/BF03195263
Raab, D. H. (1962). Statistical facilitation of simple reaction times. Transactions of the New York Academy of Sciences, 24, 574–590.
Rach, S., Diederich, A., & Colonius, H. (2011). On quantifying multisensory interaction effects in reaction time and detection rate. Psychological Research, 75, 77–94.
Ratcliff, R. (1978). A theory of memory retrieval. Psychological Review, 85, 59–108. doi:10.1037/0033-295X.85.2.59
Ratcliff, R. (1980). A note on modeling accumulation of information when the rate of accumulation changes over time. Journal of Mathematical Psychology, 21, 178–184.
Ratcliff, R., Cherian, A., & Segraves, M. (2003). A comparison of macaque behavior and superior colliculus neuronal activity to predictions from models of two-choice decisions. Journal of Neurophysiology, 90, 1392–1407. doi:10.1152/jn.01049.2002
Ratcliff, R., & McKoon, G. (2008). The diffusion decision model: Theory and data for two-choice decision tasks. Neural Computation, 20, 873–922. doi:10.1162/neco.2008.12-06-420
Ratcliff, R., Philiastides, M. G., & Sajda, P. (2009). Quality of evidence for perceptual decision making is indexed by trial-to-trial variability of the EEG. Proceedings of the National Academy of Sciences, 106, 6539–6544. doi:10.1073/pnas.0812589106
Ratcliff, R., & Rouder, J. N. (2000). A diffusion model account of masking in two-choice letter identification. Journal of Experimental Psychology: Human Perception and Performance, 26, 127–140.
Schwarz, W. (1989). A new model to explain the redundant-signals effect. Perception & Psychophysics, 46, 498–500.
Schwarz, W. (1994). Diffusion, superposition, and the redundant targets effect. Journal of Mathematical Psychology, 38, 504–520. doi:10.1006/jmps.1994.1036
Schwarz, W. (2006). On the relationship between the redundant signals effect and temporal order judgments: Parametric data and a new model. Journal of Experimental Psychology: Human Perception and Performance, 32, 558–573. doi:10.1037/0096-1523.32.3.558
Schwarz, W., & Ischebeck, A. (2003). On the relative speed account of number–size interference in comparative judgments of numerals. Journal of Experimental Psychology: Human Perception and Performance, 29, 507–522. doi:10.1037/0096-1523.29.3.507
Senkowski, D., Talsma, D., Grigutsch, M., Herrmann, C. S., & Woldorff, M. G. (2007). Good times for multisensory integration: Effects of the precision of temporal synchrony as revealed by gamma-band oscillations. Neuropsychologia, 45, 561–571.
Smith, P. L. (2000). Stochastic dynamic models of response time and accuracy: A foundational primer. Journal of Mathematical Psychology, 44, 408–463.
Spence, C., & Driver, J. (1997). Audiovisual links in exogenous covert spatial orienting. Perception & Psychophysics, 59, 1–22. doi:10.3758/BF03206843
Stanford, T. R., Quessy, S., & Stein, B. E. (2005). Evaluating the operations underlying multisensory integration in the cat superior colliculus. Journal of Neuroscience, 25, 6499–6508.
Sumby, W. H., & Pollack, I. (1954). Visual contribution to speech intelligibility in noise. Journal of the Acoustical Society of America, 26, 212–215.
Talsma, D., Kok, A., Slagter, H. A., & Cipriani, G. (2008). Attentional orienting across the sensory modalities. Brain and Cognition, 66, 1–10.
Teder-Sälejärvi, W. A., McDonald, J. J., Di Russo, F., & Hillyard, S. A. (2002). An analysis of audio-visual crossmodal integration by means of event-related potential (ERP) recordings. Cognitive Brain Research, 14, 106–114. doi:10.1016/S0926-6410(02)00065-4
Townsend, J. T., & Altieri, N. (2012). An accuracy–response time capacity assessment function that measures performance against parallel predictions. Psychological Review, 119, 500–516.
Townsend, J. T., & Honey, C. (2007). Consequences of base time for redundant signals experiments. Journal of Mathematical Psychology, 51, 242–265.
Townsend, J. T., & Nozawa, G. (1995). Spatio-temporal properties of elementary perception: an investigation of parallel, serial, and coactive theories. Journal of Mathematical Psychology, 39, 321–359. doi:10.1006/jmps.1995.1033
Ulrich, R., & Giray, M. (1986). Separate-activation models with variable base time: Testability and checking of cross-channel dependency. Perception & Psychophysics, 39, 248–254.
Usher, M., & McClelland, J. L. (2001). The time course of perceptual choice: The leaky, competing accumulator model. Psychological Review, 108, 550–592. doi:10.1037/0033-295X.111.3.757
Wagenmakers, E.-J., van der Maas, H. L. J., & Grasman, R. P. P. P. (2007). An EZ-diffusion model for response time and accuracy. Psychonomic Bulletin & Review, 14, 3–22. doi:10.3758/BF03194023
Woldorff, M. G., Gallen, C. C., Hampson, S. A., Hillyard, S. A., Pantev, C., Sobel, D., & Bloom, F. E. (1993). Modulation of early sensory processing in human auditory cortex during auditory selective attention. Proceedings of the National Academy of Sciences, 90, 8722–8726.
Author note
Supported by Grant Nos. GO 1855/1-1 and GR 998/20-2 from the German Research Foundation (Deutsche Forschungsgemeinschaft). We also thank James Townsend, Durk Talsma and an anonymous reviewer for their help on an earlier version of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(PDF 1405kb)
Appendices
Appendix A – Predictions of the diffusion superposition model with two barriers
In order to derive predictions for the mean and the variance of RTs and the amount of responses in the SOA-condition, these have to be conditioned on the cases D ≤ τ D and D > τ (cf. Diederich, 1995; Ratcliff, 1980; Schwarz, 1994). Technically, this model is a generalization of the model with one absorbing barrier (Schwarz, 1994). Schwarz derived analytical solutions for mean RTs and standard deviations of asynchronously presented stimuli. Here, we outline the derivation of the prediction functions for expected time, variance and amount of passages at the upper barrier (C = 1) only, however, predictions for absorption at the lower barrier can be readily obtained using the same functions by changing the sign of μ and interchanging the barriers. It is assumed that for t ≤ τ, drift and variance of the process correspond either to μ A and σ 2A or to μ V and σ 2V , depending on which stimulus has been presented first. This process can reach one of the barriers within the interval 0 < t ≤ τ. If this has not happened before the onset of the second stimulus, both stimuli contribute to the process that then has drift μ A + μ V and variance σ 2A + σ 2V + 2ρ AV σ A σ V. For the probability of a first passage of the upper criterion P(C = 1), one has to calculate the sum of the first-passage probabilities of both cases:
The first summand can be easily obtained using the subsurvivor function S u (t|u, − ℓ, μ, σ 2) of passages through the upper barrier, which is presented by Horrocks and Thompson (2004):
where P u is the well-known probability of absorption at the upper barrier (e.g., Horrocks & Thompson, 2004, their Eq. 9; Ratcliff, 1978, his Eq. A8). There exist two representations for the subsurvivor function S u , both involving infinite series, but with different convergence behaviors. For speed reasons and effective control of the error tolerance, we calculate the terms needed to achieve a predefined error tolerance in advance and used whichever representation converged faster (Blurton, Kesselmeier, & Gondan, 2012). For the second summand of Eq. A1, one has to consider that at time τ the process starts anywhere within the range –ℓ < x < u. The density of x at the start of the second part of the process is given by an infinite series g(x, τ|u, − ℓ, μ, σ 2), which is the density of a Wiener process between two absorbing barriers (Cox & Miller, 1965, p. 222, their Eq. 78). A second representation of this function is also an infinite series (Cox & Miller, 1965, p. 222, their Eq. 81). Again, we implement both representations and use the representation that converge faster for any given x, τ, parameters and specified error tolerance. Then,
is the probability of a first passage at the upper barrier, given that no absorption occurred before τ. P x (C = 1) indicates that barriers u and –ℓ are replaced by the modified barriers (u – x) and – (ℓ + x) in P u = P (C = 1), making the expression dependent on x.
Likewise, the expected time of a first passage of a Wiener process between two barriers, given that absorption occurs at the upper barrier, is
The first part of the numerator in Eq. A2 is the expected value for the first passage of the upper barrier, given that the upper barrier is reached first and that this occurs before the second stimulus is presented. This is
where f u (t|u, − ℓ, μ, σ 2) is the subdensity of first passage times at the upper barrier, a computationally efficient MATLAB implementation of which can be found in Navarro and Fuss (2009). The integral can then be determined numerically.
For the second summand of the numerator in Eq. A2, one needs the expected value of D, conditioned on a first passage at the upper barrier. This term, E(D|C = 1), is also given in Horrocks and Thompson (2004, their Eq. 10). Again, the process does not necessarily start at the origin, but rather at any value within the interval –ℓ < x < u. Thus, one has to insert (u – x) and –(ℓ + x) instead of u and –ℓ, respectively, making E(D|C = 1) dependent on x. Then,
represents the second part of the numerator in Eq. A2. Again, E x (D|C = 1) denotes that E(D|C = 1) is used with the modified barriers (u – x), and –(ℓ + x) and represents the expected value of D for the second part of the process (t > τ). Thus, adding τ and numerically integrating over x from –ℓ to u yields the expected value of first-passage times for the case D > τ.
The variance predictions of RT are derived as follows: The variance is the second (central) moment minus the squared first moment, so only the derivation of the former is needed. Again, we condition of the two cases D ≤ τ and D > τ:
The first summand is derived similar to the first moment (Eq. A3), except that t 2 is multiplied with f(t) before numerical integration. The second summand of Eq. A5 is more problematic, but the derivation follows that for the first central moment (Eq. A4). Thus, the second central moment conditioned on a particular value of x is needed. Differentiating between the overall decision time D and the decision time D * for the second part after τ —that is, after the onset of the second stimulus—we obtain
The second moment E[(D*)2] can be derived from Grasman et al. (2009, their Eq. 14). As for the first central moment, Expression A6 with the modified barriers (u – x) and –(ℓ + x) instead of u and –ℓ, respectively, has to be multiplied with the density g(x, τ|u, − ℓ, μ, σ 2 ) and integrated over all values of x for –ℓ < x < u. Finally, the response time T is conceived as the sum of the decision time D and residual processes M, so the model predictions for the mean and variance of response time T are
Altogether, seven free parameters (μ A, σ A 2, μ V, σ V 2, ρ AV, –ℓ, and μ M) are needed to derive the predictions for mean RTs E(T), and nine parameters (i.e., ρ DM and σ M 2 added) are necessary for variance predictions Var(T). In the case of an unbiased model, the numbers of parameters reduce to six and eight parameters for mean RT and the variance of RT, respectively.
Appendix B – Predictions of a diffusion race model with two barriers
In this appendix, we outline the derivation of the diffusion race model tested in this study. This model is based on two diffusion processes (for auditory and visual channels), which are again assumed to be Wiener processes between two absorbing barriers. In accordance with standard race model assumptions, and in contrast to the DSM, detection is complete when either racer has finished, irrespective of the place of absorption. We assume independent racers (ρ AV = 0) because, for the general case with correlated racers A and V, the two-dimensional distribution of the first-passage time of a Wiener process between two absorbing barriers is needed, which we believe is yet unknown. For the special case of two uncorrelated racers, the density of the minimum of absorption time f D(t) [D = min(D A, D V)] is derived. This is a mixture distribution of the first-passage times of either racer, given that this racer finished first. Also, we have to consider two cases for each racer—that is, being absorbed at either the upper or lower barrier. Thus, we have four cases (cf. Townsend & Altieri, 2012). We consider one case (racer A finishes first at the upper barrier), and the remaining cases are treated analogously. The probability that racer A, denoted by the process X A(t), will win the race against racer V, denoted by the process X V(t), by absorption at the upper barrier (A ∩ C = 1) is
which reduces to
Given that processes X A and X V are terminated at first passage, there must not be a prior passage of either u or –ℓ. Therefore, the appropriate density function f u ,A(t) is used for racer A, and the survivor function S V(t) for racer V in Eq. B1. This yields the probability that racer A finishes the race in the case of two synchronously presented targets. For the mean RT prediction, one is usually not interested in which racer produced the response, but whether a response was a correct response. We therefore add the probabilities that either A or V produced a response at the upper barrier, whatever the assignment of the barriers is (correct or incorrect):
Addition is valid here, because we have mutually exclusive events. Then the expected value of D, conditional on upper absorption is
For variance predictions, we calculate the second central moment, which is the expression above, but with t in the integrals of Eq. B3 replaced by t 2. These expressions are the predictions of redundant signals without onset asynchrony. For SOA-dependent predictions, one simply has to shift the time scale of that process by some time τ. We define positive SOAs τ > 0 as the cases in which V is presented before A. Then, the expressions B2 and B3 above generalize to
and
The case of τ < 0 is derived likewise; in that case, all functions in Eqs. B4 and B5 with subscript V are delayed by τ. Clearly, predictions for response accuracy, mean RTs and variance in the unimodal cases are derived from the same expressions as in the coactivation model (DSM). Like the coactivation model, these results are moments of D, not T, so that residual parameters μ M and σ M 2 are added to mean detection time and variance predictions, respectively (cf. Eqs. A7 and A8).
Rights and permissions
About this article
Cite this article
Blurton, S.P., Greenlee, M.W. & Gondan, M. Multisensory processing of redundant information in go/no-go and choice responses. Atten Percept Psychophys 76, 1212–1233 (2014). https://doi.org/10.3758/s13414-014-0644-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-014-0644-0