
Abstract
Images that are presented with targets of an unrelated detection task are better remembered than images that are presented with distractors (the attentional boost effect). The likelihood that any of three mechanisms, attentional cuing, prediction-based reinforcement learning, and perceptual grouping, underlies this effect depends in part on how it is modulated by the relative timing of the target and image. Three experiments demonstrated that targets and images must overlap in time for the enhancement to occur; targets that appear 100 ms before or 100 ms after the image without temporally overlapping with it do not enhance memory of the image. However, targets and images need not be synchronized. A fourth experiment showed that temporal overlap of the image and target is not sufficient, as detecting targets did not enhance the processing of task-irrelevant images. These experiments challenge several simple accounts of the attentional boost effect based on attentional cuing, reinforcement learning, and perceptual grouping.
Similar content being viewed by others


Introduction
An important function of any living organism is to detect and respond to behaviorally relevant events. The importance of this skill is obvious for everyday survival functions, such as finding food, as well as in engaging in modern human activities such as navigating highways and video game playing. Cognitive investigations into detecting and responding to behaviorally relevant events have taken many forms, spanning topics such as perception, attention, executive control, and reward processing. Although a great deal is known about how behaviorally relevant events are themselves processed, only recently have studies been conducted on how these events influence attention to and processing of other, unrelated, sources of input.
In simple detection tasks, the appearance of a behaviorally relevant event such as a cue or target elicits an attentional orienting response. Not only is neural processing of the target enhanced (Beck, Rees, Frith, & Lavie, 2001; Hon, Thompson, Sigala, & Duncan, 2009; Ress & Heeger, 2003), but processing of items that are presented at the same time as or soon after the target is also affected (Duncan, 1980; Raymond, Shapiro, & Arnell, 1992). In the attentional blink, the appearance of a target letter in a stream of distractor letters briefly impairs the ability to detect a second target that appears soon afterwards (Chun & Potter, 1995; Dux & Marois, 2009; Raymond et al., 1992), though targets that appear immediately after the first target are often spared (Jefferies & Di Lollo, 2009; Visser, Bischof, & Di Lollo, 1999). Experiments on the attentional dwell-time suggest that attending to a target can interfere with subsequent target detection for as long as 500 ms (Duncan, Ward, & Shapiro, 1994). The detection of targets that coincide with other targets is also impaired, as is illustrated in experiments on the “two-target cost” (Duncan, 1980; Pohlmann & Sorkin, 1976).
These data make it clear that attending to at least some goal-relevant events, such as targets in a simple detection task, can interfere with processing other targets. However, recent research has shown that not all processing is impaired when targets are detected. On the contrary, Seitz and Watanabe have shown that perceptual sensitivity to motion that coincides with a target increases following repeated pairings of the target and motion over several days (Seitz & Watanabe, 2003). This task-irrelevant perceptual learning has been shown after long-training periods and in tasks in which the background motion was subthreshold and irrelevant to the participant’s task. Similar effects have been observed in explicit, long-term memory for background images. In several experiments, Swallow and Jiang (2010) asked participants to encode a long series of images (500 ms/image) into memory. At the same time, they were asked to press a key whenever an unrelated target event occurred (e.g., an odd colored square, an odd tone, or a red ‘X’ among other colored letters). Later memory for images that were presented with a target was better than memory for images that were presented with distractors, a phenomenon labeled the attentional boost effect. The memory advantage was observed only for images presented with the target; no enhancement or deficit was observed for images presented 500 ms before of after the target appeared. A similar effect has also been observed for perceptual discrimination tasks (Swallow, Makovski, & Jiang, under revision) and for source memory for familiar stimuli (Lin, Pype, Murray, & Boynton, 2010).
The observation that processing of unrelated background stimuli is enhanced when a target is detected in an unrelated task runs counter to the ubiquitous observation of dual-task and target-related interference. Despite the surprising nature of the attentional boost effect, however, it is likely that it reflects the operation of a well-studied mechanism whose effects have not been previously observed due to an earlier emphasis on target processing itself. There are several potential mechanisms, including attentional cuing, prediction based reinforcement learning, and perceptual grouping.
In the experiments demonstrating the attentional boost effect, the target and the image onset at the same time but the image remained on the screen for several hundred milliseconds after the target. It is therefore possible that participants could have used the target as a cue to attend to the background image, thereby enhancing its processing. This suggestion encompasses two different attentional accounts of the attentional boost effect. First, the target may have acted as a cue to orient attention, with visuospatial attention spreading from it to the background image that was presented in the same location as the target. The time course of processing enhancements as a consequence of orienting attention to a target has been well characterized; peaking 100–200 ms after the target appears (Egeth & Yantis, 1997; Nakayama & Mackaben, 1989; Olivers & Meeter, 2008). Images presented with the target were on the screen during this period of time and may have benefited from this enhancement. It is also possible that the target may have had an alerting effect (Coull, 1998; Fan, McCandliss, Sommer, Raz, & Posner, 2002; Posner & Boies, 1971; Posner & Petersen, 1990), enhancing general task processing for a brief period of time. As with attentional orienting, alerting may have enhanced processing of the background image because it stayed on the screen for some time after the target appeared.
A second possibility is based on the notion that detecting a target is rewarding (Raymond, Fenske, & Westoboy, 2005; Seitz & Watanabe, 2009), producing a reinforcement signal that strengthens memory for predictive stimuli. In classical conditioning, information that is predictive or consistently paired with a rewarding stimulus is learned and reinforced in memory, allowing an organism to anticipate that a reward is imminent. In the case of the attentional boost effect, images that are concurrently presented with the target may be reinforced in memory because they signal that a rewarding stimulus is present. Indeed, reinforcement learning has been used to explain task-irrelevant perceptual learning (Seitz, Kim, & Watanabe, 2009; Seitz & Watanabe, 2009). According to Seitz and Watanabe, detecting a target in a stream of distractors triggers a reward signal. This reward signal facilitates and reinforces the processing of information that is predictive of or co-varies with the target, whether it is task-relevant or not. Although there are important differences between the attentional boost effect and task-irrelevant perceptual learning (e.g., the relevance of background images and the amount of learning prior to the manifestation of the enhancement), it is possible that similar mechanisms underlie them both.
A final mechanism that may account for the attentional boost effect is perceptual grouping of the background image with the target square. In previous experiments, the background image and the square onset at the same time. Visual stimuli whose features vary according to the same temporal schedule tend to be perceived as a single group or object (Alais, Blake, & Lee, 1998; Jiang, Chun, & Marks, 2002). If images and targets are grouped together into the same perceptual entity, then increasing attention to one part of the group, the detection target, should also lead to increased attention to another part of the group, the background image (Driver & Baylis, 1989).
An important aspect of explanations derived from attentional cuing, reinforcement learning, and perceptual grouping is time. Attention is inherently dynamic. It takes time to engage, time to peak, and time to disengage. Reinforcement also has temporal characteristics: information that coincides with or predicts a rewarding or adverse event is reinforced in memory (Gallistel & Gibbon, 2000). Finally, temporal synchrony, common onset, and common fate are strong perceptual grouping cues (Alais et al., 1998; Jiang et al., 2002; Sekuler & Bennett, 2001). However, because previous research on the attentional boost effect has been restricted to paradigms in which the target and image onset at the same time, the role of time in this effect has not been explored.
Here, three experiments constrain attentional cuing, reinforcement, and perceptual grouping hypotheses by manipulating the temporal relationship between the background images and the search stimuli. For these experiments, participants first encoded a long series of briefly presented images in a dual-task encoding procedure. During image encoding, participants were asked to monitor a second stream of white and black squares that appeared in the same location as the images.Footnote 1 The participants’ task was to remember the background images for a memory test and to press the spacebar whenever a white square appeared. The timing of the onset of the squares relative to the onset of the images was manipulated. In some conditions the square temporally overlapped with a pre- or post- image mask instead of the image itself. To preview the results, temporal overlap, but not common onset, was necessary for the attentional boost to occur in these experiments. To determine whether temporal overlap is sufficient for the attentional boost effect, a final experiment manipulated the relevance of the background image to participants’ task. The outcome of this experiment suggested that the attentional boost effect is modulated by attention to the background image.
Experiment 1: does attentional cuing account for enhanced image encoding?
Perceptual enhancement as a consequence of attentional orienting peaks approximately 100–200 ms after a cue (Egeth & Yantis, 1997; Nakayama & Mackeben, 1989; Olivers & Meeter, 2008). If targets cue attention to the background images, then images presented 100 ms after the target should benefit as much if not more from this cuing than images presented at the same time as targets. This idea is supported by observations of lag-1 sparing in the attentional blink: When a short interval separates two targets in a rapid visual stream, the second target (T2) is often detected more accurately than the first target (T1), presumably because it falls in the peak of the orienting response triggered by T1 (Potter, Staub, & O’Connor 2002). Experiment 1 tested this attentional cuing hypothesis by presenting the images for 100 ms (with a 400-ms inter-stimulus interval during which the image was masked) and varying the onset of the square so that it either temporally overlapped with the image (temporal overlap condition) or appeared 100 ms earlier (square early condition). If the attentional boost effect reflects a perceptual processing enhancement of the image as a consequence of attentional cuing by the target square, then it should be greater in the square early condition than in the temporal overlap condition.
Method
Participants
Fifteen participants (4 males, 18–21 years old) completed this experiment. All participants in all experiments were students at the University of Minnesota. They gave informed consent and were compensated $10 or with psychology course credit for their time. The procedures were approved by the University of Minnesota IRB.
Materials
A set of 350 color images (256 × 256 pixels) of celebrities, politicians, and athletes was obtained through online searches. All images were recent photographs of a recognizable individual whose face was pictured from the front. For each participant, the pictures were randomly assigned to be old faces, which were shown in the encoding task (n = 140), to be used as novel face foils for the recognition tests (n = 140), and to be used as filler faces to separate trials during the encoding task (n = 70). Randomization was done separately for different participants. A separate set of 17 faces was used for familiarizing participants with the dual-task encoding procedure.
The stimuli were presented on a 19-inch (c.48.3-cm) CRT monitor (1,024 × 768 pixels, 75 Hz) with a PowerPC Macintosh computer using MATLAB and the PsychToolBox (Brainard, 1997; Pelli, 1997). Viewing distance was approximately 40 cm but was unrestrained.
Tasks
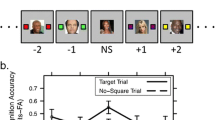
The experiment consisted of two phases, a dual-task encoding phase and a recognition memory phase. During the dual-task encoding phase (about 20 min) participants performed a continuous detection task. For this task participants were shown a series of squares and faces in the center of the screen at a rate of 500 ms per image and square (Fig. 1). The faces (12.7 × 12.7°) were presented for 100 ms, followed by a 400 ms mask (12.7 × 12.7°). The masks were images of faces whose pixels had been randomly shuffled into new locations. The squares (1 × 1°) appeared for 100 ms with a 400-ms interval between squares. Participants pressed the spacebar as quickly as possible whenever they saw a white square (target) and made no response when a black square (distractor) appeared. They were also instructed to remember all of the faces for a later recognition test, but were not informed of the exact nature of this test. More than 100 visual displays were serially presented without interruption for approximately 1 min at a time before participants were given a break.

Timeline illustrating the continuous detection task and relative timing of the images, masks, and squares in the different conditions. a For the continuous detection task participants monitored serially presented images and squares for occasional targets (white squares). Target onsets were separated by a variable interval of 3.5–7.5 s. Participants were also typically instructed to remember the images for a later memory test. b In Experiments 1 and 2 images appeared for 100 ms, followed by a 400-ms mask. Squares appeared in front of an image or mask for 100 ms followed by a 400-ms interval. The relative timing of the square and image onsets was manipulated. In the temporal overlap condition of Experiments 1 and 2, the square onset and offset at the same time as the image. In the square early condition of Experiment 1, the square appeared 100 ms before the image and in front of the mask. In the image early condition of Experiment 2, the square appeared 100 ms after the image. The common onset and separate onset conditions of Experiment 3 were identical to the temporal overlap and image early conditions, except that the image was presented for 500 ms, and was not masked (the squares always appeared in front of the image). In all cases the images assigned to the target position (T) were those that appeared closest in time to the white square target
The recognition memory test phase of the experiment consisted of old/new recognition of the faces and a confidence rating on a 7-point scale. On each trial, one face (12.7 × 12.7°) appeared in the center of the screen and participants were instructed to press ‘b’ if they believed the face was shown to them in the dual-task encoding session and ‘n’ if they believed it was a new face. After the participant’s response the face was replaced with a 7-point confidence scale. The numbers 1–7 were displayed from left to right, with the words “Not Confident” to the left of the 1 and “Certain” to the right of the 7. Participants pressed the 1–7 keys on the number pad to indicate their certainty that their previous response was correct. Participants were instructed to use the whole scale.
Design
During the dual-task encoding phase participants performed the continuous detection task. To examine the time course of the effect of target detection on image encoding, each of the 140 old faces was randomly assigned to one of 7 serial positions around the target for each participant. There were 20 unique faces per position. The square at fixation was black in all positions except for the fourth (the target position), which had white squares. Thus, a trial series consisted of 3 distractor displays, a target display, and 3 additional distractor displays. Trial series were presented continuously, with 0–8 filler faces (randomly determined for each trial) separating each trial series to reduce the regularity with which the targets appeared. The beginning and end of a trial series were not apparent to the participants. Because the number of filler displays that separated the trial series was randomized, the temporal position of the target was unpredictable. Filler faces were always presented with a black square. To ensure that performance on the memory test was above chance, each old face was presented 10 times. However, each time a face was presented, it could appear after any of the faces assigned to the previous serial position and before any of the faces assigned to the next serial position.Footnote 2 The stimulus stream consisted of a total of 200 trial series (10 repetitions of the 20 images in each serial position) and was divided into 20 blocks of 10 trial series each (all of the images were shown in two consecutive blocks).
The temporal relationship of the faces and the squares was manipulated by varying the onset of the squares relative to the onset of the faces (Fig. 1). In the temporal overlap condition, the faces and squares appeared at the same time, both for 100 ms. In the square early condition, the squares appeared 100 ms before the faces. In this condition, the square appeared against the mask of the previous face. Onset conditions were blocked and block order was randomized. The 20 faces assigned to each serial position were randomly and evenly assigned to one of the onset conditions, resulting in 10 faces per position per onset condition.
The recognition memory test consisted of 280 trials. On half the trials, an old image was presented, and on the other half a novel image was presented. The images (12.7° × 12.7°) were presented at the center of the screen for an “old/new” response and confidence rating. Trials were randomly ordered.
Analysis
During the recognition memory test, novel images were randomly intermixed with old images. Because of this and the fact that they were not shown during the encoding phase, novel images could not be uniquely assigned to serial positions or different onset conditions. Therefore, independent estimates of d’ could not be obtained for each condition. Instead, the analyses were performed on hit rates (correctly reporting that an old face was old) and a single false recognition rate was calculated for each participant. False recognition rates are plotted in the graphs to illustrate “chance” performance on the recognition tests (e.g., the probability that an image would be called “old” when there should be no memory of the image).
Results and discussion
Dual-task encoding phase
Participants responded to most of the targets and made few false alarms (Table 1) in both the temporal overlap and square early conditions. Accuracy in detecting the white square targets in these two conditions was comparable in terms of hit rate, t(14) = −1.37, p = .193, and false alarm rate, t(14) = 1.11, p = .287. However, responses were faster in the square early condition than in the temporal overlap condition, t(14) = 9.86, p < .001. This difference may reflect the fact that dual-task interference between the square-detection and the image-encoding task is smaller when the stimulus-onset-asynchrony is 100 ms rather than 0 ms. It may also be due to the fact that the background stimulus did not change when the square onset in the square early condition (e.g., there were no other visual transients), making them easier to process than in the temporal overlap condition.
Face recognition
Accuracy on the recognition test was measured as the proportion of correctly recognized old faces (hits) presented at a particular serial position. This is illustrated in Fig. 2 for both the temporal overlap and square early conditions. False recognition rates are also plotted to illustrate the chance-level of reporting that an image is old.

Recognition test performance (hit rate) for images presented at different serial positions relative to the white-square target in the temporal overlap and square early conditions in Experiment 1. False recognition rates illustrate the proportion of “old” responses to new images. Error bars ±1SEM
An analysis of variance (ANOVA) indicated that recognition test performance depended on the interaction of serial position and onset condition, F(6, 84) = 4.09, p = .001, η p 2 = .226. The main effect of onset condition was not significant, F(1, 14) = 0.4, p = .536, suggesting that, overall, performance was similar whether the square appeared 100 ms before the image or at the same time as the image. The main effect of serial position also was not significant, F = 1.32, p = .258. Critically, in the temporal overlap condition accuracy was greater for images that onset at the same time as a target than for images that onset at the same time as a distractor, replicating the attentional boost effect, F(6, 84) = 3.52, p = .004, η p 2 = .201. In contrast, in the square early condition, there was no advantage for images that onset 100 ms after the target relative to those that onset 100 ms after a distractor, F(6, 84) = 0.99, p = .434.
To verify that the interaction of serial position and onset condition reflected performance specifically for images in the target position, a second analysis compared performance for images in the target position to performance in all pre-target positions (the mean of serial positions T − 3 to T − 1) and all post-target positions (the mean of serial positions T + 1 to T + 3). In the temporal overlap condition, recognition accuracy was greater for images presented in the target position than for images presented in the pre-target positions, t(14) = 3.68, p = .002, and in the post-target positions, t(14) = 3.37, p = .004 (there was no reliable difference in accuracy for images in pre-and post-target positions, t(14) = 0.19, p = .854). In contrast, in the square early condition there were no reliable differences in recognition accuracy for images presented in pre-target, target, post-target positions, t(14)s < 1.32, ps > .208.
In addition to indicating whether they recognized a picture from the continuous detection task, participants were asked to rate their confidence in the accuracy of their recognition judgments. Confidence ratings for correct responsesFootnote 3 (Appendix A) were consistent with the accuracy data, showing that participants were more confident in their memory responses for images presented with targets in the temporal overlap condition, but not in the square early condition, indicated by a reliable interaction of serial position and onset condition, F(6, 78) = 2.36, p = .038, η p 2 = .154; main effect of position, F(6, 78) = 3.07, p = .009, η p 2 = .191; no main effect of onset condition, F(1, 13) = 0.3, p = .594.
According to the attentional cuing hypothesis, memory for images presented with targets is enhanced because the targets act as a cue to attend to the images. Perceptual processing is enhanced for several hundred milliseconds following an attentional cue, peaking approximately 100–200 ms after the cue appears (Egeth & Yantis, 1997; Nakayama & Mackeben, 1989; Olivers & Meeter, 2008). Because images in the square early condition were on the screen during this period of time, they were present when the effects of attentional cuing should have been strongest. However, there was no advantage for images that onset 100 ms after a target relative to those that onset 100 ms after a distractor. Contrary to the attentional cuing hypothesis, the attentional boost effect occurs and is greater for images that are presented slightly before but not during the period of peak attentional enhancement that follows a cue.
These data also suggest that another attentional mechanism, alerting, plays a limited role in the attentional boost effect. Unlike transient processing enhancements following a cue, alerting influences responses to information across the visual field. A visual alerting signal enhances subsequent processing, producing a significant benefit as little as 100 ms after the alerting signal (Posner & Boies, 1971). Similar to the attentional cuing hypothesis, an account of the attentional boost effect based on alerting predicts that memory for images presented 100 ms after the target should be facilitated relative to images presented 100 ms after distractors. The data from the square early condition in Experiment 1 are not consistent with this prediction.
Experiment 2: can targets retroactively enhance image encoding?
The data from Experiment 1 suggest that the attentional boost effect cannot be attributed to attentional cuing or alerting produced by target detection, but do not clearly address whether the effect reflects the reinforcement of predictive information in memory. Detecting targets may be inherently more rewarding than rejecting distractors (Seitz et al., 2009; Seitz & Watanabe, 2009). Experiment 2 tested whether targets can enhance memory for images that predict target onset when those images are the strongest environmental cue of a target (the reinforcement hypothesis). To do this, Experiment 1 was repeated, but with the squares appearing 100 ms after the faces. If reinforcement learning of predictive information is a central component of the attentional boost effect, then memory for images presented immediately before a target should be enhanced relative to those presented immediately before a distractor.
Methods
Participants
Fifteen new participants (5 males, 18–24 years old) completed this experiment.
Materials
The materials were identical to those used in Experiment 1.
Tasks and design
The tasks were the same as those used in Experiment 1, with the following exception. In the image early condition, the square appeared 100 ms after the face. In this condition, the square appeared in front of the mask for the previous face and did not temporally overlap with the face. After the square disappeared, the mask was presented on its own for an additional 300 ms (Fig. 1). As in Experiment 1, in the temporal overlap condition the face and square onset at the same time and overlapped in time.
Results and discussion
Dual-task encoding phase
Participants responded to most of the white square targets and made few false alarms (Table 1) in both the temporal overlap and image early conditions. Performance in these two conditions was comparable in terms of hit rate, t(14) = 0.13, p = 0.9, response time, t(14) = 0.38, p = .708, and false alarm rate, t(14) = -0.74, p = .468.
Face recognition
Performance on the face recognition test is illustrated in Fig. 3. Faces presented with targets in the temporal overlap condition were better remembered than faces presented with distractors. Critically, however, there was no apparent advantage for faces presented immediately before targets in the image early condition. An ANOVA confirmed that the interaction between onset condition and serial position was reliable, F(6, 84) = 2.41, p = .033, η p 2 = .147; main effect of position, F(6, 84) = 2.83, p = .014, η p 2 = .168; marginal effect of onset condition, F(1,14) = 4.42, p = .054, η p = .24. A second ANOVA excluding images presented at the target position indicated that hit rates were similar for images presented with distractors in the temporal overlap and image early conditions, F(1, 14) = 2.15, p = .164.

Recognition test performance (hit rate) for images presented at different serial positions relative to the white-square target in the temporal overlap and image early conditions in Experiment 2. False recognition rates illustrate the proportion of “old” responses to new images. Error bars ±1SEM
Follow up analyses indicated that there was a reliable main effect of position in the temporal overlap condition, F(6, 84) = 3.79, p = .002, η p 2 = .213. Images presented at the same time as targets were better remembered than images presented at the same time as distractors in pre-target positions, t(14) = 2.7, p = .017, and in post-target positions, t(14) = 4.51, p < .001. The difference in accuracy for images in pre-target positions and post-target positions did not reach significance, t(14) = 1.92, p = .075. The effect of position was not significant in the image early condition, both in the ANOVA, F(6, 84) = 1.81, p = .106 and in t tests comparing pre-target, target, and post-target positions, t(14)s < 1.37, ps > .193.
Confidence ratings also varied across serial position, F(6, 84) = 2.41, p = .034, η p 2 = .147. There was a trend towards an interaction between serial position and onset condition, F(6, 84) = 1.79, p = .111; no effect of onset condition, F(1, 14) = 0.11, p = .741. Confidence ratings for correct responses peaked for images presented with targets in the temporal overlap condition and for images presented in serial position T + 3 in the image early condition (see Appendix A).
In classical conditioning, a stimulus that consistently precedes or coincides with the rewarding stimulus is reinforced in memory, later influencing behavior to maximize the probability of obtaining the reward again (Gallistel & Gibbon, 2000). It is therefore possible that the attentional boost effect resulted from the reinforcement of the image coinciding with the target in memory. Indeed, Seitz and Watanabe rely on reinforcement learning to explain a perceptual learning phenomenon that is very similar to the attentional boost effect (Seitz & Watanabe, 2003, 2005). In their experiments, Seitz and Watanabe paired a particular direction of motion in a random dot display with target letters in a stream of briefly presented letters. Subsequent psychophysical testing showed that, following several days of training in the letter detection task, participants’ motion sensitivity selectively increased for the direction that was paired with the target letters. They argued that this learning reflects reinforcement of stimulus features (e.g., motion direction) that are consistently paired with the rewarding stimulus (e.g., the target letters). Similarly, images that are predictive of targets in this and previous experiments on the attentional boost effect may be reinforced in memory.
In the image early condition of Experiment 2, the images that were most predictive of target onset were those presented immediately before it. If detecting targets enhances memory for concurrently presented images through reinforcement learning, then images presented immediately before the target in the square early condition should benefit as much as, if not more than, those presented with targets in the temporal overlap condition (McAllister, 1953). However, the difference in memory for images presented with targets versus images presented with distractors was far greater when they temporally overlapped than when the image appeared before the target. This pattern of data casts doubt on accounts of the attentional boost effect that suggest that the images are better remembered because of their predictive value. This is not to say that other accounts based on reward processing are also ruled out. It is possible that the influence of a reinforcement mechanism in the attentional boost effect is restricted to information that is coincident with the target (Miller & Barnet, 1993). On this point, it is unclear whether the reward-based account of task-irrelevant perceptual learning proposed by Seitz and Watanabe (2005) may still apply to the attentional boost effect, as they were not specific about the temporal dynamics of reinforcement in their model. However, they do seem to suggest that, as in classical conditioning, reinforcement should be strongest for information that precedes the rewarding stimulus, with weaker reinforcement for information that coincides with it (Seitz & Watanabe, 2005, p. 332).
Experiment 3: does enhanced encoding depend on common onset?
Experiments 1 and 2 challenged simple attentional-cuing and reinforcement of predictive information accounts of the attentional boost effect. However, they are entirely consistent with the claim that the attentional boost effect reflects the spread of attention from one part of a perceptual group (the target) to the rest of the group (the image; the perceptual grouping hypothesis). Indeed, demonstrations of the attentional boost effect have been limited to those conditions in which the detection stimuli and the background images appeared at the same time. Common onset and, more generally, temporal synchrony in feature changes are perceptual grouping cues (Alais et al., 1998; Jiang et al., 2002; Sekuler & Bennett, 2001), making it possible that the attentional boost effect depends upon the grouping of images with targets. Alternatively, temporal overlap, not common onset, may be the critical factor in the attentional boost effect, as the advantage for images presented with targets was eliminated whenever the target was presented over a mask. In Experiment 3, the images always temporally overlapped with the target, but in some conditions the detection squares onset 100 ms after the image. Although temporal overlap occurs in both conditions, the presence of temporal grouping cues in the common onset condition should strengthen perceptual grouping and any effects it has on later memory for the images.
Methods
Participants
Sixteen new participants (8 males, 18–32 years old) completed this experiment.
Materials
The materials were identical to those used in Experiments 1 and 2.
Tasks and design
The tasks were the same as those used in Experiment 2, with the following exception. Rather than masking the faces after 100 ms, the faces were presented for a full 500 ms, with no inter-stimulus interval. Thus, in the common onset condition, the faces and squares appeared at the same time. After 100 ms, the square disappeared and the face was presented on its own for another 400 ms. In the separate onset condition, the squares appeared 100 ms after the face.Footnote 4 In this condition, the face was presented on its own for 100 ms, then with the square for 100 ms, and then on its own for an additional 300 ms (Fig. 1). Thus, the square and the face overlapped in time in both the common onset and separate onset conditions, but the square appeared 100 ms after the face in the separate onset condition.
Results and discussion
Dual-task encoding phase
Participants responded to most of the square targets and made few false alarms in both conditions of the experiment (Table 1). Performance in the common onset and separate onset conditions was comparable in terms of hit rate, t(15) = −0.98, p = .343, and false alarm rate, t(15) = −1.23, p = .237. Response times were faster in the separate onset condition than in the common onset condition, t(15) = 6.97, p < .001. As in Experiment 1, this difference in response times could reflect better processing of the square when its onset is not accompanied by other visual transients (e.g., the onset of an image or a mask).
Face recognition
Performance on the face recognition test is illustrated in Fig. 4. Recognition memory was best for images presented with targets, and this effect was similar in the common onset and separate onset conditions; main effect of serial position, F(6, 90) = 5.1, p < .001, η p 2 = .254, no interaction between serial position and onset condition, F(6, 90) = 0.99, p = .438, no main effect of onset condition, F(1, 15) = 0.01, p = .928. Additional analyses indicated that, in both the common onset and separate onset conditions, images presented with targets were more accurately remembered than images in pre-target positions (common onset: t(15) = 2.9, p = .011; marginal in the separate onset condition: t(15) = 2.03, p = .06), and than images in post-target positions (common onset: t(15) = 3.36, p = .004; separate onset: t(15) = 2.7, p = .016). In both onset conditions, accuracy was similar for images presented in pre-target and post-target positions, t(15) < 1.36, p > .193. Furthermore, there was no reliable difference in the memory advantage for images presented with targets in the common onset condition (difference in hits for images presented with targets and images presented with distractors, mean = .135, SD = .159) and separate onset condition (mean = .123, SD = .2), t(15) = 0.44, p = .665.

Recognition test performance (hit rate) for images presented at different serial positions relative to the white-square target in the common onset and separate onset conditions in Experiment 3. False recognition rates illustrate the proportion of “old” responses to new images. Error bars ±1SEM
Confidence ratings for hits (Appendix A) were consistent with the accuracy data, showing a main effect of serial position, F(6, 90) = 2.24, p = .046, η p 2 = .13, but no effect of onset condition, F(1,15) = 0.11, p = .746, or an interaction, F(6, 90) = 1.16, p = .336.
If the attentional boost effect reflects grouping of the images and squares into a single entity, then it may be modulated by the presence of a grouping cue. One powerful temporal grouping cue is temporal synchrony and common onset: When visual stimuli appear at the same time or share a common fate, they tend to be perceived as a single group (Alais et al., 1998; Jiang et al., 2002; Sekuler & Bennett, 2001). Removing the common onset grouping cue should decrease the likelihood that the images are grouped with the squares and eliminate or decrease the magnitude of the attentional boost effect. The data did not support this prediction, however, suggesting that temporal synchrony does not play a critical role in the attentional boost effect.
Other aspects of the data are consistent with the suggestion that the attentional boost effect does not simply reflect perceptual grouping. Perceptual grouping from temporal cues also may be influenced by whether the stimuli offset at the same time or not (e.g., they share a common fate, cf. Sekuler & Bennett, 2001). As illustrated in both conditions in Experiment 3, however, common offset also does not appear to be a necessary condition for the effect. In addition, although form identification interferes with perceptual grouping (Ben-Av, Sagi, & Braun, 1992) the attentional boost effect occurs when a target is defined by the conjunction of form and color features (Swallow & Jiang, 2010). Thus, the attentional boost effect occurs despite task demands that interfere with perceptual grouping and in the absence of two powerful temporal grouping cues.
Experiment 4: is overlap sufficient for enhanced encoding?
These experiments have clearly demonstrated that the attentional boost effect does not depend on the common onset of images and targets, but does depend on the images and targets overlapping in time. The next experiment further constrains accounts of the attentional boost effect by examining whether temporal overlap is sufficient for the effect to occur. To do this, two different groups of participants performed the continuous detection task under the common onset condition described in Experiment 3. One group was told that they would make judgments about the background images later in the experiment (the image-relevant group) and the other group was told to ignore the background images (the image-irrelevant group). If temporal overlap is sufficient to enhance memory for images presented with targets when they are task-irrelevant, then the attentional boost effect should be present in both groups. However, if attention to the background image modulates the attentional boost effect then it should be significantly weakened in the image-irrelevant group.
Methods
Participants
Thirty-four participants, evenly divided into two groups, completed the experiment (7 males, 18–28 years old).
Materials
A set of 330 images of outdoor and indoor scenes was acquired from personal collections, online searches, and Aude Oliva’s online database. Using scenes instead of faces reduced the likelihood that participants in the image-irrelevant condition would not be able to effectively ignore the background images. For each participant, these images were randomly assigned to be old scenes (n = 130) that were presented in the continuous detection task and later tested, filler scenes (n = 70) that were presented in the continuous detection task to separate trials, and new scenes (n = 130) that were used as foils in the recognition memory test.
Tasks
The task and design of the experiment were identical to the common onset condition of Experiment 3 with the following exceptions. For each participant scenes were randomly assigned to one of 13 serial positions (10 scenes per position, 130 total) around the target (6 pre-target positions and 6 post-target positions). As in the previous experiments, each scene was presented 10 times in the same serial position, but the scene assigned to a particular serial position on a given trial was randomly determined. Furthermore, the use of 0–8 filler images to separate the trial series randomized the number of displays between two targets. Two different groups of participants received different instructions for the continuous detection task. Both groups were told to respond as quickly as possible whenever a white target square appeared. The image-relevant group was told that they would be making judgments about the background images after they completed the detection task. The image-irrelevant group was told to ignore the background images and that attending to them may hurt their performance on the detection task.
For the recognition test, participants were first asked to rate how much they liked an image on a 7-point scale, with higher ratings indicating that the picture was better. The image appeared at the center of the screen with the sentence “Please indicate how much you like this scene (1–7)” and a number scale below it. Responses were made using the 1–7 keys on the keypad. Participants were instructed to avoid basing their ratings on whether they remembered the scenes from the previous task. After participants rated the image, the question “Was this scene shown to you in the last part?” appeared and participants pressed ‘b’ for yes and ‘n’ for no. The recognition question occurred after the ratings to reduce the saliency of the memory element of the task and increase the likelihood that participants did not explicitly base their preference ratings on whether they remembered the images.
Results and discussion
One participant in the image-irrelevant condition indicated that all images in the recognition memory test were “new”; data from this participant were discarded.
Dual-task encoding phase
Participants in both groups responded to most of the square targets (image-relevant mean = .97, SD = .03; image-irrelevant mean = .98, SD = .03) and made few false alarms (image-relevant mean = .01, SD = .04; image-irrelevant mean = .02, SD = .02). Target detection accuracy was therefore comparable in the two groups, Fs < 1 for both hits and false alarms. Response times were numerically slower in the image-relevant group (mean = 486 ms, SD = 41) than in the image-irrelevant group (mean = 467 ms, SD = 36), but this difference did not reach significance, t(31) = 1.38, p > .15.
Scene ratings
Participants’ ratings of the scenes during the recognition test appear in Appendix B. Preference ratings given by the two groups were comparable, F(1, 31) < 1. Ratings were also relatively uniform across serial position, F < 1, and did not interact with image relevance, F < 1.
Scene recognition
Performance on the recognition memory test was comparable between groups, both in terms of hits, F(1, 31) = 1.59, p = .216, and in terms of false recognition rates, t(31) = 2.54, p = .591. However, the serial position at which the scene was encoded influenced the hit rate, F(12, 372) = 2.55, p < .003, η p 2 = .076. Critically, the effect of serial position on hit rate depended on the relevance of the image, F(12, 372) = 1.92, p < .03, η p 2 = .058. As can be seen in Fig. 5, the benefit of presenting an image at the same time as a target was only apparent when the image was task relevant.

Recognition test performance (hit rate) for images presented at different serial positions relative to the white-square target during encoding in Experiment 4. Participants in the image-relevant group were told that they would be making judgments about the pictures after the continuous detection task. Participants in the irrelevant group were told to ignore the pictures. False recognition rates (Relevant-FR and Irrelevant-FR) illustrate the proportion of “old” responses to new images for the different groups. Error bars ±1SEM
To better characterize the effect of the target on image encoding, recognition memory for images presented at the same time as the target was compared to that for images presented in all pre-target positions (positions T − 6 to T − 1) and to images presented in all post-target positions (positions T + 1 to T + 6). When the images were relevant, images presented with targets were better remembered than those presented before the target, t(16) = 3.45, p = .004, and after the target, t(16) = 2.99, p = .009. There was no difference in performance for images in pre- and post-target encoding positions, t(16) = 0.445, p = .662. In contrast, when the image was task-irrelevant hit rates for images presented at the same time as a target was similar across pre-target, target, and post-target positions, highest t(15) = 1.26, p = .226.
Although the data from Experiments 1–3 indicated that temporal overlap of the background image and target is necessary for the attentional boost effect to occur, it does not appear that temporal overlap is sufficient. In Experiment 4, both groups of participants were exposed to the same stimuli and were told to perform the target detection task. However, only participants in the image-relevant condition were informed that the images would be part of a later task. Whereas these participants showed better memory for images presented with targets than for images presented with distractors, those participants who were told that the background images in the detection task were irrelevant showed no such advantage. One might argue that it is possible that additional pairings of the images and targets could result in enhanced memory for the background images when they are task-irrelevant: The images were each presented only ten times, whereas demonstrations of task-irrelevant perceptual learning have utilized thousands of trials (e.g., Seitz & Watanabe, 2003). This could certainly be the case, though task-irrelevant perceptual learning appears to depend upon the background stimuli being sub-threshold. Thousands of pairings of supra-threshold irrelevant background stimuli with targets does not increase later sensitivity to those stimuli (Tsushima, Seitz, & Watanabe 2008). It therefore appears that temporal overlap between the targets and images is necessary but not sufficient to produce the attentional boost effect. Attention to the background image is an important modulatory factor in the attentional boost effect.
General discussion
Images that are presented with targets are better remembered than images that are presented at the same time as distractors, a difference labeled the attentional boost effect (Swallow & Jiang, 2010). Several potential explanations of the attentional boost effect have been proposed, and most of these make predictions about the effect of changing the relative timing of the target and image onsets. This study demonstrated that, although the relative timing of target and image onsets is important to the attentional boost effect, it is secondary to the their presentation overlapping in time. The attentional boost effect was observed whenever the target and the image overlapped in time as long as the image was task-relevant. Shifting the onset of the target so that it appeared 100 ms before or 100 ms after the image but did not overlap with the image in time eliminated the attentional boost effect, as did instructing participants to ignore the background image. These data are inconsistent with simple accounts of the attentional boost effect based on attentional cuing, learning of reward-predictive information, and perceptual grouping.
The attentional boost effect and other related phenomena
The attentional boost effect is not confined to a single modality or to simple detection tasks like the one used in the experiments reported here. In a recent study (Swallow & Jiang, 2010), the advantage for images presented with targets was observed with auditory and visual targets, and with targets defined by a feature conjunction (e.g., a red ‘X’ among other red letters and ‘X’s of a different color). However, the nature of the detection task does influence whether or not the attentional boost effect is observed. If there is no detection task then perceptually distinct task-irrelevant stimuli do not influence memory (e.g., there is no advantage for images presented with task-irrelevant oddballs). Furthermore, a detection task that requires target categorization and response selection eliminates the advantage for images presented with targets, though it does not cause interference. Thus, it is likely that the attentional boost effect reflects the engagement of a mechanism associated with target-related processing and whose effects on image processing can only be observed when interference from the detection task is low or of a certain type.
Another recent study has also demonstrated that memory for images presented at the same time as targets is enhanced relative to images presented at the same time as distractors. In their experiments, Lin and colleagues (2010) first familiarized participants with a set of scenes. They then showed participants a rapid serial visual presentation (RSVP) sequence of letters that appeared over the familiar scenes. Participants pressed a key when a target letter appeared and, after the RSVP sequence was presented, indicated whether a probe scene was presented in the sequence, testing source memory for the images. As in the attentional boost effect, recognition memory was better for scenes presented at the same time as a letter target than for those presented at the same time as a letter distractor. Interestingly, there was no evidence of dual-task interference in their studies; targets enhanced source memory for images above and beyond source memory under single-task conditions. This is in contrast to the data reported by Swallow and Jiang (2010) in which images presented with targets were remembered as well as images encoded under single-task conditions. The source of this discrepancy is unclear, though it may reflect the fact that Lin et al. (2010) tested source memory rather than memory for the images themselves. Not only would this have increased the difficulty of the test (indeed, performance on the memory tests was near chance for images presented with distractors), it would also have forced participants to rely on a potentially separate memory system than that used to remember scene identity (Davachi, 2006; Dobbins, Foley, Schacter, & Wagner, 2003; Yonelinas, Otten, Shaw, & Rugg, 2005). Additional research will be required to further investigate this discrepancy.
Perhaps because of the similarity in their names and their use of serial visual presentation tasks, the attentional boost effect has also been compared to the attentional blink. In the attentional blink, the items in the stream are presented at a faster rate than the stimuli in the attentional boost effect, about one item every 100 ms. Under these conditions it is difficult to detect a target if it occurs within 200–500 ms after another target (Chun & Potter, 1995; Dux & Marois, 2009; Raymond et al., 1992). Importantly, the ability to detect a target that appears immediately after another target is not impaired (lag-1 sparing) (Jefferies & Di Lollo, 2009; Visser et al., 1999). Although there are many similarities in procedure, it is difficult to compare the attentional blink to the attentional boost effect precisely because the stimulus presentation rates are so different. It is interesting to note, however, that there was no evidence that a target in the square early condition of Experiment 1 either interfered with or facilitated processing of the image that appeared 100 ms later. These data suggest that lag-1 sparing cannot explain the enhancement of memory for images concurrently presented with targets.
Additional phenomena in which an oddball stimulus or feature facilitates performance in another task have also been described. These include effects such as the pip and pop effect (Van der Burg, Olivers, Bronkhorst, & Theeuwes, 2008), the time dilation effect (New & Scholl, 2009), the accessory stimulus effect (Jepma, Wagenmakers, Band, & Nieuwenhuis, 2009), and the isolation effect (Fabiani & Donchin, 1995; Hunt, 1995). Most of these have been discussed in greater detail elsewhere (Swallow & Jiang, 2010). However, it is worth emphasizing that these effects typically occur in single-task situations when the oddball stimulus or feature is irrelevant and when no other stimulus is presented with the control items. For example, letter identification is speeded when a tone is presented with the target letter relative to when no tone is presented with that letter (Jepma et al., 2009). In contrast, the attentional boost effect reflects a difference in performance for items presented with target tones (or letters or squares) and items presented with distractor tones (or letters or squares) (Swallow & Jiang, 2010). Moreover, the perceptual saliency of the target cannot explain the advantage for images presented with targets relative to those presented with distractors (Swallow & Jiang, 2010).
New constraints on theoretical accounts of the attentional boost effect
Although the attentional boost effect has been demonstrated with a variety of simple target detection tasks and background stimuli, there has been relatively little insight into the mechanisms that underlie it. A variety of well-studied cognitive mechanisms have been proposed, including the role of distinctiveness in memory for items, arousal, responding to and representing context changes, alerting, attentional cuing, perceptual grouping, and reinforcement learning. Previous studies (Swallow & Jiang, 2010) have shown that the processing enhancement is brief (<500 ms) and does not occur in response to the appearance of salient, task-irrelevant stimuli (e.g., when there is no target detection task but the stimuli are the same), casting doubt on accounts derived from arousal and the memory isolation effect. Furthermore, any account of the attentional boost effect is constrained by the data presented here, and must explain why the attentional boost effect does not occur for images that appear shortly after the target, images that appear shortly before the target, or for task-irrelevant images.
It may be possible to adjust the attentional cuing, reinforcement learning, and perceptual grouping accounts to accommodate the data from Experiments 1–4. For example, with attentional cuing, the time-course of processing enhancements following a cue may be different in the task used here than in studies that used different paradigms and stimuli. With reinforcement learning, one might argue that images that precede the target are not as predictive as images that coincide with the target. In both cases, accommodating the data presented here will require a better understanding of how these basic attentional and learning processes operate in tasks in which the target is not cued.
The data are more agnostic with regard to the role of grouping in the attentional boost effect. For example, grouping may occur after perceptual processing, perhaps as a result of relating an item to its context in memory (Capaldi & Neath, 1995; Diana, Yonelinas, & Ranganath, 2007; Polyn & Kahana, 2008). However, to be viable, any grouping account would have to provide a mechanism that is temporally precise, that is not influenced by grouping strength, that is modulated by image-relevance, and by which temporal overlap and image relevance are all that is necessary for grouping to occur. The literature on grouping, particularly temporal grouping, does not currently address these issues.
A framework for a theoretical account of the attentional boost effect
The data presented here and elsewhere (Swallow & Jiang, 2010) undermine accounts of the attentional boost effect derived from attentional orienting, reinforcement learning, perceptual saliency, and perceptual grouping. To best account for the attentional boost effect, it may be useful to consider what happens in the neurocognitive system as a target is processed and detected.
Neurons in the inferior temporal cortex can signal that a target is present less than 100 ms after its onset (Lamme, 2003). Although this is soon after the target is presented, by the time attention can be directed to targets in the continuous detection task used here, however, they are no longer on the screen or will soon disappear. Under these conditions the only way to enhance processing of the target is to attend to a representation that already exists (i.e., the attentional enhancement is retrospective). Attention can be directed to representations in iconic memory, working memory, and long-term memory (Ciaramelli, Grady, & Moscovitch, 2008; Makovski & Jiang, 2007; Ruff, Kristjánsson, & Driver, 2007; Sperling, 1960).
The suggestion that the attentional boost effect reflects retrospective attention may explain why it is limited to images that temporally overlap with the targets, but it is not a complete explanation of the effect. First, it does not explain why processing of images that are presented at the same time as the targets is enhanced rather than impaired. Second, whatever mechanism produces the attentional boost effect must operate on representations that have already been biased by task-relevance. This implies that the enhancement of the images is unlikely to occur on preattentive representations, such as iconic memory. Finally, it does not explain how the processing enhancement is constrained to the brief moment in time (~100 ms) when the target appeared or how the target and image representations are associated in memory.
Although these are all complex issues, there may be a simple way to account for them. In monkeys, the detection of a target is tightly coupled to a transient increase in the release of norepinephrine (NE) from neurons in the locus coeruleus (LC; Aston-Jones & Cohen, 2005). Detecting the presence of a target during the dual-task encoding phase of the attentional boost experiments may lead LC neurons to transiently fire and release NE to afferent brain regions. Transient increases in NE push neuronal firing in these regions to one extreme or another (e.g., they are either active or not), speeding the process with which neural networks settle into their final representational states (Aston-Jones & Cohen, 2005). Although speculative, it is possible that detecting a target triggers a phasic LC–NE response that then facilitates neural processing in areas that perceptually process and encode the concurrent images.
An account of the attentional boost effect based on phasic LC–NE responses addresses several of the difficulties involved in identifying and describing the mechanisms that lead to it. LC–NE projections are broad and nonspecific (Aston-Jones & Cohen, 2005; Freedman, Foote, & Bloom, 1975), making it possible that the neural processing of images will benefit from the release of NE as well as processing of the target. Furthermore, if the enhancement is due to the temporal coincidence of target and image processing then there is no need to assume that other binding or grouping mechanisms are involved. An LC–NE account of the attentional boost effect also suggests that its temporal dynamics are largely determined by the dynamics of phasic LC–NE responses to target events. Finally, because the LC projects to brain regions involved in both early and late perceptual processing (Aston-Jones & Cohen, 2005), this enhancement could occur for representations that have already been biased by attention and task-relevance.
The LC–NE system is thought to be involved in alerting and attention functions (Aston-Jones & Cohen, 2005; Coull, 1998; Einhäuser, Sout, Koch, & Carter, 2008; Robbins, 1997; Schultz & Dickinson, 2000), making it an odd candidate mechanism for a phenomenon that does not appear to conform to predictions based on alerting and attention. However, the phasic LC–NE account of the attentional boost effect emphasizes the fact that attention can also enhance the processing of representations that already exist as well as processing of current perceptual input. It fits neatly into current ideas about how the perceptual systems process and represent the world. For example, Lamme (2003) distinguishes between a fast feed-forward sweep of processing through the visual system and recurrent processing within a visual area. Within the context of the attentional boost effect, the rapid categorization of a stimulus as a potential target may trigger a phasic LC–NE response, which then may speed recurrent processing in visual areas involved in representing the concurrent background image.
In a similar vein, an alerting response to a target has also been used in conjunction with reinforcement learning to explain task-irrelevant perceptual learning (Seitz & Watanabe, 2003; 2005). However, the LC–NE account does not imply that the effect depends upon reinforcement learning. Rather, it suggests that the attentional boost effect can occur within a single trial. Indeed, the attentional boost effect has been observed in single trial designs in other studies (Lin et al., 2010; Swallow, Makovski, & Jiang, under revision). Finally, the LC–NE account of the attentional boost effect does not contradict a role of perceptual grouping in the attentional boost effect: phasic NE responses to targets could enhance processing of images that are grouped with targets as well as those that are not.
Although a fairly detailed account of the attentional boost effect may be derived from what is known about phasic responses of the LC to targets, it has not been subjected to empirical scrutiny. It should, however, provide a rich basis for future explorations of the attentional boost effect both at the cognitive and neurophysiological levels. Of critical importance will be to address whether or not the effects of phasic LC–NE signaling on perceptual processing are modulated by task-relevance and is restricted to information that is presented at the same moment in time as the target event.
Conclusion
In modern life, people often need to quickly categorize and respond to goal-relevant events. Surprisingly, the attentional boost effect indicates that detecting goal-relevant events, like a target, can facilitate the encoding of other, simultaneous relevant information. The data presented here clearly show that this enhancement is not due to attentional cuing, reinforcement of predictive images in memory, or to the synchronous presentation of the images and targets. Two factors, however, appear to be critical to the effect: temporal overlap of the image and target and the relevance of the image to the participants’ task. A theoretical framework based upon the phasic responses of the locus coeruleus to target events is consistent with this pattern of data but requires additional evidence to evaluate whether it is a viable mechanism for the attentional boost effect. Regardless of the ultimate conclusion regarding the mechanisms that underlie the attentional boost effect, the data presented here provide clear constraints that any theoretical account of the effect must satisfy.
Notes
In the present experiments, targets were always white squares and distractors were always black squares. However, previous research used a variety of targets and distractors types and has generalized the effect to more demanding detection tasks, such as when the target is defined by the conjunction of color and letterform (Swallow & Jiang, 2010).
Although repeating the images improves overall memory performance and the power of these experiments, the attentional boost effect can be observed after a single trial (Lin et al., 2010; Swallow, Makovski, & Jiang, under revision) and when the images are paired with targets only once. In a preliminary study, participants encoded objects while listening for auditory target tones. Even though the objects were presented once during encoding, recognition memory was better for objects presented with target beeps than for objects presented with distractor beeps, F(6, 24) = 2.77, p = .034.
Data from one participant were removed because this person made no correct responses in one of the cells (position 6 of the temporal overlap condition)
A control experiment evaluated whether participants could accurately discriminate conditions in which the square and face onset at the same time from those when the square onset after the face. Two stimulus streams of faces and squares were shown to eight participants. The faces and squares onset at the same time in one stimulus stream and in the other stream the square onset 50, 100, or 200 ms after the face. Participants were able to correctly indicate which stimulus stream consisted of faces and squares that onset together 86.5% (SD = 17.1%) of the time with stimulus onset asynchronies (SOAs) of 100 ms, reliably greater than with SOAs of 50 ms (mean = 76.2%, SD = 17.8%, t(7) = 2.69, p = .03) and similar to performance for SOAs of 200 ms (mean = 91.9%, SD = 11.2%, t(7) = −1.84, p = .11).
References
Alais, D., Blake, R., & Lee, S.-H. (1998). Visual features that vary together over time group together over space. Nature Neuroscience, 1(2), 160–164. doi:10.1038/1151
Aston-Jones, G., & Cohen, J. D. (2005). An integrative theory of locus coeruleus-norepinephrine function: Adaptive gain and optimal performance. Annual Review of Neuroscience, 28, 403–450. doi:10.1146/annurev.neuro.28.061604.135709
Beck, D. M., Rees, G., Frith, C. D., & Lavie, N. (2001). Neural correlates of change detection and change blindness. Nature Neuroscience, 4(6), 645–650. doi:10.1038/88477
Ben-Av, M. B., Sagi, D., & Braun, J. (1992). Visual attention and perceptual grouping. Perception & Psychophysics, 52(3), 277–294.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Capaldi, E. J., & Neath, I. (1995). Remembering and forgetting as context discrimination. Learning & Memory, 2, 107–132.
Chun, M. M., & Potter, M. C. (1995). A two-stage model for multiple target detection in rapid serial visual presentation. Journal of Experimental Psychology: Human Perception and Performance, 21(1), 109–127. doi:10.1037/0096-1523.21.1.109
Ciaramelli, E., Grady, C. L., & Moscovitch, M. (2008). Top-down and bottom-up attention to memory: A hypothesis (AtoM) on the role of the posterior parietal cortex in memory retrieval. Neuropsychologia, 46, 1828–1851. doi:10.1016/j.neuropsychologia.2008.03.022
Coull, J. T. (1998). Neural correlates of attention and arousal: Insights from electrophysiology, functional neuroimaging and psychopharmacology. Progress in Neurobiology, 55, 343–361. doi:10.1016/S0301-0082(98)00011-2
Davachi, L. (2006). Item, context and relational episodic encoding in humans. Current Opinion in Neurobiology, 16, 693–700. doi:10.1016/j.conb.2006.10.012
Diana, R. A., Yonelinas, A. P., & Ranganath, C. (2007). Imaging recollection and familiarity in the medial temporal lobe: A three-component model. Trends in Cognitive Sciences, 11(9), 379–386. doi:10.1016/j.tics.2007.08.001
Dobbins, I. G., Foley, H., Schacter, D. L., & Wagner, A. D. (2002). Executive control during episodic memory retrieval: Multiple prefrontal processes subserve source memory. Neuron, 35, 989–996. doi:10.1016/S0896-6273(02)00858-9
Driver, J., & Baylis, G. C. (1989). Movement and visual attention: The spotlight metaphor breaks down. Journal of Experimental Psychology: Human Perception and Performance, 15(3), 448–456. doi:10.1037/h0090403
Duncan, J. (1980). The locus of interference in the perception of simultaneous stimuli. Psychological Review, 87(3), 272–300. doi:10.1037/0033-295X.87.3.272
Duncan, J., Ward, R., & Shapiro, K. L. (1994). Direct measurement of attentional dwell time in human vision. Nature, 369, 313–315. doi:10.1038/369313a0
Dux, P. E., & Marois, R. (2009). The attentional blink: A review of data and theory. Attention, Perception, & Psychophysics, 71(8), 1683–1700. doi:10.3758/APP.71.8.1683
Egeth, H. E., & Yantis, S. (1997). Visual attention: Control, representation, and time course. Annual Review of Psychology, 48, 269–297.
Einhäuser, W., Stout, J., Koch, C., & Carter, O. (2008). Pupil dilation reflects perceptual selection and predicts subsequent stability in perceptual rivalry. Proceedings of the National Academy of Science, USA, 105(5), 1704–1709. doi:10.1073/pnas.0707727105
Fabiani, M., & Donchin, E. (1995). Encoding processes and memory organization: A model of the von Restorff Effect. Journal of Experimental Psychology. Learning, Memory, and Cognition, 21(1), 224–240. doi:10.1037/0278-7393.21.1.224
Fan, J., McCandliss, B. D., Sommer, T., Raz, A., & Posner, M. I. (2002). Testing the efficiency and independence of attentional networks. Journal of Cognitive Neuroscience, 14(3), 340–347. doi:10.1162/089892902317361886
Freedman, R., Foote, S. L., & Bloom, F. E. (1975). Histochemical characterization of a neocortical projection of the nucleus locus coeruleus in the squirrel monkey. The Journal of Comparative Neurology, 164(2), 209–231. doi:10.1002/cne.901640205
Gallistel, C. R., & Gibbon, J. (2000). Time, rate, and conditioning. Psychological Review, 107(2), 289–344. doi:10.1037/0033-295X.107.2.289
Hon, N., Thompson, R., Sigala, N., & Duncan, J. (2009). Evidence for long-range feedback in target detection: Detection of semantic targets modulates activity in early visual areas. Neuropsychologia, 47, 1721–1727. doi:10.1016/j.neuropsychologia.2009.02.011
Hunt, R. R. (1995). The subtlety of distinctiveness: What von Restorff really did. Psychonomic Bulletin & Review, 2(1), 105–112.
Jefferies, L. N., & Di Lollo, V. (2009). Linear changes in the spatial extent of the focus of attention across time. Journal of Experimental Psychology: Human Perception and Performance, 35(4), 1020–1031. doi:10.1037/a0014258
Jepma, M., Wagenmakers, E.-J., Band, G. P. H., & Nieuwenhuis, S. (2009). The effects of accessory stimuli on information processing: Evidence from electrophysiology and a diffusion model analysis. Journal of Cognitive Neuroscience, 21(5), 847–864. doi:10.1162/jocn.2009.21063
Jiang, Y., Chun, M. M., & Marks, L. E. (2002). Visual marking: Selective attention to asynchronous temporal groups. Journal of Experimental Psychology: Human Perception and Performance, 28(3), 717–730. doi:10.1037/0096-1523.28.3.717
Lamme, V. A. F. (2003). Why visual attention and awareness are different. Trends in Cognitive Sciences, 7(1), 12–18. doi:10.1016/S1364-6613(02)00013-X
Lin, J. Y., Pype, A. D., Murray, S. O., & Boynton, G. M. (2010). Enhanced memory for scenes presented at behaviorally relevant points in time. PLoS Biology, 8(3), e1000337. doi:1000310.1001371/journal.pbio.1000337
Makovski, T., & Jiang, Y. V. (2007). Distributing versus focusing attention in visual short-term memory. Psychonomic Bulletin & Review, 14(6), 1072–1078.
McAllister, W. R. (1953). Eyelid conditioning as a function of the CS-US interval. Journal of Experimental Psychology, 45(6), 417–422. doi:10.1037/h0059534
Miller, R. R., & Barnet, R. C. (1993). The role of time in elementary associations. Current Directions in Psychological Science, 2(4), 106–111.
Nakayama, K., & Mackeben, M. (1989). Sustained and transient components of focal visual attention. Vision Research, 29(11), 1631–1647. doi:10.1016/0042-6989(89)90144-2
New, J. J., & Scholl, B. J. (2009). Subjective time dilation: Spatially local, object-based, or a global visual experience? Journal of Vision, 9(2), 1–11. doi:10.1167/9.2.4
Olivers, C. N. L., & Meeter, M. (2008). A boost and bounce theory of temporal attention. Psychological Review, 115, 836–863. doi:10.1037/a0013395
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Pohlmann, L. D., & Sorkin, R. D. (1976). Simultaneous three-channel signal detection: Performance and criterion as a function of order of report. Perception & Psychophysics, 20(3), 179–186.
Polyn, S. M., & Kahana, M. J. (2008). Memory search and the neural representation of context. Trends in Cognitive Sciences, 12(1), 24–30. doi:10.1016/j.tics.2007.10.010
Posner, M. I., & Boies, S. J. (1971). Components of attention. Psychological Review, 78(5), 391–408. doi:10.1037/h0031333
Posner, M. I., & Petersen, S. E. (1990). The attention system of the human brain. Annual Review of Neuroscience, 13, 25–42.
Potter, M. C., Staub, A., & O’Connor, D. H. (2002). The time course of competition for attention: Attention is initially labile. Journal of Experimental Psychology: Human Perception and Performance, 28, 1149–1162. doi:10.1037/0096-1523.28.5.1149
Raymond, J. E., Fenske, M. J., & Westoboy, N. (2005). Emotional devaluation of distracting patterns and faces: A consequence of attentional inhibition during visual search? Journal of Experimental Psychology: Human Perception and Performance, 31(6), 1404–1415. doi:10.1037/0096-1523.31.6.1404
Raymond, J. E., Shapiro, K. L., & Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: An attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 18, 849–860. doi:10.1037/0096-1523.18.3.849
Ress, D., & Heeger, D. J. (2003). Neuronal correlates of perception in early visual cortex. Nature Neuroscience, 6(4), 414–420. doi:10.1038/nn1024
Robbins, T. W. (1997). Arousal systems and attentional processes. Biological Psychology, 45, 57–71. doi:10.1016/S0301-0511(96)05222-2
Ruff, C. C., Kristjánsson, Á., & Driver, J. (2007). Readout from iconic memory and selective spatial attention involve similar neural processes. Psychological Science, 18(10), 901–910. doi:10.1111/j.1467-9280.2007.01998.x
Schultz, W., & Dickinson, A. (2000). Neuronal coding of prediction errors. Annual Review of Neuroscience, 23, 473–500.
Sekuler, A. B., & Bennett, P. J. (2001). Generalized common fate: Grouping by common luminance changes. Psychological Science, 12(6), 437–444.
Seitz, A. R., Kim, D., & Watanabe, T. (2009). Rewards evoke learning of unconsciously processed visual stimuli in adult humans. Neuron, 61(5), 700–707. doi:10.1016/j.neuron.2009.01.016
Seitz, A. R., & Watanabe, T. (2003). Is subliminal learning really passive? Nature, 422, 36. doi:10.1038/422036a
Seitz, A. R., & Watanabe, T. (2005). A unified model for perceptual learning. Trends in Cognitive Sciences, 9(7), 329–334. doi:10.1016/j.tics.2005.05.010
Seitz, A. R., & Watanabe, T. (2009). The phenomenon of task-irrelevant perceptual learning. Vision Research, 49(21), 2604–2610. doi:10.1016/j.visres.2009.08.003
Sperling, G. (1960). The information available in brief visual presentations. Psychological Monographs: General and Applied, 74, 1–29.
Swallow, K. M., & Jiang, Y. V. (2010). The attentional boost effect: Transient increases in attention to one task enhance performance in a second task. Cognition, 115, 118–132. doi:10.1016/j.cognition.2009.12.003
Swallow, K. M., Makovski, T., & Jiang, Y. V. (under revision). Enhanced perceptual processing and the attentional boost effect.
Tsushima, Y., Seitz, A. R., & Watanabe, T. (2008). Task-irrelevant learning occurs only when the irrelevant feature is weak. Current Biology, 18(12), R516–R517. doi:10.1167/8.6.478
Van der Burg, E., Olivers, C. N. L., Bronkhorst, A. W., & Theeuwes, J. (2008). Pip and Pop: Nonspatial auditory signals improve spatial visual search. Journal of Experimental Psychology: Human Perception and Performance, 34(5), 1053–1065. doi:10.1037/0096-1523.34.5.1053
Visser, T. A. W., Bischof, W. F., & Di Lollo, V. (1999). Attentional switching in spatial and nonspatial domains: Evidence from the attentional blink. Psychological Bulletin, 125(4), 458–469. doi:10.1037/0033-2909.125.4.458
Yonelinas, A. P., Otten, L. J., Shaw, K. N., & Rugg, M. D. (2005). Separating the brain regions involved in recollection and familiarity in recognition memory. The Journal of Neuroscience, 25(11), 3002–3008. doi:10.1523/JNEUROSCI.5295-04.2005
Acknowledgements
This research was funded in part by NIH 071788 and the Institute for Research in Marketing at the University of Minnesota. We thank Tal Makovski for comments, and Jennifer Decker, Kathryn Hecht, Sui Lau, Erin Crawford, Heather Vandenheuvel, Leah Watson, Marie McDougall, and Ben Kline for help with data collection.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A
Appendix B
Rights and permissions
About this article
Cite this article
Swallow, K.M., Jiang, Y.V. The role of timing in the attentional boost effect. Atten Percept Psychophys 73, 389–404 (2011). https://doi.org/10.3758/s13414-010-0045-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-010-0045-y