
Abstract
Visual short-term memory (VSTM) is critical for acquiring visual knowledge and shows marked individual variability. Previous work has illustrated a VSTM advantage among action video game players (Boot et al. Acta Psychologica 129:387–398, 2008). A growing body of literature has suggested that action video game playing can bolster visual cognitive abilities in a domain-general manner, including abilities related to visual attention and the speed of processing, providing some potential bases for this VSTM advantage. In the present study, we investigated the VSTM advantage among video game players and assessed whether enhanced processing speed can account for this advantage. Experiment 1, using simple colored stimuli, revealed that action video game players demonstrate a similar VSTM advantage over nongamers, regardless of whether they are given limited or ample time to encode items into memory. Experiment 2, using complex shapes as the stimuli to increase the processing demands of the task, replicated this VSTM advantage, irrespective of encoding duration. These findings are inconsistent with a speed-of-processing account of this advantage. An alternative, attentional account, grounded in the existing literature on the visuo-cognitive consequences of video game play, is discussed.
Similar content being viewed by others

The ability to maintain task-relevant visual information in the absence of external input (i.e., visual short-term memory) is critical for learning new skills, solving novel tasks, and acquiring new knowledge from the ever-changing visual world (Baddeley, 1986, 2007; Logie, 1995). A fundamental characteristic of visual short-term memory (VSTM) is its inherently capacity-limited nature. Though there is much current debate as to the nature of the capacity limitation, VSTM capacity has commonly been estimated at approximately three or four items (Alvarez & Cavanaugh, 2004; Cowan, 2001; Luck & Vogel, 1997). The importance of VSTM in acquiring knowledge from the visual environment, in conjunction with its capacity-limited nature, highlights the need for investigating whether it is possible to enhance VSTM via training. Consistent with this possibility, extensive experience with a particular domain of stimuli, such as cars, has been shown to result in a VSTM advantage for objects within that domain (Curby & Gauthier, 2007; Curby, Glazek, & Gauthier, 2009). Furthermore, action video game players (AVGPs) have been reported to show superior performance in a change detection task, as compared to non-video game players (NVGPs; Boot, Kramer, Simons, Fabiani, & Gratton, 2008). In addition, it has been demonstrated that AVGPs perform better in a color wheel task aimed at measuring VSTM precision (Sungur & Boduroglu, 2012), use a more efficient search strategy in a scene change detection task (Clark, Fleck, & Mitroff, 2011), and perform better on an enumeration task than do NVGPs (Green & Bavelier, 2006b), all of which suggests a VSTM advantage for AVGPs. However, the authors of a recent study concluded that AVGPs do not have greater VSTM capacity, as evidenced by relatively equivalent performance for three groups with varying levels of gaming experience on a whole-report task using letter stimuli (Wilms, Petersen, & Vangkilde, 2013). These contradictory results make the notion of AVGPs possessing a VSTM advantage a tenuous question in need of further examination. Given the specificity of the VSTM advantage for objects of expertise, the possibility of a VSTM advantage among AVGPs is particularly interesting, as it may represent a more generalizable advantage that is not linked to a specific stimulus category, and thus could provide insight into the development of training procedures targeting VSTM. However, the stability and mechanisms underlying such a VSTM advantage need further investigation.
A growing body of literature has suggested that extensive action video game play may elicit domain-general enhancements in various general visual cognitive abilities. Specifically, action video game play has been shown to result in enhanced allocation of visual attention across space (Green & Bavelier, 2003, 2006a), greater temporal resolution of visual attention (Green & Bavelier, 2003), reduced attentional capture (Chisholm, Hickey, Theeuwes, & Kingstone, 2010; Chisholm & Kingstone, 2012), greater dual-task and task-switching performance (Colzato, van Leeuwen, van den Wildenberg, & Hommel, 2010; Strobach, Frensch, & Schubert, 2012; but see also Donohue, James, Eslick, & Mitroff, 2012), overall greater attentional capacity (Green & Bavelier, 2003), superior selective attention (Bavelier, Achtman, Mani, & Focker, 2012), and enhanced visual processing speed (Dye, Green, & Bavelier, 2009b). Notably, training studies have also provided evidence consistent with a causal link between action video game play and these benefits to visual attention (Dye et al., 2009b; Feng, Spence, & Pratt, 2007; Green & Bavelier, 2003, 2006a, 2007; Green, Pouget, & Bavelier, 2010; but see also Boot et al., 2008). In addition, AVGPs also demonstrate a compelling processing speed advantage: Dye et al. (2009b) reported significantly reduced response times among AVGPs in the context of a variety of perceptual and attentional tasks. Furthermore, Wilms et al. (2013) concluded that speed of processing underlies the attentional benefits seen in AVGPs, and specifically that speed of encoding into VSTM may be the pertinent factor. However, these results were found within the context of the lack of a VSTM capacity advantage for AVGPs, which is inconsistent with the findings of several other studies (Boot et al., 2008; Clark et al., 2011; Green & Bavelier, 2006b; Sungur & Boduroglu, 2012). It is unclear to what degree a processing speed advantage may contribute to some of the other advantages that AVGPs have demonstrated, such as those in the context of attentional tasks. Thus, the growing literature demonstrating a wide variety of visuo-cognitive enhancements among AVGPs provides many potential sources of the VSTM advantage observed in this group.
A processing speed advantage could provide a considerable benefit to performance in VSTM tasks. In change detection paradigms, the standard paradigm of choice when investigating VSTM, the to-be-stored stimuli are typically presented very briefly (e.g., 100 ms). The speed at which an individual can encode a single item into VSTM is a limited process that has been suggested to take approximately 50 ms, on average, for simple features such as color (Vogel, Woodman, & Luck, 2006). However, individual differences in encoding speed likely exist, and these may provide some individuals with the ability to encode more items from a brief display, which would presumably yield greater capacity estimates. If AVGPs, as a group, are able to encode items more quickly into VSTM due their enhanced speed of processing, we might expect to observe an advantage in capacity when encoding time is limited, as was the case in the previous study demonstrating a VSTM advantage among AVGPs (Boot et al., 2008).
Experiment 1
The goal of Experiment 1 was to test whether a general processing speed advantage might underlie the previously reported superior VSTM performance among AVGPs, relative to NVGPs. To do this, we manipulated encoding time by including a short encoding duration condition (168 ms) similar to that used by Boot et al. (2008), as well as a long encoding duration condition (1,018 ms) that would provide more than ample time to encode items into VSTM. If AVGPs’ greater processing speed underlies their VSTM advantage over NVGPs, this advantage should be evident during the short encoding duration, but not during the long encoding duration, when there is adequate time for both groups to encode the information into VSTM.
Method
Participants
A total of 121 Temple University undergraduates (106 malesFootnote 1, 15 females; mean age = 21.6, SD = 3.5) with normal or corrected-to-normal vision were recruited from an online participant pool and through study advertisements. Individuals with a range of video game experience (i.e., no experience up to avid gamers) were overtly recruited. Prior to participation, participants completed a questionnaire about their video game playing habits in which they listed games that they had played and the number of hours that they had played in a week, on average, over the past year, using a Likert scale with the categories never, 0–1, 1–3, 3–5, 5–10, or 10+ h. Participants placed each game that they reported playing into one of the following genres: action, fighting, strategy, fantasy, sports, or other.Footnote 2 Following previous studies (Green & Bavelier, 2003, 2006a, 2007), participants were classified as AVGPs if they reported playing ≥5 h/week of action games (e.g., Halo, Call of Duty), on average, over the past year (n = 48, 43 males). Participants who reported <1 h/week of action video games and <5 h/week of other types of games were classified as NVGPs (n = 49, 43 males). The data from individuals who did not meet the criteria for AVGP or NVGP (n = 24) were excluded.
Stimuli
The stimuli consisted of colored squares (1.0º × 1.0º), which were displayed on a gray background. The color of each square was chosen randomly without replacement from a set of seven: red, green, yellow, blue, black, white, and purple. Each square was located within an invisible 4 × 4 grid subtending a visual angle of 8.5º × 8.5º. The monitor was viewed at a distance of 60 cm.
Procedure
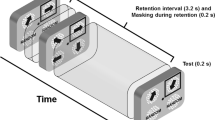
To measure VSTM capacity, a change detection paradigm was used (e.g., Luck & Vogel, 1997). After 500 ms of fixation, each trial consisted of a memory array of two, four, or six colored squares, displayed for either 168 ms (i.e., short encoding duration) or 1,018 ms (i.e., long encoding duration), followed by a 900 ms blank delay and then a 3,000 ms test array (see Fig. 1). The memory and test arrays were identical, with the exception that on half of the trials, the color of one of the squares was different between the two arrays. During “change” trials, the new color in the test array was selected at random from the other possible colors not shown in the memory array. Participants indicated whether the two arrays were the same or different by a keypress. Accuracy was stressed rather than speed. Response speed was not stressed, to ensure that performance differences between the groups would reflect the information available in VSTM rather than other factors related to producing a speeded response that are known to be enhanced by video game play (Castel, Pratt, & Drummond, 2005; Clark, Lanphear, & Riddick, 1987; Dye et al., 2009b). This was especially important due to the well-documented faster response times observed amongst AVGPs (Dye et al., 2009b). Participants received auditory feedback after each trial indicating whether their response was correct or incorrect. The participants performed 32 trials for each combination of encoding duration and set size. The different set sizes and encoding durations were randomly presented in four blocks of 48 trials, for a total of 192 trials.

Example change detection trial sequence from Experiment 1
Results and discussion
The analyses targeted whether performance varied between AVGPs and NVGPs, and if so, whether this pattern varied by encoding duration. A 3 (set size: 2, 4, 6) × 2 (encoding duration: 168, 1,018 ms) × 2 (group: AVGP, NVGP) repeated measures analysis of variance (ANOVA) was performed on the accuracy values. Individuals with accuracy scores greater than 2 SDs below the whole sample’s mean were excluded from this analysis (n = 10: four AVGPs/six NVGPs). Significant main effects of encoding duration, F(1, 85) = 54.11, p < .001, η p 2 = .39, and set size, F(2, 84) = 185.05, p < .001, η p 2 = .69, were observed, with accuracy being greater for smaller set sizes and the longer encoding duration (i.e., 1,018 ms). A significant interaction between set size and encoding duration also emerged, F(2, 84) = 5.49, p < .01, η p 2 = .06, in which the benefit of longer encoding time was greater for larger set sizes. Importantly, a main effect of group was observed, F(1, 85) = 9.52, p < .01, η p 2 = .10, in which AVGPs demonstrated greater overall task accuracy than did NVGPs.
Notably, the two- and three-way interactions involving group and encoding duration were not significant [Group × Encoding Duration interaction, F(1, 85) = 1.7, p = .19, η p 2 = .02; Group × Encoding Duration × Set Size interaction, F(2, 84) = .56, p = .57, η p 2 = .01]. Thus, AVGPs demonstrated a VSTM advantage over NVGPs, regardless of whether they had limited or ample time to encode the memory array (Fig. 2). Although it may appear that the effect at set size 6 was stronger for the short than for the long encoding duration, an additional 2 (group: AVGP, NVGP) × 2 (encoding duration: 168, 1,018 ms) repeated measures ANOVA demonstrated that no significant Encoding × Group interaction was present at set size 6 alone, F(1, 85) = 1.42, p = .24. These results are inconsistent with accounts suggesting that AVGPs’ VSTM benefit arises via faster encoding of briefly presented items for storage in VSTM.

Results of the change detection paradigm illustrating AVGPs’ greater accuracy at the largest set size, regardless of encoding duration. Error bars represent standard errors of the means. * p < .05
The interaction between group and set size was significant, F(2, 84) = 3.02, p < .05, η p 2 = .03, in that AVGPs’ performance advantage over NVGPs increased as set size increased. Planned independent-samples t tests, performed separately for each encoding duration, revealed no significant group differences at set size 2 [168 ms, t(85) = 1.50, p = .14; 1,018 ms, t(85) = 1.21, p = .23]. For set size 4, both encoding durations approached significant group differences [168 ms, t(85) = 1.76, p = .083; 1,018 ms, t(85) = 1.96, p = .053]. Finally, a significant group difference for both encoding durations emerged at set size 6 [168 ms, t(85) = 2.94, p < .01; 1,018 ms, t(85) = 2.04, p < .05]. Therefore, AVGPs only outperformed NVGPs at the largest set size (see Fig. 2). In order to compare the sizes of these effects with reference to capacity estimates, Cowan’s K was also calculated separately for each set size and encoding duration (Cowan, 2001). For set size 6 with the short encoding duration, AVGPs’ average capacity estimate was 3.4 items (SD = 1.0), as compared to 2.7 items (SD = 1.0) for the NVGPs. For set size 6 with the long encoding duration, AVGPs stored an average of 4.3 items (SD = .95), as compared to 3.8 items (SD = 1.03) for the NVGPs.
In sum, we replicated previous findings of a VSTM advantage among AVGPs as compared with NVGPs (Boot et al., 2008) and extended this finding by demonstrating that this advantage remains robust even when both AVGPs and NVGPs are given ample time to encode items into VSTM. Notably, this pattern of performance under different temporal encoding limitations is inconsistent with a speed of processing account of this difference in VSTM performance, as AVGPs similarly outperformed NVGPs in both the long and short encoding duration conditions.
Experiment 2
Experiment 1 revealed a VSTM advantage among AVGPs, regardless of encoding time. However, only simple objects (colored squares) where used. Thus, it is possible that the task was not sufficiently perceptually challenging to reveal an effect of encoding time. In other words, perhaps both groups found the task in Experiment 1 relatively easy due to the simple nature of the stimuli used, and therefore any encoding speed advantage among the AVGPs would have provided little additional benefit. In Experiment 2, we thus sought to replicate the VSTM advantage among AVGPs and to assess whether the independence of this effect from encoding time manipulations would hold even when more perceptually challenging, complex stimuli were used.
Method
Participants
A total of 47 individuals from Experiment 1 also participated in Experiment 2 during a separate experimental session. During the Experiment 1 testing session, participants were informed that they would have the opportunity to participate in a second experiment, and therefore they were not provided any information about Experiment 1 that could have biased their performance in future testing sessions. Groups of 23 AVGPs (age, M = 21.4, SD = 3.3; 21 males) and 24 NVGPs (age, M = 22.9, SD = 5.3; 23 males) took part in Experiment 2. Participants reported how many hours/week they spent playing each genre of game (i.e., action, fighting, strategy, fantasy, sports; see note 2). All of the NVGPs reported no action video game playing. The AVGP group reported an average of 15.6 h/week of action games (SD = 5.6).
Stimuli
The stimuli consisted of nine gray novel shapes (1.3º × 1.3º). Due to the greater visual complexity of these stimuli, VSTM capacity estimates were expected to be lower than those reported in Experiment 1 (Alvarez & Cavanaugh, 2004; Luria, Sessa, Gotler, Jolicœur, & Dell’Acqua, 2009).
Procedure
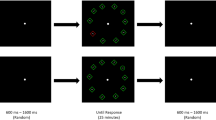
As in Experiment 1, a change detection paradigm was used to estimate VSTM capacity. All stimuli were displayed on a white background. After 500 ms of fixation, each trial consisted of a memory array followed by a test array. The memory and test arrays were separated by 1,500 ms of fixation (Fig. 3). The memory array was displayed using the same encoding durations as in Experiment 1 (i.e., 168 and 1,018 ms). The memory array contained one, two, or four target items.Footnote 3 On each trial, the shape of each object presented was chosen randomly without replacement and was located within an invisible 4 × 4 grid subtending a visual angle of 7.1º × 7.1º. The test array was displayed for 3,000 ms or until a response. The monitor was viewed at a distance of 60 cm. The memory and test arrays were identical, with the exception that on half of the trials, the shape of one of the targets changed between the two arrays. During “change” trials, the new shape in the test array was selected at random from the other possible shapes not shown in the memory array. Participants indicated whether the two arrays were the same or different by a keypress. Accuracy was once again stressed rather than speed. Participants received visual feedback after each trial as to whether their response was correct or incorrect, and they performed 40 trials for each combination of encoding duration and set size. The trials were presented randomly in ten blocks of 24 trials, for a total of 240 trials.

Trial sequence (a) and stimuli (b) used for Experiment 2
Results and discussion
Our analyses again targeted any group differences and, if they were present, whether the differences varied by encoding duration. The data from three participants (two AVGPs, one NVGP) were excluded from further analyses due to poor performance (>2 SDs below the whole sample’s mean). A 3 (set size: 1, 2, 4) × 2 (encoding duration: 168, 1,018 ms) × 2 (group: AVGP, NVGP) repeated measures ANOVA was performed on the accuracy data. We found main effects of set size, F(2, 41) = 171.89, p < .001, η p 2 = .89, and group, F(1, 42) = 5.12, p = .028, η p 2 = .11, with performance accuracy being greater at smaller set sizes and among AVGPs as compared to NVGPs. As in Experiment 1, and despite the lower performance level resulting from the use of complex shapes as stimuli, we observed no main effect or interaction with encoding duration (all ps > .31). In addition, no interaction was apparent between group and set size (p = .23).
Thus, AVGPs maintained their VSTM advantage, regardless of encoding duration, when complex shapes were used as the to-be-encoded items. Notably, the considerably lower performance in general among both NVGPs and AVGPs, relative to that in Experiment 1 (see Fig. 4), affirms that the complex shapes produced the expected substantial increase in task difficulty relative to when simple colored squares were encoded. To specifically compare the task difficulties in the two experiments, we tested a 2 (set size: 2, 4) × 2 (experiment: 1, 2) repeated measures ANOVA to determine whether performance was indeed different across experiments for the two set sizes that were used in both experiments. A main effect of experiment emerged, F(1, 42) = 92.29, p < .001, with accuracy being higher in Experiment 1 than in Experiment 2. Furthermore, a significant main effect of set size emerged, F(1, 42) = 193.61, p < .001, with performance being higher at set size 2. Finally, the Set Size × Experiment interaction also reached significance, F(1, 42) = 95.12, p < .001, in that the decline in accuracy from set sizes 2 to 4 was smaller in Experiment 1 than in Experiment 2. In other words, adding two additional memory items decreased accuracy significantly more in Experiment 2 than in Experiment 1. These results demonstrate that our use of complex shapes in Experiment 2 did indeed increase the difficulty of the task.

Results of Experiment 2, using more complex memory items, again illustrating AVGPs’ greater accuracy regardless of encoding duration. Error bars represent standard errors of the means
Finally, for those individuals who participated in both Experiments 1 and 2, an average of 102 (SD = 144)Footnote 4 days apart, VSTM performance was stable across testing sessions. A correlation analysis illustrated that average VSTM accuracy was highly correlated across the two experiments (r = .764, p < .001), demonstrating the stability of our samples’ performance across sessions and task changes. Thus, AVGPs consistently outperformed NVGPs across Experiments 1 and 2.
General discussion
Visual short-term memory is an inherently capacity-limited system; however, the present results support the potential malleability of this system. We confirmed a previous finding that individuals with extensive experience playing action video games have enhanced VSTM for briefly presented stimuli, as compared to individuals who did not play action games (Boot et al., 2008). Extending previous findings, AVGPs displayed a VSTM advantage, regardless of whether limited or ample time was given to encode the initial memory array (i.e., 168 vs. 1,018 ms) and of the complexity of the to-be-stored items (i.e., colored squares vs. complex shapes). Thus, whereas previous studies have demonstrated that AVGPs’ faster processing of visual information affords them benefits in a number of tasks (Dye et al., 2009b), it does not appear to account for their VSTM advantage.
Our results showed no evidence for an interaction between encoding duration and group, which suggests that the amount of time given to encode the memory items did not alter the degree of the advantage that AVGPs demonstrated over NVGPs. Given the existing literature on VSTM consolidation timing, it seems unlikely that using a longer encoding duration (i.e., >1,018 ms) would have allowed the NVGP group to “catch up” and equate their performance with the AVGPs. Previous work has illustrated that the average amount of time required to consolidate a simple colored item into VSTM is approximately 50 ms (Vogel et al., 2006), suggesting that our long encoding duration of 1,018 ms provided more than ample time for individuals to encode up to six items in Experiment 1. Furthermore, our use of more complex shapes in Experiment 2 demonstrated that AVGPs’ VSTM advantage is still similarly unaffected by encoding duration when the perceptual load of the to-be-stored items is increased. As expected, the complex shapes used in Experiment 2 increased the difficulty of the VSTM task. Notably, both groups appeared similarly less able to encode and store the complex shapes, relative to the simple colored squares, with the decrements to performance appearing to be similar across the groups. Thus, the use of even more complex shapes or an even longer encoding duration would be unlikely to change our findings.
Our results are inconsistent with those of Wilms et al. (2013), who found increased speed of processing for AVGPs and attributed that speed of processing to faster encoding of information into VSTM. The main difference between their study and the present one was the encoding durations used. Wilms et al. used 50- and 100 ms encoding durations. However, it seems unclear why they did not find a capacity advantage for their AVGP group using a 100 ms encoding duration, as this is the same encoding duration used by Boot et al. (2008), who did find a VSTM advantage. Furthermore, given the evidence that the average consolidation time for simple colored stimuli like those used in Experiment 1 is 50 ms (Vogel et al., 2006), the encoding duration used in Experiment 1—that is, 168 ms—should have been sufficiently short to reveal any effect, if one was present, of an encoding speed advantage on AVGPs’ VSTM performance. Furthermore, in Experiment 2 we used the same encoding duration, but with more complex stimuli that one might assume would require additional time to encode into VSTM, but still we failed to reveal evidence of the contribution of an encoding speed advantage to AVGPs’ enhanced VSTM performance. However, the present study cannot speak directly to potential contributions of encoding speed to AVGPs enhanced VSTM under shorter encoding durations (i.e., <168 ms), such as those used in the Wilms et al. study. Notably, Wilms et al.’s failure to find a VSTM advantage under these conditions puts in question the potential of such data to provide insight into the sources of the VSTM advantage amongst AVGPs (documented here and elsewhere; Boot et al., 2008). Taken together, the results of the present study and of previous studies (Boot et al., 2008; Clark et al., 2011; Green & Bavelier, 2006b; Sungur & Boduroglu, 2012; Wilms et al., 2013) suggest that AVGPs do possess a VSTM advantage; however, the relationship between VSTM capacity and speed of encoding may be complex and may vary under differential task conditions.
One potential limitation to our results may be the use of the same participants across both experiments. By using the same group of AVGPs and NVGPs in Experiment 2, the replication of findings from Experiment 1 is perhaps not surprising in some respects. However, the stability of AVGPs’ VSTM advantage across the two experimental sessions and despite the change in the complexity of the stimuli used provides further support for the robustness of a VSTM advantage among AVGPs. Furthermore, using the same participants allowed us to demonstrate the stability of VSTM performance differences at an individual level, even when the testing sessions occurred on average approximately 102 days apart and assessed VSTM for different stimulus dimensions (i.e., color vs. shape). Notably, to our knowledge, the stability of effects over time has not been previously demonstrated in the video gaming literature.
Previous work on VSTM capacity has suggested that individual differences may emerge at large set sizes due to the greater need for selectivity and control of attention (e.g., Fukuda & Vogel, 2009; Herrero, Nikolaev, Raffone, & van Leeuwen, 2009; Kuo, Stokes, & Nobre, 2012; Vogel, McCullough, & Machizawa, 2005). Considering the previously discussed attentional findings in the action video game literature (e.g., Bavelier et al., 2012), it may be that enhanced selective attention underlies AVGPs’ VSTM advantage. Indeed, Green and Bavelier (2012) suggested that the underlying mechanism of AVGPs’ visuo-cognitive advantages may be increased abilities to select task-relevant and to ignore task-irrelevant visual information via augmented attentional control and executive functioning. They suggested that action video games foster an increased ability to flexibly and effortlessly allocate attentional and executive resources in visuo-cognitive tasks. This notion of enhanced selective attention underlying AVGPs’ visuo-cognitive advantages is consistent with our finding in Experiment 1 that AVGPs showed a greater VSTM advantage at the largest set size. Furthermore, whereas a significant Group × Set Size interaction did not emerge in Experiment 2, examination of Fig. 4 illustrates a trend toward a larger advantage for AVGPs at set size 4 than at set sizes 1 and 2. Given that only set size 4 represented a supracapacity set size in Experiment 2, these results are consistent with those of Experiment 1 and suggest that enhanced selective attention may contribute to this VSTM advantage. Additional studies will be needed in order to more directly explore the potential role of superior attentional control in contributing to the AVGPs’ VSTM advantage documented here.
Notably, the VSTM advantage demonstrated here amongst AVGPs, relative to NVGPs, is unlike some other previously reported experience-based VSTM advantages, such as that for faces and other objects of expertise (Curby & Gauthier, 2007; Curby et al., 2009; Scolari, Vogel, & Awh, 2008). In addition to its domain-specific nature, the VSTM advantage reported for faces and nonface objects of expertise was dependent on encoding time, with the VSTM advantage emerging with extended encoding time, suggesting that experts, if given enough time, can more efficiently store complex objects that lie within their domain of expertise (Curby & Gauthier, 2007). In contrast, the VSTM advantage among AVGPs appears to be domain-general, to be equally present under brief and extended encoding durations, and to be unaffected by the visual complexity of the stimuli to be stored. Thus, the present findings, in the context of previous work documenting VSTM advantages for objects of expertise, highlight that experience might impact VSTM in multiple ways. Furthermore, the present study has focused on the notion that a VSTM advantage for AVGPs translates to greater capacity, or at least a greater estimate of capacity, as measured by performance in our change detection tasks. However, much debate still focuses on the influences of capacity versus resolution with regard to differences in performance on change detection tasks (e.g., Alvarez & Cavanaugh, 2004; Bays, Catalao, & Husain, 2009; Bays & Husain, 2008; Luck & Vogel, 1997). It may be that AVGPs’ VSTM advantage is more akin to an advantage in the precision with which items are stored in VSTM (Sungur & Boduroglu, 2012). Regardless, these findings, in addition to those in the expertise literature, suggest that visual experience can influence VSTM in multiple ways.
A potential limitation to the present study is the use of overt recruitment. According to Boot, Blakely, and Simons (2011), cross-sectional studies should engage in covert recruitment in order to avoid differential demand characteristics and motivation levels between gamers and nongamers. It may be possible that our explicit recruitment of “individuals with a range of video game experience” biased our AVGP group in some way that differed from our NVGP group. However, there is no empirical evidence to support the notion that overt recruitment leads to differential motivation in AVGPs and NVGPs at this point in time. This will be a critical avenue for future research, as this body of literature expands.
Whereas the VSTM advantage for AVGPs reported here builds on the existing literature regarding enhanced visuo-cognitive abilities resulting from extensive action video game playing (Bavelier et al., 2012; Chisholm et al., 2010; Clark et al., 2011; Dye, Green, & Bavelier, 2009a, b; Feng et al., 2007; Green & Bavelier, 2003, 2006a, 2006b, 2007; Green, Sugarman, Medford, Klobusicky, & Bavelier, 2012; Mishra, Zinni, Bavelier, & Hillyard, 2011; Sungur & Boduroglu, 2012; West, Stevens, Pun, & Pratt, 2008), it is worth noting that the effect sizes found in our study are relatively small in comparison to those in other cross-sectional studies. Although AVGPs display a VSTM advantage over NVGPs, this advantage appears to be less pronounced than some of the attentional and perceptual benefits found in the literature. It is also possible that a selection bias (i.e., individuals with high VSTM capacity may be more likely to play action video games initially) may contribute to this VSTM advantage observed among AVGPs. Training studies, in which nongamers are recruited and randomly assigned to train on action video games or a control game, are typically used in this literature to avoid self-selection biases that might be at play in real-world AVGP and NVGP groups. Notably, although Boot et al. (2008) did not find a training effect on VSTM after 21.5 h of training, a more recent study suggests that 20 h of action video game play is sufficient to improve VSTM, as evidenced by increased change detection performance relative to a control group (Oei & Patterson, 2013). Although the present study cannot attest to the causal effect of action video game play on VSTM, these mixed findings from training studies warrant further investigation into the relationship between action video game play and VSTM performance.
In summary, action video games provide the player with a complex and constantly changing visual environment in which efficient visual attention and accurate visual memory often determine the player’s success or failure in the game. From the present results, exposure to these visual environments over an extensive period of time appears to enhance this capacity-limited VSTM system. Thus, video game playing could serve as a useful tool for enhancing VSTM performance in a domain-general manner. The importance of VSTM in acquiring knowledge from the visual environment renders the potential to enhance VSTM through training an important avenue for further research.
Notes
Due to the low incidence of female AVGPs, mainly male participants were recruited. For each female AVGP who did enroll in the study, we recruited a gender- and age-matched NVGP. The results remained unchanged with regard to the significance levels or direction of effects when the females were excluded.
We verified the participants’ video game genre classifications to ensure accurate estimates for each genre of game.
On half of the trials, black distractor items (chose from a set of shapes that were identical, except for their color, to the target items) were presented in addition to the gray targets. The participants were instructed to always ignore these black shapes, as they were never task-relevant, and the same shape never appeared in the same trial as both a target and a distractor. The presence of these distractors had no statistically detectable effect on performance (all ps ≥ .1), and thus the data were collapsed over these conditions, which did not allow us to effectively examine group differences in distractor filtering in this task. A stronger distractor manipulation could be used in future studies to probe this important question.
Recruitment for Experiment 2 was done in two waves, which yielded two groups of participants who participated in both experiments on vastly different time scales. In one of the waves, 21 participants completed the two experiments an average of 271 days apart (SD = 101), and in the other, 36 completed the experiments an average of 3 days apart (SD = 2). The correlation between performance in Experiments 1 and 2 was unchanged in direction or significance if these groups of participants were considered separately.
References
Alvarez, G. A., & Cavanaugh, P. (2004). The capacity of visual short-term memory is set both by visual information load and by the number of objects. Psychological Science, 15, 106–111. doi:10.1111/j.0963-7214.2004.01502006.x
Baddeley, A. (1986). Working memory (Oxford Psychology Series, No. 11). Oxford: Oxford University Press, Clarendon Press.
Baddeley, A. (2007). Working memory, thought, and action. Oxford: Oxford University Press.
Bavelier, D., Achtman, R. L., Mani, M., & Focker, J. (2012). Neural bases of selective attention in action video game players. Vision Research, 61, 132–143. doi:10.1016/j.visres.2011.08.007
Bays, P. M., Catalao, R. F. G., & Husain, M. (2009). The precision of visual working memory is set by allocation of a shared resource. Journal of Vision, 9(10), 7. doi:10.1167/9.10.7
Bays, P. M., & Husain, M. (2008). Dynamic shifts of limited working memory resources in human vision. Science, 321, 851–854. doi:10.1126/science.1158023
Boot, W. R., Blakely, D. P., & Simons, D. J. (2011). Do action video games improve perception and cognition? Frontiers in Cognition, 2(226), 1–6. doi:10.3389/fpsyg.2011.00226
Boot, W. R., Kramer, A. F., Simons, D. J., Fabiani, M., & Gratton, G. (2008). The effects of video game playing on attention, memory, and executive control. Acta Psychologica, 129, 387–398. doi:10.1016/j.actpsy.2008.09.005
Castel, A. D., Pratt, J., & Drummond, E. (2005). The effects of action video game experience on the time course of inhibition of return and the efficiency of visual search. Acta Psychologica, 119, 217–230. doi:10.1016/j.actpsy.2005.02.004
Chisholm, J. D., Hickey, C., Theeuwes, J., & Kingstone, A. (2010). Reduced attentional capture in action video game players. Attention, Perception, & Psychophysics, 72, 667–671. doi:10.3758/APP.72.3.667
Chisholm, J. D., & Kingstone, A. (2012). Improved top-down control reduces oculomotor capture: The case of action video game players. Attention, Perception, & Psychophysics, 74, 257–262. doi:10.3758/S13414-011-0253-0
Clark, K., Fleck, M. S., & Mitroff, S. R. (2011). Enhanced change detection performance reveals improved strategy use in avid action video game players. Acta Psychologica, 136, 67–72. doi:10.1016/j.actpsy.2010.10.003
Clark, J. E., Lanphear, A. K., & Riddick, C. C. (1987). The effects of videogame playing on the response selection processing of elderly adults. Journal of Gerontology, 42, 82–85.
Colzato, L. S., van Leeuwen, P. J. A., van den Wildenberg, W. P. M., & Hommel, B. (2010). DOOM’d to switch: Superior cognitive flexibility in players of first person shooter games. Frontiers in Cognition, 1(8), 1–5. doi:10.3389/fpsyg.2010.00008
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24, 87–114. doi:10.1017/S0140525X01003922
Curby, K. M., & Gauthier, I. (2007). A visual short-term memory advantage for faces. Psychonomic Bulletin & Review, 14, 620–628. doi:10.3758/BF03196811
Curby, K. M., Glazek, K., & Gauthier, I. (2009). A visual short-term memory advantage for objects of expertise. Journal of Experimental Psychology. Human Perception and Performance, 35, 94–107. doi:10.1037/0096-1523.35.1.94
Donohue, S. E., James, B., Eslick, A. N., & Mitroff, S. R. (2012). Cognitive pitfall! Videogame players are not immune to dual-task costs. Attention, Perception, & Psychophysics, 74, 803–809. doi:10.3758/s13414-012-0323-y
Dye, M. W. G., Green, C. S., & Bavelier, D. (2009a). The development of attention skills in action video game players. Neuropsychologia, 47, 1780–1789. doi:10.1016/j.neuropsychologia.2009.02.002
Dye, M. W. G., Green, C. S., & Bavelier, D. (2009b). Increasing speed of processing with action video games. Current Directions in Psychological Science, 18, 321–326. doi:10.1111/j.1467-8721.2009.01660.x
Feng, J., Spence, I., & Pratt, J. (2007). Playing an action video game reduces gender differences in spatial cognition. Psychological Science, 18, 850–855. doi:10.1111/j.1467-9280.2007.01990.x
Fukuda, K., & Vogel, E. K. (2009). Human variation in overriding attentional capture. Journal of Neuroscience, 29, 8726–8733. doi:10.1523/JNEUROSCI.2145-09.2009
Green, C. S., & Bavelier, D. (2003). Action video game modifies visual selective attention. Nature, 423, 534–538. doi:10.1038/nature01647
Green, C. S., & Bavelier, D. (2006a). Effect of action video games on spatial distribution of visuospatial attention. Journal of Experimental Psychology. Human Perception and Performance, 32, 1465–1478. doi:10.1037/0096-1523.32.6.1465
Green, C. S., & Bavelier, D. (2006b). Enumeration versus multiple object tracking: The case of action video game players. Cognition, 101, 217–245. doi:10.1016/j.cognition.2005.10.004
Green, C. S., & Bavelier, D. (2007). Action-video-game experience alters the spatial resolution of vision. Psychological Science, 18, 88–94. doi:10.1111/j.1467-9280.2007.01853.x
Green, C. S., & Bavelier, D. (2012). Learning, attentional control, and action video games. Current Biology, 22, R197–R206. doi:10.1016/j.cub.2012.02.012
Green, C. S., Pouget, A., & Bavelier, D. (2010). Improved probabilistic inference as a general learning mechanism with action video games. Current Biology, 20, 1573–1579. doi:10.1016/j.cub.2010.07.040
Green, C. S., Sugarman, M. A., Medford, K., Klobusicky, E., & Bavelier, D. (2012). The effect of action video game experience on task-switching. Computers in Human Behavior, 28, 984–994. doi:10.1016/j.chb.2011.12.020
Herrero, J. L., Nikolaev, A. R., Raffone, A., & van Leeuwen, C. (2009). Selective attention in visual short-term memory consolidation. NeuroReport, 20, 652–656. doi:10.1097/WNR.0b013e328329a431
Kuo, B.-C., Stokes, M. G., & Nobre, A. C. (2012). Attention modulates maintenance of representations in visual short-term memory. Journal of Cognitive Neuroscience, 24, 51–60. doi:10.1162/jocn_a_00087
Logie, R. H. (1995). Visuo-spatial working memory. Hove: Erlbaum.
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390, 279–281. doi:10.1038/36846
Luria, R., Sessa, P., Gotler, A., Jolicœur, P., & Dell’Acqua, R. (2009). Visual short-term memory capacity for simple and complex objects. Journal of Cognitive Neuroscience, 22, 496–512. doi:10.1162/jocn.2009.21214
Mishra, J., Zinni, M., Bavelier, D., & Hillyard, S. A. (2011). Neural basis of superior performance of action videogame players in an attention-demanding task. Journal of Neuroscience, 31, 992–998. doi:10.1523/JNEUROSCI.4834-10.2011
Oei, A. C., & Patterson, M. D. (2013). Enhancing cognition with video games: A multiple game training study. PLoS ONE, 8, e58546. doi:10.1371/journal.pone.0058546
Scolari, M., Vogel, E. K., & Awh, E. (2008). Perceptual expertise enhances the resolution but not the number of representations in working memory. Psychonomic Bulletin & Review, 15, 215–222. doi:10.3758/PBR.15.1.215
Strobach, T., Frensch, P. A., & Schubert, T. (2012). Video game practice optimizes executive control skills in dual-task and task switching situations. Acta Psychologica, 140, 13–24. doi:10.1016/J.Actpsy.2012.02.001
Sungur, H., & Boduroglu, A. (2012). Action video game players form more detailed representation of objects. Acta Psychologica, 139, 327–334. doi:10.1016/j.actpsy.2011.12.002
Vogel, E. K., McCullough, A. W., & Machizawa, M. G. (2005). Neural measures reveal individual differences in controlling access to working memory. Nature, 438, 500–503. doi:10.1038/nature04171
Vogel, E. K., Woodman, G. F., & Luck, S. J. (2006). The time course of consolidation in visual working memory. Journal of Experimental Psychology. Human Perception and Performance, 32, 1436–1451. doi:10.1037/0096-1523.32.6.1436
West, G. L., Stevens, S. A., Pun, C., & Pratt, J. (2008). Visuospatial experience modulates attentional capture: Evidence from action video game players. Journal of Vision, 8(16). doi:10.1167/8.16.13
Wilms, I. L., Petersen, A., & Vangkilde, S. (2013). Intensive video gaming improves encoding speed to visual short-term memory in young male adults. Acta Psychologica, 142, 108–118. doi:10.1016/j.actpsy.2012.11.003
Author Note
We thank Elizabeth Klobusicky for help with piloting and collecting the data for Experiment 1.
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article
Cite this article
Blacker, K.J., Curby, K.M. Enhanced visual short-term memory in action video game players. Atten Percept Psychophys 75, 1128–1136 (2013). https://doi.org/10.3758/s13414-013-0487-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0487-0