
Abstract
Attentional orienting can be involuntarily directed to task-irrelevant stimuli, but it remains unsolved whether such attentional capture is contingent on top-down settings or could be purely stimulus-driven. We propose that attentional capture depends on the stimulus property because transient and static features are processed differently; thus, they might be modulated differently by top-down controls. To test this hybrid account, we adopted a spatial cuing paradigm in which a noninformative onset or color cue preceded an onset or color target with various stimulus onset asynchronies (SOAs). Results showed that the onset cue captured attention regardless of target type at short—but not long—SOAs. In contrast, the color cue captured attention at short and long SOAs, but only with a color target. The overall pattern of results corroborates our hypothesis, suggesting that different mechanisms are at work for stimulus-driven capture (by onset) and contingent capture (by color). Stimulus-driven capture elicits reflexive involuntary orienting, and contingent capture elicits voluntary feature-based enhancement.
Similar content being viewed by others

In a visual world with multiple stimuli, attention helps us select information relevant to our goal. However, in a goal-setting mode, our attention still would be attracted to irrelevant events. For example, an article on a Web page might have advertisements next to the article that involuntarily capture our attention. They could be banners, flickers, or colorful images. While irrelevant to the current goal—reading the article—they attract our attention nonetheless. This phenomenon is called attentional capture, where a task-irrelevant stimulus captures attention and distracts us from the task at hand.
Several theories propose explanations for the determinants of attentional capture. Some claim that attentional capture occurs as long as the stimulus’s properties fulfill a criterion, such as salience (e.g., Theeuwes, 1992, 1994), transience (Franconeri, Hollingworth, & Simons, 2005; Franconeri, Simons, & Junge, 2004), a new object (Jonides & Yantis, 1988; Yantis & Jonides, 1984), or animacy (Pratt, Radulescu, Guo, & Abrams, 2010). Others claim that the stimulus can capture attention only when it matches top-down control settings (e.g., Folk, Remington, & Johnston, 1992; Folk, Remington, & Wright, 1994). We categorize these theories into two classes: the stimulus-driven capture hypothesis and the contingent capture hypothesis. The major difference between them lies in whether top-down control is considered critical in attentional capture.
The stimulus-driven capture hypothesis is gaining in supporting evidence (Al-Aidroos, Guo, & Pratt, 2010; Franconeri et al., 2005; Franconeri et al., 2004; Liao & Yeh, 2011; Neo & Chua, 2006; Rauschenberger, 2003; Schreij, Owens, & Theeuwes, 2008; Schreij, Theeuwes, & Olivers, 2010a, b; Theeuwes, 1991, 1992, 1994, 1995, 2004; Theeuwes & Burger, 1998; Turatto & Galfano, 2000, 2001; Yantis & Jonides, 1984, 1990; Yeh & Liao, 2008, 2010). For example, Theeuwes (1992) demonstrated that when searching for a circle among multiple diamonds, an additional task-irrelevant color singleton slowed down the search, as compared with when no such color singleton appeared. It is inferred that the color singleton captures attention, hampering the search for a shape-defined target. More recently, Theeuwes (2010) reviewed evidence to support his view that the determinative role for initial priority of attentional selection requires mere stimulus salience and that top-down modulation occurs only afterward.
The contingent capture hypothesis, on the contrary—that top-down control determines initial attentional selection—also has accumulated support (Al-Aidroos, Harrison, & Pratt, 2010; Atchley, Kramer, & Hillstrom, 2000; Bacon & Egeth, 1994; Burnham, 2007; Chen & Mordkoff, 2007; Folk, Leber, & Egeth, 2002; Folk & Remington, 1998, 1999, 2006, 2008; Folk et al., 1992; Folk et al., 1994; Gibson & Kelsey, 1998; Leber & Egeth, 2006; Liao & Yeh, 2011). In a series of studies, Folk and colleagues showed that in a search for a red letter among white letters, only a task-irrelevant red distractor (but not an onset distractor) captured attention (e.g., Folk & Remington, 1998, 1999; Folk et al., 1992; Folk et al., 1994). When the target was the only letter in the display (defined by “onset” in this case), only the onset distractor captured attention (but not the color distractor). This pattern of results—that attentional capture occurs only when the distractor matches the target-defining feature—supports the contingent capture hypothesis, suggesting that top-down control takes a decisive role in attentional selection. Relevant to the discussion here, this hypothesis excludes the possibility of pure stimulus-driven attentional capture.
Our previous study, however, calls into question the generality of the contingent capture hypothesis, especially for visual onsets (Yeh & Liao, 2008). By applying the same spatial cuing paradigm as that used by Folk and his colleagues (e.g., Folk & Remington, 1998, 1999; Folk et al., 1992; Folk et al., 1994), we found that the contingent capture hypothesis holds true only when a fixed set size of four was used throughout the experiment. When participants viewed set sizes of four and eight in different blocks (Experiments 1–3), the task-irrelevant onset cue captured attention even when the target was defined by color in both set size four and eight conditions. Note that only four items were shown in the target display of the set size four condition, whereas participants have viewed target appearance in eight possible target locations in separate blocks. The result of attentional capture by onset found in this set size four condition suggests that it is the increase in the number of possible target locations, but not the actual items in the target display, that is critical for stimulus-driven capture by onset. The finding that onset can capture attention independently of top-down control settings, although depending on the number of potential target locations, cannot be explained by the contingent capture hypothesis (see also Schreij et al., 2008, 2010a, b; Yeh & Liao, 2010).
We further examined the effect of set sizeFootnote 1 (four vs. eight) on attentional capture and found that stimulus-driven capture by onset was more likely to be revealed in large than in small set size conditions (Liao & Yeh, 2011), due to an interactive process of stimulus-driven activation and top-down modulation that is modulated by set size. To isolate the stimulus-driven component, we added no-cue trials prior to the with-cue trials to make the first appearing cue unexpected and, thus, free of top-down modulation. Results showed that when a color target was searched for, the unexpected onset cue elicited a larger capture effect in the set size eight than in the set size four condition. This suggests that the more promising stimulus-driven capture by onset observed in large set size conditions can be at least partly attributed to the increase in the stimulus-driven component of the onset cue by increasing set size. The increased spatial uncertainty from the increase in the number of potential target locations in the large set size condition may lead the participants’ attention to be more sensitive to the stimulus-driven activation. Alternatively, top-down modulation may be less effective with increased set size.
Yet, it remains unclear whether other types of stimuli (e.g.,. salient color singletons) can also capture attention in the stimulus-driven manner—namely, independently of top-down control settings. Visual onset is shown to be unique in capturing attention (e.g., Jonides & Yantis, 1988; Yantis & Jonides, 1984), whereas it is controversial as to whether color is able to capture attention in a stimulus-driven manner (e.g., Cole, Kentridge, & Heywood, 2005; Theeuwes, 1992, 1995; Yantis & Egeth, 1999). Therefore, it is possible that only onset—but not other types of stimuli—can capture attention in a stimulus-driven manner. Considering the transient property of visual onset, it could be that the time window of the transient activation is narrow, thus leaving no room (if any) for top-down modulation. In contrast, an activation boosted by the sustained signal (such as color) has a longer latency and lasts longer, thus leaving more time to allow for an interaction with top-down modulation.
Therefore, we propose a hybrid account of attentional capture depending on the stimulus property of the cue: stimulus-driven capture for onset and top-down contingent capture for color. Our predictions differ from those based on either the stimulus-driven capture hypothesis or the contingent capture hypothesis. According to the stimulus-driven capture hypothesis, any salient stimulus captures attention, regardless of its match with top-down control settings; the prediction would be that both onset and color singletons capture attention as long as they are salient enough. According to the contingent capture hypothesis, however, only the stimulus that matches the same feature as the target captures attention; thus, the prediction is that onset or a color singleton captures attention only when the target is defined by onset or color, respectively. According to our hybrid account, onset is predicted to capture attention regardless of top-down setting (i.e., it is stimulus-driven), and color singleton is predicted to capture attention only when the target is defined by color but not onset (i.e., it is contingent on attentional control setting).
Experiment 1: Asymmetry of attentional capture by onset and color
In this experiment, we tested the hybrid account by using a spatial cuing paradigm with a crossed design of two (cue: onset or color) by two (target: onset or color) factors. In contrast to previous studies using a set size of four in the display (Folk et al., 1992; Folk et al., 1994), we used a set size of eight because it is more like our visual world, which is full of multiple stimuli, and because both stimulus-driven capture and contingnet capture can be better observed under this condition (Liao & Yeh, 2011). To better reveal the underlying mechanism of attentional capture, we manipulated the cue-to-target stimulus onset asynchrony (SOA) from 0 to 500 ms to learn how the capture effect changes with time. If the capture effect resulted from involuntary orienting toward the task-irrelevant cue, we would find the cuing effect only at short—but not long—SOAs.
Bacon and Egeth (1994) proposed that while a circle target is searched for among diamond nontargets, top-down control settings can be flexible: One can search either for the unique singleton in the display or for the predesignated shape feature. A salient task-irrelevant color singleton (e.g., red) could capture attention when the singleton detection mode (in the former case) was adopted, whereas it failed to do so when the feature search mode (in the latter case) was adopted (see also Leber & Egeth, 2006; cf. Theeuwes, 2004). Accordingly, the researchers questioned that attentional capture by a task-irrelevant salient singleton might be due to a contingency on singleton detection mode, rather than being purely stimulus-driven. In the present study, to prevent participants from adopting the singleton detection mode, in the color target display, one letter was red (i.e., defined as the target), one was an nonred letter (e.g., green), and the others were white; therefore, the display had two color letters. If attentional capture by onset or color singleton could be independent of the specific top-down control settings—the singleton detection mode—we would expect to find attentional capture by the salient singleton even with two color letters in the display.
Method
Participants
We recruited 128 undergraduates at National Taiwan University and divided them into four groups of 32 each to participate in the following four conditions consisting of cue (onset, color) and target (onset, color) factors: onset-cue/onset-target, onset-cue/color-target, color-cue/onset-target, and color-cue/color-target. All had normal or corrected-to-normal vision and were naïve as to the purpose of this study. All experiments reported in the present study were approved by the Committee of the Department of Psychology at National Taiwan University for the Protection of Human Subjects, and all the participants signed a consent form before the experiment.
Stimuli, design, and procedure
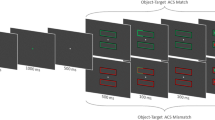
Stimulus displays were controlled by a personal computer with DMDX software (Forster & Forster, 2003) and presented on a 22-in. ViewSonic monitor (Professional Series P225f) with a refresh rate of 60 Hz. Participants sat at a viewing distance of 57 cm in a dark chamber. Each trial consisted of three kinds of displays: fixation, cue, and target displays (see Fig. 1). A gray dot [0.6° diameter; CIE (.311, .450), 1.40 cd/m2] against a black background served as the fixation point throughout the trials. In the fixation display, eight gray boxes (3.2° × 3.2°) were presented at the circumference of an imagery circle with a radius of 11.2°. The eight boxes were presented at 0°, 45°, 90°, 135°, 180°, 225°, 270°, and 315° relative to the horizontal line.

General procedure (not to scale) of this study. The fixation point and boxes were gray on a black background. Other black dots and signs were white, and the dark gray dots and letters were red. The light gray letter in the color target display was a nonred letter. Participants were required to discriminate whether the target sign was × or =. The onset cue and color were used in all experiments, and the neutral cue was used only in Experiment 3
In the onset cue display, one of the eight gray boxes was surrounded by four white dots [0.5° diameter; CIE (.290, .327), 49.94 cd/m2] at the positions of 0°, 90°, 180°, and 270°. In the color cue display, all eight gray boxes were surrounded by four white dots, except for one group of four white dots replaced by red, signaling the color cue. In the onset target display, one white character (2° × 2°), either × or =, was presented in one of the eight gray boxes. In the color target display, eight different letters were presented in each of the gray boxes. One letter was red [CIE (.633, .340), 5.26 cd/m2]; another was green [CIE (.300, .608), 12.45 cd/m2] in the onset-cue/color-target condition and purple [CIE (.292, .155), 1.05 cd/m2] in the color-cue/color-target condition.Footnote 2 All remaining letters were white.
For each group of participants, the experiment was conducted with five SOAs and the cue–target location was manipulated as being valid or invalid. Both the cue and the target letter were presented at the eight locations with equal probability, and the location where the target appeared was irrelevant to the cued location; 12.5 % were valid trials (same cue–target location), and 87.5 % were invalid trials (different cue–target location). Five SOAs were used: 0, 100, 200, 350, and 500 ms. The sequence of displays is shown in Fig. 1: fixation (1,000 ms), cue (50 ms), fixation (50, 150, 300, or 450 ms, for the 100-, 200-, 350-, or 500-ms SOA conditions), and target (50 ms). For the 0-ms SOA, the cue and the target letters were presented simultaneously for 50 ms, immediately following the initial fixation display.
Each SOA condition consisted of 128 trials for a total of 640 trials, presented in a random sequence. Twenty-four practice trials were conducted with randomly selected SOAs and cue–target locations before the formal experiment; these trials were not included in the analysis.
Each trial started with the participant pressing the space key. The target was equally likely to be × or =, and the task was to press the z key if the target character × was presented or to press the / key if = was presented. The participants were instructed to maintain fixation on the central fixation point throughout each trial. They were told that the cue did not provide any information about the target location and were requested to ignore the cue and respond to the target as quickly and accurately as possible. Written and oral instructions were provided, and participants took self-paced breaks during the experiment.
Results
Attentional capture was indexed by the validity effect: shorter reaction times (RTs) for valid trials than for invalid trials. RTs deviating more than three times the standard deviation were excluded from further analysis; among all the experiments reported in the present study, in no experiment did these trials exceed 1.9 % (M = 1.56 %). Mean correct RTs and error rates were subjected to a mixed-design ANOVA with cue type and target type as between-subjects factors and cue–target location and SOA as within-subjects factors.
Results for RTs are shown in Fig. 2. The mixed-design ANOVA showed main effects of cue type, F(1, 124) = 21.32, MSe = 1,167,156.19, p < .001, SOA, F(4, 496) = 226.86, MSe = 208,147.41, p < .001, and location, F(1, 124) = 35.42, MSe = 24,959.70, p < .001, but no main effect of target type, F(1, 124) = 0.17, MSe = 9,023.16, p > .6. The higher-order interactions were also significant, including all the two-way interactions (ps < .001) and all the three-way interactions (ps < .02) except the cue type × target type × SOA interaction, F(4, 496) = 0.73, MSe = 673.65, p > .5. The four-way cue type × target type × SOA × location interaction was also significant, F(4, 496) = 3.82, MSe = 1,904.77, p < .01.

Mean reaction times (RTs) for target discrimination in Experiment 1. Error bars represent one standard error of the mean. Asterisks indicate statistically significant differences between the valid and invalid locations (p < .05)
Further analyses of the four-way interaction showed that the three-way target type × SOA × location interaction was found only for the color cue, F(4, 496) = 6.55, MSe = 3,266.59, p < .001. For the onset cue, since the three-way target type × SOA × location interaction was not significant, F(4, 496) = 0.24, MSe = 119.28, p > .9, we collapsed the data over two target types and examined the two-way SOA × location interaction, F(4, 496) = 12.75, MSe = 6,358.98, p < .001, to investigate how the capture effect changed with SOA. The validity effect was found at 100- and 200-ms SOAs, F(1, 620) = 9.37, MSe = 5,060.53, p < .01, and F(1, 620) = 10.06, MSe = 5,431.47, p < .01, respectively, but not at 350- or 500-ms SOAs (ps > .4). A reversed validity effect—longer RTs at valid than at invalid locations—was found at the 0-ms SOA, F(1, 620) = 26.88, MSe = 14,515.92, p < .001.
For the color cue, whether the color cue captured attention depends on the target type. When the color cue preceded the color target, the validity effect was found at the 100-ms, F(1, 620) = 32.19, MSe = 17,381.72, p < .001, 200-ms, F(1, 620) = 40.97, MSe = 22,123.48, p < .001, 350-ms, F(1, 620) = 49.06, MSe = 26,496.06, p < .001, and 500-ms, F(1, 620) = 26.33, MSe = 14,220.56, p < .001, SOAs, but not at the 0-ms SOA, F(1, 620) = 1.94, MSe = 1,046.27, p > .1, substantiated by the two-way SOA × location interaction, F(4, 496) = 5.25, MSe = 2,618.66, p < .001. When the color cue preceded the onset target, the validity effect did not interact with SOA, F(4, 496) = 2.37, MSe = 1,181.91, p > .05. No validity effect was found at any SOAs, F(1, 124) = 1.73, MSe = 1,220.51, p > .1.Footnote 3
Analysis of the error rate data (listed in Table 1) revealed no speed–accuracy trade-off. The ANOVA showed significant main effects of SOA, F(4, 496) = 45.76, MSe = 0.09, p < .001, and location, F(1, 124) = 5.67, MSe = 0.01, p < .02, but no main effect of cue type, F(1, 124) = 0.28, MSe = 0.003, p > .5, or target type, F(1, 124) = 0.14, MSe = 0.001, p > .7. The two-way cue type × location, F(1, 124) = 18.78, MSe = 0.04, p < .001, and target type × SOA, F(4, 496) = 3.11, MSe = 0.01, p < .02, interactions were significant, but not the two-way cue type × target type, F(1, 124) = 0.002, MSe = 0.000, p > .9, cue type × SOA, F(4, 496) = 0.64, MSe = 0.001, p > .6, target type × location, F(1, 124) = 0.30, MSe = 0.001, p > .5, and SOA × location, F(4, 496) = 2.13, MSe = 0.003, p > .07, interactions. No three-way interactions were significant (ps > .2), except for the cue type × SOA × location interaction, F(4, 496) = 14.61, MSe = 0.02, p < .01. The four-way interaction was significant, F(4, 496) = 4.14, MSe = 0.01, p < .01.
Further analysis of the four-way interaction showed that the three-way target type × SOA × location interaction was found only for color cue, F(4, 496) = 3.87, MSe = 0.01, p < .01, but not for onset cue, F(4, 496) = 1.15, MSe = 0.00, p > .3. For the onset cue, similar result patterns were found regardless of target type. The reversed validity effect—higher error rates at the valid than at the invalid locations—was found at the 0-ms SOA, F(1, 620) = 43.48, MSe = 0.07, p < .0001. The validity effect —lower error rates at the valid than at the invalid locations— was found at the 100-ms SOA, F(1, 620) = 5.39, MSe = 0.01, p < .03, but not at any other SOAs (ps > .1), substantiated by the two-way SOA × location interaction, F(4, 496) = 13.33, MSe = 0.02, p < .0001. For the color cue, different patterns of results were found depending on the target type. In the color-cue/onset-target condition, the validity effect was found at the 0-ms SOA, F(1, 620) = 26.90, MSe = 0.04, p < .0001, but not at any other SOAs (ps > .5), substantiated by the two-way SOA × location interaction, F(4, 496) = 5.27, MSe = 0.01, p < .001. In the color-cue/color-target condition, the validity effects were found at all SOAs, F(1, 124) = 22.54, MSe = 0.05, p < .001.
Discussion
The overall results of this experiment indicate that the task-irrelevant onset cue captured attention involuntarily at short, but not at long, SOAs, regardless of whether the target was defined by onset or color. The capture effect cannot be explained by the participants’ adopting the singleton detection mode (Bacon & Egeth, 1994; Leber & Egeth, 2006), since we excluded this possibility by presenting two color letters in the target display. The impairment of target discrimination by the onset cue (i.e., the reversed validity effect) at the 0-ms SOA might result from visual masking, in that the cue was taken as the four-dot masker to the target (Enns & Di Lollo, 1997, 2000). In sum, the results suggest the existence of pure stimulus-driven capture by a transient stimulus, onset.Footnote 4
In contrast, the task-irrelevant color cue did not capture attention when the target was defined by onset. The result suggests that top-down control settings determine attentional capture by color; the color cue cannot capture attention independently of top-down control settings, as the onset cue does. Asymmetry of stimulus-driven capture by onset and color is illustrated: Only onset, but not color, is able to capture attention in the stimulus-driven manner.
To our surprise, the color cue captured attention when the target was defined by color, not only at short, but also at long SOAs. It is paradoxical that the color cue does not elicit reflexive involuntary orienting but is, instead, more like voluntary orienting, based on the prolonged capture effect through the 500-ms SOA (Muller & Rabbitt, 1989). Attentional orienting toward a task-irrelevant stimulus should be involuntary, since the cue is irrelevant to the target location and ought to be ignored. However, the color cue does share the target-defining feature, and in terms of the feature dimension, color is, in fact, relevant to the task (Yantis, 1993). Thus, attentional capture by color might result from feature-based attentional enhancement of the target-defining feature (e.g., Bichot, Cave, & Pashler, 1999; Cave, 1999; Wolfe, Cave, & Franzel, 1989). Alternatively, it could be due to the intertrial priming caused by featural similarity between repeated trials (Belopolsky, Schreij, & Theeuwes, 2010). In any case, our results suggest that the color cue elicits voluntary orienting instead of involuntary orienting, as the onset cue does.
Experiment 2: Stimulus-driven capture
In Experiment 1, we mixed the 0-ms SOA condition together with the other SOA conditions. One may argue (especially the proponent of the contingent capture hypothesis) that the findings of stimulus-driven capture by onset might have been caused by the addition of the 0-ms SOA condition, in which the cue masked the appearance of the target—as shown by the results of the 0-ms SOA for the onset cue. Since the cue sometimes masked the target, the participants might have been confused as to whether the target was presented and, thus, adopted a search strategy of paying attention to the cued location. To exclude this possibility, the 0-ms SOA condition was removed in this experiment. We selectively used two SOAs—200 and 800 ms—to examine the capture effect. Only the conditions in which the cue and the target did not match—namely, the onset cue followed by the color target and the color cue followed by the onset target—were conducted, since these were critical in examining the mechanisms of stimulus-driven capture. Stimulus-driven capture by onset, but not color, would be expected to be observed in the short (i.e., 200-ms) but not long (i.e., 800-ms) SOA condition if stimulus-driven capture is genuine and not induced by the 0-SOA masking condition used in Experiment 1.
Method
Participants
Another group of 64 undergraduate students at NTU, as described before, participated in Experiment 2. Participants were randomly assigned to two conditions: onset-cue/color-target and color-cue/onset-target.
Stimuli, design, and procedure
The stimuli, design, and procedure were the same as in Experiment 1, with the following exceptions. First, only the onset-cue/color-target and color-cue/onset-target conditions were conducted. Second, only two SOA conditions (200 and 800 ms) were conducted (the duration of the fixation display after the cue display was 150 and 750 ms, respectively). Finally, the different SOA conditions were conducted in a block design rather than a mixed design, as in Experiment 1. The order of the two SOA conditions was counterbalanced across participants.
Results and discussion
Results for RTs are shown in Fig. 3. Mean correct RTs were subject to separate repeated measures ANOVAs with SOA and cue–target location as within-subjects factors for the two conditions. In the onset-cue/color-target condition, neither the main effect of SOA, F(1, 31) = 3.98, MSe = 4,485.89, p > .05, nor that of location, F(1, 31) = 1.33, MSe = 621.77, p > .2, was significant, whereas the two-way SOA × location interaction was significant, F(1, 31) = 4.56, MSe = 2,005.92, p < .05. Further analysis showed the validity effect at 200-ms SOA, F(1, 62) = 7.98, MSe = 6,245.63, p < .01, but not at 800-ms SOA, F(1, 62) = 0.31, MSe = 246.18, p > .5. By contrast, no effect was found in the color-cue/onset-target condition (Fs < 3, ps > .1). For error rates (Table 1), no effect was found in either condition (Fs < 3, ps > .09).

Mean reaction times (RTs) for target discrimination in Experiment 2. Error bars represent one standard error of the mean. Asterisks indicate statistically significant differences between the valid and invalid locations (p < .05)
The results replicated our previous findings (Experiment 1; see also Yeh & Liao, 2008) that an onset cue captured attention when a color target was searched for, whereas a color cue did not capture attention when an onset target was searched for. Asymmetry of stimulus-driven capture by onset and color is again demonstrated here. The onset cue led to a robust capture effect at short—but not long—SOAs in two experiments with various manipulations, suggesting that attentional capture by onset is indeed stimulus-driven. However, color cue cannot capture attention in a stimulus-driven fashion.
Experiment 3: Stimulus salience in guiding attention—100 %-valid cues
One might doubt that our finding of stimulus-driven attentional capture by onset, but not color, is due to difference in stimulus salience of the two types of cues. That is, it is possible that the color cue used in previous experiments was not salient enough in capturing attention. We argue against that hypothesis, since the same color cue did capture attention when the participant searched for a color target (Experiment 1). In fact, the capture effect of the color cue when it preceded a color target was the strongest among all the conditions in Experiment 1.
Yet it remains unclear whether the salience of the cue varies depending on its contingency on the top-down control settings and stimulus property. For example, the salience of the color cue might be reduced when the target is defined by onset, as compared with color, but the salience of the onset cue might not change with the target-defining feature. As a result, the failure of attentional capture in the color-cue/onset-target condition could be due to a lack of salience of the color cue. To examine whether the color cue is as effective as the onset cue in guiding attention when the cue is not contingent on the top-down control settings, we presented the two types of cues with 100 % validity to predict the target location. As in Experiment 2, only the two conditions with unmatched cue and target—onset cue with color target and color cue with onset target—were conducted. The two types of targets followed the cue with 100 % validity. To examine whether the search performance is enhanced, two baseline conditions for searching the different types of targets were conducted, in which the targets followed a neutral cue (i.e., all the placeholders were surrounded by four white dots). If the color cue is salient enough in guiding attentional orienting as the onset cue, the color cue would be expected to enhance the search performance, as well as the onset cue, since the cue predicts the target location with 100 % certainty and participants are instructed to attend to the cue purposely.
Method
Participants
Another group of 22 undergraduate students at NTU, as described before, participated in Experiment 3.
Stimuli, design, and procedure
The stimuli, design, and procedure were the same as in Experiment 2 (onset cue followed by color target and color cue followed by onset target), with the following exceptions. First, only the 200-ms SOA condition was used. Second, the cue and the target were always presented at the same location; cue validity was 100 %. Third, a neutral-cue condition was added to create a baseline, and the cue was made by changing all the dots in the color cue display to white (Fig. 1). Four conditions consisting of two types of targets (onset and color) and two types of cues (100 %-valid noncontingent cue and neutral cue) were conducted in different blocks. The order of the cue types was counterbalanced across participants, and the order of the target types was randomly assigned. Each block consisted of 64 trials, for a total of 256 trials.
Results and discussion
Results for mean RTs under each condition are shown in Fig. 4. Mean correct RTs were subjected to a repeated measures ANOVA with target type (onset, color) and cue type (100 %-valid, neutral) as the within-subjects factors. The main effect of cue type, F(1, 21) = 16.95, MSe = 29,546.60, p < .001, was significant, but not the main effect of target type, F(1, 21) = 1.50, MSe = 2,273.38, p > .2. This result indicated that both the 100 %-valid color and onset cues speeded up target discrimination performance, as compared with each of the neutral-cue conditions, suggesting attentional guidance by the cues. The two-way target type × cue type interaction was also significant, F(1, 21) = 9.76, MSe = 5,272.61, p < .01. Further analysis showed that the larger difference between the 100 %-valid cue and the neutral cue for the onset cue than for the color cue was due to the difference in the baseline neutral-cue conditions, F(1, 42) = 7.03, MSe = 7,235.17, p < .02, but not the 100 %-valid cue condition, F(1, 42) = 0.30, MSe = 310.82, p > .5. This result suggested that when the 100 %-valid cue was employed, both the onset and color cues were equally sufficient to guide attention to the cued location (the black and white bars in Fig. 4), regardless of the different baseline neutral-cue conditions (the two bars filled with fine and coarse slashes in Fig. 4).

Mean reaction times (RTs) for target discrimination under each condition in Experiment 3. Error bars represent one standard error of the mean
For error rates (Table 1), the main effects of target type, F(1, 21) = 12.99, MSe = 0.01, p < .01, and cue type, F(1, 21) = 7.64, MSe = 0.01, p < .02, and the two-way interaction, F(1, 21) = 4.82, MSe = 0.00, p < .04, were all significant. Further analysis showed that the error rate was higher for the neutral cue than for the 100 %-valid onset cue when the target was defined by color, F(1, 42) = 12.05, MSe = 0.01, p < .01, and higher in the color target condition than in the onset target condition for the neutral cue, F(1, 42) = 16.95, MSe = 0.02, p < .001, but not for the 100 %-valid cue, F(1, 42) = 1.14, MSe = 0.00, p > .2. No speed–accuracy trade-off was suggested.
The results confirmed that the color cue is salient enough to guide attentional orienting when it is relevant to the target location, albeit the cue is not contingent on the top-down control settings. It suggests that the failure of stimulus-driven capture by the color cue shown in previous experiments is not due to lack of the color cue's salience. Rather, the color cue is just ignored when it is irrelevant to the task and when it does not share the same feature as the target.
General discussion
We used a spatial cuing paradigm with set size eight to test our hybrid account of attentional capture with different cue-to-target SOAs. Two types of cues (onset and color) and two types of targets (onset and color) were crossed in Experiment 1. The results showed distinct patterns of attentional capture by onset and color. The onset cue captured attention when the target was defined by onset, as well as when it was defined by color. In both conditions, the capture effect was observed at 100- and 200-ms SOAs, but not at SOAs longer than 350-ms. In contrast, the color cue captured attention only when the target was defined by color but not onset. The capture effect by color not only was observed at 100- and 200-ms SOAs but lasted through the 500-ms SOA. The asymmetry of attentional capture by onset and color was further confirmed and replicated when the 0-ms SOA condition was excluded to avoid possible confoundings from including this condition (Experiment 2). Furthermore, a control experiment to examine the salience of the color and onset cues showed that both cues were able to direct attentional orienting when they were 100 % valid in predicting the target location, confirming that the cues were both salient enough in guiding attention (Experiment 3).
That is, we have demonstrated the asymmetry of stimulus-driven capture by onset and color: Attentional capture by onset occurs regardless of top-down control settings, whereas attentional capture by color occurs only when the color cue is contingent on top-down control settings. When the stimulus is not contingent on top-down control settings, visual onset captures attention, but color does not. It suggests that onset is unique in capturing attention in a stimulus-driven manner.
Why is visual onset unique in capturing attention? Yantis and his colleagues first demonstrated the uniqueness of attentional capture by abrupt visual onset (Jonides & Yantis, 1988; Yantis & Jonides, 1984) and, consequently, proposed the new object hypothesis that visual onset signals new object files, therefore receiving priority in attentional processing (Yantis & Hillstrom, 1994). Franconeri et al. (2005) directly examined the new object hypothesis by decoupling transient signals from new objects and found that new objects cannot capture attention unless accompanied by transient luminance changes. Their results suggest that it is the transient property, but not new objects, that is critical to inducing involuntary orienting. Our previous study also showed that new objects captured attention only when they were contingent on trial-wide onsets—when all stimuli were presented abruptly (Jingling & Yeh, 2007)—and thus new objects per se, without accompanying transient changes, did not seem to capture attention in a stimulus-driven manner. Taken together, we favor the view that the capture effect by onset in the present study results from transient luminance changes but not new objects. However, because our manipulation of the luminance transients here are confounded with the presence of new objects, further study is required to clarify this issue, using different transient stimuli other than visual onsets.
The major difference between our hybrid account and the stimulus-driven capture hypothesis is that we find a contingent component in attentional capture, depending on the stimulus property. We propose that visual onset and color are processed with different efficiencies and modulated by top-down control settings in different ways: Visual onset is a transient stimulus; due to its efficient processing with a narrow time window in neural activation, it can bypass top-down controls and capture attention independently of top-down control settings. In contrast, a static feature, such as color, is processed with slower processing efficiency. The sustained neural activation leaves more time to interact with top-down modulation, and as a result, the color stimulus is susceptible to top-down control settings in capturing attention.
The present findings cannot be easily explained by the contingent capture hypothesis (Folk et al., 1992; Folk et al., 1994) either, because we found attentional capture by onset when the target was defined by color in all three experiments (see also Liao & Yeh, 2011; Yeh & Liao, 2008). However, one may argue that the seemingly stimulus-driven capture by onset is still contingent on top-down control settings with a broader definition of top-down control settings (e.g., display-wide attentional setting; for a review, see Burnham, 2007), which states that all the visual features accompanying the target presentation are included in top-down control settings (Gibson & Kelsey, 1998). Below, we provide reasons to argue that attentional capture by transient onset is purely stimulus-driven and cannot be explained by more broadly defined top-down control settings.
First, onset captures attention in the same way whether or not it is contingent on top-down control settings, suggesting purely stimulus-driven capture. If attentional capture by onset is contingent on top-down control settings, a larger capture effect would be found when the target is defined by onset than by color. However, no such effect was found in Experiment 1. Second, attentional capture by onset cannot be explained by adopting the singleton detection mode (Bacon & Egeth, 1994; Leber & Egeth, 2006). This possibility is ruled out by presenting heterogeneous color features in the target display to constrain the top-down control settings to be on the particular color. Finally, a more broadly defined top-down control setting, the display-wide attentional setting (Gibson & Kelsey, 1998), may account for the seemingly stimulus-driven capture by onset. However, we directly examined this hypothesis previously and found that display-wide attentional settings are applicable to static color feature but not to transient visual onset (Yeh & Liao, 2010).
Further support for the distinct underlying mechanisms of attentional capture by onset and color comes from our finding that attentional capture by onset occurs only at short, but not long, SOAs, whereas attentional capture by color not only occurs at short but lasts through long SOAs. These suggest that onset captures attention involuntarily, whereas color captures attention through voluntary feature-based attentional enhancement. Schreij et al. (2010a, b) recently showed, in a spatial cuing paradigm, that while onset cue caused IOR regardless of top-down control settings, color cue showed no sign of IOR, suggesting involuntary attentional orienting guided by onset but not color. The authors hypothesized that attentional capture by color is based on feature-based top-down search. Our findings provide further supporting evidence for this hypothesis.
The different underlying mechanisms of attentional capture by onset and color are also evident in an asymmetry in capturing focal attention by the two types of stimuli. In a previous study, we found that, when a color target is searched for, onset is unable to capture attention when it appears outside focal attention, but a color distractor does capture attention (Liao & Yeh, 2007). In our view, the results can be interpreted as showing that attentional capture by onset involves involuntary orienting and, as such, it is difficult to resist the constraint of the attentional window. According to Theeuwes (2010), attentional capture must occur within the attentional window. On the contrary, attentional capture by color is through feature-based attentional enhancement and thus is not limited by the window of spatial attention.
The view of different underlying mechanisms of attentional capture by onset and color is coincidently suggested by Du and Abrams (2010), although different in exact mechanisms from ours. They suggest that attentional capture by onset—but not attentional capture by color—happens equally in the two hemispheres of the brain. However, two different paradigms were used to demonstrate this: They used a visual search paradigm to demonstrate that attentional capture by onset did not differ between the two hemifields and an RSVP paradigm to show that the color distractor worsened performance when presented in the left visual field rather than in the right, illustrating a visual field asymmetry in attentional capture by color. One major concern is the task difference, in which the target was presented in the periphery in the visual search paradigm, as compared with the central location in the RSVP paradigm, possibly resulting in different influences on the lateralization of the stimulus processing. Ansorge, Kiss, Worschech, and Eimer (2011; see also Eimer & Kiss, 2008) used the visual search paradigm and did not find a difference for the N2pc component elicited by the color distractor in capturing attention between the hemifields. However, Ansorge et al. did not use an onset distractor for comparison. Further study is needed, with a symmetrical design for onset and color in the same paradigm, to investigate the issue of brain lateralization for attentional capture by onset and color.
The dichotomy of transient onset and sustained color stimuli in capturing attention might result from the diverse neural processing of the two types of stimuli, starting from the early visual system (Livingstone & Hubel, 1988). Transient stimuli are processed by magno-cells in LGN, which are coarse-grained and sensitive to motion; however, sustained stimuli are processed by parvo-cells, which are fine-grained and sensitive to color. While magno-cells mainly converge at dorsal visual areas, such as MT, parvo-cells mainly project to ventral visual areas, such as IT or V4. The dual visual pathways—dorsal versus ventral—were originally referred to as “where” versus “what” pathways (Mishkin & Ungerleider, 1982), which was revised as “action” versus “perception” pathways, respectively (Goodale & Milner, 1992).
Attentional capture by transient onset is postulated through the subcortical route to the dorsal pathway. Visual onset sometimes fails to capture attention by manual response (e.g., Folk & Remington, 1999; Folk et al., 1992; Yeh & Liao, 2008), whereas it captures attention by oculomotor response under similar conditions (Boot, Kramer, & Peterson, 2005; Theeuwes, Kramer, Hahn, & Irwin, 1998; Van der Stigchel & Theeuwes, 2005; Wu & Remington, 2003). Taking into account that oculomotor capture is closely related to the function of the superior colliculus (SC) and pulvinar (Van der Stigchel, Arend, van Koningsbruggen, & Rafal, 2010), it is possible that attentional capture by onset is through the subcortical route, in which the SC and pulvinar project directly to the parietal cortex to induce attentional capture (see the review of Mulckhuyse & Theeuwes, 2010). Assuming that attentional capture by transient stimuli is for action response, it should be reflexive and dependent on stimulus characteristics, per se, for survival.
In contrast, attentional capture by static color feature is through the cortical route and requires coordination of different brain areas. Serences et al. (2005; see also Serences & Yantis, 2007) showed, in an event-related fMRI study, that the neural network of attentional capture by color involves the intraparietal sulcus and frontal eye fields, the areas known to represent voluntary attentional shift. In addition, the temporoparietal junction was shown to elicit concurrent activation, with the presentation of the color stimulus contingent on top-down control settings. The results suggest that attentional capture by color requires coordination of the parietal, frontal, and temporal cortices.
In conclusion, we demonstrate here that whether top-down control settings determine attentional capture depends on the stimulus property, providing evidence that a distinct pattern of attentional capture by onset and color is illustrated (Experiment 1). The asymmetry of stimulus-driven capture by onset and color is further confirmed (Experiment 2) and evaluated not to be due to the different stimulus salience of onset and color (Experiment 3). Abrupt onset—a transient visual stimulus—captures attention independently of top-down control settings and induces reflexive involuntary orienting. In contrast, a sustained visual stimulus, such as color, is unable to capture attention in a pure stimulus-driven manner: The color stimulus captures attention only when it is contingent with the top-down control settings and results from voluntary feature-based attentional enhancement. As when dynamic advertisements appear on a Web page, their flickers and static color images are both able to capture attention, albeit under different conditions with different time courses because they capture attention through different underlying mechanisms.
Notes
We follow the common use of the term set size to refer to the condition in which the number of potential target locations and the actual number of items are the same.
The nontarget letter was green in the onset-cue/color-target condition, following Yeh and Liao (2008). It was purple in the color-cue/color-target condition because it was conducted in combination with another study. We did not expect the color of the nontarget letter to affect the top-down control settings on the target feature—at least for colors used in the present study.
One may note that RTs were slower in the color cue/onset target condition, as compared with other conditions, and wonder whether the longer RTs in this condition would mask a potential cuing effect. We do not think the RTs within the range of 550–750 ms would mask a cuing effect if it existed. In our previous study (Yeh & Liao, 2010), we examined attentional capture under display-wide setting in which there was no target-defining feature in the target display. The average RTs were around or above 800 ms, longer than in any of the current conditions, and yet robust cuing effects were still found in all three experiments in that study.
One may argue that the attentional capture effect by onset could be due to color similarity (i.e., white) between the cue and the target (Ansorge & Heumann, 2003). The onset cue shares the same color as the onset target (white), but not the color target (red); therefore, it is expected to have a larger capture effect with an onset target than with a color target if color similarity plays a role. However, the onset cue showed the same magnitude of capture effect when the target was defined by onset, as well as when it was defined by color, as indicated by the lack of interaction of target type, SOA, and validity effect for the onset cue. This suggests that color similarity does not contribute to the capture effect by onset.
References
Al-Aidroos, N., Guo, R. M., & Pratt, J. (2010a). You can’t stop new motion: Attentional capture despite a control set for colour. Visual Cognition, 18, 859–880.
Al-Aidroos, N., Harrison, S., & Pratt, J. (2010b). Attentional control settings prevent abrupt onsets from capturing visual spatial attention. The Quarterly Journal of Experimental Psychology, 63, 31–41.
Ansorge, U., & Heumann, M. (2003). Top-down contingencies in peripheral cuing: The roles of color and location. Journal of Experimental Psychology. Human Perception and Performance, 29, 937–948.
Ansorge, U., Kiss, M., Worschech, F., & Eimer, M. (2011). The initial stage of visual selection is controlled by top-down task set: New ERP evidence. Attention, Perception, & Psychophysics, 73, 113–122.
Atchley, P., Kramer, A. F., & Hillstrom, A. P. (2000). Contingent capture for onsets and offsets: Attentional set for perceptual transients. Journal of Experimental Psychology: Human Perception and Performance, 26, 594–606.
Bacon, W. F., & Egeth, H. E. (1994). Overriding stimulus-driven attentional capture. Perception & Psychophysics, 55, 485–496.
Belopolsky, A. V., Schreij, D., & Theeuwes, J. (2010). What is top-down about contingent capture? Attention, Perception, & Psychophysics, 72, 326–341.
Bichot, N. P., Cave, K. R., & Pashler, H. (1999). Visual selection mediated by location: Feature-based selection of noncontiguous locations. Perception & Psychophysics, 61, 403–423.
Boot, W. R., Kramer, A. F., & Peterson, M. S. (2005). Oculomotor consequences of abrupt object onsets and offsets: Onsets dominate oculomotor capture. Perception & Psychophysics, 67, 910–928.
Burnham, B. P. (2007). Displaywide visual features associated with a search display’s appearance can mediate attentional capture. Psychonomic Bulletin & Review, 14, 392–422.
Cave, K. R. (1999). The feature gate model of visual selection. Psychological Research, 62, 182–194.
Chen, P., & Mordkoff, J. T. (2007). Contingent capture at a very short SOA: Evidence against rapid disengagement. Visual Cognition, 15, 637–646.
Cole, G. G., Kentridge, R. W., & Heywood, C. A. (2005). Object onset and parvocellular guidance of attentional allocation. Psychological Science, 16, 270–274.
Du, F., & Abrams, R. A. (2010). Visual field asymmetry in attentional capture. Brain and Cognition, 72, 310–316.
Eimer, M., & Kiss, M. (2008). Involuntary attentional capture is determined by task set: Evidence from event-related brain potentials. Journal of Cognitive Neuroscience, 20, 1423–1433.
Enns, J. T., & Di Lollo, V. (1997). Object substitution: A new form of visual masking in unattended visual locations. Psychological Science, 8, 135–139.
Enns, J. T., & Di Lollo, V. (2000). What’s new in visual masking? Trends in Cognitive Sciences, 4, 345–352.
Folk, C. L., Leber, A., & Egeth, H. E. (2002). Made you blink! Contingent attentional capture produces a spatial blink. Perception & Psychophysics, 64, 741–753.
Folk, C. L., & Remington, R. W. (1998). Selectivity in distraction by irrelevant featural singletons: Evidence for two forms of attentional capture. Journal of Experimental Psychology. Human Perception and Performance, 24, 847–858.
Folk, C. L., & Remington, R. W. (1999). Can new objects override attentional control settings? Perception & Psychophysics, 61, 727–739.
Folk, C. L., & Remington, R. W. (2006). Top-down modulation of preattentive processing: Testing the recovery account of contingent capture. Visual Cognition, 14, 445–465.
Folk, C. L., & Remington, R. W. (2008). Bottom-up priming of top-down attentional control settings. Visual Cognition, 16, 215–231.
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology. Human Perception and Performance, 18, 1030–1044.
Folk, C. L., Remington, R. W., & Wright, J. H. (1994). The structure of attentional control: Contingent attentional capture by apparent motion, abrupt onset, and color. Journal of Experimental Psychology. Human Perception and Performance, 20, 317–329.
Forster, K. I., & Forster, J. C. (2003). DMDX: A Windows display program with millisecond accuracy. Behavior Research Methods, Instruments, & Computers, 35, 116–124.
Franconeri, S. L., Hollingworth, A., & Simons, D. J. (2005). Do new objects capture attention? Psychological Science, 16, 275–281.
Franconeri, S. L., Simons, D. J., & Junge, J. A. (2004). Searching for stimulus-driven shifts of attention. Psychonomic Bulletin & Review, 11, 876–881.
Gibson, B. S., & Kelsey, E. M. (1998). Stimulus-driven attentional capture is contingent on attentional set for displaywide visual features. Journal of Experimental Psychology. Human Perception and Performance, 24, 699–706.
Goodale, M. A., & Milner, A. D. (1992). Separate visual pathways for perception and action. Trends in Neurosciences, 15, 20–25.
Jingling, L., & Yeh, S. L. (2007). New objects do not capture attention without a top-down setting: Evidence from an inattentional blindness task. Visual Cognition, 15, 661–684.
Jonides, J., & Yantis, S. (1988). Uniqueness of abrupt visual onset in capturing attention. Perception & Psychophysics, 43, 346–354.
Leber, A. B., & Egeth, H. E. (2006). It’s under control: Top-down search strategies can override attentional capture. Psychonomic Bulletin & Review, 13, 132–138.
Liao, H. I., & Yeh, S. L. (2007). Involuntary orienting caused by salient stimuli outside focal attention: Comparison of two paradigms. Chinese Journal of Psychology, 49, 145–158.
Liao, H. I., & Yeh, S. L. (2011). Interaction between stimulus-driven orienting and top-down modulation in attentional capture. Acta Psychologica, 138, 52–59.
Livingstone, M., & Hubel, D. (1988). Segregation of form, color, movement, and depth: Anatomy, physiology, and perception. Science, 240, 740–749.
Mishkin, M., & Ungerleider, L. G. (1982). Contribution of striate inputs to the visuospatial functions of parieto-preoccipital cortex in monkeys. Behavioural Brain Research, 6, 57–77.
Mulckhuyse, M., & Theeuwes, J. (2010). Unconscious attentional orienting to exogenous cues: A review of the literature. Acta Psychologica, 134, 299–309.
Muller, H. J., & Rabbitt, P. M. (1989). Reflexive and voluntary orienting of visual attention: Time course of activation and resistance to interruption. Journal of Experimental Psychology: Human Perception and Performance, 15, 315–330.
Neo, G., & Chua, F. K. (2006). Capturing focused attention. Perception & Psychophysics, 68, 1286–1296.
Pratt, J., Radulescu, P. V., Guo, R. M., & Abrams, R. A. (2010). It’s alive! Animate motion captures visual attention. Psychological Science, 21, 1724–1730.
Rauschenberger, R. (2003). When something old becomes something new: Spatiotemporal object continuity and attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 29, 600–615.
Schreij, D., Owens, C., & Theeuwes, J. (2008). Abrupt onsets capture attention independent of top-down control settings. Perception & Psychophysics, 70, 208–218.
Schreij, D., Theeuwes, J., & Olivers, C. N. L. (2010a). Abrupt onsets capture attention independent of top-down control settings II: Additivity is no evidence for filtering. Attention, Perception, & Psychophysics, 72, 672–682.
Schreij, D., Theeuwes, J., & Olivers, C. N. L. (2010b). Irrelevant onsets cause inhibition of return regardless of attentional set. Attention, Perception, & Psychophysics, 72, 1725–1729.
Serences, J. T., Shomstein, S., Leber, A. B., Golay, X., Egeth, H. E., & Yantis, S. (2005). Coordination of voluntary and stimulus-driven attentional control in human cortex. Psychological Science, 16, 114–122.
Serences, J. T., & Yantis, S. (2007). Spatially selective representations of voluntary and stimulus-driven attentional priority in human occipital, parietal, and frontal cortex. Cerebral Cortex, 17, 284–293.
Theeuwes, J. (1991). Exogenous and endogenous control of attention: The effect of visual onsets and offsets. Perception & Psychophysics, 49, 83–90.
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51, 599–606.
Theeuwes, J. (1994). Stimulus-driven capture and attentional set: Selective search for color and visual abrupt onsets. Journal of Experimental Psychology. Human Perception and Performance, 20, 799–806.
Theeuwes, J. (1995). Abrupt luminance change pops out; Abrupt color change does not. Perception & Psychophysics, 57, 637–644.
Theeuwes, J. (2004). Top-down search strategies cannot override attentional capture. Psychonomic Bulletin & Review, 11, 65–70.
Theeuwes, J. (2010). Top-down and bottom-up control of visual selection. Acta Psychologica, 135, 77–99.
Theeuwes, J., & Burger, R. (1998). Attentional control during visual search: The effect of irrelevant singletons. Journal of Experimental Psychology. Human Perception and Performance, 24, 1342–1353.
Theeuwes, J., Kramer, A. F., Hahn, S., & Irwin, D. E. (1998). Our eyes do not always go where we want them to go: Capture of the eyes by new objects. Psychological Science, 9, 379–385.
Turatto, M., & Galfano, G. (2000). Color, form and luminance capture attention in visual search. Vision Research, 40, 1639–1643.
Turatto, M., & Galfano, G. (2001). Attentional capture by color without any relevant attentional set. Perception & Psychophysics, 63, 286–297.
Van der Stigchel, S., Arend, I., van Koningsbruggen, M. G., & Rafal, R. D. (2010). Oculomotor integration in patients with a pulvinar lesion. Neuropsychologia, 48, 3497–3504.
Van der Stigchel, S., & Theeuwes, J. (2005). Relation between saccade trajectories and spatial distractor locations. Cognitive Brain Research, 25, 579–582.
Wolfe, J. M., Cave, K. R., & Franzel, S. L. (1989). Guided search: An alternative to the feature integration model for visual search. Journal of Experimental Psychology. Human Perception and Performance, 15, 419–433.
Wu, S. C., & Remington, R. W. (2003). Characteristics of covert and overt visual orienting: Evidence from attentional and oculomotor capture. Journal of Experimental Psychology. Human Perception and Performance, 29, 1050–1067.
Yantis, S. (1993). Stimulus-driven attentional capture and attentional control settings. Journal of Experimental Psychology. Human Perception and Performance, 19, 676–681.
Yantis, S., & Egeth, H. E. (1999). On the distinction between visual salience and stimulus-driven attentional capture. Journal of Experimental Psychology. Human Perception and Performance, 25, 661–676.
Yantis, S., & Hillstrom, A. P. (1994). Stimulus-driven attentional capture: Evidence from equiluminant visual objects. Journal of Experimental Psychology. Human Perception and Performance, 20, 95–107.
Yantis, S., & Jonides, J. (1984). Abrupt visual onsets and selective attention: Evidence from visual search. Journal of Experimental Psychology. Human Perception and Performance, 10, 601–621.
Yantis, S., & Jonides, J. (1990). Abrupt visual onsets and selective attention: Voluntary versus automatic allocation. Journal of Experimental Psychology: Human Perception and Performance, 16, 121–134.
Yeh, S. L., & Liao, H. I. (2008). On the generality of the contingent orienting hypothesis. Acta Psychologica, 129, 157–165.
Yeh, S. L., & Liao, H. I. (2010). On the generality of the displaywide contingent orienting hypothesis: Can a visual onset capture attention without top-down control settings for displaywide onset? Acta Psychologica, 135, 159–167.
Author Notes
This research was supported by the National Science Council in Taiwan (NSC 98-2410-H-002-023-MY3, 101-2410- H-002-083-MY3, 098-2811-H-002-034, and 099-2811-H-002-038). We thank Bradley Gibson, Ulrich Ansorge, and Jan Theeuwes for their valuable comments on an earlier version of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Liao, HI., Yeh, SL. Capturing attention is not that simple: Different mechanisms for stimulus-driven and contingent capture. Atten Percept Psychophys 75, 1703–1714 (2013). https://doi.org/10.3758/s13414-013-0537-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0537-7