
Abstract
In three experiments, we investigated the spatial allocation of attention in response to central gaze cues. In particular, we examined whether the allocation of attentional resources is influenced by context information—that is, the presence or absence of reference objects (i.e., placeholders) in the periphery. On each trial, gaze cues were followed by a target stimulus to which participants had to respond by keypress or by performing a target-directed saccade. Targets were presented either in an empty visual field (Exps. 1 and 2) or in previewed location placeholders (Exp. 3) and appeared at one of either 18 (Exp. 1) or six (Exps. 2 and 3) possible positions. The spatial distribution of attention was determined by comparing response times as a function of the distance between the cued and target positions. Gaze cueing was not specific to the exact cued position, but instead generalized equally to all positions in the cued hemifield, when no context information was provided. However, gaze direction induced a facilitation effect specific to the exact gazed-at position when reference objects were presented. We concluded that the presence of possible objects in the periphery to which gaze cues could refer is a prerequisite for attention shifts being specific to the gazed-at position.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Interacting with other people in a crowded environment is a difficult task that requires complex cognitive skills. Even simple interactions, like shaking hands or passing an object from one person to another, are challenging, in that two individuals must coordinate their actions. A prerequisite for successful interaction is the anticipation of action goals (Sebanz, Bekkering, & Knoblich, 2006)—which can be inferred from the other’s focus of attention, as locations or objects attended by the other are the likely targets for upcoming actions. For identifying where or what others are paying attention to, we rely on directional information provided by social cues, including gestures, body and head orientation, and in particular, gaze direction (Emery, 2000; Kingstone, Smilek, Ristic, Friesen, & Eastwood, 2003; Langton, Watt, & Bruce, 2000).
Utilizing gaze direction to infer action goals requires us to identify where the other is looking and to shift our own attentional focus to the corresponding location/object (for a review, see Frischen, Bayliss, & Tipper, 2007). Previous studies have shown that humans are quite precise in estimating gaze direction, with estimation errors ranging from 0.5° to 4° of visual angle. This high level of precision has been found for dyadic interactions, in which observers had to discern the direct and averted gaze of an interaction partner (Ando, 2002; Anstis, Mayhew, & Morley, 1969; Cline, 1967; Gamer & Hecht, 2007; J. J. Gibson & Pick, 1963), as well as for triadic interactions, in which observers had to judge to which object in space an interaction partner’s gaze was directed (Bock, Dicke, & Thier, 2008; Gale & Monk, 2000; Schwaninger, Lobmaier, & Fischer, 2005; Symons, Lee, Cedrone, & Nishimura, 2004; Wiese, Kohlbecher, & Müller, 2012). Besides factors that are directly associated with the physical appearance of the eyes, such as the iris/sclera ratio (Ando, 2002; Anstis et al., 1969; Langton et al., 2000) or the luminance contrast between the iris and the sclera (Ando, 2002), various context factors—such as body and head orientation (Gamer & Hecht, 2007; Todorović, 2006), number of visible eyes (Gamer & Hecht, 2007; Symons et al., 2004), looker–observer distance (Gamer & Hecht, 2007; Symons et al., 2004), and the presence of objects in the attended space (Lobmaier, Fischer, & Schwaninger, 2006)—have been shown to influence the accuracy of gaze direction estimation.
Interestingly, when watching another person gazing at a distinct location in space, the attentional focus of the observer is quasireflexively shifted to the gazed-at location (Driver et al., 1999; Friesen & Kingstone, 1998; Hietanen, 1999; Hietanen & Leppänen, 2003; Langton & Bruce, 1999; cf. P. Downing, Dodds, & Bray, 2004; Driver et al., 1999; Friesen, Ristic, & Kingstone, 2004), so as to permit flexible responding to upcoming actions of the gazer. Gaze-induced shifts of attention have traditionally been investigated by using a cueing paradigm (Friesen & Kingstone, 1998), in which a schematic face is presented centrally on the screen, gazing either straight ahead or to the left or right side of the screen. Targets appearing in the cued direction are detected, located, and discriminated faster than targets in the other, noncued direction (for a review, see Frischen et al., 2007). Cueing effects emerge as early as 150 ms after cue onset, decay relatively quickly (within 1,000 ms after cue presentation), and are obtained in cases in which gaze direction is nonpredictive (Friesen & Kingstone, 1998), or even counterpredictive, with regard to upcoming target positions (Friesen et al., 2004). Moreover, gaze-cueing effects can be induced by realistic faces (Hietanen & Leppänen, 2003; Langton & Bruce, 1999), as well as by various kinds of nonface objects that convey eye-like information (Quadflieg, Mason, & Macrae, 2004).
Given the number of studies that have examined how precise observers are in determining the gaze direction of others, it is surprising that the question of how accurately they deploy their own attention to the gazed-at locations has been neglected in the literature. Arguably, though, this is an important question, in particular with regard to complex environments in which multiple objects of potential interest to the observed person may be located close to each other, making it difficult for the observer to determine the other’s attentional focus precisely. In this situation, specific-location theories of spatial attention, such as the zoom-lens model (e.g., Eriksen & Yeh, 1985) or the gradient model (e.g., C. J. Downing & Pinker, 1985; Henderson, 1991; LaBerge & Brown, 1989; Shulman, Wilson, & Sheehy, 1985), predict that attention will be directed to the exact gaze-cued location, selectively enhancing attentional processing for a narrow region of the visual field. In contrast, general-region theories, such as the meridian-boundary model (Hughes & Zimba, 1985, 1987), predict that gaze-cueing effects will generalize to the whole cued hemifield or quadrant, as attentional allocation is constrained by a neural machinery that can demarcate only broader regions of the visual field.
To our knowledge, only one neuropsychological study (Vuilleumier, 2002, Exps. 4–5) has looked at the spatial specificity of attentional orienting in response to gaze cues (and even then, more as a side effect). The main objective of the study was to examine whether gaze-induced shifts of attention would still be observed in patients with right parietal damage and left visual-field neglect, whose ability to attend to contralesional space was impaired. Targets appeared at one of four predefined positions inside a placeholder, while a centrally presented schematic face looked toward the target location, toward another location on the same side, toward a location on the opposite side, or straight ahead. Gaze direction was neither relevant for the task nor predictive of the target location. In patients, Vuilleumier could show that in the intact, ipsilesional hemifield, attention was selectively directed to the exact cued location; in the contralesional hemifield, by contrast, attentional orienting was specific only to the cued quadrant. In healthy controls, gaze direction always led to a shift of attention to the exact cued position, whereas the other position in the cued hemifield did not receive any facilitation.
Although these findings have provided an important first attempt at assessing the spatial specificity of gaze-cueing effects, it is difficult to generalize them for several reasons. First, while Vuilleumier (2002) showed that gaze direction can produce specific cueing effects under certain conditions, his findings did not specify how cueing effects change as a function of the distance of the target from the cued position. Second, the study was not conclusive as to how the modulation of spatial–attentional allocation by context information actually works: In particular, were specific cueing effects triggered by the gaze cues per se, or rather by the combination of directional information provided by the cue and the presence of context information in the periphery (i.e., predefined placeholders)?
These are important issues, given that context information may impact the spatial specificity of gaze cueing via two different mechanisms: On the one hand, presenting placeholders might cause specific gaze-cueing effects by restricting processing to only a few regions of the visual field where task-relevant events may happen. In this context, cueing effects caused by nonsocial central cues (e.g., arrows) have been shown to be widely distributed when targets were presented in an uncluttered visual field, in which case transitions in performance were evident only for the horizontal and vertical field meridians (Hughes & Zimba, 1985, 1987). Interestingly, however, when targets were presented in predefined placeholders, cueing effects were specific to the exact cued position (e.g., Eriksen & Yeh, 1985; Henderson & Macquistan, 1993; Shepherd & Müller, 1989). On the other hand, humans might expect that changes in gaze direction would be related to the appearance of objects or events at the gazed-at location and would, accordingly, shift their attentional focus only under these conditions to the exact gazed-at position. Evidence for this assumption has come from developmental studies that have shown that sharing attention between two partners is only facilitated when objects are placed in the visual field, thereby providing information about what the other’s gaze is referring to (Striano & Stahl, 2005).
The present study, with adult participants, was designed to investigate whether the allocation of spatial attention in response to social gaze cues is modulated by visual context information—in particular, whether spatially specific cueing effects are inherently induced by gaze cues per se, rather than being due to the interplay of gaze direction and context (i.e., placeholder) information. Spatial-attentional allocation was determined by comparing response times (RTs) as a function of the distance between the cued and target positions. On the basis of the findings for nonsocial cues (Eriksen & Yeh, 1985; Hughes & Zimba, 1985, 1987; Shepherd & Müller, 1989), we hypothesized that the cueing effects for social gaze cues would be spatially specific only when objects were presented as reference frames in the periphery with which the observer’s, as well as the gazer’s, attentional focus could be aligned. If gaze cueing was spatially specific, facilitation would be strongest for the exact cued position, whereas other positions in the cued hemifield would exhibit only weaker facilitation, if any. By contrast, if gaze-cueing effects were not position- but rather hemifield-specific, all positions in the cued hemifield would show equal facilitation.
Experiment 1
The main goal of Experiment 1 was to determine how spatial attention is allocated in response to centrally presented gaze cues when no context information is provided in the periphery: That is, would attention, in this situation, be allocated to the exact cued location, or to a more global region of the field? An answer to this question would be provided by analyzing the cueing effects as a function of the distance of the target from the cued location.
A secondary goal was to examine whether the allocation of attention following gaze cues would be modulated by the type of task to be performed, as previous studies had shown that the size of the attended region varies considerably, dependent on the perceptual task demands (C. J. Downing, 1988; LaBerge, 1983; Müller & Findlay, 1987). To this end, two different types of tasks were introduced in Experiment 1, which differed in their demands on perceptual resolution: target localization (Exp. 1a), which makes low demands, and target discrimination (Exp. 1b), which requires greater resolution. According to C. J. Downing (1988), tasks that are more difficult to solve require narrower attentional foci, whereas less demanding tasks may still be performed effectively with a broader distribution of attention. Thus, for roughly localizing a salient target in the visual field (left vs. right hemifield decision), it may not be necessary to precisely focus attention on the exact target position. Consequently, spatially specific cueing effects might be best, or only, demonstrable in tasks for which higher perceptual resolution is required for successful performance.
Another reason why we used a target discrimination, in addition to the—ubiquitously used (e.g., Friesen & Kingstone 1998)—(left–right) target localization task in Experiment 1 was that localization performance is prone to spatial stimulus–response (S–R) compatibility effects. With left–right target localization (required in Exp. 1a), such effects may be induced, in the valid-cue condition, by the central (gaze) cue pointing to the side on which the (target-congruent) manual response has to be given. That is, the cue might directly facilitate (or preactivate) the response, rather than (solely) attentionally enhancing the processing of the target. In other words, RT facilitation might not (solely) arise from gaze-induced orienting of attention, but also from Simon-like modulations (Simon, 1969) acting at the stages of response preparation and execution (see also Nummenmaa & Hietanen, 2009). Given that the cue might induce a global response bias toward the cued side, this bias might obscure any spatially specific attentional effect deriving from the gaze cueing. Given this reasoning, in this account too, the discrimination task used in Experiment 1b (in which the cue could not logically bias the response) would hold a greater potential to reveal the true distribution of attention in response to gaze cues.
The questions outlined above were investigated by using a modified version of the gaze-cueing paradigm (Friesen & Kingstone, 1998). Instead of one target position on each side, we used nine semicircularly arranged positions in each hemifield, with gaze cues always indicating only either the left or the right position on the horizontal meridian (= central position; see Fig. 1). Our design permitted recording of RTs to targets positioned at different distances from the exact cued location, providing a measure of gaze-cueing effects as a function of the distance between the cued and target positions.

Method
Participants
A group of 36 volunteers participated in Experiment 1, for either course credit or payment (€8/h). Of these participants, 18 were tested on the localization task (Exp. 1a; 13 women, five men; age M = 25.17 years, SD = 3.65, range 20–32), and the other 18 on the discrimination task (Exp. 1b; 11 women, seven men; age M = 22.94 years, SD = 3.21, range 19–32). All of the participants were right-handed and reported normal or corrected-to-normal visual acuity. The testing time was about 1 h for the localization task and about 2 h for the discrimination task (split into two testing sessions).
Apparatus
The experiment was controlled by a Dell Precision 390 computer, with stimuli being presented on a 17-in. Graphics Series CRT G90fB monitor, with a refresh rate set at 85 Hz. RT measures were based on keyboard responses. The participants viewed the monitor from a distance of 57 cm, with their head position centered with respect to the screen and keyboard. The experiment was set up using the Experiment Builder software (SR Research Ltd., Ontario, Canada).
Stimuli
Schematic faces, constructed following Friesen and Kingstone (1998), were used as gaze-cue providers. Faces were drawn in black against a white background. The round face covered an area of 6.8° of visual angle and contained two circles representing the eyes, a smaller circle symbolizing the nose, and a straight line representing the mouth. The eyes subtended 1.0° and were located 1.0° from the central vertical axis and centered on the central horizontal axis of the display. The nose subtended 0.2°, was located 0.9° below the eyes and served as a fixation point. The mouth was 2.2° in length and centered 1.3° below the nose. Black-filled circles appeared within the eyes to represent the pupils. The pupils subtended 0.5° and were centered horizontally and vertically in the eyes (straight gaze) or shifted either leftward (gaze to the left) or rightward (gaze to the right) until they touched the outline eye circles.
In the localization task (Exp. 1a), the target stimulus was a gray dot of 0.5° diameter. In the discrimination task (Exp. 1b), the targets were black capital letters, F or T, measuring 0.8° wide and 1.3° high. The targets could appear at 18 positions (not marked by placeholders) that were equally distributed around an imaginary circle of 6.0° radius centered at the fixation point (Fig. 1a). The resulting radial distance between adjacent target positions was 20°. Gaze direction was manipulated orthogonal to target position: That is, in one third of the trials, gaze was directed to the side on which the target appeared (cued hemifield), and in another third, to the other side (uncued hemifield); in the remaining third of the trials, the face was gazing straight ahead. Importantly, on trials with changes in gaze direction, only the central position on each side was directly gazed at. Consequently, targets in the cued hemifield could appear at radial distances of 0°, 20°, 40°, 60°, or 80° from the specifically cued position.
Design
Experiment 1a (localization task) consisted of 884 trials, and Experiment 1b (discrimination task) of 1,768 trials split into two test sessions of 884 trials each. The experimental sessions started with a block of 20 practice trials preceding eight experimental blocks of 108 trials each. In the localization task, participants were asked to decide whether a target dot was shown on the left or the right side of the screen, and to press “D” with the left index finger for left and “K” with the right index finger for right. In the discrimination task, participants were asked to determine whether an F or a T was presented in the target display. To minimize any target–response associations, half of the participants responded to F by pressing “D” with the left index finger and to T by pressing “K” with the right index finger, and vice versa for the other half of the participants.
The gaze direction (straight, left, right), target side (left, right), target position (1–9), and, in Experiment 1b, target identity (F, T) levels appeared pseudorandomly and with equal frequency within each block. In the localization task, stimulus onset asynchrony (SOA: 300 or 600 ms) was randomized throughout the experiment; in the discrimination task, SOA was blocked and counterbalanced across the two test sessions (i.e., half of the participants started with the short and half with the long SOA).
Cue validity was defined in terms of the combination of gaze direction and target side. Trials with straight-ahead gaze served as the neutral condition. On valid trials, the gaze direction and target side matched, whereas on invalid trials, targets appeared opposite the gaze-cued hemifield.
Procedure
Figure 2a illustrates the sequence of events on a trial. Trial start was signaled by the onset of a fixation cross at the center of the screen. After 400 ms, a face with blank eyes appeared on the screen. After a random time interval of 700–1,000 ms, pupils appeared within the eyes, looking left, right, or straight ahead. Following the gaze cue, a target dot appeared at one of 18 target positions with an SOA of either 300 or 600 ms, measured from the onset of the pupils (the cue) to the onset of the target. The schematic face, pupils, and target remained on the screen until a response was given or until 1,200 ms had elapsed. The intertrial interval (ITI) was 680 ms.

Sequence of trials in a localization and discrimination tasks and b the saccade task.
Prior to the test sessions, participants were instructed to fixate the central cross as long as it was shown on the screen. They were told that following the fixation cross, a drawing of a face with blank eyes would appear at the center of the screen and that they now had to fixate the nose of the face. Furthermore, participants were advised that after the presentation of the face, pupils would appear in the eyes (looking left, right, or straight ahead), followed by a gray target dot/capital letter that could appear anywhere in the field. Participants were expressly informed that the direction in which the eyes looked was not predictive of the location of the target, and they were asked to respond as quickly and accurately as possible when detecting the target.
Analysis
Statistical analyses focused on the comparison of valid and invalid trials as a function of target position. Cueing effects were examined in terms of costs-plus-benefits (invalid – valid), rather than benefits (neutral – valid) and costs (invalid – neutral) with respect to the neutral condition—because neutral trials may not provide an adequate baseline for the separate assessment of cueing effects (Jonides & Mack, 1984). In fact, neutral trials were found to elicit longer RTs than either valid or invalid trials, likely owing to straight-ahead gaze having a holding effect on attention (George & Conty, 2008), making it difficult for the target onset to summon an orienting response (Senju & Hasegawa, 2011).
The spatial specificity of gaze cueing was assessed in a three-way repeated measures analysis of variance (ANOVA) of the RTs, with the factors Cue Validity (valid, invalid), Target Position (1–9), and SOA (300, 600 ms). Spatially specific gaze-cueing effects would be evidenced by a significant interaction between position and validity (over and above a main effect of validity), with enhanced cueing effects for the exact cued position as compared to other positions in the same hemifield. By contrast, spatially nonspecific gaze cueing would manifest in terms of a main effect of validity (not accompanied by a Position × Validity interaction), with equal facilitation for all positions in the cued hemifield.
To more precisely determine whether and how gaze-cueing effects varied as function of the distance of the target from the cued position, a one-way repeated measures ANOVA was conducted on the gaze-cueing effects [ΔRT(invalid – valid)] with the factor Cue–Target Distance (0°, 20°, 40°, 60°, 80°). Cueing effects were calculated as the RT difference for a given position (e.g., the position 40° in the upper left quadrant) between trials on which this position was validly cued (i.e., gaze directed to the left) versus when this position was invalidly cued (i.e., gaze directed to the right), with cueing effects collapsed across the two hemifields.
Results
Misses (localization, 0.44 %; discrimination, 0.29 %) and incorrect responses (localization, 4.20 %; discrimination, 3.31 %), as well as outliers (±2.5 SDs from an individual participant’s condition means), were excluded from the analysis. The mean RTs and standard errors for valid, neutral, and invalid trials are presented in Table 1 as a function of target position and SOA. As SOA did not have an influence on the spatial specificity of cueing [localization, F(16, 272) = 1.054, p = .401; discrimination, F < 1], the data were collapsed across this factor, and only validity and position effects were considered further. The results of the statistical analyses for all trial types (neutral, valid, invalid) are summarized in Table 2.
Experiment 1a: Localization task
The ANOVA of the RTs, with the factors Validity and Position, revealed the following effects: Mean RTs were shorter overall on valid than on invalid trials [validity: F(1, 17) = 29.543, p < .001, η 2 = .635]. Furthermore, responses were slower to targets that appeared closer to, as compared to targets located farther away from, the vertical midline of the display [position: F(8, 136) = 64.030, p < .001, η 2 = .790]. Importantly, the general RT benefits for valid as compared to invalid trials appeared to be of equal magnitude for all target positions, indicating that gaze cueing was equally strong for all positions in the cued hemifield [Validity × Position: F(8, 136) = 1.497, p = .164, η 2 = .081, 1–β = .406]. In line with this, the gaze-cueing effects were not modulated by the distance between the cue and the target [main effect of Distance in the ANOVA of cueing effects: F(4, 68) = 0.282, p = .889, η 2 = .016, 1–β = .677]; see Fig. 3a.

Gaze-cueing effects as function of the distance between cued position and target position (uncluttered visual field). a Results of Experiments 1a and b (18 target positions). b Results of Experiments 2a and 2b (six target positions). The solid lines depict results for target localization, the dotted lines for target discrimination, and the dashed lines for the saccade task.
Experiment 1b: Discrimination task
As in Experiment 1a, RTs were shorter on valid than on invalid trials [Validity: F(1, 17) = 11.957, p = .003, η 2 = .413], indicating that gaze cues facilitated the discrimination of targets in the cued hemifield. In contrast to Experiment 1a, RTs did not differ among the nine target positions in the cued hemifield [Position: F(8, 136) = 1.418, p = .194, η 2 = .077, 1–β = .406]; that is, in contrast to target localization, target discrimination was equally difficult, however close a target was to the vertical midline. Importantly, the cueing effects were equivalent for all target positions [Distance: F(4, 68) = 0.088, p = .986, η 2 = .005, 1–β = .677], providing evidence that gaze facilitated target discrimination generally for the whole cued hemifield, rather than specifically for gazed-at locations [Validity × Position: F(8, 136) = 1.166, p = .324, η 2 = .064, 1–β = .406]; see Fig. 3a.
Comparison between Experiments 1a and 1b
In a follow-up ANOVA, the gaze-cueing effects were compared between the target localization (Exp. 1a) and target discrimination (Exp. 1b) tasks. This ANOVA, with Task Type (localization, discrimination) as a between-subjects factor and Validity (valid, invalid) and Position (1–9) as within-subjects factors, revealed the essential patterns of cueing effects to be similar for both types of task: While the RTs were shorter overall and the cueing effects smaller overall for the discrimination versus the localization task [Task, F(1, 34) = 18.900, p < .001, η 2 = .357; Task × Validity, F(1, 34) = 16.324, p < .001, η 2 = .324], the spatial distribution of the cueing effects [Validity × Position: F(8, 272) = 1.354, p = .238, η 2 = .038, 1–β = .903] was not influenced by the task to be performed [Task × Validity × Position: F(8, 272) = 1.389, p = .224, η 2 = .039, 1–β = .903]: The effects were of equivalent magnitudes for all positions in the cued hemifield for both task types. The only other effect involving task was the Task × Position interaction [F(8, 272) = 43.793, p < .001, η 2 = .563], due to RTs varying as a function of the distance of the target from the vertical midline in the localization but not the discrimination task.
Discussion
The main goal of Experiment 1 was to investigate the distribution of attention following a central gaze cue (when no context information was available in the periphery). Our findings clearly showed equal RT benefits for all targets that appeared (at one of the nine positions) in the cued hemifield (relative to the corresponding positions in the uncued hemifield), indicating that changes in gaze direction caused cueing effects that were not specific to the exact gazed-at location. In the localization task, RTs were slower the closer that the target was located to the vertical midline, likely owing to the fact that it is harder to make a left/right localization decision for targets appearing closer to, rather than farther away from, the vertical axis. Consistent with this, a main effect of position was not found in the discrimination task; rather, the difficulty of discriminating between an F and a T was equivalent for all nine target positions, however close they were to the vertical midline. Importantly, the position effect in the localization task was not modulated by validity; that is, gaze cueing was not enhanced for the exact cued position relative to the other positions within the cued hemifield. Furthermore, at variance with the expectation that specific cueing effects would more likely be observed in tasks requiring greater perceptual resolution, the cueing effects were equally distributed across the cued hemifield, even in the discrimination task. Thus, taken together, the cueing effects were spatially nonspecific, with all positions in the cued hemifield receiving equal facilitation, in both the localization and discrimination tasks. Changes in RTs occurred only when the vertical meridian was crossed from the cued to the uncued hemifield (ΔRT = 17 ms). Furthermore, the cueing effects were global for short (300 ms) as well as for long (600 ms) cue–target SOAs.
Although gaze-cueing effects were spatially nonspecific with both types of task, changing the task had a considerable influence on the overall size of cueing benefits: These were significantly reduced in the discrimination as compared to the localization task. Given that the effect of gaze cueing decays with time (Friesen & Kingstone, 1998), this reduction might, in part, be attributable to the extended processing time required to solve the discrimination task. Another explanation would be that gaze cueing not only induces attentional orienting toward the cued hemifield, but also interacts with spatial S–R compatibility effects along the lines sketched above. As compared to the localization task, in which the cue might induce a general bias to produce a directionally corresponding left/right response (in addition to inducing attentional orienting), the discrimination task measures cueing effects independent of spatial S–R compatibility. This additional response bias component might explain why the cueing effect was larger in the localization task. Nevertheless, given that the cue–response compatibility effect is additive to that of the attentional effect of cueing, the localization task remains a valid alternative to the discrimination task, for three reasons: (1) Processing of the target and response preparation after cue presentation can be accomplished faster for localization than for discrimination tasks, thus making them more sensitive for examining cue-induced effects on attentional orienting at different SOAs; (2) target localization is easier for participants to perform; and (3) localization requires only half as many trials as the discrimination task.
Experiment 2
Although the essential results were consistent in Experiments 1a and 1b, they were not directly comparable with those of Vuilleumier (2002), who had used a smaller number of possible target positions (two per hemifield). Importantly, differences in set size could account for differences in the spatial allocation of attention, as has been shown for the inhibition-of-return (IOR) effect (Birmingham, Visser, Snyder, & Kingstone, 2007). This is because increasing the number of target positions increases the proximity between cued and uncued locations, while at the same time decreasing the spatial predictivity of the cues. Thus, to reveal possible effects arising from the number of target positions, in Experiment 2 we examined the spatial specificity of gaze cueing using a reduced number of positions; that is, would spatially nonspecific gaze-cueing effects still be obtained when the number of potential target positions within a hemifield was reduced from nine (Exp. 1) to three?
We had two further objectives: The first was to test more directly for differences between target localization and target discrimination by manipulating task type within subjects (Exp. 2a), in contrast to the between-subjects manipulation in Experiment 1a and b. The other objective was to examine whether a pattern of spatially nonspecific gaze-cueing effects would also be observed with overt shifts of attention (involving eye movements to the target), rather than the covert shifts required in Experiment 1. In the context of gaze-cueing effects, it has been shown that the mere observation and the actual execution of eye movements activate similar cortical regions (Grosbras, Laird, & Paus, 2005), and that even covert shifts of attention activate the motor system, triggering the preparation of an eye movement to the cued position (Friesen & Kingstone, 2003; Rizzolatti, Riggio, Dascola, & Umiltà, 1987). However, on the basis of the results of Experiment 1, it would appear that the mere (covert) programming of a saccade is not sufficient to induce specific cueing effects for the exact gaze-cued position. Rather, it might be that the requirement to actually execute eye movements to the target, together with the preparation of a saccade in response to the gaze cues, is essential for inducing spatially specific cueing effects. If this is true, participants would be faster to make saccades to targets appearing at gazed-at positions, as compared to targets at uncued locations in the cued hemifield. This prediction was tested in Experiment 2b, in which participants were required to make a speeded saccadic response to the target.
As cue–target SOA had no influence on the spatial specificity of gaze cueing in Experiment 1, it was kept constant at 500 ms in Experiment 2. In all other respects, Experiments 2a and 2b were similar to Experiment 1.
Method
Participants
A group of 36 volunteers participated in Experiment 2: 18 participants (13 women, five men) performed localization and discrimination tasks (Exp. 2a: age M = 25.11, SD = 4.03, range 19–34 years; one left-handed), and the other 18 participants (14 women, four men) performed a saccade task (Exp. 2b: age M = 24.94, SD = 5.02, range 21–38; two left-handed). In Experiment 2b, the data of one participant had to be excluded from analysis because of eyetracking problems. The testing times were about 30 min for the localization and saccade tasks, and 1 h for the discrimination task. None of the participants had taken part in Experiment 1.
Stimuli
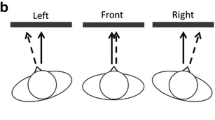
In Experiment 2, targets could appear at only six positions, three within each hemifield—resulting in a radial distance of 60° between adjacent target positions (Fig. 1b). As before, a target could appear at only one of these positions on a trial, and only the position on the horizontal meridian was cued.
Experiment 2a: Apparatus, design, procedure, and analysis
The apparatus in Experiment 2a was the same as that in Experiment 1. Experiment 2a was split into two sessions: Participants performed the localization task in one session and the discrimination task in the other session. Half of the participants started with the localization task, and the other half with the discrimination task. The localization task consisted of 380 trials, with a block of 20 practice trials preceding the 20 test blocks of 18 trials each. The discrimination task consisted of 740 trials, with a block of 20 practice trials and 20 test blocks of 36 trials each. Gaze direction (straight, left, right), target side (left, right), and target position (top, center, bottom) were selected pseudorandomly and appeared with equal frequency within each block (with the SOA between cue and target onset fixed at 500 ms). In the discrimination task, target identity (F, T) was also varied.
The data were analyzed in a three-way repeated measures ANOVA with the factors Task Type (localization, discrimination), Validity (valid, invalid), and Position (top, center, bottom).
Experiment 2b: Apparatus, design, procedure, and analysis
In Experiment 2b, the stimuli were presented on a Dell CRT color monitor, with the refresh rate set at 100 Hz. Monocular eyetracking of the left eye was performed using an EyeLink 1000 system in combination with a tower-mounted chin-and-head rest (SR Research Ltd., Ontario, Canada). Viewing distance was fixed at 55 cm, and eye data were sampled at 1000 Hz with a spatial resolution of 0.01°.
Experiment 2b consisted of 380 trials, with a block of 20 practice trials preceding five test blocks of 72 trials each. Figure 2b provides an illustration of the sequence of events in the saccade task, in which participants were instructed to make, as quickly and accurately as possible, a saccade from the nose of the schematic face (starting position) to the location of the target.
Prior to the experiment, the eyetracker was calibrated. Participants had to fixate the central fixation cross for 400 ms to initiate a trial. Technically, this required the participant’s eye position to remain for a 400-ms period within a tolerance region 1° in diameter around the cross. Achieving successful fixation triggered the appearance of a schematic face with blank eyes, while the fixation cross remained visible on the screen. After a further 400 ms, the fixation cross was replaced by the nose of the schematic face, which participants were instructed to fixate. After a random time interval (700–1,000 ms), pupils appeared within the eyes, looking left, right, or straight ahead. Participants were told that the direction in which the eyes were looking was not predictive of target location. After successful fixation for a further 500 ms, the target appeared at one of six possible positions. If fixation was not maintained successfully, the instruction “Please fixate the nose to proceed” was displayed at fixation. The schematic face, pupils, and target remained on the screen until a successful saccade was made or until 4,000 ms had elapsed, whichever came first. During the experiment, the saccade RT (SRT) was measured, which was defined as the time interval between target onset and successful landing of the saccade in the region of interest (1° in diameter) around the target. The ITI between consecutive trials was 680 ms. Participants were instructed to take a short break after each test block. Before starting the next block, the eyetracker was recalibrated.
Results
In the saccade task, the only error that could occur was a miss. Misses (localization, 0.15 %; discrimination, 0.75 %; saccade, 3.42 %), incorrect responses (localization, 1.85 %; discrimination, 5.37 %), and outliers (±2.5 SDs from an individual participant’s mean) were excluded from the analysis. The mean RTs (or SRTs) for valid, neutral, and invalid trials are presented in Table 3 as a function of target position. Results of the statistical analyses for all trial types (neutral, valid, invalid) are given in Table 2.
Experiment 2a
RTs were shorter for valid than for invalid trials [Validity: F(1, 17) = 26.257, p < .001, η 2 = .607], but did not vary as a function of position [Position: F(2, 34) = 2.970, p = .096, η 2 = .149, 1–β = .627]. Overall, participants were faster at localizing than at discriminating targets [Task: F(1, 17) = 157.788, p < .001, η 2 = .903], and cueing effects were more marked in the former than in the latter condition [Task × Validity: F(1, 17) = 4.996, p = .039, η 2 = .227]. Most importantly, the distance between the cued position and the target position did not modulate the size of gaze-cueing effects [Distance: F(1, 17) = .002, p = .967, η 2 < .001, 1–β = .717], indicating that all positions in the cued hemifield were equally facilitated [Validity × Position: F(2, 34) = .563, p = .575, η 2 = .032, 1–β = .627]. This pattern of spatially nonspecific gaze-cueing effects was evident for both the localization and discrimination tasks [Task × Validity × Position, F(2, 34) = .627, p = .490, η 2 = .051, 1–β = .627; Task × Distance, F(1, 17) = .562, p = .464, η 2 = .032, 1–β = .717]; see Fig. 3b.
Comparison between Experiments 1 and 2a
To examine whether the number of target positions influenced the size of gaze-cueing effects, we compared the results of Experiment 2a (three positions per hemifield) with those of Experiment 1 (nine positions per hemifield) in a meta-analysis of the effect sizes (Rosenthal & DiMatteo, 2001). As the size of the cueing effect is reflected in the main effect of validity, two separate meta-analyses were carried out on the estimated effect sizes for validity: one for the localization and one for the discrimination task. The estimated effect sizes r were as follows: Experiment 1a, r 1 = .797 (localization, 18 positions); Experiment 1b, r 2 = .643 (discrimination, 18 positions); Experiment 2a, r 3 = .678 (localization, six positions); and r 4 = .543 (discrimination, six positions). We found no significant difference in the estimated effect sizes for either target localization (r 1 vs. r 3, z = .725, p = .154) or target discrimination (r 2 vs. r 4, z = .421, p = .183), indicating that the sizes of the cueing effects were comparable between experiments and were not systematically influenced by the number of possible target positions.
Experiment 2b
Comparable to Experiments 1 and 2a (covert attention), SRTs in the saccade task were shorter for valid than for invalid trials [Validity: F(1, 16) = 63.562, p < .001, η 2 = .799], indicating that gaze cues expedited saccadic reactions when the gaze was directed toward the hemifield in which the target was subsequently presented. Furthermore, the SRTs were generally shorter for targets presented on the horizontal meridian (center position) than for targets in the upper and lower quadrants (top and bottom position) [Position: F(2, 32) = 7.161, p = .003, η 2 = .309]. However, position did not modulate the size of the gaze-cueing effects [Validity × Position: F(2, 32) = 0.323, p = .726, η 2 = .020, 1–β = .599], which were equivalent for all positions in the cued hemifield, independent of the distance of the target from the cued position [Distance: F(1, 16) = 0.198, p = .662, η 2 = .012, 1–β = .819]; see Fig. 3b.
Discussion
Experiment 2a
Experiment 2a demonstrated that (1) spatially nonspecific cueing effects are also found when the number of target positions within a hemifield is reduced, while (2) the size of the gaze-cueing effect itself is unaffected by this reduction. Thus, spatially nonspecific cueing effects are more likely attributable to attention being distributed equally over the cued (but unstructured) hemifield, rather than to set-size effects.
Note that the finding of spatially nonspecific cueing effects, even with the reduced number of target positions, is unlikely to be attributable to the use of schematic, instead of realistic, gaze stimuli. In a prior study with a human and a robot gazer, we found participants to be very precise in indicating the gaze direction of the robot’s schematic eyes; indeed, acuity did not differ between the realistic human and schematic robot eyes (Wiese et al., 2012). This strongly suggests that the schematic cues used in the present study were precise enough for participants to perceive them as pointing in a specific direction, rather than just globally indicating a whole hemifield.
Furthermore, the spatially nonspecific cueing effects are unlikely to be due to the fact that the schematic face was consistently looking at the central position on the horizontal midline (and never at any of the other potential target positions) in a hemifield, which might, for some reason, induce a global bias toward the cued side. This was effectively ruled out by a control experiment in which the (spatially nonpredictive) gaze cue was equally likely to be directed to positions in the lower and upper hemifield quadrants, as well as to the central position on the horizontal midline. In all other respects, the experiment was comparable to the localization task of Experiment 2a: The results obtained from ten participants (six female, four male; age M = 25 years, range 20–30; all right-handed) mirrored the findings of Experiment 2a, as evidenced by a repeated measures ANOVA with the factors Validity (valid, invalid), Gaze Direction (top, center, bottom), and Target Position (top, center, bottom): RTs were shorter on valid than on invalid trials [Validity: F(1, 9) = 13.831, p = .005, η 2 = .606], whether the lower, the central, or the upper position was cued. The RTs were also longer for positions located closer to the vertical midline [Target Position: F(2, 18) = 25.590, p < .001, η 2 = .740], as is typical for left–right localization. Importantly, the cueing effects did not differ between the exact gazed-at position and the respective other positions in the cued hemifield, whichever position had been cued [Validity × Gaze Direction × Target Position: F(4, 36) = 0.816, p = .523, η 2 = .083, 1–β = .494]. Thus, general cueing effects for the whole gaze-cued hemifield were still found under conditions in which a central gaze cue was directed to one of all possible target positions (rather than just to the central position) on one or the other side.
Experiment 2b
The goal of Experiment 2b was to examine the hypothesis that gaze-cueing effects would be spatially specific if the task required participants to actually execute a saccade to the target (together with the implicit, covert preparation of an eye movement in response to the gaze cue). However, at variance with this hypothesis, SRTs mirrored the previous findings of nonspecific cueing effects: Facilitation was equivalent for all target positions within the cued hemifield, with no extra enhancement for the exact gazed-at position. Most importantly, as was shown in a meta-analysis of the effect sizes for the main effect of validity, overt orienting in response to gaze cues was not more robust than mere covert orienting [r 1 = .779 (Exp. 2a), r 2 = .894 (Exp. 2b); r 1 vs. r 2, z = 1.07, p = .113], which is in line with results of Friesen and Kingstone (2003).
Thus, going beyond previous findings, the results of Experiment 2b show that even for overt shifts of attention, gaze-cueing effects are not confined to the exact gazed-at position; rather, gaze cues facilitate equally the programming of an eye movement to any position in the cued hemifield. This pattern is consistent with Rizzolatti et al. (1987), who showed that the eye movement program induced by symbolic cues specifies only the left/right direction parameter of a saccade, resulting in a global benefit for the cued hemifield, but not for the exact cued position. This finding is very plausible, given that oblique saccades are composed of a vertical and a horizontal component that are implemented by separate neuronal channels in the brain stem and are executed by distinct groups of motor neurons and eye muscles (Bahill & Stark, 1977; King, Lisberger, & Fuchs, 1986). Consequently, given that vertical and horizontal components of saccadic eye movements are planned and generated independently of each other and that oblique saccades are more difficult to generate in general (as they involve the coordination of two separate components), it is possible that observing a lateral gaze shift also triggers the preparation of an eye movement in only one, dominant (i.e., horizontal) channel, but not the other (i.e., vertical). Thus, when presented with horizontal gaze shifts, only the horizontal (but not the vertical) component of an eye movement is prepared, resulting in SRT benefits for left/right but not for up/down saccadic eye movements.
In sum, Experiments 1 and 2 indicated that when no visual context information is provided to which gaze cues could refer, (1) spatial attention is not allocated to the exact cued position, but facilitates target localization and discrimination at all positions in the cued hemifield; (2) nonspecific gaze-cueing effects are independent of task demands; (3) the size of gaze cueing is not influenced by the number of target positions; and (4) nonspecific cueing effects are also found for overt attention shifts.
Experiment 3
Experiment 3 was designed to investigate whether the allocation of attention induced by gaze cues is sensitive to context information presented in the visual field. Assuming that gaze direction provides important information about another person’s internal states, we hypothesized that gaze cues would only be interpreted specifically in relation to external reference objects that represent the targets of the other’s attentional focus. If so, presenting targets inside predefined reference objects would be expected to turn spatially nonspecific gaze-cueing effects into specific effects, as a link between gaze direction and potential objects of interest could already be established before the target appeared.
Method
The methodological details were generally the same as in Experiment 2a, with the following exceptions: A group of 24 volunteers (17 women, seven men) participated in Experiment 3 (age M = 24.54 years, SD = 2.63, range 21–30; all right-handed); none of them had taken part in the previous experiments. Targets were presented in predefined placeholder objects that consisted of a white rectangle surrounded by a black line (1.0° wide, 1.5° high); these peripheral placeholders appeared simultaneously with the blank-eyed face in the display center. Next, pupils appeared inside the eyes, creating the impression of the face looking at one of the placeholders. After 500 ms, the target—either a dot (localization task) or a letter (discrimination task)—was presented centered inside one of the placeholders. The spatial specificity of gaze cueing was assessed by a two-way repeated measures ANOVA of the RTs, with the factors Validity (valid, invalid) and Position (top, center, bottom), as well as by an ANOVA of the cueing effects [i.e., ΔRT(invalid – valid)] with the factor Cue–Target Distance (0°, 60°).
Results
Misses (localization, 1.89 %; discrimination, 0.39 %), incorrect responses (localization, 1.54 %; discrimination, 4.74 %), and outliers (±2.5 SDs from an individual participant’s mean) were excluded from the analysis. The mean RTs for valid, neutral, and invalid trials are presented in Table 4 as a function of target position. Results of the statistical analyses for all trial types (neutral, valid, invalid) are presented in Table 2.
As in the first two experiments, RTs were shorter for valid than for invalid trials [Validity: F(1, 23) = 16.926, p < .001, η 2 = .424], and participants were always faster at localizing than at discriminating targets [Task: F(1, 23) = 130.607, p < .001, η 2 = .850]. Again, gaze cueing effects were larger in the localization than in the discrimination task [Task × Validity: F(1, 23) = 5,920, p = .023, η 2 = .205], and performance in the localization, but not the discrimination, task depended on target position [Task × Position: F(2, 46) = 9.508, p < .001, η 2 = .292]. Most importantly, this time the cueing effects were modulated by target position, with larger effects for the exact gazed-at position than for the other two positions in the cued hemifield [Validity × Position: F(2, 46) = 9.113, p < .001, η 2 = .284]. In line with this, the gaze-cueing effects within the cued hemifield varied as a function of the distance between cue and target [Distance: F(1, 23) = 13.133, p = .001, η 2 = .363]. Note that although gaze cueing was strongest for the exact cued position, we still found facilitation for the other two positions in the cued hemifield. This pattern indicates that, under the conditions of Experiment 3, gaze cues caused a significantly stronger facilitation effect for the exact gazed-at position than for the other two positions in the cued hemifield.
As can be seen from Fig. 4, spatially specific gaze cueing was evident for both types of task (dotted lines). Statistically, the Task × Validity × Position interaction [F(2, 46) = 1,301, p = .282, η 2 = .054, 1–β = .770] and the Task × Distance interaction [F(1, 23) = 2.049, p = .166, η 2 = .082, 1–β = .936] were nonsignificant. Also, when the localization and discrimination tasks were analyzed separately, the critical Validity × Position interactions [localization, F(2, 46) = 6.054, p = .005, η 2 = .208; discrimination, F(2, 46) = 3.632, p = .034, η 2 = .136], as well as the effects of cue–target distance [localization, F(1, 23) = 8.091, p = .009, η 2 = .260; discrimination, F(1, 23) = 8.675, p = .007, η 2 = .274], were significant for both types of tasks.

Comparison between Experiments 2a (without context information, solid lines) and 3 (with context information, dotted lines). a Results of the localization task. b Results of the discrimination task. With both types of task, adding context information in the form of predefined position placeholders changed a general cueing effect for the whole cued hemifield into a more specific cueing effect for the exact gazed-at position.
Importantly, as is depicted in Fig. 4, a comparison between Experiments 3 (with placeholders—dotted lines) and 2a (without placeholders—solid lines) revealed the spatial specificity effect to be significantly enhanced when context information was presented in the periphery [Distance × Experiment: F(1, 40) = 8.262, p = .006, η 2 = .171], in both the localization and discrimination tasks [Distance × Experiment × Task, F(1, 40) = .515, p = .477, η 2 = .013, 1–β = .997; Distance × Experiment (localization), F(1, 40) = 4.206, p = .046, η 2 = .095; Distance × Experiment (discrimination), F(1, 40) = 6.610, p = .014, η 2 = .142]. This pattern indicates that visual context information changes the general cueing effect that is observable under conditions without context information into a specific cueing effect for the exact cued position, with significantly stronger facilitation for the exact gazed-at position than for the other positions in the cued hemifield. Figure 4 suggests that this change in the spatial specificity of gaze cueing is due to increased facilitation for the exact gazed-at position, coupled with reduced facilitation for the uncued positions in the cued hemifield. However, when comparing cueing effects for the same positions (exact, other) between the conditions with and without context information (across experiments) separately for the localization and discrimination tasks, only the reduced facilitation for the other positions in the discrimination task turned out to (just) be significant [t(40) = 2.753, p = .036; all other ts < 1.506, ps > .140].
Discussion
In Experiment 3, we examined whether the specificity of gaze cueing is modulated by visual context information in the periphery—in particular, whether spatially specific cueing effects are dependent on context information, such as objects of interest being available in the field to which the gazer’s attentional focus could be directed. The assumption that cueing effects are modulated by context information is consistent with previous findings on the spatial specificity of nonsocial symbolic cues: While Hughes and Zimba (1985, 1987) found general cueing effects for larger regions of the visual field (i.e., hemifields or quadrants) when no context was provided, spatially specific cueing effects were observed when targets were presented at predefined placeholder locations (e.g., Eriksen & Yeh, 1985; Henderson & Macquistan, 1993; Shepherd & Müller, 1989). On the basis of these observations, we hypothesized that the manifestation of specific gaze-cueing effects critically depends on the availability of context information (i.e., placeholders) in the periphery, which would restrict processing to only a few regions of the visual field where task-relevant events were likely to occur. Experiment 3 clearly supported this hypothesis. In contrast to the first two experiments, it revealed an interaction between validity and position: Gaze-cueing effects were significantly enhanced for the exact gazed-at position, as compared to the other two positions within the cued hemifield.
This pattern points to an interplay of two components that determine the spatial specificity of gaze-cueing effects: (1) a general orienting component that is activated bottom-up by gaze cues, whether or not further context information is provided; and (2) a top-down component that comes into play only if contextual information is available, permitting the gaze direction to be linked to specific reference objects. While the bottom-up component results in a general gaze-cueing effect for the whole gaze-cued hemifield, the top-down component appears to induce a facilitation effect that is spatially specific to the exact gazed-at position.
One possible challenge to this interpretation of the data is that when placeholder structures are available in the periphery, participants are more likely to make a saccade in response to the gaze cues, which could potentially generate a pattern of spatially specific cueing effects. In order to validate that participants did heed the instructions to maintain fixation on the central fixation cross throughout a trial, we tested six additional participants (age: M = 27 years, range 23–30; five female, one male; all right-handed) in an eyetracking experiment using the same displays, with potential target positions in the periphery marked by placeholders, as in Experiment 3. Only the discrimination task was tested, on the basis of the assumption that the likelihood of making eye movements to the cued (or target) location would be highest when task performance required greater perceptual resolution. However, even under these conditions, fixations remained on the central cross (i.e., within a tolerance area of ±1.5°) on 94.6 % of all trials. Of the remaining 5.4 % of the trials, only 0.2 % of the eye movements went to the target (with a tolerance area of ±1.5°), indicating that participants followed the instructions and did not execute saccades toward the current target location. For those trials on which participants maintained central fixation during the whole trial, the results were comparable to those of Experiment 3 (first 12 participants): RTs were shorter overall for targets appearing in the cued rather than the uncued hemifield (442 vs. 447 ms) [Validity: F(1, 16) = 4.485, p = .05, η 2 = .219], as well as for targets presented on the horizontal meridian as compared to targets in the upper and lower field quadrants (437 vs. 448 ms) [Position: F(2, 32) = 19.260, p < .001, η 2 = .546]. Importantly, gaze-cueing effects were larger for the exact gazed-at position than for the other positions in the cued hemifield (12 vs. 1 ms) [Validity × Position: F(2, 32) = 8.780, p = .001, η 2 = .354]. Most importantly, the patterns of results did not differ between the eye movement control experiment and Experiment 3 (discrimination task): The Experiment × Validity [F(1, 16) = .143, p = .710, η 2 = .009, 1–β = .712], Experiment × Position [F(2, 32) = 2.038, p = .147, η 2 = .105, 1–β = .625], and Experiment × Validity × Position [F(2, 32) = 2.326, p = .114, η 2 = .127, 1–β = .625] interactions were all nonsignificant. This makes it unlikely that the spatially specific gaze-cueing effects observed in Experiment 3 could be attributed to systematic saccades to potential target positions marked by the placeholders.
General discussion
The goal of the present study was to investigate the spatial allocation of attention induced by nonpredictive gaze cues. In Experiments 1 and 2, we examined how gaze-cueing effects were distributed in an uncluttered visual field, dependent on the type of task, the number of possible target positions (set size), and whether attention was oriented covertly or overtly. In Experiment 3, we then examined the influence of context information, in the form of peripheral position placeholders, on visuospatial orienting in response to gaze cues. The results revealed that the spatial specificity of gaze cueing is critically dependent on the availability of context information: Nonspecific gaze-cueing effects were found consistently when no placeholder objects to which the gaze cues were presented in the periphery, and this general cueing effect was independent of the type of task to be performed (localization, discrimination), the set size, and whether attention had to be shifted covertly or overtly. In contrast, when reference objects were provided in the periphery, the gaze cues induced a cueing effect specific to the exact gazed-at position.
The present results help integrate different theories of spatial attention with regard to their validity for gaze cueing. On the one hand, the results confirm the assumptions of general-region theories of attention—such as the meridian-boundary model (Hughes & Zimba, 1985, 1987)—by showing that gaze cues give rise to spatially nonspecific, hemifield cueing effects when no further information about potential reference objects in the periphery is provided. On the other hand, the results are also consistent with specific-location theories of attention—such as the zoom-lens model (Eriksen & Yeh, 1985) or the gradient model (e.g., C. J. Downing & Pinker, 1985)—by showing that attentional resources can be allocated to specific, narrow regions of the visual field when objects that can serve as reference points for another’s gaze direction are presented in the periphery.
The present findings argue in favor of the idea that gaze direction cues can initiate both a general and a specific component of attentional orienting, dependent on the availability of context information in the visual scene: If no further information is provided, only a general directional-orienting component is activated (bottom-up), yielding a global cueing effect for the whole gaze-cued hemifield. By contrast, if context information is available, a spatially specific component (top-down) comes into play, inducing a facilitation effect for the exact gazed-at position. However, it is not entirely clear from the presented data whether the modulation of the spatial specificity of gaze-cueing effects is due to a trade-off relationship between the top-down and bottom-up components, or whether the top-down component is simply additive to the bottom-up component. Whatever the precise relationship between the two orienting components, the specific component seems to critically depend on the availability of context information, and is thus likely to result from the combination of two separate sources of information: the linking of context information provided in the visual field with directional information from the gazer’s eyes.
The proposal that visual information from both the eye region and the periphery is integrated when processing gaze direction is in line with results from Lobmaier et al. (2006). They showed that objects in the visual field can capture the perceived gaze direction of an interaction partner, causing systematic biases in estimating where the other is looking. Arguably, rather than being achieved directly (in a bottom-up manner), this linkage may involve complex, higher-level processes of cross-referencing central gaze direction with peripheral structures, which may then exert a top-down-like effect on the allocation of attention. However, this does not rule out that the computations involved could be highly automatized and that, once it is established which peripheral object is referred to by the gaze cue, this object becomes an effective attractor for the allocation of attention.
The idea that gaze direction can induce both a general and a specific cueing effect, the latter being dependent on the availability of peripheral context information, is also consistent with B. S. Gibson, Thompson, Davis, and Biggs (2011). They showed that the extent to which attention is oriented to specific locations in response to symbolic cues depends on the expectancies that observers have about the direction and distance of the upcoming target: While directional information is provided by the cue itself, distance information is either derived from experience (e.g., learning that targets always appear at the same eccentricity) or provided by position placeholders (see also Shepherd & Müller, 1989). However, in the present study, simply presenting targets consistently at the same distance from fixation did not give rise to spatially specific cueing effects (Exps. 1 and 2); rather, specific effects were dependent on the presence of position placeholders (Exp. 3), suggesting that reference objects are critical for the exact interpretation of gaze direction.
This notion would also be consistent with joint-attention theories, according to which attending to the attentional focus of others is an important prerequisite for sharing information in social interactions (Butterworth & Jarrett, 1991; Scaife & Bruner, 1975). Of importance with respect to the present findings, it has been shown that joint attention can only be established when objects are placed in the visual field, with which the other’s gaze can be aligned (Butterworth & Jarrett, 1991; Moore & Corkum, 1995). In line with this, our findings showed that the presence of objects in the visual field is also essential for inducing spatially specific gaze-cueing effects in adults.
The evidence available to date suggests that what has been established in the present study with regard to the spatial specificity of gaze cueing may also apply to nonsocial symbolic (e.g., arrow) cues in general: Symbolic cueing toward an uncluttered visual field produces spatially nonspecific cueing effects (Hughes & Zimba, 1985, 1987), whereas cueing effects are spatially specific when possible target locations are predefined by placeholders (e.g., Eriksen & Yeh, 1985; Henderson & Macquistan, 1993; Shepherd & Müller, 1989). Nevertheless, given that these studies were quite different with regard to the stimulus arrangements and tasks used (the only commonality being the use of central arrow cues), the generality issue would need to be examined in further, systematic experiments adapting the designs of the present study. However, even if gaze cueing turned out to be a specific instance of symbolic cueing, as concerns the role of visual context for the spatial specificity of cueing effects, it would remain that gaze direction induces cueing effects faster and in a more reflexive manner than do arrow cues (Friesen et al., 2004). Also, gaze-cueing effects may well be particularly reliant on the availability of external objects. Further work would be required to elucidate the exact mechanisms that relate the central information from the cues with peripheral context information, and whether their dynamics are the same with social and with nonsocial symbolic cues.
In summary, the present results reveal a degree of flexibility in the gaze-cueing system that allows for the integration of multiple sources of information to guide attention: When information about possible reference objects in the visual field is lacking, attention is allocated to a broader area, whereas attention shifts are specific to the cued location when a relation between gaze direction and objects of interest can be established. This context-dependent flexibility is adaptive, in that it allows for rapid detection of relevant objects in a constantly changing social environment.
References
Ando, S. (2002). Luminance-induced shift in the apparent direction of gaze. Perception, 31, 657–674.
Anstis, S. M., Mayhew, J. W., & Morley, T. (1969). The perception of where a face or television “portrait” is looking. The American Journal of Psychology, 82, 474–489.
Bahill, A. T., & Stark, L. (1977). Oblique saccadic eye movements—Independence of horizontal and vertical channels. Archives of Ophthalmology, 95, 1258–1261.
Birmingham, E., Visser, T. A. W., Snyder, J. J., & Kingstone, A. (2007). Inhibition of return: Unraveling a paradox. Psychonomic Bulletin & Review, 14, 957–963.
Bock, S. W., Dicke, P., & Thier, P. (2008). How precise is gaze following in humans? Vision Research, 48, 946–957. doi:10.1016/j.visres.2008.01.011
Butterworth, G., & Jarrett, N. L. M. (1991). What minds have in common space: Spatial mechanisms for perspective taking in infancy. British Journal of Developmental Psychology, 9, 55–72.
Cline, M. G. (1967). The perception of where a person is looking. The American Journal of Psychology, 80, 41–50.
Downing, C. J. (1988). Expectancy and visual–spatial attention: Effects on perceptual quality. Journal of Experimental Psychology. Human Perception and Performance, 14, 188–202. doi:10.1037/0096-1523.14.2.188
Downing, P., Dodds, C. M., & Bray, D. (2004). Why does the gaze of others direct visual attention? Visual Cognition, 11, 71–79.
Downing, C. J., & Pinker, S. (1985). The spatial structure of visual attention. In M. I. Posner & O. S. M. Marin (Eds.), Attention and performance XI (pp. 171–188). Hillsdale, NJ: Erlbaum.
Driver, J., Davis, G., Ricciardelli, P., Kidd, P., Maxwell, E., & Baron-Cohen, S. (1999). Gaze perception triggers reflexive visuospatial orienting. Visual Cognition, 6, 509–540.
Emery, N. J. (2000). The eyes have it: The neuroethology, function and evolution of social gaze. Neuroscience and Biobehavioral Reviews, 24, 581–604.
Eriksen, C. W., & Yeh, Y.-Y. (1985). Allocation of attention in the visual field. Journal of Experimental Psychology. Human Perception and Performance, 11, 583–597. doi:10.1037/0096-1523.11.5.583
Friesen, C. K., & Kingstone, A. (1998). The eyes have it! Reflexive orienting is triggered by nonpredictive gaze. Psychonomic Bulletin & Review, 5, 490–495. doi:10.3758/BF03208827
Friesen, C. K., & Kingstone, A. (2003). Abrupt onsets and gaze direction cues trigger independent reflexive attentional effects. Cognition, 87, B1–B10. doi:10.1016/S0010-0277(02)00181-6
Friesen, C. K., Ristic, J., & Kingstone, A. (2004). Attentional effects of counterpredictive gaze and arrow cues. Journal of Experimental Psychology. Human Perception and Performance, 30, 319–329. doi:10.1037/0096-1523.30.2.319
Frischen, A., Bayliss, A. P., & Tipper, S. P. (2007). Gaze cueing of attention: Visual attention, social cognition, and individual differences. Psychological Bulletin, 133, 694–724. doi:10.1037/0033-2909.133.4.694
Gale, C., & Monk, A. F. (2000). Where am I looking? The accuracy of video-mediated gaze awareness. Perception & Psychophysics, 62, 586–595.
Gamer, M., & Hecht, H. (2007). Are you looking at me? Measuring the cone of gaze. Journal of Experimental Psychology. Human Perception and Performance, 33, 705–715.
George, H., & Conty, L. (2008). Facing the gaze of others. Clinical Neurophysiology, 38, 197–207.
Gibson, J. J., & Pick, A. (1963). Perception of another person’s looking behavior. The American Journal of Psychology, 76, 386–394.
Gibson, B. S., Thompson, A. N., Davis, G. J., & Biggs, A. T. (2011). Going the distance: Extra-symbolic contributions to the symbolic control of spatial attention. Visual Cognition, 19, 1237–1261. doi:10.1080/13506285.2011.628636
Grosbras, M. H., Laird, A. R., & Paus, T. (2005). Cortical regions involved in eye movements, shifts of attention and gaze perception. Human Brain Mapping, 25, 140–154.
Henderson, J. M. (1991). Stimulus discrimination following covert attentional orienting to an exogenous cue. Journal of Experimental Psychology. Human Perception and Performance, 17, 91–106.
Henderson, J. M., & Macquistan, A. D. (1993). The spatial distribution of attention following an exogenous cue. Perception & Psychophysics, 53, 221–230. doi:10.3758/BF03211732
Hietanen, J. K. (1999). Does your gaze direction and head orientation shift my visual attention? NeuroReport, 10, 3443–3447.
Hietanen, J. K., & Leppänen, J. M. (2003). Does facial expression affect attention orienting by gaze direction cues? Journal of Experimental Psychology. Human Perception and Performance, 29, 1228–1243. doi:10.1037/0096-1523.29.6.1228
Hughes, H. C., & Zimba, L. D. (1985). Spatial maps of directed visual attention. Journal of Experimental Psychology. Human Perception and Performance, 11, 409–430.
Hughes, H. C., & Zimba, L. D. (1987). Natural boundaries for spread of directed visual attention. Neuropsychologia, 2, 5–18.
Jonides, J., & Mack, R. (1984). On the cost and benefit of cost and benefit. Psychological Bulletin, 96, 29–44. doi:10.1037/0033-2909.96.1.29
King, W. M., Lisberger, S. G., & Fuchs, A. F. (1986). Oblique saccadic eye movements of primates. Journal of Neurophysiology, 56, 769–784.
Kingstone, A., Smilek, D., Ristic, J., Friesen, C. K., & Eastwood, J. D. (2003). Attention researchers! It is time to take a look at the real world. Current Directions in Psychological Science, 12, 176–180.
LaBerge, D. (1983). Spatial extent of attention to letters and words. Journal of Experimental Psychology. Human Perception and Performance, 9, 371–379. doi:10.1037/0096-1523.9.3.371
LaBerge, D., & Brown, V. (1989). Theory of attentional operations in shape identification. Psychological Review, 96, 101–124. doi:10.1037/0033-295X.96.1.101
Langton, S. R. H., & Bruce, V. (1999). Reflexive visual orienting in response to the social attention of others. Visual Cognition, 6, 541–567.
Langton, S. R. H., Watt, R. J., & Bruce, V. (2000). Do the eyes have it? Cues to the direction of social attention. Trends in Cognitive Sciences, 4, 50–59.
Lobmaier, J. S., Fischer, M. H., & Schwaninger, A. (2006). Objects capture perceived gaze direction. Experimental Psychology, 53, 117–122.
Moore, C., & Corkum, V. (1995). The origins of joint visual attention. In C. Moore & P. Dunham (Eds.), Joint attention: Its origins and role in development (pp. 61–85). Hillsdale, NJ: Erlbaum.
Müller, H. J., & Findlay, J. M. (1987). Sensitivity and criterion effects in the spatial cuing of visual attention. Perception & Psychophysics, 42, 383–399. doi:10.3758/BF03203097
Nummenmaa, L., & Hietanen, J. K. (2009). How attentional systems process conflicting cues: The superiority of social over symbolic orienting revisited. Journal of Experimental Psychology. Human Perception and Performance, 35, 1738–1754.
Quadflieg, S., Mason, M. F., & Macrae, C. N. (2004). The owl and the pussycat: Gaze cues and visuo-spatial orienting. Psychonomic Bulletin & Review, 11, 826–831.
Rizzolatti, G., Riggio, L., Dascola, I., & Umiltà, C. (1987). Reorienting attention across the horizontal and vertical meridians: Evidence in favor of a premotor theory of attention. Neuropsychologia, 25, 31–40. doi:10.1016/0028-3932(87)90041-8
Rosenthal, R., & DiMatteo, M. R. (2001). Meta-analysis: Recent developments in quantitative methods for literature reviews. Annual Review of Psychology, 52, 59–82.
Scaife, M., & Bruner, J. (1975). The capacity for joint visual attention in the infant. Nature, 253, 265–266.
Schwaninger, A., Lobmaier, J. S., & Fischer, M. H. (2005). The inversion effect of gaze perception reflects processing of component information. Experimental Brain Research, 167, 49–55.
Sebanz, N., Bekkering, H., & Knoblich, G. (2006). Joint action: Bodies and minds moving together. Trends in Cognitive Sciences, 10, 70–76. doi:10.1016/j.tics.2005.12.009
Senju, A., & Hasegawa, T. (2011). Direct gaze captures visuospatial attention. Visual Cognition, 12, 127–144.
Shepherd, M., & Müller, H. J. (1989). Movement versus focusing of visual attention. Perception & Psychophysics, 46, 146–154.
Shulman, G. L., Wilson, J., & Sheehy, J. B. (1985). Spatial determinants of the distribution of attention. Perception & Psychophysics, 37, 59–65.
Simon, J. R. (1969). Reactions toward the source of stimulation. Journal of Experimental Psychology, 81, 174–176. doi:10.1037/h0027448
Striano, T., & Stahl, D. (2005). Sensitivity to triadic attention in early infancy. Developmental Science, 8, 333–343.
Symons, L. A., Lee, K., Cedrone, C. C., & Nishimura, M. (2004). What are you looking at? Acuity for triadic eye gaze. The Journal of General Psychology, 131, 451–469.
Todorović, D. (2006). Geometrical basis of perception of gaze direction. Vision Research, 46, 3549–3562. doi:10.1016/j.visres.2006.04.011
Vuilleumier, P. (2002). Perceived gaze direction in faces and spatial attention: A study in patients with parietal damage and unilateral neglect. Neuropsychologia, 40, 1013–1026.
Wiese, E., Kohlbecher, S., & Müller, H. J. (2012, March). Acuity in estimating gaze direction in human–human and human–robot interaction. Paper presented at the 7th ACM/IEEE International Conference on Human–Robot Interaction, Boston, MA.
Author note
We thank Verena Zierl, Christoph Voelter, Natalia Rabel, and Regina Lanz for help with data collection, and Mark Schroeder for help with programming. This work was supported by the German Research Foundation (Deutsche Forschungsgemeinschaft) within the Excellence Cluster Cognition for Technical Systems (CoTeSys). We also thank the Graduate School of Systemic Neurosciences, Munich, for their support.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Wiese, E., Zwickel, J. & Müller, H.J. The importance of context information for the spatial specificity of gaze cueing. Atten Percept Psychophys 75, 967–982 (2013). https://doi.org/10.3758/s13414-013-0444-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0444-y