
Abstract
Objectives
Our objective was to generate a value set for the SF-6Dv2 using time trade-off (TTO) and a discrete-choice experiment with a duration dimension (DCETTO) in China.
Methods
A large representative sample of the Chinese general population was recruited from eight provinces/municipalities in China, stratified by age, sex, education level, and proportion of urban/rural residence. Respondents completed eight TTO tasks and ten DCETTO tasks during face-to-face interviews. Ordinary least squares (OLS), random-effects, fixed-effects, and Tobit models were used for TTO data, and conditional logit and mixed logit models were used for DCETTO. The monotonicity of model coefficients and the consistency of the predicted values according to intraclass correlation coefficient (ICC), mean absolute difference (MAD), and mean squared difference (MSD) were compared between the two approaches.
Results
In total, 3320 respondents (50.3% male; range 18–90 years) were recruited. The random-effects model and the conditional logit model were preferred for the TTO and DCETTO, respectively. The TTO values ranged from − 0.277 to 1, with 927 (4.94%) states considered as worse than dead (WTD). The corresponding range for DCETTO was − 0.535 to 1, with a higher WTD of 8.50%. DCETTO presented minor nonmonotonicity with the coefficients in two dimensions. Values from the two approaches were highly consistent (ICC 0.9804, MAD 0.0588, MSD 0.0055), albeit those with DCETTO were slightly lower than those with TTO. The value set generated by TTO was preferred given the better monotonicity and the statistical significance of coefficients.
Conclusions
The Chinese value set for the SF-6Dv2 was established based on the TTO approach, but the DCETTO also performed well. Minor issues of nonmonotonicity did present for DCETTO.
Similar content being viewed by others
The Chinese value set for the SF-6Dv2 was established using a time trade-off (TTO) approach, which will facilitate the calculation of quality-adjusted life-years. |
A direct comparison between the TTO and discrete-choice experiment with a duration dimension (DCETTO) approaches indicated a good performance for both; however, minor issues of non-monotonicity existed in DCETTO estimates. |
A systematic difference was found between value sets developed using the TTO and DCETTO approaches. |
1 Introduction
Economic evaluations of healthcare interventions are becoming integral to the reimbursement decision-making process in many countries, including China [1, 2]. Cost-utility analysis is a form of economic evaluation that quantifies health outcomes on a standardized metric, typically the quality-adjusted life-year (QALY), a single value produced by multiplying a quality adjustment weight (or health utility) by life duration [2,3,4]. The health utility, which lies on a 0–1 death–full health QALY scale, is calculated by a value set for a range of possible health states described by the health state classification system of generic preference-based measures. Examples of the most used measures include the EuroQol 5-Dimensions (EQ-5D) and the Short-Form Six-Dimension (SF-6D) [2, 5, 6], both of which are recommended for use in Chinese guidelines for pharmacoeconomic evaluations [7].
The SF-6D is derived from the Short-Form 36 (SF-36) health survey, which is one of the most widely-used health-related quality-of-life measures worldwide, including in China [2, 6, 8, 9]. The original health state classification system of the SF-6D comprises six dimensions with four to six levels in each, including physical functioning (PF), role limitation (RL), social functioning (SF), pain (PN), mental health (MH), and vitality (VT). Recently, a second version of the SF-6D, SF-6Dv2, was developed, which revisited the items selected from the SF-36 and modified the ambiguity between dimension levels and inconsistency of wording in the original version [8, 10]. The SF-6Dv2 has the same six dimensions as the SF-6Dv1, with five to six levels in each dimension, yielding up to 18,750 health states [2, 8, 10]. More details on the development of the SF-6Dv2 and comparisons with the SF-6Dv1 can be found elsewhere [8, 10]. The Simplified Chinese version of the SF-6Dv2 was developed after translation and cross-cultural adaption, and preliminary psychometric testing was also conducted among the Chinese general population [11]. A country-specific value set for the SF-6Dv2 is currently available in the UK [12].
Health state utility values are commonly elicited using time trade-off (TTO) and standard gamble (SG) approaches [2, 13, 14]. Although TTO is generally regarded as simpler than SG, it is still considered too cognitively demanding for certain populations because of its iterative process, which may further result in response inconsistencies and subsequent data exclusions [2, 14,15,16]. A choice-based approach, the discrete-choice experiment (DCE), which some studies have argued may be simpler than the iterative process of TTO tasks, has recently gained popularity [16,17,18,19]. DCE tasks present two or more alternative health states, and respondents indicate their preference for one state over the other. However, a key problem in using DCEs has been how to anchor the values estimated by logit models, i.e., latent utilities, onto the QALY scale [20,21,22,23]. The DCE with a duration dimension (DCETTO) approach, in which an additional dimension of life duration is presented with the health state, provides a valid alternative requiring no separate task or data manipulation for anchoring [19, 24,25,26,27,28,29,30].
Until now, no Chinese value set for the SF-6Dv2 has been available for the calculation of QALYs. A pilot study in 2018, based on a representative sample of the general population in Tianjin, China, was conducted to compare the acceptability, consistency, and accuracy of the TTO, DCE, and DCETTO approaches in utility elicitation by using the SF6Dv2 [31]. DCE and DCETTO were found to be feasible in the establishment of value sets, but they were not considered easier to understand or answer than TTO, which is consistent with a previous study [19]. In the pilot study, DCETTO had the highest completion rates and shortest completion time but showed a slight non-monotonicity on model coefficients [31], which has also been reported in other studies [12, 24, 28,29,30]. Therefore, this study aimed to generate a Chinese value set for SF-6Dv2 and to compare TTO and DCETTO approaches in a large representative sample of the general population in China.
2 Methods
Face-to-face interviews were conducted among a large representative sample of the general population of China to collect TTO and DCETTO responses, which were then modeled to estimate utility values for all health states in the SF-6Dv2.
2.1 Elicitation Tasks Design
Both TTO and DCETTO elicitation tasks were employed in this study. The composite TTO approach, which was developed by the EuroQol group [32, 33], was used in the TTO task (hereafter TTO) (Fig. 1a in the electronic supplementary material [ESM]), where “better than dead” and “worse than dead” (WTD) states were valued by conventional TTO and lead-time TTO, respectively. A detailed description of the composite TTO approach can be found elsewhere [31,32,33]. The health states ‘‘being in a wheelchair’’ and “being in a health state worse than dead” were used as warm-up questions to make sure respondents understood the concept of TTO before proceeding to the formal tasks. In the DCETTO task (Fig. 1b in the ESM), respondents were presented with a pair of health states described by the SF-6Dv2, with a further dimension representing the number of years living in that health state followed by death. Four levels of life-years were chosen: 1, 4, 7, and 10 years [12]. The longest duration was set to 10 years to be commensurate with the standard timeframe of the TTO task. Two stepwise warm-up questions were used in the DCETTO tasks. The first warm-up question consisted of a pair of health states described by three dimensions, the first two of which were randomly chosen from SF-6Dv2 dimensions, and the third dimension represented the life duration. In the second warm-up question, two extra dimensions were further randomly chosen from the remaining SF-6Dv2 dimensions and added to describe the health states (i.e., five dimensions in total).
2.2 Health State Selection
The SF-6Dv2 defines a total of 18,750 health states, with more than 175 million potential pairwise combinations generated in the full factorial design. The number of possible combinations is even larger if the life duration dimension is added. A trade-off between the number of health states directly valued and the cognitive burden on respondents was considered following previous studies [31, 34, 35]. For TTO tasks, 295 health states described by the SF-6Dv2 were selected, including the six mildest imperfect health states (211111, 121111, 112111, 111211, 111121, 111112), the worst state (555655), and 288 other states generated based on near orthogonal arrays using SAS® Studio. The mildest health states were deliberately included because it allowed direct observations to distinguish the mildest impairments from full health. The 288 states were first distributed over 48 blocks, the state 555655 (included in all 48 blocks), and the six mildest states (each randomly included in eight blocks) were then added in the blocks. Each respondent was randomly assigned a block (i.e., eight TTO tasks) for valuation.
For DCETTO tasks, 300 pairs of health states (split into 30 blocks) were generated using the balanced overlap method. Both main effects and two-way interactions between the levels of each dimension and life-years were considered in the experimental design. Statistical efficiency was maximized with regard to the D-efficiency using Lighthouse Studio 9.6.0 (Sawtooth Software, Inc.) [36,37,38]. Each respondent was randomly assigned a block (i.e., ten DCETTO tasks) for valuation; the task order and the left–right position of health states within each task were all randomized.
2.3 Respondents
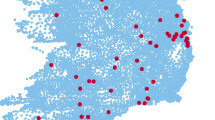
For each pair of DCETTO tasks, 100 observations are expected to result in robust model estimation [12]. Accordingly, the total target sample size was set at 3000. Respondents were recruited from eight cities, including Wuhan (central), Tianjin (north), Nanjing (east), Guangzhou (south), Lanzhou (northwest), Harbin (northeast), Chengdu, and Guiyang (southwest), as well as their surrounding rural areas, to achieve sufficient geographical spread and varied economic development levels in China (Fig. 2a in the ESM) [39, 40].
A stratified sampling method was used, in which four quotas were set for age, sex, education level, and proportion of urban/rural residence, to ensure these distributions of the sample resembled those of the Chinese general population [39, 40]. In each of the eight cities chosen in this study, seven to ten districts (for urban areas) and villages (for rural areas) were selected, and 40–60 respondents were then recruited in each district/village. Recruitment was conducted in publicly accessible places (parks, shops, streets, or university campuses) and private places (participants' residence). Respondents were also required to meet the following inclusion criteria: (1) aged ≥ 18 years; (2) had Chinese nationality; (3) lived in mainland China during the past 5 years; (4) were literate and had no disease that limited cognitive function, such as dementia; and (5) gave informed consent.
2.4 Data Collection
Data were collected through two-to-one face-to-face computer-assisted personal interviews. The structure of the interview was as follows. First, respondents answered quota and inclusion criteria questions to confirm they were eligible for the interview. Second, respondents recorded their health state on the SF-6Dv2. Third, respondents completed the TTO and DCETTO tasks in the randomized order. Last, respondents provided a series of socio-demographic characteristics. Sound recordings of all interviews were collected with the respondents’ permission.
In each of the eight selected cities, interviews were conducted by a local team from a local university. Each team was led by a local lead investigator and supervised by the principal investigators. A total of 146 interviewers with a bachelor’s degree or higher were involved in this study. The interviewers attended a 2-day training to ensure equivalent task understanding, procedures, and interactions with respondents. Before the beginning of data collection, each interviewer was asked to complete three pilot interviews under the supervision of both the local lead investigator and the principal investigators of this study.
The study protocol was approved by the institutional review board of the School of Pharmaceutical Science and Technology, Tianjin University (no. 20180615). Informed consent was obtained from all respondents included in the study.
2.5 Quality Control
The quality of the collected data was monitored daily by the principal investigators. Interviews were directly excluded if (1) the interview was not completed; (2) respondents were not patient enough to follow the interviewers’ guidance; or (3) interviewers failed to ask the questions or operate the questionnaire system according to the study protocol. Potentially problematic data were also identified, including respondents who gave the same values for all tasks; gave the worst state (555655) a higher value (at least 0.5) than the other states in the TTO exercise [41,42,43,44]; always selected the same options, such as “AAAAA”; or selected “ABABAB” in the DCETTO [19, 43, 44]. Furthermore, we randomly selected 30% of the interview sound recordings for further daily double checking by the principal investigators to ensure the data quality.
2.6 Data Analysis
TTO data were analyzed according to main-effect specification using ordinary least squares (OLS) and Tobit models [2, 33]. The basic equation for the OLS model is as shown in Equation 1.
where \(y_{i}\) represents the disutility value; \(\alpha\) represents the intercept; \(x_{dl}\) represents 25 dummy variables indicating the health state described by SF-6Dv2 dimension \(d\) at level \(l\), except the first level of each dimension (for reference); \(\beta_{dl}\) represents the estimated disutility on dimension \(d\) at level \(l\); and \(\epsilon\) represents the error term. Considering each respondent completed multiple TTO tasks, in addition to the OLS estimator with cluster-robust standard errors, the fixed- and random-effects models were also considered to account for the panel structure in the data.
The Tobit model has a potentially favorable characteristic because observed values were left-censored by the TTO methodology at − 1, whereas latent preferences of respondents might include valuations lower than − 1 for health states WTD (Fig. 4 in the ESM). As shown in Eq. (2), the Tobit model assumes that a latent variable \(y_{i}^{*}\) underlies the observed \(y_{i}\) TTO disutility value and uses a likelihood function to adjust the parameter estimates for the probability of the \(y_{i}^{*}\) value beyond the censored value (i.e., lower than − 1). Detailed information for the Tobit model is described elsewhere [41, 42, 45].
The DCETTO data were analyzed under the random utility framework using both a conditional logit model (which assumes a homogenous preference from the respondents) and a mixed logit model (which allows for potential preference heterogeneity among respondents), following the model specification proposed by Bansback et al. [19] (Eq. 3).
where \(U_{ij}\) represents the binary choice of respondent \(i\) for DCETTO task \(j\); \(t_{ij}\) represents the life duration, which is modeled as a linear, continuous variable; \(\beta\) represents the coefficient for the life duration; \(x_{ij} t_{ij}\) represents the interactions between dimension levels and life duration; \(\lambda\) represents the coefficients for the interactions; and \(\varepsilon_{ij}\) represents the error term, which is assumed to be independently and identically distributed with Gumbel distribution. The mixed-logit model considers preference heterogeneity by estimating both the mean (which represents the average preferences of respondents) and the standard deviation (SD). In this study, a SF-6Dv2 dimension was considered random (with normal distribution) as long as the SD of at least one response level was statistically significant. The DCETTO value for each health state can be anchored on the QALY scale as shown in Eq. (4) [19, 26, 27, 29, 30].
2.7 Model Evaluation
The preferred models for both TTO and DCETTO approaches were selected based on (1) the monotonicity of logical ordering of the model coefficients, meaning that theoretically, the coefficients of more severe levels should have lower values than the coefficients of milder levels within each dimension; (2) the goodness of fit of the model using Akaike information criterion (AIC) and Bayesian information criterion (BIC); and (3) the parsimony of the model, meaning that the most parsimonious model would be selected if two or more models exhibited similar prediction performances. Furthermore, for TTO data, the prediction accuracy could be assessed by comparing predicted and observed mean values for health states valued in the study, using the intraclass correlation coefficient (ICC), the mean absolute difference (MAD), and the mean squared difference (MSD). Lower MAD and MSD and higher ICC values indicated better accuracy. Several interaction terms were also tested based on the preferred model for both TTO and DCETTO, which can be found in Tables 2 and 3 in the ESM. The final model, which would be used to calculate the health utility values and inform policy, requires the monotonicity of model coefficients [30, 46, 47]. The adjacent inconsistent levels in the preferred models were combined in this study to produce a fully consistent model.
2.8 Value Set Comparison
Based on the preferred model specification, after handling the potential issue of monotonicity, the comparison of the characteristics of health utility value sets generated by TTO and DCETTO was evaluated by the descriptive features, including the range of the utility value, the utility distribution of all 18,750 health states in SF-6Dv2, and the number of health states WTD. The consistency between two value sets was also evaluated using ICC, MAD, and MSD values. The degree of agreement between utility values of TTO and DCETTO was assessed using a Bland–Altman plot. The cross-validation method was further used to demonstrate and compare the robustness of model estimation for both approaches. Specifically, data for one of the eight cities were excluded and the data for the remaining seven cities used for model estimation. This process was repeated eight times, in turn excluding data for each of the eight cities. Then, the MAD between coefficients of these fitted models and coefficients of the whole sample model was compared.
All statistical analyses were conducted using STATA 15.1. To compare the distribution of characteristics between subgroups, the t test was used for continuous variables and the χ2 or Fisher’s exact test was used for categorical variables. Differences in distribution of characteristics and model coefficients were considered statistically significant if p < 0.05.
3 Results
3.1 Respondents
A total of 3575 respondents were interviewed from June to September in 2019 (Fig. 3 in the ESM), of which 255 interviews were excluded because the respondents did not complete the whole interview (N = 174) or the interviews did not pass the quality control process (N = 81). Finally, a total of 3320 respondents were included, with geographic distribution as shown in Fig. 2b in the ESM. As illustrated in Table 1, the mean ± SD age of respondents was 44.6 ± 16.1 years (range 18–90); 50.3% were males, and 40.4% lived in rural areas. The characteristics of respondents were close to those of the Chinese general population. The distributions for four quota characteristics were comparable across respondents in eight cities, and various distributions were observed for other characteristics, reflecting the geographical spread and different economic development levels in China (Table 1 in the ESM).
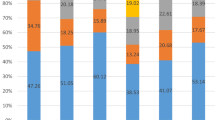
The mean ± SD time spent in the interview was 39.4 ± 17.0 min, and the duration for TTO tasks was significantly longer than for DCETTO tasks (16.2 vs. 12.9 min; p < 0.001). Health problems were most frequently reported in the VT dimension (76.7%) and least frequently in PF (35.9%) (Fig. 1).

Distribution across levels of the SF-6Dv2 dimensions. All dimensions have five levels, except for the pain dimension, which has six levels; higher values represent more severe states
3.2 Data Characteristics
Mean observed TTO values ranged from − 0.243 for state 555655 to 0.885 for state 111112 and ranged from 0.862 to 0.885 for the six mildest imperfect health states. Of 26,560 responses, 5011 (18.9%) were considered WTD. The distribution of observed TTO values for 295 states is presented in Fig. 4 in the ESM. For DCETTO data, as the difference in overall severity between the two states increased, respondents were more likely to choose the state with the lower severity; as expected, several inconsistencies were found because of the additional life duration dimension (Fig. 5 in the ESM).
Nevertheless, potentially problematic answer patterns were observed, including three respondents who gave the same values for all tasks, 51 who gave the worst state a higher value (at least 0.5) than the other states in TTO data, and respondents who always selected the same options (e.g., 20 responded “AAAAA” and 19 responded “ABABAB”) in the DCETTO. These respondents were few, with no noticeable differences in demographic characteristics, and some answers may be due to random errors. Therefore, these respondents were not excluded from this study.
3.3 Model Estimation
The estimated coefficients of the models on TTO data are presented in Table 2. The random-effects model performed better as measured by the criteria mentioned and was selected for the final data analysis for TTO data. Although the mixed logit model performed better in AIC and BIC, the conditional logit model was chosen for DCETTO data given that there were fewer non-monotonic coefficients and that the preference heterogeneity was not substantial (only four dimension levels had statistically significant SDs in the mixed logit model) (Table 3). In these two preferred models, all of the coefficients for TTO were ordered as expected. Level 2 in MH and VT dimensions for DCETTO showed slight non-monotonicity, while the coefficients were not statistically significant. The goodness of fit was slightly improved after combining the inconsistent levels. Most of the coefficients in both TTO and DCETTO models were significantly different from 0 (p < 0.001). All of the interaction terms were excluded in the final models because they resulted in non-monotonicity, varying degrees of impairment of the model estimations, or the parsimony of the model (Tables 2 and 3 in the ESM).
Following the previous study, the linear adjustment to the predicted values of TTO was made using the formula UAdjusted = UPredicted/(1 − intercept) (Table 4) [48]. This additional step was to remove the effect of the non-zero intercept in TTO, which leads to a predicted value of less than 1 for full health (111111).
3.4 Value Set Comparison
As illustrated in Table 4, values in the two approaches were highly consistent (ICC 0.9804, MAD 0.0588, MSD 0.0055). The orders of overall decrement of the dimensions were the same for both approaches, as follows: PN, PF, MH, VT, SF, and RL. The Bland–Altman plot (Fig. 6 in the ESM) also showed that the mean difference of 0.02 was close to zero, the 95% limits of agreement between TTO and DCETTO ranged from − 0.11 to 0.16, and 95.7% of points lay within limits. Although agreement was generally good, we also observed that TTO values tended to be lower than DCETTO values for milder health states and higher than DCETTO values for worse health states. The comparison of the tendency of coefficients between TTO and DCETTO is presented in Fig. 2a, which shows that the coefficients of TTO decreased more smoothly than DCETTO. The estimated utility values for the 18,750 health states for SF-6Dv2 of both approaches, with the benchmark of observed TTO values, are shown in Fig. 2b. A similar trend can be found with the Bland–Altman plot (Fig. 6 in ESM). In total, 927 (4.94%) health states were estimated to be WTD in TTO, which were less than 1593 (8.50%) in DCETTO. The utility values of the worst state 555655 were − 0.277 for TTO and − 0.535 for DCETTO. The cross-validation results showed that excluding the data from one of the eight cities had only trivial effects on the coefficients for both TTO (less than 0.003) and DCETTO (less than 0.002) (Tables 4 and 5 in the ESM).

Comparison of the value sets generated by TTO and DCETTO. a Comparison of the tendency of coefficients between TTO and DCETTO. b Estimated utility values for the 18,750 health states for the SF-6Dv2 based on the TTO and DCETTO data, with the benchmark of observed TTO values (ordered by the TTO observed values). TTO time trade-off, DCETTO discrete-choice experiment with a duration dimension
The value set generated by the random-effects model of TTO data after adjusting the intercept (Table 4) was preferred over that generated by the conditional logit model of DCETTO data, based on its performance concerning the monotonicity and statistical significance of the coefficients. In applying this preferred model as the value set of SF-6Dv2 in China, a health state utility value was obtained by subtracting coefficients for each dimension level of the health state from 1. For example, for the health state 232154, the utility value would be 1 − (0.038 + 0.059 + 0.047 + 0 + 0.134 + 0.108) = 0.614.
4 Discussion
This study collected TTO and DCETTO responses via face-to-face interviews with 3320 respondents who were representative of the general population of China in terms of age, sex, education, and proportion of urban/rural population. All of these response data were modeled to estimate utility values for all health states in the SF-6Dv2. This study presents the first empirical evidence of the systematic difference between these two approaches that directly compared value sets of the SF-6Dv2 generated by TTO and DCETTO approaches. Value sets for the EQ-5D-3L and the EQ-5D-5L have already been developed for China [48,49,50], and this study reports a Chinese-specific value set for the SF-6Dv2 that can be used for economic evaluations. Furthermore, as the first to generate a value set for the SF-6Dv2 in Asia, this study facilitates cross-country comparisons, which could provide further information on the health preference differences between eastern and western populations.
Both TTO and DCETTO approaches were feasible for eliciting health state utility values, and the orders of overall decrement of the dimensions were the same for both approaches. There were some (statistically insignificant) inconsistent coefficients in the DCETTO model and, following previous literature, the adjacent inconsistent levels were combined when developing value sets. It should be noted that this issue is not unique to this study and has been found in several previous valuation studies using DCE or DCETTO [12, 24, 28,29,30,31, 43]. Non-monotonicity of the coefficients can be caused by many factors, including respondents’ characteristics, instruments used to describe health states, health states selected for valuation, and the model chosen to estimate the data. It has also been reported in studies conducted in different countries, among respondents with different characteristics and cultural backgrounds [12, 24, 28, 31, 43]; using different instruments [12, 24, 29, 30]; estimating data based on different models [12, 29, 30]; or even using different health states [12, 31]. Further research exploring the issue of inconsistent coefficients in DCE approaches is encouraged.
Although the value set generated by TTO data was favored over that generated by DCETTO data given the monotonicity and statistical significance of the coefficients, DCETTO did generate sensible results. The utility values generated by DCETTO were generally lower than those provided by TTO, which is consistent with previous studies [19, 26]. When compared with the UK value set for the SF-6Dv2, the range of values was similar, despite the different health states and experimental designs used for the DCETTO approach [12]. Specifically, the range of values was from 1 (111111) to − 0.535 (555655) for China and from 1 (111111) to − 0.574 (555655) for the UK, with the UK value set producing a slightly lower value [12]. The number of health states WTD was 1593 (8.50%) for China and 2850 (15.2%) for the UK [12]. The PN dimension had the largest decrement, and RL had the smallest, for both the China and the UK value sets; nevertheless, the order of the other dimensions was not identical. Further studies are warranted to compare the TTO and DCETTO value sets to provide more evidence when using DCETTO as a promising alternative to TTO, based on previous discussions [19, 31].
The value set generated by the TTO data was preferred in this study, even though statistically significant non-zero intercepts were observed. This was mainly because respondents gave low values for the very mild health state. This finding also existed in the Chinese EQ-5D-5L valuation study, which had an intercept of 0.121 [48]. Therefore, this issue may be related to the health preferences of the Chinese population, which tend to give very mild states a lower value. A significant intercept would favor and could result in overinvestment in treatments for very mild health problems. Therefore, following the Chinese EQ-5D-5L valuation study [48], a linear adjustment to all model coefficients was applied in this study in terms of using the SF-6Dv2 value set to better inform healthcare decision making.
This study also found that the decrement of the PN and the PF dimensions were the largest, indicating that the Chinese general population gave more weight to these two dimensions than other dimensions in SF-6Dv2. This is consistent with SF-6Dv1 value sets for Hong Kong China and Japan, which had the largest decrement for the same two dimensions [51, 52]. Similarly, in both Chinese EQ-5D-3L (2014) and EQ-5D-5L value sets, the decrement for pain/discomfort and mobility dimensions was the largest [48, 50] similar to the EQ-5D-5L value sets for South Korea, Malaysia, and Thailand [53,54,55]. However, in the Chinese EQ-5D-3L (2018) value set [49], the decrement for the self-care dimension was the largest, and pain/discomfort was the smallest, which differed from these studies. This inconsistency may be partly because of the different TTO task design used to generate the Chinese EQ-5D-3L (2018) value set [49]. In western countries, such as the USA, the UK, Germany, and the Netherlands, the decrements in the PN and MH dimensions in the SF-6Dv1 [56, 57] and in the pain/discomfort and anxiety/depression dimensions in the EQ-5D-5L [41, 45, 58], were the largest. Although different measures were used in these studies, the similarities in the health state classification system provided good comparability. Populations of both eastern and western countries may give similarly large preferences for PN. In contrast, populations of eastern countries may give more weight to PF, while those of western countries may have more preference for MH. The similarities and distinctions in the ranking of the dimensions reflect cultural and socioeconomic factors, which are essential to shaping the preferences of populations. Further investigation is needed to explore and compare the impact on the results of economic evaluations by using the newly established SF-6Dv2 value set in this study and the existing Chinese EQ-5D value sets as mentioned.
A particular strength of this study is its sample size, which was larger than most of the other valuation studies [59,60,61,62] and helped to reduce the standard errors of model coefficients (no larger than 0.01 in this study). Besides, given the large proportion of rural residents in China, an important factor that may affect health preferences [49, 63, 64], a specific quota of the urban and rural proportion of the Chinese general population was employed for the first time in this study. This improved the representativeness of the study sample and provided a more reliable health utility value set to reflect the health preferences of the Chinese population.
Several limitations of this study need to be noted. First, 146 interviewers involved in this study had the same extensive training but came from different backgrounds and used different communication skills when conducting the interviews. Although the cross-validation results showed that excluding the data from one of the eight cities had only trivial effects on the model estimation, there may be some unobservable effects [65]. Second, to achieve the maximum statistical efficiency of modeling, implausible health states in SF-6Dv2 were not excluded in the experimental design for both TTO and DCETTO. Asking respondents to consider implausible health states was likely to have had an impact on the quality of their responses and may have affected the model estimation results. There was also a lack of agreement among respondents on which states were implausible [66]. Furthermore, the order of the eight tasks in each TTO block was not completely random. The mildest state and the worst state were always the seventh and eighth states, respectively, because of the technical limitations during production of the survey. This could have had some minor impacts on the estimates.
5 Conclusions
The Chinese value set for the SF-6Dv2 was established based on the TTO approach, and both TTO and DCETTO approaches performed well when eliciting health state utility values in China. Minor issues of nonmonotonicity did present for DCETTO.
References
Zhao R, Zhao K. Health technology assessment takes the road of development with Chinese characteristics. China Health. 2019;10:76–8.
Brazier J, Ratcliffe J, Saloman J, Tsuchiya A. Measuring and valuing health benefits for economic evaluation. Oxford: Oxford University Press; 2017.
Neumann PJ, Sanders GD, Russell LB, Siegel JE, Ganiats TG. Cost-effectiveness in health and medicine. 2nd ed. New York: Oxford University Press; 2016.
Rascati K. Essentials of pharmacoeconomics. Philadelphia: Commonwealth of Pennsylvania, Lippincott Williams & Wilkins; 2013.
The EuroQol Group. EuroQol—a new facility for the measurement of health-related quality of life. Health Policy. 1990;16(3):199–208. https://doi.org/10.1016/0168-8510(90)90421-9.
Brazier J, Usherwood T, Harper R, et al. Deriving a preference-based single index from the UK SF-36 Health Survey. J Clin Epidemiol. 1998;51:1115–28.
Liu GG, Hu S, Wu JH, Wu J, Dong C, Li H. China guidelines for pharmacoeconomic evaluations (2020). Beijing, China: China Market Press; 2020.
Poder TG, Fauteux V, He J, et al. Consistency between three different ways of administering the short form 6 dimension version 2. Value Health. 2019;22:837–42.
Liu X, Li S, Chen G. Development of the short form health survey and introduction of short form 6-dimension (SF-6D). Chin Health Econ. 2019;38(02):8–11.
Brazier J, Mulhern BJ, Bjorner JB, et al. Developing a new version of the SF-6D health state classification system from the SF-36v2: SF-6Dv2. Med Care. 2020;58:557–65.
Wu J, Xie S, He X, et al. The simplified Chinese version of SF-6Dv2: translation, cross-cultural adaptation and preliminary psychometric testing. Qual Life Res. 2020;29:1385–91.
Mulhern BJ, Bansback N, Norman R, et al. Valuing the SF-6Dv2 classification system in the United Kingdom using a discrete-choice experiment with duration. Med Care. 2020;58:566–73.
Martin AJ, Glasziou PP, Simes RJ, et al. A comparison of standard gamble, time trade-off, and adjusted time trade-off scores. Int J Technol Assess Health Care. 2000;16:137–47.
Morimoto T, Fukui T. Utilities measured by rating scale, time trade-off, and standard gamble: review and reference for health care professionals. J Epidemiol. 2002;12:160–78.
Craig BM, Busschbach JJ, Salomon JA. Keep it simple: ranking health states yields values similar to cardinal measurement approaches. J Clin Epidemiol. 2009;62(3):296–305.
Craig BM, Busschbach JJ. The episodic random utility model unifies time trade-off and discrete choice approaches in health state valuation. Popul Health Metrics. 2009;7:3.
Lancsar E, Louviere J. Conducting discrete choice experiments to inform healthcare decision making: a user’s guide. Pharmacoeconomics. 2008;26:661–77.
Stolk EA, Oppe M, Scalone L, et al. Discrete choice modeling for the quantification of health states: the case of the EQ-5D. Value Health. 2010;13:1005–13.
Bansback N, Brazier J, Tsuchiya A, et al. Using a discrete choice experiment to estimate health state utility values. J Health Econ. 2012;31:306–18.
Salomon JA. Reconsidering the use of rankings in the valuation of health states: a model for estimating cardinal values from ordinal data. Popul Health Metrics. 2003;1:12.
McCabe C, Brazier J, Gilks P, et al. Using rank data to estimate health state utility models. J Health Econ. 2006;25:418–31.
Ratcliffe J, Brazier J, Tsuchiya A, et al. Using DCE and ranking data to estimate cardinal values for health states for deriving a preference-based single index from the sexual quality of life questionnaire. Health Econ. 2009;18:1261–76.
Brazier J, Rowen D, Yang Y, et al. Comparison of health state utility values derived using time trade-off, rank and discrete choice data anchored on the full health-dead scale. Eur J Health Econ. 2012;13:575–87.
Norman R, Cronin P, Viney R. A pilot discrete choice experiment to explore preferences for EQ-5D-5L health states. Appl Health Econ Health Policy. 2013;11:287–98.
Mulhern B, Bansback N, Brazier J, et al. Preparatory study for the revaluation of the EQ-5D tariff: methodology report. Health Technol Assess (Winchester, England). 2014;18:1–191 (vii-xxvi).
Norman R, Viney R, Brazier J, et al. Valuing SF-6D health states using a discrete choice experiment. Med Decis Making. 2014;34:773–86.
Viney R, Norman R, Brazier J, et al. An Australian discrete choice experiment to value EQ-5D health states. Health Econ. 2014;23:729–42.
Mulhern B, Bansback N, Hole AR, et al. Using discrete choice experiments with duration to model EQ-5D-5L health state preferences: testing experimental design strategies. Med Decis Mak. 2017;37(3):285–97.
King MT, Viney R, Simon Pickard A, et al. Australian Utility Weights for the EORTC QLU-C10D, a multi-attribute utility instrument derived from the cancer-specific quality of life questionnaire, EORTC QLQ-C30. Pharmacoeconomics. 2018;36:225–38.
Rowen D, Mulhern B, Stevens K, et al. Estimating a Dutch value set for the pediatric preference-based CHU9D using a discrete choice experiment with duration. Value Health. 2018;21:1234–42.
Xie S, Wu J, He X, et al. Do discrete choice experiments approaches perform better than time trade-off in eliciting health state utilities? Evidence from SF6Dv2 in China. Value Health. 2020;23:1391–9.
Janssen BM, Oppe M, Versteegh MM, et al. Introducing the composite time trade-off: a test of feasibility and face validity. Eur J Health Econ. 2013;14(Suppl 1):S5-13.
Oppe M, Rand-Hendriksen K, Shah K, et al. EuroQol protocols for time trade-off valuation of health outcomes. Pharmacoeconomics. 2016;34:993–1004.
Oppe M, Devlin NJ, van Hout B, et al. A program of methodological research to arrive at the new international EQ-5D-5L valuation protocol. Value Health. 2014;17:445–53.
Burgess L, Street DJ, Wasi N. Comparing designs for choice experiments: a case study. J Stat Theory Pract. 2011;5:25–46.
Chrzan K, Orme B. An overview and comparison of design strategies for choice-based conjoint analysis. Sawtooth software research paper series. 2000; 98382.
Johnson FR, Lancsar E, Marshall D, et al. Constructing experimental designs for discrete-choice experiments: report of the ISPOR conjoint analysis experimental design good research practices task force. Value Health. 2013;16:3–13.
Marshall DA, Deal K, Bombard Y, et al. How do women trade-off benefits and risks in chemotherapy treatment decisions based on gene expression profiling for early-stage breast cancer? A discrete choice experiment. BMJ Open. 2016;6:e010981.
National Bureau of Statistics of China. China Sixth National Census. 2010. http://stats.tj.gov.cn/nianjian/2017nj/zk/indexch.htm. Accessed 25 Sept 2020.
National Bureau of Statistics of China. China Statistical Yearbook. 2018. http://www.stats.gov.cn/tjsj/ndsj/2018/indexch.htm. Accessed 25 Sept 2020.
Ludwig K, von der Schulenburg JMG, Greiner W. German value set for the EQ-5D-5L. Pharmacoeconomics. 2018;36:663–74.
Pickard AS, Law EH, Jiang R, et al. United States valuation of EQ-5D-5L health states using an international protocol. Value Health. 2019;22:931–41.
Purba FD, Hunfeld JAM, Iskandarsyah A, et al. The Indonesian EQ-5D-5L value set. PharmacoEconomics. 2017;35:1153–65.
Ramos-Goni JM, Oppe M, Slaap B, et al. Quality control process for EQ-5D-5L valuation studies. Value Health. 2017;20:466–73.
Versteegh MM, Vermeulen KM, Evers SMAA, et al. Dutch Tariff for the Five-Level Version of EQ-5D. Value Health. 2016;19:343–52.
Brazier J, Roberts J. The estimation of a preference-based measure of health from the SF-12. Med Care. 2004;42:851–9.
Mukuria C, Rowen D, Brazier J, et al. Deriving a preference-based measure for myelofibrosis from the EORTC QLQ-C30 and the MF-SAF. Value Health. 2015;18:846–55.
Luo N, Liu G, Li M, et al. Estimating an EQ-5D-5L value set for China. Value Health. 2017;20:662–9.
Zhuo L, Xu L, Ye J, et al. Time trade-off value set for EQ-5D-3L based on a nationally representative Chinese Population Survey. Value Health. 2018;21(11):1330–7.
Liu GG, Wu H, Li M, et al. Chinese time trade-off values for EQ-5D health states. Value Health. 2014;17:597–604.
Lam CL, Brazier J, McGhee SM. Valuation of the SF-6D health states is feasible, acceptable, reliable, and valid in a Chinese population. Value Health. 2008;11:295–303.
Brazier J, Fukuhara S, Roberts J, et al. Estimating a preference-based index from the Japanese SF-36. J Clin Epidemiol. 2009;62:1323–31.
Kim SH, Ahn J, Ock M, et al. The EQ-5D-5L valuation study in Korea. Qual Life Res. 2016;25:1845–52.
Shafie AA, Vasan Thakumar A, Lim CJ, et al. EQ-5D-5L valuation for the Malaysian population. Pharmacoeconomics. 2019;37:715–25.
Pattanaphesaj J, Thavorncharoensap M, Ramos-Goñi JM, et al. The EQ-5D-5L Valuation study in Thailand. Expert Rev Pharmacoecon Outcomes Res. 2018;18:551–8.
Craig BM, Pickard AS, Stolk E, et al. US valuation of the SF-6D. Med Decis Mak. 2013;33:793–803.
Brazier J, Roberts J, Deverill M. The estimation of a preference-based measure of health from the SF-36. J Health Econ. 2002;21:271–92.
Devlin NJ, Shah KK, Feng Y, et al. Valuing health-related quality of life: An EQ-5D-5L value set for England. Health Econ. 2018;27:7–22.
Wang P, Liu GG, Jo MW, et al. Valuation of EQ-5D-5L health states: a comparison of seven Asian populations. Expert Rev Pharmacoecon Outcomes Res. 2019;19:445–51.
Mulhern B, Norman R, Street DJ, et al. One method, many methodological choices: a structured review of discrete-choice experiments for health state valuation. Pharmacoeconomics. 2019;37:29–43.
Zhou T, Guan H, Yao J, et al. The quality of life in Chinese population with chronic non-communicable diseases according to EQ-5D-3L: a systematic review. Qual Life Res. 2018;27(11):2799–814.
Xie F, Gaebel K, Perampaladas K, et al. Comparing EQ-5D valuation studies: a systematic review and methodological reporting checklist. Med Decis Mak. 2014;34:8–20.
Zhou Z, Zhou Z, Gao J, et al. Urban-rural difference in the associations between living arrangements and the health-related quality of life (HRQOL) of the elderly in China-evidence from Shaanxi province. PLoS One. 2018;13(9):e0204118.
Chen Y, Sun G, Guo X, et al. Factors affecting the quality of life among Chinese rural general residents: a cross-sectional study. Public Health. 2017;146:140–7.
Yang Z, van Busschbach J, Timman R, et al. Logical inconsistencies in time trade-off valuation of EQ-5D-5L health states: whose fault is it? PLoS One. 2017;12(9):e0184883.
Yang Z, Feng Z, Busschbach J, et al. How prevalent are implausible EQ-5D-5L health states and how do they affect valuation? A study combining quantitative and qualitative evidence. Value Health. 2019;22(7):829–36.
Acknowledgements
The authors thank Dr. Zhihao Yang, Dr. Keren Zhang, Dr. Hong Zhu, Dr. Yunfang Jiang, Jie Tian, Mengqian Zhang, Jiahui Zhang, Pinan Chen, Nan Fang, Lili Chen, Meng Lv, Jia Wang, Li Zhou, Zhuoru Liang and Yunyu Li, for the excellent quality control work during this study. We also thank all of the interviewers and respondents for taking part in this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
This study was funded by the National Natural Science Foundation of China (Grant no. 71673197 and no. 71804122) and the Science and Technology Program of Guangzhou, China (Grant no. 201704020198).
Conflict of interest
JW and XH reported receiving grants from the National Natural Science Foundation of China during the conduct of the study. JJ reported receiving grants from the Science and Technology Program of Guangzhou, China during the conduct of the study. JB is one of the developers and holds the patent for SF-6D with royalties paid to the University of Sheffield. SX, GC, GB, DF, MH, XW, HW, and QW have no conflicts of interest that are directly relevant to the content of this article.
Ethics approval
This study was approved by the Institutional Review Board of School of Pharmaceutical Science and Technology, Tianjin University (No. 20180615) and was conducted in accordance with the Declaration of Helsinki.
Consent to participate
Informed consent was obtained from all individual participants included in the study. Participants were informed about their freedom of refusal. Anonymity and confidentiality were maintained throughout the research process.
Consent for publication
Informed consent for publication was obtained from all individual participants. Participants were informed about their freedom of refusal for data publication. Anonymity and confidentiality were maintained in this publication.
Availability of data and material
The predicted values of the 18,750 health states, together with standard errors and 95% confidence intervals, are available from the corresponding author on reasonable request.
Code availability
Not applicable.
Author Contributions
Concept and design: JW, SX, XH, GC, and JB. Acquisition of data: SX, GB, DF, MH, JJ, XW, HW, and QW. Analysis and interpretation of data: JW, SX, XH, GC, and JB. Drafting of the manuscript: JW, SX, and GC. Statistical analysis: SX and GC. Obtaining funding: JW, XH, and JJ. Supervision: JW, JB. All authors commented on previous versions of the manuscript and approved the final manuscript.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Wu, J., Xie, S., He, X. et al. Valuation of SF-6Dv2 Health States in China Using Time Trade-off and Discrete-Choice Experiment with a Duration Dimension. PharmacoEconomics 39, 521–535 (2021). https://doi.org/10.1007/s40273-020-00997-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40273-020-00997-1