
Abstract
When searching for an object, an observer holds a representation of the target in mind while scanning the scene. If the observer repeats the search, performance may become more efficient as the observer hones this target representation, or “search template,” to match the specific demands of the search task. An effective search template must have two characteristics: It must reliably discriminate the target from the distractors, and it must tolerate variability in the appearance of the target. The present experiment examined how the tolerance of the search template is affected by the search task. Two groups of 18 observers trained on the same set of stimuli blocked either by target image (block-by-image group) or by target category (block-by-category group). One or two days after training, both groups were tested on a related search task. The pattern of test results revealed that the two groups of observers had developed different search templates, and that the templates of the block-by-category observers better captured the general characteristics of the category. These results demonstrate that observers match their search templates to the demands of the search task.
Similar content being viewed by others

Practice improves visual search. When observers perform a search task repeatedly, their times decrease exponentially (Heathcote, Brown, & Mewhort, 2000; Suzuki & Goolsby, 2003). Some of this improvement may reflect a general enhancement in scanning efficiency (Sireteanu & Rettenbach, 1995), but most of the improvement is specific to the search task: With practice, observers learn to attend to the target of their search and to ignore distractors (Schneider & Shiffrin, 1977).
When the target and distractor sets are large and varied, observers may learn each set independently. In this case, observers may show a practice effect even when they are trained on the targets and distractors in separate search tasks. (Czerwinski et al. 1992; Mruczek & Sheinberg, 2005). In other cases, the improvements from practice are contingent on a consistent pairing of the target and distractor sets (Schneider & Shiffrin, 1977). One explanation for this contingency is that training allows observers to learn the features of the targets that best distinguish them from the distractors (Corcoran & Jackson, 1979; Lefebvre, Cousineau, & Larochelle, 2008). Observers can then optimize their performance by using these distinctive features as their search template.
The idea that observers search for the most distinctive target features was given compelling support in a study by Navalpakkam and Itti (2007). In their study, observers searched for a line oriented at 55 deg among lines oriented at 50 deg. Using a physiologically plausible model, the authors demonstrated that 55- and 50-deg lines are best discriminated by a feature detector tuned to 60 deg. They then showed that observers do indeed use a 60-deg feature detector when searching for the 55-deg target. Thus, rather than relying on the feature detector that is most sensitive to the target, observers relied on the feature detector that best discriminates the target from the distractors.
In the Navalpakkam and Itti (2007) experiment, the appearance of the target did not vary across trials: It was always a line oriented at 55 deg. In everyday search, variation in the target is inevitable. Repeated search often involves finding different exemplars from a category, and even when repeated search involves the same object, variation in the pose of the object will cause variation in its appearance. Target variation due to exemplar variation or pose variation necessitates search templates that not only distinguish the target from the distractors, but also match the different appearances of the target.
One might imagine that observers deal with variation in the target’s appearance by simultaneously employing several target templates, each associated with a distinct image (a distinct exemplar or a distinct view). Empirical evidence suggests that observers do not use such a strategy. Houtkamp and Roelfsema (2009) examined the effect of target set size on accuracy in rapid serial search. When observers searched for two targets rather than one, their accuracy declined in a way that was best fit by a single-template model, suggesting that observers use only one target template at a time. This result implies that when observers learn to attend to the targets in an everyday search task, they learn the features of the target that are distinctive and that are common across exemplars and across viewpoints.
The experiment reported here examined how observers might learn to search for common category features by examining how variation within a target set affects what is learned about the targets. The experiment was based on the assumption that when observers search repeatedly for targets from a visually coherent category (here, a species of tropical fish), they learn to search for features that are common to the category. In contrast, it is assumed that when observers search for a fixed target image (a particular fish image), they learn to search for distinctive features particular to that target, whether these features are common to the category or specific to the image.
We were motivated to examine this question by an unexpected result in an earlier study (Bravo & Farid, 2009). In this earlier study, observers learned to associate the names of five fish species with an image of a fish from each species. The names were later used to cue the observers as they searched for the fish in coral reef scenes. The name cues facilitated search when the target image was identical to the image that had been associated with the name, but the name cue did not facilitate search when the target was a different image from the same species. Given the visual similarity of fish within a species, this result indicated that observers had learned extremely specific search templates. We were surprised by this result, because such extreme specificity would be detrimental for many everyday search tasks, which, as we have noted, generally involve some degree of target variability. It occurred to us that concentrated training on single images might have caused observers to develop overly restrictive search templates. We wondered whether we could induce observers to develop more general templates by training them on a few images from each species and, critically, by intermixing these images during training.
For the present experiment, we trained 36 observers to search for 16 images of tropical fish. The 16 images consisted of four exemplars from four fish species (Fig. 1). The same set of stimuli was viewed by all observers, but the ways in which the stimuli were blocked varied across observers. For half of the observers, the stimuli were blocked by image. That is, the same fish image served as the target throughout a block of trials (block-by-image condition). For the other half of the observers, the stimuli were blocked by category. That is, the four exemplars from the same category were intermixed within a block of trials (block-by-category condition). Although both sets of observers trained on the same set of stimuli, we expected that the way the stimuli were organized into blocks would affect the specificity of their search templates. We expected that the observers in the block-by-category condition would learn a search template that generalized across exemplars. In contrast, we expected that observers in the block-by-image condition would learn a search template that was more specific to the target image.

The 16 target images arranged in columns by category: copperband butterflyfish, blue tang, saddled butterflyfish, and zebrasoma tang
To assess what the observers learned about the fish targets during training, we tested them 1 or 2 days later on a related task. During the test, the observers once again searched for tropical fish in reef scenes, but this time all 16 target images were intermixed within a block of trials. Before each scene, the observers were cued with one of the studied fish images. After the cue, the search scene was presented, and observers judged whether a fish was present. The target and the cue were always the same species, but they were not always the same image. On some trials, the target was another studied fish from the cue species, while on other trials it was a new fish from that species. We expected that the observers given block-by-category training would show a different pattern of cueing effects than would those given block-by-image training. Because we expected the block-by-category observers to have learned a more general search template, we predicted that they would show greater cueing effects for target images that, although not identical to the cue, were from the same category. Conversely, because we expected the block-by-image observers to have learned a more specific search template, we predicted that they would show cueing effects that were specific for the target image.
Method
Observers
A group of 36 observers were recruited for the study from the Introduction to Psychology subject pool at Rutgers University, Camden. The observers reported having normal or corrected-to-normal visual acuity and normal color vision.
Stimuli
The photo-collage stimuli were created in MATLAB using images downloaded from various websites, including www.fishbase.org and www.flickr.com. To generate each stimulus, we started with one of 40 large coral reef scenes (1,024 × 768 pixels). To this background scene, we added 10 sea creatures in random locations (Fig. 2). On 80% of the trials, the tenth sea creature added was a fish target. Although the added images were allowed to overlap, the target fish was never occluded because it was always added last to the scene. The targets were selected from 16 images of four highly discriminable species: copperband butterflyfish, blue tang, saddled butterflyfish, and zebrasoma tang (see Fig. 1). The distractors were selected from 100 highly diverse images of anemones, sea slugs, sea stars, and coral. The target and distractors were each scaled to an area of 50,000 pixels before being added to the background scene.

Coral reef scenes, each with nine added distractors and a target
These stimuli were very similar to those described in an earlier article (Bravo & Farid, 2009), which includes a detailed discussion of the stimulus characteristics. Here we note an unusual property of these stimuli that would likely promote large cueing effects. Our observers’ task was always to indicate whether a fish—any fish—was present in the stimulus. (They were never asked to determine whether a particular fish or a particular species was present.) Without an informative cue, observers presumably searched for objects belonging to the basic-level category “fish.” Although basic-level stimuli are often recognized by shape, in these stimuli, as in nature, the shapes of the fish were obscured. Tropical fish have evolved bold markings that function as disruptive camouflage when the fish appear against a patterned background. Although these markings interfered with search for the basic-level category, they likely aided search for a particular species, because these distinctive markings are highly consistent within a species. Thus, any cue that provided knowledge of the target fish’s species could greatly assist search.
Procedure
The experiments were run on an iMac and were controlled by a MATLAB program using routines from the PsychToolbox (Brainard, 1997; Pelli, 1997).
Training
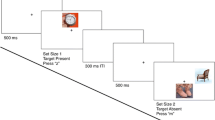
Training consisted of 16 blocks of 60 trials, 48 of which contained a fish target. We used a majority of target-present trials to maximize the observers’ exposure to the fish stimuli during the training session. All observers saw the same stimuli, but the way the stimuli were blocked varied across observers. For half of the observers, the targets in a block were always the same fish image: This was the block-by-image training condition. For the other half of the observers, the targets within a block were the four exemplars from one species: This was the block-by-category training condition. For both conditions, the order of the blocks was randomized across observers, with the requirement that successive blocks display different species.
Observers initiated each block of trials. After a 1-s delay, the first search stimulus was presented. The stimulus remained on until the observer responded by pressing one of two keys to indicate whether a target was present or absent. If the response was incorrect, the trial was followed by an auditory feedback signal and a 3-s “time out.” If the response was correct, the next trial was presented after a 1-s delay. Observers were encouraged to take breaks between blocks. The training session typically lasted 50 min.
Testing
Each observer returned 1 or 2 days after their training session for a testing session. The search stimuli used for testing were generated in the same way as those used for training, with the exception that an additional 16 target images were used. These target images were new exemplars of the same fish species used for training.
Testing involved 10 blocks of 36 trials, and 80% of the trials had a target. This percentage of target-present trials was the same as during training, and it allowed us to maximize the usable data we could collect in a session. Unlike in training, the four fish species were intermixed within blocks during testing. Each trial began with the 20-ms presentation of a cue that was either the image of a studied fish or the word “fish.” (The uninformative word cues provided a baseline for assessing cueing effects.) The cue was followed by a 600-ms blank interval. This blank interval was followed by the search stimulus, which remained on until the observer responded. As before, the observers’ task was to decide whether a fish, any fish, was present in the reef scene, and incorrect responses were followed by an auditory tone and a 3-s time out. The brief cue and the long interstimulus interval were intended to favor top-down cueing effects over bottom-up priming effects. Thus, although the cue itself would cause some stimulus-specific priming, we also expected it to inform the observer of the target’s identity. This information would allow the observers to activate an internal template of the upcoming target.
Five conditions were intermixed within the testing blocks. The conditions differed in the type of cue (word or image), in the similarity between the cue and the target (same image or same category), and in the familiarity of the target (a studied target or a new target). In the conditions with image cues, the cue was one of the studied fish images. This cue was followed by a search array that contained a target fish from the same species as the cue. The target image was identical to the cue, was another studied fish, or was a new fish. In the remaining two test conditions, the cue was the word “fish,” and the target was either a studied fish or a new fish. One fifth of the trials were catch trials that did not include a fish.
Results
We predicted that, as compared with the observers who received block-by-image training, the observers who received block-by-category training would show more generalized cueing effects during testing. This prediction was based on three assumptions: (1) Observers who trained on the block-by-category condition would learn search templates that emphasized features common to the fish species, while observers who trained on the block-by-image condition would learn search templates that emphasized distinctive features particular to that image. (2) When both sets of observers were later presented with a studied fish as a cue in a search experiment, they would recall the search template that they learned during training. (3) Learned templates that emphasized features common to the category would be likely to facilitate search for targets from the cue’s category, whereas learned templates that emphasized features specific to an image would be less likely to facilitate search for targets from the cue’s category. Thus, the critical test of our hypothesis was the comparison of the cueing effects for the two groups of observers when the cue and target were from the same category but were not identical.
To measure cueing effects, we calculated the difference between each observer’s average search times for targets preceded by informative cues and their search times for the same targets preceded by an uninformative cue (the word “fish”). Such direct comparisons were possible because a speed–accuracy trade-off was unlikely: All conditions were completely intermixed, and all observers maintained a very high level of accuracy across conditions (>95%, on average). The average target detection times for the various conditions are shown in Fig. 3, and the cueing effects that were calculated from these data are shown in Fig. 4. An ANOVA of the difference data shown in Fig. 4 indicated that the patterns of results were different for the two groups of observers: There were both a significant between-group effect, F(1, 34) = 6.12, p = .019, and a significant group × condition interaction, F(2, 68) = 3.13, p = .05. We elaborate on these effects below.

Average response times for the two groups of observers in the five test conditions. The first three pairs of bars correspond to trials with an image cue that was followed by an identical target (Image), a studied target from the same category as the cue (Cat Old), or a new target from the same category as the cue (Cat New). The remaining pairs of bars correspond to trials with an uninformative cue (the word “fish”) that was followed by a studied target (Old) or a new target (New). The errors bars show one standard error

The response time advantage conferred by the informative cues. Each bars reflects the response time difference between an informative cue condition and the corresponding uninformative cue condition in Fig. 3. The cue advantage was significant in all but the Cat New condition for the block-by-image observers. * p < .05. ** p < .01
Consistent with previous research (Bravo & Farid, 2009; Vickery, King, & Jiang, 2005; Wolfe, Horowitz, Kenner, Hyle, & Vasan, 2004), both groups of observers showed large cueing effects (Fig. 4, left) when the cue image exactly matched the target image. This cueing effect was calculated by subtracting the average search times for trials in which the cue and the target were an exact match from the average search times for the same targets with an uninformative cue.
The effect of the cue was diminished when the cue and the target were different images from the same category. In this same-category condition, we used both old, familiar targets and new, unfamiliar targets. In agreement with previous studies showing that target familiarity can facilitate search, (Jagadeesh, Chelazzi, Mishkin, & Desimone, 2001), our observers found old, familiar targets faster than new, unfamiliar ones when the cue was uninformative [one-tailed t(17) = 2.02, p = .03, for both groups of observers]. Because of this baseline difference, we calculated the cueing effect separately for the old and new targets. Both groups of observers showed significant cueing effects for this condition. Although we expected that a category cue would produce a larger cueing effect for block-by-category observers than for block-by-image observers, the difference in the cue effect size did not quite reach significance for the old targets (one-tailed t test, p = .06).
There was a significant difference, however, with new targets, and this condition provided the most critical test of our hypothesis (see Tanaka, Curran, & Sheinberg, 2005, for a similar critical condition used in a different context). If block-by-category training causes observers to form a more general category template than block-by-image training, the block-by-category observers should show a larger cueing effect with new exemplars of the target species. To calculate this final cueing effect, we subtracted response times for the informative-cue–new-target condition from the times for the uninformative-cue–new-target condition. There was a significant cueing effect for the block-by-category observers, but no cueing effect for the block-by-image condition. It seems that observers who trained on the block-by-category condition used a more general search template than did the observers who trained on the block-by-image condition.
On 20% of the trials in this experiment, the target was absent. The error rates on these trials were comparable to those for the target-present trials (average 5%), but the search times were considerably slower (block-by-image observers, 1,157 and 1,117 ms for the image and word cues, respectively; block-by-category observers, 1,170 and 1,189 ms for the image and word cues).
Discussion
The role of search templates in visual search was first proposed by ethologists studying the foraging behavior of birds: Tinbergen (1960), Pietrewicz and Kamil (1979), and Bond (1983). Birds feeding on a variety of insects tend to oversample the insect that is most common, suggesting that their search behavior is biased in favor of the targets from previously successful searches. A similar effect has been demonstrated in humans, and two distinct processes have been proposed to account for this bias. One process involves short-term priming of the target’s features. This priming facilitates the detection of the same features on the immediately subsequent search trial (Kristjansson, Ingvarsdottir, & Teitsdottir, 2009; Lee, Mozer, & Vecera, 2009; Maljkovic & Nakayama, 1994). A second process involves holding a representation of the target in working memory and using this representation to facilitate the detection of the target (Bravo & Farid, 2009; Vickery et al., 2005; Wolfe et al., 2004). The target representation that is held in working memory is referred to variously as the “target template,” the “attentional template,” or the “search template.”
In recent years, a great deal of research has focused on finding the neural correlates of the search template held in working memory during visual search. In primates, the activation of the search template is believed to involve neurons in the prefrontal cortex (PFC) that select and maintain immediate behavioral goals, such as the goal of a search task. These neurons project to inferotemporal (IT) cortex, where visual objects are represented (Mruczek & Sheinberg, 2007; Peelen, Fei-Fei, & Kastner, 2009). This top-down input from PFC enhances the gain on IT neurons that are selective for the target object. As a result, the goal-related input from PFC biases the pattern of stimulus-related activity in IT to favor the representation of the target over that of the distractors (Stokes, Thompson, Nobre, & Duncan, 2009; Zhang, Meyers, Bichot, Serre, Poggio, & Desimone, 2011). This bias may also be relayed to V4 and other lower-level visual areas that encode stimulus features, resulting in an enhancement of target-related neural activity throughout the visual processing stream (Hon, Thompson, Sigala, & Duncan, 2009).
Several factors that limit the effectiveness of this top-down bias can result in inefficient search. One limiting factor is the high degree of spatial pooling that occurs in peripheral vision. Pooling in the early stages of vision limits acuity, making it difficult to resolve the fine details necessary for subtle discriminations. Pooling in later stages of vision combines the features of adjacent objects, producing an effect known as “crowding” (Levi, 2008). Although the limitations imposed by pooling can be mitigated somewhat by spatial attention (Carrasco, Loula, & Ho, 2006), it is often necessary for an observer to scan a scene so that different regions can be analyzed by central vision. This scanning process may be guided by the search template if useful information about the target survives the effects of blurring and crowding. In particular, the search template might guide the eyes to a peripheral target if the template includes a simple feature like a “vertical edge” (Wolfe, 2007). This is because although crowding interferes with the proper combination of features, it does not impair the detection of simple features (Pelli, Palomares, & Majaj, 2004).
A number of behavioral studies have examined the extent to which search templates can guide eye movements during visual search. In these behavioral studies, guidance is assessed by counting the number of saccades required to fixate the target. These experiments have produced a range of results that is likely related to their methodological differences. In some experiments, the search items were arranged in a regular array on a blank background to minimize crowding. In other experiments, the stimuli were cluttered scenes that likely produced high levels of crowding. In general, experiments with crowded displays showed little evidence of guidance (McCarley, Kramer, Wickens, Vidoni, & Boot, 2004), but this effect appears to be moderated by knowledge of the target’s features. When observers were precued with an exact target image, the observers’ scan patterns showed evidence of guidance even if the displays were cluttered (Malcolm & Henderson, 2009). Likewise, in experiments with targets that were defined by membership in a broad category such as “chairs,” no guidance was seen even if the displays minimized crowding (Castelhano, Pollatsek, & Cave, 2008; Schmidt & Zelinsky, 2009). Overall, these studies suggest that guidance can occur when there is little clutter and the targets and distractors are highly discriminable or when the target is reliably associated with a simple feature.
These studies underscore a second factor that limits the effectiveness of the search template: target uncertainty. Objects belonging to the same category can differ markedly in appearance, and even a single object may have a different appearance when viewed from different angles. Since some uncertainty is inherent in the vast majority of everyday search tasks, observers must develop search templates that show some degree of tolerance. The present study examined one training method—intermixing stimuli—that could lead observers to develop search templates that emphasize features that are common across viewpoints and exemplars. Other training approaches that require observers to generalize across exemplars might produce similar results.
All observers in this experiment practiced the same search task on the same search stimuli, but the ways that the stimuli were blocked—by image or by category—determined the generality of the observers’ search templates. Blocking by image caused one group of observers to develop a template for each image that was relatively specific for that image, while blocking by category caused another group of observers to develop a template that generalized to other members of the species. This effect was not due to short-lived priming: When the two groups of observers were tested 1 or 2 days after training, they showed a significant difference in the specificity of their search templates.
Although this study demonstrates that the training task can affect the specificity of the search template, it does not discriminate among several possible causes for this effect. The characteristics of the training task could alter the way that the target stimuli are represented in long-term memory. Several studies have reported that discrimination training causes neurons in IT to become more selective for the features that are relevant for the discrimination task (Freedman, Riesenhuber, Poggio, & Miller, 2003; Li, Mayhew, & Kourtzi, 2009; Sigala & Logothetis, 2002; van der Linden, Murre, & van Turennout, 2008). Alternatively, the characteristics of the training task could affect which features are given prominence when the target representation is activated in working memory. Depending on the task context, observers might switch between different search templates for the same target. Finally, the specific characteristics of the training task could affect the observer’s criterion for detection; that is, after training on a category, observers might require only a rough match between the stimulus and the template in order to decide that a target is present. These three accounts differ in the degrees to which task context affects the search template used to find a particular object, so it should be possible to discriminate among them by testing trained observers on a variety of tasks. Given the central role that visual search plays in most visual activities, it will be important to understand the mechanisms that shape the search template.
References
Bond, A. B. (1983). Visual search and selection of natural stimuli in the pigeon: The attention threshold hypothesis. Journal of Experimental Psychology: Animal Behavior Processes, 9, 292–306.
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Bravo, M. J., & Farid, H. (2009). The specificity of the search template. Journal of Vision, 9(1), 34:1–9. doi:10.1167/9.1.34
Carrasco, M., Loula, F., & Ho, Y.-X. (2006). How attention enhances spatial resolution: Evidence from selective adaptation to spatial frequency. Perception & Psychophysics, 68, 1004–1012. doi:10.3758/BF03193361
Castelhano, M. S., Pollatsek, A., & Cave, K. R. (2008). Typicality aids search for an unspecified target, but only in identification and not in attentional guidance. Psychonomic Bulletin & Review, 15, 795–801. doi:10.3758/PBR.15.4.795
Corcoran, D. W. J., & Jackson, A. (1979). Flexibility in the choice of distinctive features in visual search with blocked and random designs. Perception, 8, 629–633. doi:10.1068/p080629
Czerwinski, M., Lightfoot, N., & Shiffrin, R. M. (1992). Automatization and training in visual search. American Journal of Psychology, 105, 271–315.
Freedman, D. J., Riesenhuber, M., Poggio, T., & Miller, E. K. (2003). A comparison of primate prefrontal and inferior temporal cortices during visual categorization. Journal of Neuroscience, 23, 5235–5246.
Heathcote, A., Brown, S., & Mewhort, D. J. K. (2000). The power law repealed: The case for an exponential law of practice. Psychonomic Bulletin & Review, 7, 185–207. doi:10.3758/BF03212979
Hon, N., Thompson, R., Sigala, N., & Duncan, J. (2009). Evidence for long-range feedback in target detection: Detection of semantic targets modulates activity in early visual areas. Neuropsychologia, 47, 1721–1727.
Houtkamp, R., & Roelfsema, P. R. (2009). Matching of visual input to only one item at any one time. Psychological Research, 73, 317–326. doi:10.1007/s00426-008-0157-3
Jagadeesh, B., Chelazzi, L., Mishkin, M., & Desimone, R. (2001). Learning increases stimulus salience in anterior inferior temporal cortex of the macaque. Journal of Neurophysiology, 86, 290–303.
Kristjansson, A., Ingvarsdottir, A., & Teitsdottir, U. D. (2009). Object- and feature-based priming in visual search. Psychonomic Bulletin & Review, 15, 378–384.
Lee, H., Mozer, M. C., & Vecera, S. P. (2009). Mechanisms of priming of pop-out: Stored representations or feature-gain modulations? Attention, Perception, & Psychophysics, 71, 1059–1071. doi:10.3758/APP.71.5.1059
Lefebvre, C., Cousineau, D., & Larochelle, S. (2008). Does training under consistent mapping conditions lead to automatic attention attraction to targets in search tasks? Perception & Psychophysics, 70, 1401–1415.
Levi, D. M. (2008). Crowding—An essential bottleneck for object recognition: A mini-review. Vision Research, 48, 635–654. doi:10.1016/j.visres.2007.12.009
Li, S., Mayhew, S. D., & Kourtzi, Z. (2009). Learning shapes the representation of behavioral choice in the human brain. Neuron, 62, 441–452.
Malcolm, G. L., & Henderson, J. M. (2009). The effects of target template specificity on visual search in real-world scenes: Evidence from eye movements. Journal of Vision, 9(11), 8:1–13. doi:10.1167/9.11.8
Maljkovic, V., & Nakayama, K. (1994). Priming of pop-out: I. Role of features. Memory & Cognition, 22, 657–672. doi:10.3758/BF03209251
McCarley, J. S., Kramer, A. F., Wickens, C. D., Vidoni, E. D., & Boot, W. R. (2004). Visual skills in airport-security screening. Psychological Science, 15, 302–306.
Mruczek, R. E. B., & Sheinberg, D. L. (2005). Distractor familiarity leads to more efficient visual search for complex stimuli. Perception & Psychophysics, 67, 1016–1031. doi:10.3758/BF03193628
Mruczek, R. E. B., & Sheinberg, D. L. (2007). Activity of inferior temporal cortical neurons predicts recognition choice behavior and recognition time during visual search. Journal of Neuroscience, 27, 2825–2836.
Navalpakkam, V., & Itti, L. (2007). Search goal tunes visual features optimally. Neuron, 53, 605–617.
Peelen, M. V., Li, F.-F., & Kastner, S. (2009). Neural mechanisms of rapid natural scene categorization in human visual cortex. Nature, 460, 94–97. doi:10.1038/nature08103
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Pelli, D. G., Palomares, M., & Majaj, N. J. (2004). Crowding is unlike ordinary masking: Distinguishing feature integration from detection. Journal of Vision, 4(12), 12:1136–1169. doi:10.1167/4.12.12
Pietrewicz, A. T., & Kamil, A. C. (1979). Search image formation in the blue jay (Cyanocitta cristata). Science, 204, 1332–1333.
Schmidt, J., & Zelinsky, G. (2009). Search guidance is proportional to the categorical specificity of a target cue. Quarterly Journal of Experimental Psychology, 62, 1904–1914.
Schneider, W., & Shiffrin, R. M. (1977). Controlled and automatic human information processing: I. Detection, search, and attention. Psychological Review, 84, 1–66. doi:10.1037/0033-295X.84.1.1
Sigala, N., & Logothetis, N. K. (2002). Visual categorization shapes feature selectivity in the primate temporal cortex. Nature, 415, 318–320. doi:10.1038/415318a
Sireteanu, R., & Rettenbach, R. (1995). Perceptual learning in visual search: Fast, enduring, but non-specific. Vision Research, 35, 2037–2043. doi:10.1016/0042-6989(94)00295-W
Stokes, M., Thompson, R., Nobre, A. C., & Duncan, J. (2009). Shape-specific preparatory activity mediates attention to targets in human visual cortex. Proceedings of the National Academy of Sciences, 106, 19569–19574.
Suzuki, S., & Goolsby, B. A. (2003). Sequential priming is not constrained by the shape of long-term learning curves. Perception & Psychophysics, 65, 632–648.
Tanaka, J. W., Curran, T., & Sheinberg, D. (2005). The training and transfer of real-world, perceptual expertise. Psychological Science, 16, 145–151.
Tinbergen, N. (1960). The natural control of insects in pine woods: Vol. I. Factors influencing the intensity of predation by songbirds. Archives Neelandaises de Zoologie, 13, 265–343.
van der Linden, M., Murre, J. M. J., & van Turennout, M. (2008). Birds of a feather flock together: Experience-driven formation of visual object categories in human ventral temporal cortex. PLoS ONE, 3, e3995.
Vickery, T. J., King, L. W., & Jiang, Y. H. (2005). Setting up the target template in visual search. Journal of Vision, 5(1), 8:81–92. doi:10.1167/5.1.8
Wolfe, J. M. (2007). Guided Search 4.0: Current progress with a model of visual search. In W. D. Gray (Ed.), Integrated models of cognitive systems (pp. 99–119). New York: Oxford University Press.
Wolfe, J. M., Horowitz, T. S., Kenner, N., Hyle, M., & Vasan, N. (2004). How fast can you change your mind: The speed of top-down guidance in visual search. Vision Research, 44, 1411–1426.
Zhang, Y., Meyers, E. M., Bichot, N. P., Serre, T., Poggio, T. A., & Desimone, R. (2011). Object decoding with attention in inferior temporal cortex. Proceedings of the National Academy of Sciences, 108, 8850–8855. doi:10.1073/pnas.1100999108
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Bravo, M.J., Farid, H. Task demands determine the specificity of the search template. Atten Percept Psychophys 74, 124–131 (2012). https://doi.org/10.3758/s13414-011-0224-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-011-0224-5