
Abstract
Offering reward for performance can motivate people to perform a task better, but better preparation for one task usually means decreased flexibility to perform different tasks. In six experiments in which reward varied between low and high levels, we found that reward can encourage people to prepare more flexibly for different tasks, but only as it increased from the level on the previous trial. When the same high rewards were offered continuously trial after trial, people were more inclined to simply stick with doing what had worked previously. We demonstrated such enhancements in flexibility in task switching, a difficult visual search task, and an easier priming of pop-out search task, which shows that this effect generalizes from executive tasks to perceptual processes that require relatively little executive control. These findings suggest that relative, transient changes in reward can exert more potent effects on behavioral flexibility than can the absolute amount of reward, whether it consists of money or points in a social competition.
Similar content being viewed by others
Our society rewards individuals highly for skill, as well as for the flexibility to execute multiple skills. The best-paid basketball players are not merely slam-dunk champions but, rather, those who can flexibly utilize different skills depending on their opponents and the situation. Lucrative rewards often await those who can flexibly deploy their skills, and there is little doubt that potential rewards can motivate people and animals to work harder on the task at hand (e.g., Hertwig & Ortmann, 2001; Olds & Milner, 1954; Skinner, 1950). Motivating people to potentially perform two or more different tasks well, however, may not be as straightforward. For instance, if a basketball player keeps hitting short jump shots, it would make sense to keep trying those same shots. As the old adage goes, if it ain’t broke, don’t fix it.
Then how can new strategies or actions be motivated? If nothing drastic changes in one’s environment, the same actions can typically yield the same rewards. To obtain a higher amount of reward per action, often a different action is required, such as foraging for fruit from another tree or switching to a new and potentially faster method of harvesting fruit. In addition, a change in the amount of reward available usually suggests that something has changed in one’s immediate surroundings, which often requires a different set of actions to obtain the reward. Hence, although people may be inclined to repeat actions that reliably produce the same rewards, it may be more advantageous to flexibly prepare for different actions when higher rewards become available. That way, one can be more prepared to do whatever it takes when one finds that the stakes are being raised.
In this research, we explored whether people can indeed respond more flexibly when the stakes are raised. To do so, we assessed cognitive and perceptual flexibility in different attentional tasks (Chun, Golomb, & Turk-Browne, 2011). Cognitive flexibility is a hallmark of our executive control capabilities (Leber, Turk-Browne, & Chun, 2008; Logan, 2004; Rogers & Monsell, 1995; Rubinstein, Meyer, & Evans, 2001). To that end, we can test people’s flexibility by asking them to take different actions, one after another. Although people can easily do so, the act of switching between actions has a cost: We are slower to perform a new task than a task we had been doing previously (Allport, Styles, & Hsieh, 1994; Jersild, 1927). The lower the cost, the more flexible the behavioral preparation. Similar costs have also been found in other studies that require flexible, controlled deployment of mental resources, such as shifting attention between different object attributes or switching between two stimulus–response mappings (Rushworth, Paus, & Sipila, 2001; Wager, Jonides, & Reading, 2004).
These costs are not limited to controlled behaviors that William James (1890) would attribute to the will. Another cost of switching exists in studies of automatic perception. Notably, in the phenomenon of priming of pop-out (POP), people are slower to detect new targets than to detect the same type of targets that they had been looking for previously, even when those targets are defined by a distinctive feature that allows them to “pop out” (Maljkovic & Nakayama, 1994). Whereas task switching is regarded as deliberate and effortful, POP is regarded as primarily automatic and implicit (Nakayama, Maljkovic, & Kristjánsson, 2004). Recent work, however, has shown that POP also depends on current goals (Fecteau, 2007) and that it recruits brain regions and neural mechanisms involved in task switching (Fecteau & Munoz, 2003; Kristjánsson, 2008). Therefore, if we can promote cognitive flexibility by increasing rewards as people deliberately execute actions, we can potentially promote perceptual flexibility as they detect targets in their surroundings as well.
Experiment 1: flexibility in task switching
Promoting flexibility in executive control is difficult, since task switching is robust against efforts to decrease switch costs. Although costs have been reported to decrease with practice (Rogers & Monsell, 1995), this result has not been found consistently (see Yeung & Monsell, 2003). Notably, switch costs can still persist even after tens or hundreds of thousands of training trials (Berryhill & Hughes, 2009; Stoet & Snyder, 2007). Switch costs can apparently diminish with monetary performance incentives, although those reported decreases were measured across two different experiments, conducted with different participants several years apart (Nieuwenhuis & Monsell, 2002). Other studies in which new stimuli have been introduced at the time of switching have suggested, instead, that monetary incentives encourage more stable, rather than flexible, behavior (Müller et al., 2007), although the researchers also reported that people who approached the task with relaxed and positive attitudes showed increased flexibility (see also Dreisbach & Goschke, 2004). Even though the field has recognized the relevance and usefulness of lowering switch costs in our increasingly complex lives (e.g., Leber et al., 2008; Logan, 2004; Wager et al., 2004), we are still lacking reliable and reasonably quick means for decreasing or at least modulating these costs.
In Experiment 1, we tested whether increasing rewards can effectively decrease switch costs and promote flexibility in executive control. These increases occurred within trial sequences in which the reward offered for task performance randomly fluctuated between low and high. By considering the reward on the current trial, relative to that on the previous trial, we observed instances in which reward increased, remained high, decreased, and remained low. We assessed the potential effects of reward on a number judgment task-switching design commonly used to assess willful control processes (e.g., Logan, 2004; Rogers & Monsell, 1995).
Method
Participants
Seventeen participants (13 female, M age = 23.1 years) were recruited from the Yale University campus. One participant was excluded during data analysis (see the Results section for details). All were at least 18 years of age, provided written informed consent in accordance with IRB protocol, and were naïve as to the purposes of the experiment.
Apparatus
Participants performed the experimental task in a dimly lit room, seated about 80 cm (unrestrained) from a 16-in. computer monitor. All the experiments were conducted using MATLAB with Psychophysics Toolbox version 3 (Brainard, 1997; Pelli, 1997).
Stimuli
The experimental task involved making judgments on digits (1–4, 6–9). Participants switched between judging whether a digit was odd or even and whether it was greater than or less than 5 (Rogers & Monsell, 1995). They used the left arrow to indicate “odd” or “less” and the right arrow to indicate “even” or “greater,” and their responses were contingent upon cues we presented on screen with the digits.
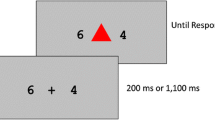
We used a square (2° visual angle) at the center of the screen to cue the judgment and the reward, starting 800 ms before the onset of the digit (see Fig. 1). Task was cued by whether the square was oriented upright or tilted by 45°, and the cue–judgment association was counterbalanced across participants. Cuing the task 800 ms prior to the digit onset should have offered enough preparation time so that we would observe only residual costs—that is, persistent switch costs that remained even after participants had done what they could to prepare for the next task (Monsell, 2003). Reward was cued by whether the border of that square was bold (high) or not (low).

Two sample consecutive trials in Experiment 1. Trial N is a low-reward trial, and trial N + 1 is a high-reward trial, as indicated by the thin and thick borders, respectively, on the square cue. Thus, trial N + 1 would be classified as a reward-increase trial. The task switches from trial N to N + 1, as indicated by the change of orientation in the square (the cue–task association was counterbalanced across participants). The reward displays here show potential points participants could have earned had they been correct. On trial N + 1, they could have earned 5–10 points, depending on response time
Procedure
We randomly intermixed trials that promised high and low rewards. High-reward trials offered participants the opportunity to earn 5–10 points for correct responses, with more points given for shorter response times (RTs). Low-reward trials offered just 1 point for correct responses. This means that participants were motivated to be both fast and accurate on high-reward trials and only accurate on low-reward trials. In order to maintain the motivational capabilities of our point scheme even toward the end of the experimental sessions, we used a staircasing procedure to decrease the RT thresholds for awarding more points as participants’ performance sped up. From a base high reward of 5 points, participants received 1, 2, 3, 4, or 5 additional points if their current trial RT was shorter than 35%, 50%, 65%, 80%, or 95%, respectively, of their RTs in all the previous blocks. The points were not converted into money in this experiment. Instead, we set up a competition where participants could compare their own point totals with others on a “high score display” that was shown at the experiment’s beginning and end, as well as during each rest break.
The experimental session began with instructions on the task and reward scheme, followed by a 40-trial practice block. During practice, feedback was provided only for incorrect responses. Although we did not analyze the practice RTs in the results, we did use them to initiate the individualized high-reward point thresholds. Participants then performed 10 blocks of 100 trials each: 50 switch and 50 repeat, not including an additional, uncategorized first trial for each block.
Results
In our analyses of RT data, we excluded incorrect trials (9.1%), trials immediately following incorrect responses (an additional 8.7%), and trials with RTs less than 100 ms (0%) or greater than 3,000 ms (0.5%). We found that 1 participant showed especially sluggish average RTs of 1,408 ms, over 3 SDs above the mean of 745 ms. This participant was excluded from further analyses, although the exclusion had no impact on the statistical pattern of results we obtained. We used a 2 × 2 × 2 repeated measures ANOVA to examine the effects of task (repeat vs. switch), current trial reward (high vs. low), and previous trial reward (high vs. low) on RT. We found the expected task switch cost: RTrepeat = 673 ms, RTswitch = 736 ms, F(1, 15) = 21.90, p < .001, Cohen’s d = 1.13. The difference between these condition averages produced a switch cost of 63 ms. The point system proved effective in motivating shorter RTs: Participants responded significantly faster on currently high-reward trials (661 ms) than on low-reward trials (744 ms), F(1, 15) = 6.42, p < .03, Cohen’s d = 0.62.
Most important, we found a significant three-way interaction, suggesting that changes in reward exerted a significant influence on task switch costs, F(1, 15) = 11.64, p < .004. The vertical distance between the curves in Fig. 2 tracks task switch costs through changes in reward. The shaded region reveals a significant decrease in switch cost as the reward increased from low to high (25 ms), as compared with when the reward simply remained low (93 ms), F(1, 15) = 26.76, p < .001, Cohen’s d = 1.29. This interaction between task and reward shows that although increases in reward led to shorter RTs regardless of whether the task repeated or switched, the RT improvement was much bigger for switching task (97 ms change), t(15) = 2.97, p < .01, Cohen’s d = 0.74, than for repeating the same task (29 ms change), t(15) = 1.02, p > .32, Cohen’s d = 0.26. This suggests that people favored switching tasks as rewards increased and performed more flexibly as a result. In fact, they performed so flexibly that their overall switch cost associated with reward increases had a medium effect size and was only marginally significant after 16 participants, t(15) = 1.95, p = .07, Cohen’s d = 0.49.

Effects of reward, as defined by comparison between the current and previous trials, on response times in Experiment 1. Error bars represent 95% confidence intervals. The vertical difference between the two curves represents variations in switch costs across the reward conditions. Actual experiment rewards were randomized from trial to trial and did not cycle predictably through the four conditions; the order of conditions in the figure was chosen to maximize descriptive clarity and was consistent across all our experiments. The table shows switch costs and accuracy further broken down by switch versus repeat conditions
After this initial flexibility, task switch costs seemed to have risen back up significantly (to 73 ms) as reward continued to remain high, F(1, 15) = 15.54, p < .002, Cohen’s d = 0.99. As we expected, participants continued to get faster on repeating tasks, significantly lowering their RTs by another 31 ms, t(15) = 3.93, p < .002, Cohen’s d = 0.98. By contrast, they actually got slower at switching tasks by a slowdown of 16 ms, although this change was not significant, t(15) = 1.60, p = .13. This fits with our initial claim that consistently high rewards would be best at reinforcing performance on the same task, because people often expect to obtain the same rewards with the same actions. Although consistently high rewards were effective in maintaining short RTs, they did not appear as effective as increasing rewards at inducing lower switch costs and more flexible behavior.
Moving on to when the reward decreased, we can see in Fig. 2 that it was easily the condition in which participants responded the slowest, ts(15) > 2.23, p < .05, Cohen’s ds > 0.55, as compared with all the other conditions. Nevertheless, the switch cost stayed relatively stable, as compared with when the reward remained high, and was still significantly greater than when the reward increased, F(1, 15) = 7.08, p < .02, Cohen’s d = 0.67. It is also notable that switch costs were marginally significantly smaller when the reward remained high or decreased, as compared with when the reward remained low, ps < .13, Cohen’s ds = 0.40 and 0.42, respectively.
Reward did not make a significant difference in accuracy (acc high = 90.0% vs. acc low = 91.0%), t(15) = 1.56, p = .14, Cohen’s d = 0.39, although the numbers suggest that there might have been a trend toward an RT–accuracy trade-off. There was a significant difference in overall accuracy just as participants were becoming more flexible—that is, as the reward increased (89.8%), rather than remained low (91.5%), t(15) = 2.29, p < .04, Cohen’s d = 0.57 (see Fig. 2 for accuracy data broken down by all conditions). These findings are not surprising, given that there was a clear emphasis on speed in the high-reward condition (more points for faster responses), but not in the low-reward condition. Whether this trade-off mediated the enhanced flexibility we observed will be addressed in the next experiment.
Discussion
Our task-switching experiment showed that switch costs were smallest as rewards increased from the previous trial. The marginally significant, medium-effect-sized switch cost observed with increasing rewards is on the small side, as compared with costs in most studies on task switching. In addition, the trials on which the reward remained low were probably most representative of lab conditions under which task-switching experiments are usually conducted, because they involved the least amount of external motivation. Therefore, the most plausible interpretation for our findings is an enhancement in people’s flexibility to take different actions only when rewards have just increased.
Although participants appeared most flexible in the reward-increase condition, it was not when they were fastest. That happened when the reward remained high. Given the common expectation that the same rewards can be obtained with the same actions, we had expected that participants would respond fastest when the reward remained high, although only when performing the same task as they had just performed previously. Our results confirm that participants were fastest only at repeating the same task when the reward remained high. In fact, they were no faster at switching tasks when the reward remained high than when the reward—and flexibility—increased.
One might have expected flexibility to decrease as the reward decreased if it increased with reward. However, we argued for the latter, because we believed that participants will become more willing to do whatever it takes when offered additional incentives. If we take away incentives and decrease their motivation, participants should simply become more willing to do whatever is easier. On the one hand, the easier thing to do would be to stay on task, which would increase the switch cost if participants perform it disproportionately faster than switching tasks. On the other hand, less motivation overall might mean less motivation to maintain their task set from the previous trial and, thus, lead to decreases in switch costs. Results from Experiment 1 suggest a combination. Although switch costs for the reward-decrease condition were significantly higher than those for when the reward increased, they were almost significantly lower than the costs for when the reward remained low. It should be noted that the decreases in reward in no way presented opportunities for loss aversion, which applies when there are potential losses. When participants received a low reward cue after a high-reward trial, a decrease in points was already ensured, and their performance could determine only whether they would endure an n or n + 1 point decrease.
The fact that only 1 point was at stake on low-reward trials was a concern, because it left no room to incentivize participants to respond as quickly as they could, which we did on high-reward trials. Thus, all the reward effects we observed could have been due to the increase in reward, the speed incentive in the high-reward condition only, or both. Although it would have been interesting to find that an incentive to respond faster also encouraged flexible behavior, we wanted to know whether changes in reward amount could promote flexibility on their own. This was the focus of our next experiment.
Experiment 2: effects of reward magnitude or just speed incentives?
In Experiment 1, the differences between high- and low-reward trials included more points and a speed incentive. In Experiment 2, we sought to assess the influence of just the size of the point rewards by introducing speed incentives into the low-reward condition as well. Instead of providing 5–10 points in the high-reward condition, we simplified the reward structure to provide either 10 or 20 points, where participants received 20 points for faster responses. For the low-reward blocks, this reward structure was decreased by an order of magnitude, as participants received either 1 or 2 points. This preserved a speed incentive in the low-reward block while keeping intact the interesting difference in reward magnitude, since faster responses on high-reward trials would earn 10 extra points, whereas faster responses on low-reward trials would earn just 1 extra point. We hoped that this difference would be sufficient to replicate the reward effects observed in Experiment 1.
Method
Participants
Thirty-four (15 female, M age = 19.0 years) naïve participants took part in Experiment 2. As will be discussed in the Results section, we excluded 4 outlier participants from data analyses.
Apparatus and stimuli
The apparatus and stimuli were dentical to those in Experiment 1.
Procedure
The only change we made was to the point incentives, which now constituted 10 or 20 points (nothing in between) for high reward and 1 or 2 points for low reward. Participants received 20 or 2 points when their current trial RTs were shorter than 60% of their RTs in previous blocks.
Results
Again, we excluded incorrect trials (11.9%), trials immediately following incorrect responses (an additional 10.5%), and trials with RTs less than 100 ms (0.1%) or greater than 3,000 ms (0.5%). After these exclusions, 2 participants produced fewer than 60% analyzable trials and were thus excluded from further analyses. Another 2 participants showed extremely long RTs of 1,086 and 1,093 ms, over 200 ms longer than those for the next slowest participant and almost double the average RT of 575 ms for everyone else. Although, at 2.8 and 2.9 SDs above the mean, their RTs did not quite cross the 3 SD threshold, it was because having both of them increased the variance of the RTs. If either person had been excluded, the other would have been over 3 SDs from the group RT mean. Thus, we decided to exclude their data from analyses in order to reduce noise.
Using the same three-factor repeated measures ANOVA as in Experiment 1, we found a significant task switch cost: RTrepeat = 553 ms, RTswitch = 598 ms, F(1, 29) = 34.25, p < .001, Cohen’s d = 1.05, and a significant reward effect (with strikingly similar numbers): RThigh = 553 ms, RTlow = 598 ms, F(1, 29) = 25.36, p < .001, Cohen’s d = 0.92.
Our three-way task × current reward × previous reward interaction was again significant in this experiment, F(1, 29) = 5.36, p < .03. Figure 3 shows a similar overall pattern of results in this experiment, as compared with Experiment 1. In particular, participants still showed reduced switch costs when the reward increased (30 ms), as compared with when the reward remained low (61 ms), F(1, 29) = 7.61, p < .01, Cohen’s d = 0.50. Thus, flexibility again increased with reward. Also replicating Experiment 1, RT improvement was much bigger for switching task (48-ms change), t(29) = 4.57, p < .001, Cohen’s d = 0.83, than for repeating the same task (17-ms change), t(29) = 1.72, p = .10, Cohen’s d = 0.31. This once again demonstrated a preference for switching tasks as the reward increased.

Effects of reward, as defined by comparison between the current and previous trials, on response times in Experiment 2. Error bars represent 95% confidence intervals. The table shows switch costs and accuracy further broken down by switch versus repeat conditions
Switch costs showed a marginally significant increase when the reward remained high (53 ms), as compared with when the reward just increased, F(1, 29) = 3.33, p = .08, Cohen’s d = 0.33, and there was a strong trend toward the pattern we observed in Experiment 1. Participants still improved significantly at repeating the same task (by 19 ms) as the reward remained high, t(29) = 3.29, p < .003, Cohen’s d = 0.60, whereas they got a bit slower (4 ms) at switching tasks, t(29) = 0.47, p = .64. Again, consistently high rewards promoted repetitive action. Although it is clear that the reward-decrease condition once again elicited the most sluggish RTs from participants, ts(29) > 3.08, ps < .005, Cohen’s ds > 0.56, its switch cost did not significantly differ from the other conditions’ switch costs, ps > .11.
In Experiment 1 we saw signs of a reward-induced speed–accuracy trade-off, but there were no signs of such a trade-off in this experiment with speed incentives in both reward conditions. Just the opposite, participants were significantly less accurate in the low-reward condition (88.9%) than in the high reward condition (90.5%), t(29) = 3.79, p < .001, Cohen’s d = 0.69. Similarly, accuracy was slightly lower as the reward remained low (89.2%) versus when it increased (90.5%), t(29) = 2.41, p < .03, Cohen’s d = 0.44, and thus the increase in flexibility cannot be explained by changes in accuracy.
Discussion
In this experiment, we replicated two key findings from Experiment 1. (1) Participants became significantly more flexible as reward increased from low to high, as compared with when they remained low, as demonstrated by significantly decreased switch costs. (2) Participants improved further at repeating tasks as reward remained high, as demonstrated by significantly decreased RTs for task-repeat trials. They showed no further improvement at switching tasks as reward remained high, leading to a marginally significant increase in switch cost and a decrease in flexibility. In this experiment, these findings could not be explained simply by a lack of any speed incentives in the low-reward condition, since we had analogous speed incentives in both reward conditions. This shows that participants did not get more flexible simply because they were rushed. It was not because they sacrificed speed for accuracy either, since we observed accuracy patterns opposite to those in Experiment 1 and still obtained flexibility increases with increased rewards.
The only condition that was difficult to place among the rest was the reward-decrease condition, which showed a switch cost that fell in between the reward-increase and the two reward-constant conditions. Its switch cost did not differ significantly from those in any other condition. It still appeared to have been the condition into which participants put the least amount of effort, since their RTs were longest in that condition. As was mentioned in Experiment 1’s Discussion section, there may be two counteracting effects at work, both driving up and keeping down the switch cost, and in this experiment, neither seems to have prevailed to produce a significant change in flexibility.
Up to this point, our rewards were simply points that were not linked to any external incentives. Although effective in our two experiments at inducing more flexible behaviors, it is arguable that their incentive structures were not as strong as they could have been with external consequences, such as prize money. Thus, perhaps many of the reward conditions, such as the reward-remained-high and the reward-remained-low conditions, did not exhibit significantly different switch costs from one another because the differences in incentives were not strong enough to elicit those differences. To assess this possibility, we introduced prize money into the next set of experiments.
Experiment 3a and 3b: monetary rewards
Although adding monetary incentives often increases motivation and strengthens psychological effects (Camerer & Hogarth, 1999; Hertwig & Ortmann, 2001), such benefits are far from guaranteed. In fact, a large body of literature suggests that monetary incentives and fines can make people less motivated to do something they had other motivations to do, such as donating blood or picking up their children on time (Frey & Jegen, 2001; Gneezy & Rustichini, 2000; Lepper, Greene, & Nisbett, 1973; Mellström & Johannesson, 2008). It is possible that monetary incentives could also similarly reduce participants’ intrinsic motivations to perform as well as they could in the social competitions we set up in our experiments. To assess the effects of monetary incentives, we ran two variations of the experiment: one with money as the sole motivator (Experiment 3a) and another that kept the competition structure intact as well (Experiment 3b).
Method
Participants
Thirty-four (14 female, M age = 23.2 years) naïve participants took part in Experiment 3a, and 30 (18 female, M age = 20.7) took part in Experiment 3b, all for pay. We excluded 4 outlier participants from Experiment 3a.
Apparatus and stimuli
The apparatus and stimuli were identical to those in Experiments 1 and 2.
Procedure
All the procedures were identical to those in the previous experiments, except the incentive structure. We allotted points using the system in Experiment 1: 5–10 points for high reward and 1 point for low reward. In Experiment 3a, we removed all point displays and replaced them with updates about how much money participants had earned thus far, which were displayed during each rest break and at the end of the experiment. In Experiment 3b, we presented both the point and money updates. Participants earned $1 per 500 points in both experiments, and this bonus was added to the base $10/hr rate that they were paid at the end of the experiments. On average, participants across both experiments earned 3,930 points, and with their earnings rounded up to the next whole dollar amount, they earned an average bonus of $8.38. Participants were not informed of the rounding until the end of the experiment. In addition, in Experiment 3b, we awarded $10 prizes to the top 15% of participants as determined by points, to provide competitive motivation on top of their direct earnings. Five such winners of the $10 prize were notified upon completion of Experiment 3b.
Results
In Experiment 3a, our excluded trial percentages for incorrect trials, trials following incorrect responses, RTs less than 100 ms, and RTs greater than 3,000 ms were 10.1%, 9.0%, 0.02%, and 0.4%, respectively. We had to exclude 4 participants for producing fewer than 60% usable trials after these exclusions were implemented. For Experiment 3b, they were 8.1%, 7.9%, 0.1%, and 0.4%, respectively, and no participant needed to be excluded. In both experiments, we found significant task switch costs: In Experiment 3a, RTrepeat = 600 ms, RTswitch = 649 ms, F(1, 29) = 24.59, p < .001, Cohen’s d = 0.89; in Experiment 3b, RTrepeat = 619 ms, RTswitch = 671 ms, F(1, 29) = 26.29, p < .001, Cohen’s d = 0.92. The monetary incentives produced faster responses with high reward in both experiments: In Experiment 3a, RThigh = 556 ms, RTlow = 693 ms, F(1, 29) = 32.87, p < .001, Cohen’s d = 1.04; in Experiment 3b, RThigh = 602 ms, RTlow = 688 ms, F(1, 29) = 22.75, p < .001, Cohen’s d = 0.87.
Experiment 3a
We again found a significant task × current reward × previous reward interaction in this experiment, F(1, 29) = 4.66, p < .04. Figure 4 confirms that switch costs were smallest when rewards increased, similar to those in previous experiments across reward conditions. As in the previous experiments, the largest numerical change in switch costs was between the reward-increase (36 ms) and remain-high (58 ms) conditions, although this change did not quite reach significance, F(1, 29) = 2.85, p = .10, Cohen’s d = 0.31. Both switch and repeat RTs showed large changes across the two conditions: for switch, 118 ms, t(29) = 5.02, p < .001, Cohen’s d = 0.92; for repeat, 96 ms, t(29) = 4.41, p < .001, Cohen’s d = 0.80.

Effects of reward on response times, switch costs, and accuracy in Experiment 3a
We also replicated the finding that participants were fastest at repeating tasks when the reward remained high. Switch costs rose significantly to 56 ms as the reward remained high versus when it first increased (36 ms). Although this change was numerically smaller than the change between when the reward remained low and when it increased, unlike the latter it did reach significance, F(1, 29) = 5.23, p < .03, Cohen’s d = 0.42. As in Experiments 1 and 2, participants responded significantly faster on repeat trials when the reward remained high (521 ms) over when it first increased (545 ms), t(29) = 3.21, p < .004, Cohen’s d = 0.59. There was once again no significant difference on switch trials (577 vs. 581 ms), t(29) = 0.64, p = .53.
As in Experiment 2, we found the longest RTs in the reward-decrease condition, ts > 4, ps < .001, Cohen’s ds > 0.73, and we did not find a speed–accuracy trade-off. In this experiment, there simply was no difference in accuracy between the high-reward (92.5%) and low-reward (92.9%) conditions, t(29) = 0.75, p = .46.
Experiment 3b
Although the three-way interaction did not reach significance, F(1, 29) = 2.08, p = .16, switch costs were again lowest when the reward increased. As can be seen in Fig. 5, switch costs were significantly lower as the reward increased (38 ms), over when it remained low (61 ms), F(1, 29) = 5.93, p < .03, Cohen’s d = 0.44. Participants’ RTs on repeat trials decreased by 43 ms from 634 to 591 ms, t(29) = 2.95, p < .007, Cohen’s d = 0.54, but the previous interaction shows that the corresponding RT decrease on switch trials was significantly greater: 73 ms from 703 to 629 ms, t(29) = 4.12, p < .001, Cohen’s d = 0.75. Thus, participants once again appeared to improve more on task switches as rewards increased.

Effects of reward on response times, switch costs, and accuracy in Experiment 3b
Consistent with all three previous experiments, participants were fastest on task repeats when the reward remained high, as compared with when the reward increased (RT = 572 and 591 ms, respectively), t(29) = 2.11, p < .05, Cohen’s d = 0.38. Despite this improvement in the speed of detection, there was no corresponding significant increase in the switch cost, F < 1, p = .35, because participants’ performance on task switches improved slightly, although not significantly, from 629 to 620 ms, t(29) = 1.11, p > .27. Participants were once again slowest to respond when the reward decreased, ts(29) > 3.93, ps < .001, Cohen’s ds > 0.71, although the switch costs were not different, as compared with when the reward remained high, F(1, 29) < 1, p > .74.
Accuracy was slightly higher on high-reward trials (92.2%) than on low-reward trials (91.6%), although not significantly so, t(29) = 0.86, p > .39. This shows that there was no speed–accuracy trade-off.
Discussion
We replicated the two key significant findings from Experiments 1 and 2: increased flexibility with increased reward and faster repeat task performance as reward remained high. The expected increase in flexibility (lower switch costs) was significant in Experiment 3b and marginally so in Experiment 3a. The fastest RT performance was on task-repeat trials when the reward remained high. These results demonstrate that the flexibility changes we previously observed are not confined to experiments utilizing social or competitive motivators.
Our results suggest that one should not expect the introduction of money into a task to always boost motivations. Adding monetary incentives on top of our competition in Experiment 3b did not strengthen any reward effects, and as was mentioned in our introduction for these experiments, there are numerous examples of how money can decrease motivation (e.g., Frey & Jegen, 2001; Gneezy & Rustichini, 2000; Lepper et al., 1973, Mellström & Johannesson, 2008). Although not everyone would change their behaviors because of points in an artificially constructed competition, our experiments showed that many would and did. When participants want to excel in the points competition, the difference between getting 1 and 10 points in a trial can seem very salient. In fact, the average separation between 2 participants on the leader board was a mere 48 points in Experiment 3b. On the other hand, if we translate the points into money for our experiments, a change from 1 to 10 points represented a change from 0.2 to 2 cents. We think it is reasonable to expect points to induce comparable motivation. We have little doubt that a larger monetary difference between the two conditions would have been more effective, but this was not economically feasible or necessary in a lab setting.
One could also ask whether offering no reward at all in place of the low reward could also have made the incentive differences more salient. In fact, our pilot testing for this and other paradigms has generally shown that having a no-reward condition makes the difference too salient and indicates to some participants that they can completely disregard no-reward trials, resulting in excessive guessing and unmotivated responses. Thus, for practical reasons to reduce noise, a very low reward was preferable to none.
With these results in mind regarding the mechanisms through which reward can induce more flexible behavior, we sought to generalize our findings. A good test of the scope of these findings would be to also demonstrate them in the performance of fairly automated tasks, ones that participants may have little explicit control over. Such a demonstration would still be far from a confirmation that reward increases can promote behavioral flexibility in general. Nevertheless, it could be an indication that these reward effects are fundamental processes that affect even some of the simplest tasks that we perform and that complex, rational thought may not be required. Our next experiment investigated the effects of reward on flexibility in one such simple perceptual task.
Experiment 4: flexibility in automatic perceptual set
To demonstrate that flexibility is not restricted to the performance of willful, deliberate actions, we tested for it in POP, an automatic behavioral phenomenon thought to rely primarily on implicit mechanisms. POP assesses people’s preparedness for detecting different types of salient targets on visual displays, and people are slower to respond to a new type of target than to one they had been looking for previously (Maljkovic & Nakayama, 1994). Perhaps indicative of the challenge we face in trying to decrease priming with rewards, POP has been described as “impervious to other mental processes and reflecting only passive repetition” (Nakayama et al., 2004, p. 403). However, more recent studies, reviewed in the introduction, suggest some susceptibility of POP to higher-level influences (Fecteau, 2007; Fecteau & Munoz, 2003; Kristjánsson, 2008).
Method
Participants and apparatus
Thirty-two (18 female, M age = 19.2 years) naïve participants took part in this experiment. We excluded 2 outlier participants from analysis.
Stimuli
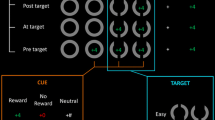
Participants searched for a uniquely colored shape on the computer screen and made a response based on its orientation. Using Maljkovic and Nakayama’s (1994) paradigm, in Experiment 4 we arranged three diamond shapes (1.5° × 1.5° visual angle), each with either its left or its right corner cut off, in an ellipse (11° × 9°) about the center of the computer screen (see Fig. 6). Participants switched between looking for a red diamond among green and vice versa, using the left or right arrow key to respond to the side with the cut-off edge. The target color switched 50% of the time, as the task did in previous experiments.

Trial structure in Experiment 4, showing a low-reward trial followed by a high-reward trial, as indicated by the colors of the screen borders. The search target is the uniquely colored shape in each display. Thus, trial N + 1 is a “switch” trial on which the target color has changed from the previous trial
We cued reward on each display with a colored fixation dot and screen border combination. Because POP is very different from task switching and requires no prior task cue, we opted to fit in more trials by starting the reward cue just 400 ms prior to the appearance of the shapes. Participants needed only to consider reward during this period, whereas in the previous experiments, they were processing both reward and task cues. The reward cue remained up until response, as in the previous experiments. The colored reward cue was either cyan or yellow, and the associations between color and reward size were counterbalanced across participants.
Procedure
The procedures were identical to those in the task-switching experiments, except that participants completed 16 blocks of 80 trials each. We reverted to providing points only, instead of having monetary incentives.
Results
The excluded trial percentages for incorrect trials, trials following incorrect responses, RTs less than 100 ms, and RTs greater than 3,000 ms were 6.7%, 5.8%, 0.3%, and 0.3%, respectively. The proportion of trials excluded was lower than in the previous experiments, reflecting the general ease of the pop-out search task. Nevertheless, 2 participants produced fewer than 60% analyzable trials and had to be excluded from further analyses. Analogous to significant switch costs, we found a significant repeat-color priming effect, since participants, on average, took 652 ms to respond to targets of the same color as that on the previous trial and 717 ms to respond to targets of the other color, F(1, 29) = 185.14, p < .001, Cohen’s d = 2.54. The reward points still exerted their usual main effect: RThigh = 652 ms, RTlow = 715 ms, F(1, 29) = 11.38, p < .003, Cohen’s d = 0.63.
Just as in task switching, we ran the target color (replacing “task”) × current reward × previous reward repeated measures ANOVA on RT. As in the previous experiments, we found a significant three-way interaction, F(1, 29) = 8.17, p < .008. Figure 7 shows the same general pattern of results that we observed in Experiments 1–3, despite the change in task. There was the least amount of priming (45 ms) when the reward increased from the previous trial, suggesting that participants were more flexible at detecting targets of both colors as they were being promised more reward. This priming was significantly lower, as compared with the 67 ms of priming when the reward remained low, F(1, 29) = 4.30, p < .05, Cohen’s d = 0.38, which confirms that RTs for searching for a different colored target decreased more as the reward increased than did RTs for searching for the same-colored target (74 vs. 52 ms decrease).

Effects of reward on priming of pop-out, as defined by the response time difference between trials on which the target color repeats and trials on which the target color switches, in Experiment 4. Please note that “priming” is a measure analogous to switch cost
Participants also became very adept at detecting the same targets as the reward stayed consistently high. The priming in the reward-remained-high condition (80 ms) was significantly greater than when the reward first increased to high, F(1, 29) = 16.00, p < .001, Cohen’s d = 0.73. It was even marginally significantly greater than the priming when the reward remained low, F(1, 29) = 3.60, p = .07, Cohen’s d = 0.35. It appears that the high-reward condition was especially conducive to promoting repeat task performance in this pop-out search task. Unlike in task switching, it appeared to be primarily attributable to a drop in performance on detecting targets that had switched color, as RTs increased from 672 ms when the reward first increased to 697 ms when the reward stayed high, t(29) = 4.65, p < .001, Cohen’s d = 0.85. There was also an accompanying 10-ms RT decrease for targets that repeated in color, t(29) = 1.90, p = .07, Cohen’s d = 0.35.
As always, participants exhibited the longest RTs and, presumably, the least amount of motivation when the reward decreased, although unlike in all the previous experiments, these RTs were not significantly greater than those for the reward-remained-low condition, t(29) = 1.04, p > .3. They were still, however, substantially longer than the RTs for the reward-increased and remained-high conditions, ts(29) > 3.1, ps < .005, Cohen’s ds > 0.56. Participants’ switch costs for the reward-decrease condition (61 ms) fell at an intermediate level between when the reward increased, F(1, 29) = 3.24, p = .08, Cohen’s d = 0.33, and when the reward remained high, F(1, 29) = 4.71, p < .04, Cohen’s d = 0.40.
As in Experiment 1, there seemed to have been a speed–accuracy trade-off. When the reward was high on the current trial, participants exhibited an accuracy of 93.7%, significantly less than the 95.3% they exhibited under low reward, t(29) = 3.47, p < .002, Cohen’s d = 0.63. In particular, there was a significant decrease in overall accuracy as the reward increased (94.0%), as compared with when it remained low (95.2%), t(29) = 2.75, p < .02, Cohen’s d = 0.50.
Discussion
As in Experiments 1–3, flexibility increased as the reward increased. Participants were also marginally significantly faster at repeating searches for the same color, much as they were significantly faster at repeating tasks in Experiments 1, 2 and 3 when the reward remained high. Whereas the task in Experiment 1 required willful and deliberate processing, this time we found these effects in a perceptual phenomenon known for its implicit nature. The effect sizes for the decreases in priming were smaller than those for the decreases in switch costs in Experiment 1, and the POP effects remained highly significant for all the reward conditions (ps < .001). Hence, POP appeared more resistant to intentions, as Nakayama et al. (2004) suggested. In general, a reward increase probably enhances flexibility better on tasks requiring more executive control.
Our basic finding that reward speeds up the detection of pop-out targets is consistent with previous findings that reward helps in target detection via directing exogenous attention (Engelmann & Pessoa, 2007) and saccades (Milstein & Dorris, 2007). One new effect that we did not find with task switching was that participants got significantly slower at detecting a different-colored target when the reward remained high, whereas previously we found only that they got faster at repeating the same task. This allowed consistently high rewards to increase implicit priming to a level almost significantly above what we found with consistently low rewards. This appears to concur with some recent research in POP showing that a high reward on the previous trial speeds up search for objects with the same features on subsequent trial(s) (Hickey & Theeuwes, 2008; Kristjánsson, Sigurjónsdóttir, & Driver, 2010). In fact, Kristjánsson et al. found that participants also showed greater priming on high-reward trials following a previous sequence of low-reward trials, although their changes in reward were unannounced and—due to their probabilistic nature—were only gradually discovered by participants. Thus, their enhanced priming effects appeared only after a number of trials with increased reward, long after we observed the initial decreases in priming in our experiments. What is interesting is that we did not observe analogous increases in switch costs for consistently high over consistently low rewards in task switching. We are also not aware of any reports in the literature of such findings, so this boost in priming under consistently high reward seems to be confined to search tasks.
Although we found a speed–accuracy trade-off in this experiment, it was expected, considering that we used exactly the same reward system as in Experiment 1, which produced the strongest effects of reward contrast. In any case, Experiments 2 and 3 have shown that the ability for reward to increase flexibility is unlikely to be explained by speed–accuracy trade-offs.
Experiment 5: flexibility in more controlled perception
To perceive items of interest, we often need to deliberately direct ourselves to look for something or check to make sure that we have found it. We believe that increasing rewards should more strongly promote flexibility when perception becomes more controlled and deliberate. To introduce the need for more controlled search, we added two additional shapes of another color into our POP search displays (see Fig. 8).

Sample search display for Experiment 5. The participants’ task was still to detect the uniquely colored shape. The actual colors we used were red, green, and blue
Method
Twenty-five (10 female, M age = 18.8 years) naïve participants took part in Experiment 5. The apparatus and stimuli were identical to those in Experiment 4, except for the aforementioned addition of different-colored shapes. In addition to red and green from the previous experiment, we added blue as another potential target and distractor color. Despite having three colors to choose from, we still changed the target color 50% of the time, as in the previous experiments. We cued different rewards by varying the luminance of the fixation dot and border. The length of the experiment was reduced to 12 blocks of 80 trials, due to the longer search RTs.
Results
The excluded trial percentages for incorrect trials, trials following incorrect responses, RTs less than 100 ms, and RTs greater than 3,000 ms were 7.2%, 6.3%, 0.2%, and 0.2%, respectively. Our target color × current reward × previous reward ANOVA once again yielded the expected main effect of priming from repeated targets (RTrepeat = 782 ms, RTswitch = 941 ms), F(1, 24) = 145.13, p < .001, Cohen’s d = 2.43, along with the expected effect of reward (RThigh = 822 ms, RTlow = 897 ms), F(1, 24) = 22.52, p < .001, Cohen’s d = 0.99. The introduction of the additional shapes and color significantly increased RTs, as compared with Experiment 4, t(53) = 5.90, p < .001, Cohen’s d = 1.63, confirming that the task was indeed more difficult and demonstrating a slowdown of search due to set size not observed in POP (Maljkovic & Nakayama, 1994).
We once again found a significant three-way interaction, F(1, 24) = 4.87, p < .04. Although it is somewhat more difficult to see in Fig. 9, due to the large repeat color benefit/priming, performance was once again significantly more flexible as the reward increased. Searching for different-colored targets was 127 ms slower than searching for targets of the same color again in the reward-increase condition, and that was significantly smaller than the 162-ms to 174-ms differences in the other three reward conditions, Fs(1, 24) > 5.46, ps < .03, Cohen’s ds > 0.46. The other conditions did not differ from each other in terms of this same color benefit, Fs < 1, ps > .33.

Effects of reward on target color priming in Experiment 5
When flexibility increased with reward, search RTs for detecting different- and same-colored targets decreased by 78 and 43 ms, respectively (ps < .01), although the interaction confirms that the decrease was more severe when target color changed (Cohen’s d = 0.96 for different vs. 0.62 for same). When flexibility gave way to better repeat performance when the reward remained high, it was the product of a significant 20-ms RT increase for detecting different-colored targets, as in POP (Experiment 4), t(24) = 2.36, p < .03, Cohen’s d = 0.47, combined with a significant 26-ms RT decrease for detecting color repeat targets, as in task switching (Experiments 1, 2, and 3), t(24) = 2.83, p < .01, Cohen’s d = 0.57.
As in Experiments 1 and 4, there was a speed–accuracy trade-off: acc high = 91.9% vs. acc low = 93.8%, t(24) = 2.44, p < .03, Cohen’s d = 0.49. The accuracy decrease from when reward remained low (94.0%) to when reward increased (92.3%), however, was not quite significant, t(24) = 1.87, p = .07, Cohen’s d = 0.37.
Discussion
We ran this study as a bridge between task switching and POP, and it indeed replicated the two main significant results from our task-switching experiments: increased flexibility with increased reward and faster repeat task performance as reward remained high. It combined these findings with significantly longer RTs when target color switched but reward remained high, which we observed in our POP experiment. In addition, the flexibility increase in this experiment—a Cohen’s d of 0.47—fell between the analogous increases in Experiments 1 and 2 (d = 1.29 and 0.50, respectively) and the increase in Experiment 4 (d = 0.38). In these ways, this last experiment seemed to strike a middle ground between the two experimental paradigms, which could have been expected since it introduced some of the deliberate control needed for task switching into a mostly automated search task. The flexibility effects appeared across our full spectrum of experiments, but they seemed to be stronger in tasks that required more deliberate cognitive control.
General discussion
In six experiments that assessed both cognitive and perceptual flexibility, people behaved more flexibly when reward increased, and not when it simply remained consistently high. Starting from the same point, with a low reward on the previous trial, participants showed significantly decreased switch costs, POP, and repeat search target benefits when the reward increased to high on the current trial, as compared with when the reward remained low. These flexibility enhancements were significant in all five of our experiments involving competitive motivation. In addition, they were also found to influence POP, a simple target detection task that requires little executive control. Furthermore, in all of our experiments, participants became better at staying on task as the reward remained high, as compared with when the reward first increased, even though both types of trials offered the same reward for current trial performance. This suggests that the same rewards work best at promoting repeats of the same actions. Figure 10 summarizes these main findings across all of our experiments. Previous research has suggested that cognitive flexibility naturally fluctuates from moment to moment (De Jong, 2000; Leber et al., 2008), and we have identified one of the factors that can reliably modulate these fluctuations in both action and perception. By reserving our most flexible moments for occasions on which more rewards become available, we can perform best in an environment where the same actions can usually earn the same rewards but may not be enough to earn more.

Summary of main findings across all experiments. a Changes in switch costs (Experiments 1–3) and priming/color-switch cost (Experiments 4 and 5) when the reward increased from low to high, as compared with when the reward remained low. Decreases correspond to more flexible behavior when the reward increased. b Changes in response time (RT) for repeating tasks when the reward remained high, as compared with when the reward first increased from low to high (which was always the condition with the second shortest RTs). Decreases represent further improvement at repeat task performance as the reward remained high, which resulted in the shortest RTs of all the conditions. Error bars indicate 95% confidence intervals, so bars that do not cross the x-axes indicate significant effects
Not only did we find the smallest switch costs in the reward-increase condition in every experiment, we also found, in every experiment except Experiment 3, that participants had the shortest switch trial RTs when the reward increased. In addition, every experiment revealed the shortest repeat task RTs when the reward remained high. Given previous task-switching research demonstrating that cue changes in the absence of task changes can slow down responses (Logan & Bundesen, 2003; Mayr & Kliegl, 2003), one can point to the longer repeat task RTs in the reward-increase condition and ask whether it was attributable to cue changes that indicated a change in reward. After all, those changes were not present when the reward remained the same. However, unlike in those previous studies, our reward cue (thickness of shape borders) changed independently from the task cue (the shape). Furthermore, participants’ RTs showed the same pattern when they switched between detecting different targets without relying on any cues in POP and visual search, and thus, cue change effects cannot apply in all of our experiments.
Instead, we believe that people’s fastest task performance (as measured by RTs) and highest flexibility (as measured by switch costs) did not coexist in the same condition because flexibility trades off with stability—our tendency to stay on task (see Leber et al., 2008; Müller et al., 2007). The aforementioned researchers have suggested that when we are at our most flexible, we are actually not as prepared to perform a practiced task or primed response, which may help explain some cases of choking under pressure (e.g., Baumeister, 1984; Beilock & DeCaro, 2007). We can become more capable of taking multiple courses of action when the stakes increase. Yet, in many cases, we prepare and practice in low-pressure situations for those high-pressure occasions, and we would much rather just do that one thing we practiced when the pressure is on. It appears that only after being exposed to the high pressure for a while do we hit our stride at performing a repetitive or perhaps well-rehearsed task. However, the forms of preparation in our experiments were short term, and the tasks were much more basic than those that people usually face under high pressure. More research is needed before we can potentially connect findings regarding cognitive and perceptual flexibility to people’s initial jitters on important examinations or performances.
In light of recent theories that describe task switch costs entirely as products of basic memory mechanisms and interference among them (e.g., Altmann & Gray, 2008; Badre & Wagner, 2006), it is worth assessing how the reward effects we observed can fit into such models. These models associate the current task with a neural activation that leaves a diminished trace that can still interfere with performance on the next trial—in particular, if the task has changed. Finding similar effects in POP, which primarily reflects buildup and competition in implicit visual memory, like those we found in task switching, suggests that memory processes can parallel, if not underlie, task-switching processes. We believe that the reward effects we observed could fit into those models if we simply assume that higher rewards produce stronger memory-related neural activations (e.g., Kennerley & Wallis, 2009). This can easily explain why people were faster at repeating the same task when getting a high reward after a high reward, as compared with after a low reward (more memory trace remaining from the previous trial) and why they were slowest when the reward decreased (lower activation from the current trial must compete with strong memory trace from a previous trial). The switch cost changes, however, depend on specific activation levels, and testing out those parameters in models may be a worthwhile future theoretical investigation.
Our primary findings were all driven by relative changes in rewards, instead of their absolute amounts. Although recent work has examined how rewards obtained from previous tasks can affect performance on subsequent unrewarded tasks (e.g., Della Libera & Chelazzi, 2006, 2009), not much attention has been paid to potential changes in behavior resulting from variations in incentives over time. We have shown that such relative changes in reward can affect behavior in ways that consistently large rewards do not. People are known for emotionally and cognitively adapting to a tremendous influx of rewards, such as higher salaries or winning the lottery (Frederick & Loewenstein, 1999), and behavioral economists now generally argue that people’s perceptions of changes in their economic status are reference dependent (Kahneman & Tversky, 1979; Köszegi & Rabin, 2006). Even rats have been shown to perform better when reward increases than when reward stays consistently high (Zeaman, 1949). These findings and theories, coupled with everyday experience we might have, suggest that changes in rewards and incentives are important motivating factors for our actions. Their influences on many other psychological processes have yet to be discovered.
In our experiments, changes in reward appeared to have been salient and influential even when the ultimate reward was success in a competition, rather than money. When experiments require us to run hundreds of trials, often the monetary reward amount we can give in individual trials may be too small for participants to be concerned about, and the repetitiveness certainly does not help rewards to stand out either. A competitive setting, where the difference between winning and losing out on a prize may be the performance on a few trials, appears to be one way to make these reward differences matter more (see also Kristjánsson et al., 2010, who doubled prize earnings for top performers). We do not doubt that larger differences in monetary reward can also be highly effective motivators on their own, especially in experiments with fewer trials. However, we think we have shown that the prospect of besting a fellow competitor, even in a just-for-fun competition, can be at least as effective a motivator as the prospect of earning a few more cents. This could be because differences in competitive outcomes also enhance psychological mechanisms that commonly change with monetary reward, such as vigilance or arousal, but it could also be because competition enhances other motivational processes specifically associated with social incentives. What we know now is that for reward and motivation researchers looking for a more cost-effective alternative than simply paying participants exorbitant sums for cognition experiments requiring hundreds of trials, a competition may be a good option to make those small trial-by-trial reward differences count.
References
Allport, A., Styles, E. A., & Hsieh, S. (1994). Shifting intentional set: Exploring the dynamic control of tasks. In C. Umiltà & M. Moscovitch (Eds.), Attention and performance XV: Conscious and nonconscious information processing (pp. 421–452). Cambridge, MA: MIT Press.
Altmann, E., & Gray, W. (2008). An integrated model of cognitive control in task switching. Psychological Review, 115, 602–639. doi:10.1037/0033-295X.115.3.602
Badre, D., & Wagner, A. D. (2006). Computational and neurobiological mechanisms underlying cognitive flexibility. Proceedings of the National Academy of Sciences, 103, 7186–7191. doi:10.1073/pnas.0509550103
Baumeister, R. F. (1984). Choking under pressure: Self consciousness and paradoxical effects of incentives on skillful performance. Journal of Personality and Social Psychology, 46, 610–620. doi:10.1037/0022-3514.46.3.610
Beilock, S. L., & DeCaro, M. S. (2007). From poor performance to success under stress: Working memory, strategy selection, and mathematical problem solving under pressure. Journal of Experimental Psychology. Learning, Memory, and Cognition, 33, 983–998. doi:10.1037/0278-7393.33.6.983
Berryhill, M. E., & Hughes, H. C. (2009). On the minimization of task switch costs following long-term training. Attention, Perception, & Psychophysics, 71, 503–514. doi:10.3758/APP.71.3.503
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Camerer, C. F., & Hogarth, R. M. (1999). The effects of financial incentives in experiments: A review and capital-labor-production framework. Journal of Risk and Uncertainty, 19, 7–42. doi:10.1023/A:1007850605129
Chun, M. M., Golomb, J. D., & Turk-Browne, N. B. (2011). A taxonomy of external and internal attention. Annual Review of Psychology, 62, 73–101. doi:10.1146/annurev.psych.093008.1004271
De Jong, R. (2000). An intention-activation account of residual switch costs. In S. Monsell & J. Driver (Eds.), Control of cognitive processes: Attention and performance XVIII (pp. 357–376). Cambridge, MA: MIT Press.
Della Libera, C., & Chelazzi, L. (2006). Visual selective attention and the effects of monetary rewards. Psychological Science, 17, 222–227. doi:10.1111/j.1467-9280.2006.01689.x
Della Libera, C., & Chelazzi, L. (2009). Learning to attend and to ignore is a matter of gains and losses. Psychological Science, 20, 778–784. doi:10.1111/j.1467-9280.2009.02360.x
Dreisbach, G., & Goschke, T. (2004). How positive affect modulates cognitive control: Reduced perseveration at the cost of increased distractibility. Journal of Experimental Psychology. Learning, Memory, and Cognition, 30, 343–353. doi:10.1037/0278-7393.30.2.343
Engelmann, J. B., & Pessoa, L. (2007). Motivation sharpens exogenous spatial attention. Emotion, 7, 668–674. doi:10.1037/1528-3542.7.3.668
Fecteau, J. H. (2007). Priming of pop-out depends upon the current goals of observers. Journal of Vision, 7(6, Art. 1), 1–11. doi: 10.1167/7.6.1
Fecteau, J., & Munoz, D. (2003). Exploring the consequences of the previous trial. Nature Reviews. Neuroscience, 4, 435–443. doi:10.1038/nrn1114
Frederick, S., & Loewenstein, G. (1999). Hedonic adaptation. In D. Kahneman, E. Diener, & N. Schwartz (Eds.), Well-being: The foundations of hedonic psychology (pp. 302–329). New York: Russell Sage Foundation Press.
Frey, B. S., & Jegen, R. (2001). Motivation crowding theory. Journal of Economic Surveys, 15, 589–611. doi:10.1111/1467-6419.00150
Gneezy, U., & Rustichini, A. (2000). A fine is a price. Journal of Legal Studies, 29, 1–17. doi:10.1086/468061
Hertwig, R., & Ortmann, A. (2001). Experimental practices in economics: A methodological challenge to psychologists? Brain and Behavioral Sciences, 24, 383–451.
Hickey, C., & Theeuwes, J. (2008). Reward primes visual search [Abstract]. Perception, 37(Suppl.), 46a.
James, W. (1890). The principles of psychology (Vol. 2). New York: Dover.
Jersild, A. (1927). Mental set and shift. Archives of Psychology, 14(Whole No. 89).
Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47, 263–291.
Kennerley, S. W., & Wallis, J. D. (2009). Reward-dependent modulation of working memory in lateral prefrontal cortex. The Journal of Neuroscience, 29, 3259–3270. doi:10.1523/JNEUROSCI.5353-08.2009
Köszegi, B., & Rabin, M. (2006). A model of reference-dependent preferences. Quarterly Journal of Economics, 121, 1133–1165. doi:10.1162/qjec.121.4.1133
Kristjánsson, Á. (2008). "I know what you did on the last trial"—A selective review of research on priming in visual search. Frontiers in Bioscience, 13, 1171–1181.
Kristjánsson, Á., Sigurjónsdóttir, Ó., & Driver, J. (2010). Fortune and reversals of fortune in visual search: Reward contingencies for pop-out targets affect search efficiency and target repetition effects. Attention, Perception, & Psychophysics, 72, 1229–1236. doi:10.3758/APP.72.5.1229
Leber, A. B., Turk-Browne, N. B., & Chun, M. M. (2008). Neural predictors of moment-to-moment fluctuations in cognitive flexibility. Proceedings of the National Academy of Sciences, 105, 13592–13597. doi:10.1073/pnas.0805423105
Lepper, M. R., Greene, D., & Nisbett, R. E. (1973). Undermining children's intrinsic interest with extrinsic reward: A test of the "overjustification" hypothesis. Journal of Personality and Social Psychology, 28, 129–137.
Logan, G. D. (2004). Working memory, task switching, and executive control in the task span procedure. Journal of Experimental Psychology: General, 133, 218–236. doi:10.1037/0096-3445.133.2.218
Logan, G. D., & Bundesen, C. (2003). Clever homunclus: Is there an endogenous act of control in the explicit task-cuing procedure? Journal of Experimental Psychology: Human Perception and Performance, 29, 575–599. doi:10.1037/0096-1523.29.3.575
Maljkovic, V., & Nakayama, K. (1994). Priming of pop-out: I. Role of features. Memory & Cognition, 22, 657–672.
Mayr, U., & Kliegl, R. (2003). Differential effects of cue changes and task changes on task-set selection costs. Journal of Experimental Psychology. Learning, Memory, and Cognition, 29, 362–372. doi:10.1037/0278-7393.29.3.362
Mellström, C., & Johannesson, M. (2008). Crowding out in blood donation: Was Titmuss right? Journal of the European Economic Association, 6, 845–863. doi:10.1162/JEEA.2008.6.4.845
Milstein, D. M., & Dorris, M. C. (2007). The influence of expected value on saccadic preparation. The Journal of Neuroscience, 27, 4810–4818. doi:10.1523/JNEUROSCI.0577-07.2007
Monsell, S. (2003). Task switching. Trends in Cognitive Sciences, 7, 134–140. doi:10.1016/S1364-6613(03)00028-7
Müller, J., Dreisbach, G., Goschke, T., Hensch, T., Lesch, K., & Brocke, B. (2007). Dopamine and cognitive control: The prospect of monetary gains influences the balance between flexibility and stability in a set-shifting paradigm. The European Journal of Neuroscience, 26, 3661–3668. doi:10.1111/j.1460-9568.2007.05949.x
Nakayama, K., Maljkovic, V., & Kristjánsson, Á. (2004). Short-term memory for the rapid deployment of visual attention. In M. S. Gazzaniga (Ed.), The cognitive neurosciences III (pp. 397–408). Cambridge, MA: MIT Press.
Nieuwenhuis, S., & Monsell, S. (2002). Residual costs in task switching: Testing the failure-to-engage hypothesis. Psychonomic Bulletin & Review, 9, 86–92.
Olds, J., & Milner, P. (1954). Positive reinforcement produced by electrical stimulation of septal area and other regions of rat brain. Journal of Comparative and Physiological Psychology, 47, 419–427.
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Rogers, R. D., & Monsell, S. (1995). Costs of a predictable switch between simple cognitive tasks. Journal of Experimental Psychology: General, 124, 207–230.
Rubinstein, J. S., Meyer, D. E., & Evans, J. E. (2001). Executive control of cognitive processes in task switching. Journal of Experimental Psychology: Human Perception and Performance, 27, 763–797. doi:10.1037//0096-1523.27.4.763
Rushworth, M. F. S., Paus, T., & Sipila, P. K. (2001). Attention systems and the organization of the human parietal cortex. The Journal of Neuroscience, 21, 5262–5271.
Skinner, B. F. (1950). Are theories of learning necessary? Psychological Review, 57, 193–216.
Stoet, G., & Snyder, L. H. (2007). Extensive practice does not eliminate human switch costs. Cognitive, Affective & Behavioral Neuroscience, 7, 192–197. doi:10.3758/CABN.7.3.192
Wager, T. D., Jonides, J., & Reading, S. (2004). Neuroimaging studies of shifting attention: A meta-analysis. Neuroimage, 22, 1679–1693. doi:10.1016/j.neuroimage.2004.03.052
Yeung, N., & Monsell, S. (2003). The effects of recent practice on task switching. Journal of Experimental Psychology: Human Perception and Performance, 29, 919–936. doi:10.1037/0096-1523.29.5.919
Zeaman, D. (1949). Response latency as a function of the amount of reinforcement. Journal of Experimental Psychology, 39, 466–483.
Author information
Authors and Affiliations
Corresponding author
Additional information
This research was supported by the Yale Kavli Institute. Portions of this article were presented at the 2009 annual meeting of the Vision Sciences Society in Sarasota, FL. We thank Jeremy Wolfe, Árni Kristjánsson, Riccardo Pedersini, Vidhya Navalpakkam, and an anonymous reviewer for helpful comments and suggestions on an earlier version of the manuscript.
This research was supported by the Yale Kavli Institute. Portions of this article were presented at the 2009 annual meeting of the Vision Sciences Society in Sarasota, FL. We thank Jeremy Wolfe, Árni Kristjánsson, Riccardo Pedersini, Vidhya Navalpakkam, and an anonymous reviewer for helpful comments and suggestions on an earlier version of the manuscript.
Rights and permissions
About this article
Cite this article
Shen, Y.J., Chun, M.M. Increases in rewards promote flexible behavior. Atten Percept Psychophys 73, 938–952 (2011). https://doi.org/10.3758/s13414-010-0065-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-010-0065-7