
Abstract
In order to determine how participants represent practiced, discrete keying sequences in the discrete sequence production task, we had 24 participants practice two six-key sequences on the basis of two pre-learned six-digit numbers. These sequences were carried out by fingers of the left (L) and right (R) hand with between-hand transitions always occurring between the second and third, and the fifth and sixth responses. This yielded the so-called LLRRRL and RRLLLR sequences. Early and late in practice, the keypad used for the right hand was briefly relocated from the front of the participants to 90° at their right side. The results indicate that after 600 practice trials, executing a keying sequence relies heavily on a spatial cross-hand representation in a trunk- or head-based reference frame that after about only 15 trials is fully adjusted to the changed hand location. The hand location effect was not found with the last sequence element. This is attributed to the application of explicit knowledge. The between-hand transitions appeared to induce initial segmentation in some of the participants, but this did not consolidate into a concatenation point of successive motor chunks.
Similar content being viewed by others


Introduction
A large number of studies has been devoted to understanding how humans automate movement sequences like writing one’s signature and shifting gears when driving an automobile (for recent reviews, see, e.g., Abrahamse et al. 2010, 2013; Heuer and Massen 2013; Keele et al. 2003; Shea and Kovacs 2013; Verwey et al. 2015). Automating movement sequences allow individuals to devote most of their processing resources to concurrent tasks and/or prepare for upcoming behavior while they are executing a familiar movement pattern. To study the human capacity to automate movement sequences, researchers have developed various laboratory tasks that allow them to distinguish the various cognitive processes and representations underlying skilled movement execution. These tasks include, among others, sequential aiming tasks like the flexion–extension (FE) task (Panzer et al. 2006) and sequential key pressing tasks like the serial reaction time (RT) task (Nissen and Bullemer 1987) and the presently used discrete sequence production (DSP) task (Abrahamse et al. 2013; Verwey 1999). Research with tasks like these have made a strong case that sequential motor learning involves the simultaneous development and use of various task- and practice-dependent representations (Berniker et al. 2014; Keele et al. 1995; Panzer et al. 2014; Proteau and Carnahan 2001; Shea and Kovacs 2013; Shea et al. 2011; Verwey et al. 2015; Wiestler et al. 2014). Representing movement sequences in such a redundant way allows human motor control to be flexibly adjusted to changes in the environment and the effectors being used, as well as deal with the detrimental effects on serial behavior of aging and neural damage.
In the laboratory, movement order in sequence learning tasks is usually guided by a series of stimuli, each indicating an element of the sequence. Consequently, sequences in these tasks are initially produced in the reaction mode (Abrahamse et al. 2013; Hikosaka et al. 1999; Park and Shea 2005; Verwey 2003). As the movement sequence is repeated, regularities in the order of the movements—and the associated stimuli—are gradually learned at all levels of information processing (Abrahamse et al. 2010; Verwey et al. 2015). With limited practice, participants still need external guidance to produce the sequence, but the successive processes and movements are already primed using the associative mode (Verwey and Abrahamse 2012; also see Ruitenberg et al. 2014; Verwey and Wright 2014). The associative mode is assumed to be responsible for the skill that develops in the serial RT task.
When movement sequences are limited to about 5–8 elements, as is typically the case for the DSP task (Abrahamse et al. 2013), they can be planned before being executed. This allows strategies to develop and use effective representations (Henry and Rogers 1960; Sternberg et al. 1978; Verwey 1996). Consequently, with further practice, the need for perceptual and central processing resources to translate individual stimuli (S) into responses (Rs) reduces because sequence-specific representations develop that are called motor chunks, and that rely on R–R associations. These motor chunks allow sequence execution to occur without external guidance in the so-called chunking mode (Abrahamse et al. 2013; Verwey and Abrahamse 2012). Like memory chunks in general (Halford et al. 1998; Miller 1956; Newell and Rosenbloom 1981), motor chunks help bypass limitations in information processing so that short movement series can be selected, prepared, and executed as if they constitute a single response (Verwey 1999). While the motor chunk construct is generally accepted, it is defined by its behavioral properties, and despite its name, it remains unclear as to how motor chunks code the individual movements of the DSP task (Verwey 2015). This is the central issue in the present paper.
Sequence representations
The recently proposed cognitive framework for sequential motor behavior (C-SMB; Verwey et al. 2015) postulates that the repeated execution of movement sequences induces the development of a number of different representations some of which may underlie motor chunks. In keeping with the general notion that with practice perceptual motor skills become increasingly task-specific (Ackerman 1988; Fleishman and Hempel 1955; Newell and Rosenbloom 1981; Proteau et al. 1992), C-SMB assumes that, first, S-R associations develop that allow a central processor to perform in the reaction mode. With limited practice, central-symbolic (e.g., spatial and/or verbal) representations develop that can be parsed by the central processor in a cognitive loop. Central-symbolic representations may involve various ways of coding the sequence, such as a visual–spatial image of the required actions (relying on episodic memory), the numbers of one’s PIN (using verbal memory), and/or a spatial representation of successive target locations (spatial memory). This type of knowledge can probably be verbally expressed and is assumed to contribute heavily to what has been called explicit sequence knowledge. Given the abstract level of this knowledge, it is independent of the effector system being used.
Spatial representations of the successive movements are assumed to develop more slowly than the verbal representations that are stored in episodic memory (Shea et al. 2011; Witt et al. 2008). However, during sequence execution, these spatial representations require less cognitive processing than verbal descriptions because spatial representations provide information that can directly be used for planning each individual movement. Inspired by findings with single-cell recordings, behavioral research has explored the nature of these spatial representations in various tasks. That research confirmed neurophysiological indications for a variety of spatial reference frames in which movements can be coded (Flanders and Soechting 1995; Shea et al. 2011; Wiestler et al. 2014). That is, the spatial coordinates of individual movement endpoints may be relative to objects in the person’s environment (they are then coded in an allocentric reference frame), but also relative to body parts like the eye, head, shoulder, trunk, forearm, and hand (i.e., involving egocentric reference frames, Bernier and Grafton 2010; Colby and Goldberg 1999; Gentilucci et al. 1996; Krakauer et al. 1999; Obhi and Goodale 2005; Shea et al. 2011; Zacks 2008).
Allocentric representations have been argued to support strategic, goal-oriented processes that are effector independent. Egocentric reference frames are important for executing motor sequences (Willingham 1998), may include effector-dependent and effector-independent components (Wiestler et al. 2014), and are associated with other brain networks than allocentric representations (Zacks 2008). It is generally believed now that sequential motor tasks involve the simultaneous use of spatial representations with varying reference frames (Keulen et al. 2002; Leoné et al. 2015; McIntyre et al. 1998). Activating a particular movement goal and action plan would automatically activate the spatial representations needed for executing a sequencing task (Jeannerod 1997). The contributions of the various reference frames can probably also be modulated intentionally (Abrams and Landgraf 1990; Proctor et al. 2004), which might be useful when the movement sequence is carried out in different spatial contexts. Neurophysiological measurements indicate that various brain regions can host different reference frames simultaneously. Also, one reference frame can be replaced by another within less than about 100 ms (Derdikman and Moser 2010; Zacks 2008), which may be associated with the ability to rotate spatial representations (Georgopoulos et al. 1986; Leoné et al. 2015; Pellizzer et al. 2009; Petit et al. 2003; Shepard and Metzler 1971).
According to C-SMB, extensive practice of a sequential motor task would introduce the use of motor representations that are carried out by the motor processor. This type of representation is called motoric because it would entail activation patterns of agonist/antagonist muscles (Shea et al. 2011), musculoskeletal forces and dynamics (Krakauer et al. 1999), joint angles (Criscimagna-Hemminger et al. 2003), posture-related representations (Rosenbaum et al. 2009; Rosenbaum et al. 1999), and/or the orientation of body segments relative to each other (Lange et al. 2004). Despite the varying terminology, these notions all suggest that a sequence representation is developed in terms of muscles or muscle groups (cf. Keele 1968). Due to their motoric coding, these representations require little processing to execute a sequence and allow rapid sequence execution by the motor processor without relying very much on the central processor (Verwey et al. 2015). These motor representations are not accessible to processes involved in awareness, that is, motor representations are implicit (though people may still have independent explicit knowledge too, Jeannerod 1997).
There now seems some consensus that the various representations underlying motor sequencing skill develop at different processing levels and that each representation can contribute to the execution of individual movements. Even central-symbolic codes—like verbal ones—and reacting to guiding stimuli are believed to contribute to the execution of highly practiced motor sequences (Keisler and Shadmehr 2010; Kovacs et al. 2009; Stanley and Krakauer 2013; Verwey 1999). In DSP sequences, these central-symbolic representations may speed up especially those sequence elements that are executed more slowly (Verwey 2015). Furthermore, due to primacy and recency effects in memory (Bonanni et al. 2007; Johnson 1991), the speedup by explicit knowledge can be expected especially for the elements at the sequence start and end. Using Monte Carlo simulations, Verwey (2003) showed that simultaneous activity of independent parallel processing systems—each potentially using another representation—increases execution rate as long as there is an overlap in the distributions of the times it takes each system to trigger a response. A racing processor mechanism appears to be a general feature of information processing as it underlies also models of simple RT, response selection, and the processing of redundant signals (Cho and Proctor 2002; Logan 1988; Logan et al. 2014; Miller and Ulrich 2003; Nicoletti et al. 1984; Proctor and Reeve 1988; Ulrich and Miller 1997). Behavioral support for the idea that executing familiar movement sequences involves a race between (processors using) different representations comes from the finding that individual participants had two or three peaks in their RT distribution when they changed from the reaction to the chunking mode (Verwey 2003). This suggests that for some trials, the fastest of several different representations was not applied, and a less efficient one was used to trigger the appropriate sequence element.
The conclusion in behavioral studies that a motor representation developed is usually based on the slowing that is observed when a highly practiced sequence is executed with another effector (e.g., Andresen and Marsolek 2012; Park and Shea 2005; Verwey and Clegg 2005; Verwey and Wright 2004). Such a motor representation should make execution skill independent of the location in which the effector is being used. However, location-independent sequence execution contrasts with the idea that practice makes perceptuomotor skills increasingly task (and thus location) specific (Ackerman 1988; Fleishman and Hempel 1955; Proteau et al. 1992). In this context, it is interesting that De Kleine and Verwey (2009) found that the speed advantage of the practiced over the unpracticed hand in a DSP task reduced when the practiced hand was located on the other side of the participants’ body. This suggests that the advantage of the practiced over the unpracticed hand cannot always be attributed to a motor (muscle-specific) representation and may instead involve a spatial representation that is both effector specific and sensitive to the location of the hand.
The main goal of the present study was to examine bimanual keying sequences in the DSP task to determine the representations underlying sequencing skill earlier and later in practice. To that end, participants practiced a discrete keying sequence with fingers of both hands while the hands were in the normal adjacent position in front of the body. They then relocated the right hand to the side while the left hand remained in its usual location in front of the trunk (like a 1970s or 1980s musician playing on two keyboards at the same time). According to what will be referred to as the applicability hypothesis, participants switch off inappropriate representations when their hand is in a novel location. When in that situation, the most applicable representations are hand-based (i.e., muscle-oriented and/or with a hand-based reference frame), and execution rate will suffer little. An alternative account is called the adjustment hypothesis. It assumes that with practice, execution is based on highly task-specific sequence representations that can be fine-tuned for a particular task. So, rather than switching off inappropriate representations, representations are adjusted to accommodate a changed hand location, for example, by rotating a spatial representation of the sequence (Shepard and Metzler 1971).
Chunk boundaries
Another issue in the present study concerns many indications that movement sequences exceeding about 3–5 elements include multiple motor chunks (Acuna et al. 2014; Bo and Seidler 2009; Kornbrot 1989; Kovacs et al. 2009; Verwey and Eikelboom 2003; Wymbs et al. 2012). The prime indicator that a motor chunk is used consists of a relatively slow response followed by several relatively fast responses (Bo et al. 2009; Bo and Seidler 2009; Kennerley et al. 2004; Ruitenberg et al. 2013; Ruitenberg et al. 2015; for a test of various indicators of motor chunks, see Verwey 2001). The estimate of 3–5 elements per motor chunk in discrete keying sequences is remarkably similar to the chunk size for verbal and visuospatial knowledge of 3–4 in working memory (Anderson 2014; Broadbent 1975; Cowan 2000; Logie and Cowan 2015). One could therefore hypothesize that the initial segmentationFootnote 1 of a longer sequence is determined by working-memory capacity and that practice then consolidates these segments into successive motor chunks. Support for this hypothesis comes from studies showing correlations between individual visuospatial working-memory capacity and motor chunk length (Bo et al. 2009; Bo and Seidler 2009; Seidler et al. 2012). While the number of elements per motor chunk does indeed seem to be a prime determinant of where these transitions occur (Abrahamse et al. 2013), other sequence properties may influence the sequential position of this so-called concatenation point. Those properties include regularities in the order of the elements (like 123123, De Kleine and Verwey 2009; Jones 1981; Koch and Hoffmann 2000; Kornbrot 1989; Sakai et al. 2003; Verwey and Eikelboom 2003), the use of random versus blocked practice schedules (Wilde et al. 2005), and the occurrence of a pause at a particular sequential position during practice (Stadler 1993; Verwey 1996; Verwey et al. 2009; Verwey and Dronkert 1996).
The occurrence in the present study of between-hand transitions at two fixed sequential positions allowed us to examine the suggestion by Verwey and Eikelboom (2003) that such transitions might in unfamiliar sequences determine segmentation, which then consolidates with practice into the more robust motor chunks. This idea received some support from the finding with unfamiliar keying sequences that six of the eight observed slow elements in a DSP sequence were associated with a between-hand transition (Verwey et al. 2009). A lasting effect of between-hand transitions in DSP sequences would be consistent with the development of hand-specific sequence representations in the serial RT task (Berner and Hoffmann 2008, 2009) and with indications that fingers of one hand can be prepared by a neural system (a network including the basal ganglia), which differs from the one used for two hands (Adam et al. 2003). The question whether between-hand transitions contribute to dividing a keying sequence into different segments in early practice, that may consolidate with practice into the more robust motor chunks, has not been addressed in earlier DSP studies because those studies involved sequence elements being balanced across fingers of different participants, so that between-hand transitions were distributed across all sequential positions.
The present experiment
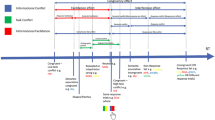
The applicability and the adjustment hypotheses were tested by having participants first practice two six-element DSP sequences with both hands in the typical adjacent frontal location and then examining the effect on the individual sequence elements of relocating the right hand to the side. This was done after approximately 100 and 600 practice trials per sequence. The applicability hypothesis predicts that all sequence elements are slowed when one hand has been relocated because one or more sequence representations are no longer used. This slowing should not change significantly during a test block because new sequence representations do not develop very fast. In contrast, the adjustment hypothesis predicts that the slowing caused by relocating one hand to the side may last for just a few trials because participants quickly learn to apply a transformation to the representations used (like when rotating a spatial representation). This slowing should occur before the first of the responses given by a particular hand because (the representations making up) motor chunks are adjusted before they can be used. Because practice execution is based on fewer, more sequence-specific, representations (Ackerman 1988; Fleishman and Hempel 1955; Newell and Rosenbloom 1981; Proteau et al. 1992), indications for such an adjustment of representations are expected to be stronger in Block 9 than in Block 2. We also assessed awareness of the sequences to determine whether explicit sequence knowledge may contribute to sequence execution. In discrete keying sequence, this may concern especially the second and last responses (i.e., R2 and R6, Verwey 2015). Finally, we addressed in the conditions in which the right hand was in the front, whether the between-hand transitions might influence the segmentation of each sequence in early practice, and whether this would consolidate with practice when motor chunks develop.
Method
Participants
Twenty-four students (16 female, M age = 21 years, SD = 2.0 years) from the University of Twente took part in this study in exchange for course credit. All participants were self-proclaimed right-handed students. Informed consent was obtained from all individual participants included in the study. The study had been approved by the Ethics Committee of the University of Twente and was performed in accordance with the ethical standards described in the Declaration of Helsinki.
Apparatus
The experiment was programmed and conducted in E-Prime 2.0 on a 2.8 GHz Pentium 4 PC with 512 MB RAM running under Windows XP. Key-specific stimuli consisted of eight squares that subtended a visual angle of approximately 1°. They were presented on a 15″ Philips 107T5 CRT display at a refresh rate of 75 Hz, with a resolution of 640 × 480 pixels, and at 16-bit color depth.
Directly in front of the participant were two Trust USB numeric keypads, embedded near each other in a black wooden mold (see Fig. 1). In this frontal location, the left keypad was itself rotated 90° counterclockwise, the one on the right 90° clockwise. This allowed participants to place their left hand’s little, ring, middle, and index fingers on the left keypad’s “/,” “8,” “5,” and “2” keys, respectively, and their right hand’s index, middle, ring and little fingers on the right keypad’s “3,” “6,” “9,” and “*” keys, respectively. Connecting these two identical keypads via the same USB controller in the computer induced negligible delays (USB 2.0 delays signals by about 8 ms). The dual keypad setup was chosen so that the hands were placed as close together as possible during the practice phase, while in the test phase the right-hand keypad could be relocated without a possible confound with using different keypads. Because participants had their head in a chinrest, the keypad located at the side of the participant was outside the participants’ field of view. To prevent confounding of keypad location and sight at the keypads in the frontal location, we occluded the participants’ sight for the frontal keypad location with a black letter tray. In one of the two test conditions in each test block, the right-hand keypad was relocated to the mold 90° to the side of the participants’ shoulder. The chinrest was placed at 60 cm from the display to diminish any effect of the right hand being relocated over the course of the experiment and to assure that potential head-based frames of reference did not differ across participants. The room (2.25 × 2.25 × 3.50 m) was dimly lit with fluorescent light and fitted with a webcam for monitoring purposes.

Participant in the test phase condition with the right hand on the side, the left hand on the keypad that was occluded from vision, and the head in the chinrest
Task
Upon registering for the experiment, participants received the assignment to memorize two six-digit numbers, without telling them why. The ability to recite the numbers from memory was a prerequisite for further participation in the experiment, and one participant was rescheduled to a later time slot for not having learned the numbers. The digits in these six-digit numbers were associated with the left little finger (“1”) through the right little finger (“8”). At the start of the experiment, participants were told that only the first response of a sequence would be indicated by the location of the stimulus on the display, after which the memorized numbers were to be used as imperatives by the participant for the subsequent key presses in the sequence. Presentation of key-specific stimuli was omitted to preclude incompatible mappings between the location of a stimulus and the location of the associated response when the right hand was at the participants’ side.
For the little finger (“pinky”) and the ring, middle, and index fingers of the left hand (“p”, “r”, “m”, and “i”, respectively) and for the index, middle, ring fingers, and the pinky of the right hand (“I”, “M”, “R”, and “P”, respectively), the base sequences were ipIRPm (learned as 4-1-5-7-8-3) and MRmprI (6-7-3-1-2-5). The order of the sequences was counterbalanced over participants across the fingers of each hand. So, ipIRPm was counterbalanced to prMPIi, rmRIMp, and miPMRr, while MRmprI was counterbalanced to RPirmM, PIpmiR, and IMripP. Hence, the transitions between the second and third key presses in each sequence (i.e., R2 and R3), and between R5 and R6 involved a between-hand transition for each participant. Given their design, the two sequences are indicated as the LLRRRL and RRLLLR sequences with L indicating a left-hand finger and R a right-hand finger.
Throughout the entire experiment, the display showed eight homogenously gray square outlines (6 × 6 mm) against a black background and with a black filling. This layout corresponds with the spatial arrangement of the assigned response keys (i.e.,/, 8, 5, 2, 3, 6, 9, and *) when the two keypads were in the adjacent frontal location. The eight squares were placed in a horizontal order with 4-mm spacing (i.e., about 0.4° at 60-cm face–display distance). The row of squares was centered in the horizontal plane and vertically aligned at about one third from the top of the display.
The stimulus consisted of one square lighting up by its filling becoming bright green. Participants responded by depressing the spatially compatible key, after which the square became black again. All ensuing key presses were to be deduced from the corresponding, pre-learned six-digit numbers (cf. Experiment 2 in De Kleine and Verwey 2009). The completion of a six-element keying sequence is denoted a trial. Pressing a false key (i.e., failing to execute the sequence in its correct order) terminated a trial and resulted in the message “Wrong key” (in Dutch) being displayed for 500 ms. A premature first response resulted in a message saying “Too early” (in Dutch). The ensuing sequence started 1000 ms after a sequence was completed or terminated. Key release was not registered and could thus follow depressing a later key.
Procedure
At the start of the experiment, the experimenter helped the participant attain a posture that would remain comfortable even when the right hand was turned 90° outward. An on-screen message instructed participants on which keys they were to place their fingers. At the end of each block, and halfway through each block, participants received feedback for 10 s displaying their average execution time and error rates. If the error rate rose above 8 %, the message “Try to respond more accurately” (in Dutch) was presented. Error rates below 3 % resulted in the message “Try to respond faster” (in Dutch) in order to prevent cautious and therefore slow key pressing.
The experiment consisted of nine blocks in a single session. In Block 1, both keypads were placed in the mold in front of the participant. Each practice block in this experiment was composed of an 80-trial sub-block, a 20-s break, and another 80-trial sub-block. At the end of each block, a message informed the participant the block had finished, that the participant was to wait for the experimenter, and that a 4-min break started. If necessary, the experimenter would encourage the participant to improve sequence execution by responding faster or more accurately.
Block 2 was the first test block. By then, all participants had learned to translate the six-digit code into motor actions. The test block was composed of two 40-trial sub-blocks separated by a break that the experimenter terminated manually. The two sub-blocks of each test block differed in the location of the right keypad, which was either in front of the participant as with the practice blocks, or placed in a mold 90° to the right (relative to the shoulder). Half of the participants started with the right keypad at the side of the body and then performed with the right keypad in front of them, while this was reversed for the other half. Next, the participants continued practice in Blocks 3 through 8 with the two keypads in the frontal position. Finally, Block 9 was the second test block, which was identical to Block 2. Across Blocks 1 through 9, participants performed 600 repetitions of each sequence with the two keypads in the frontal location, and two times 20 trials per sequence with the right-hand keypad relocated to the participants’ side.
Following Block 9, the participants filled out a questionnaire. It first asked participants to write down the two sequences they had been practicing (‘free recall’) in terms of the symbols on the keys they had been depressing. As support, the symbols on the actual keys were presented in the questionnaire in a spatially realistic location (i.e., /852 369*). Notice that these symbols differed from the ones the participants had been learning before the experiment (which had consisted of the numbers 1–8). Next, the participants were asked to indicate the strategy they had been using for writing the sequences down. That is, whether (a) they had remembered the order of the symbols on the keys, (b) they had remembered the order of the stimulus locations, (c) they had executed the sequences with their fingers on the table or in their mind, or (d) they had used some other strategy.
Data analysis
The first two trials of each sub-block and sequences with an error were excluded from the RT analyses. Sequences were considered outliers and also removed when their total execution time was longer than the average time plus three times the standard deviation in a block. This excluded 1.8 % of the sequences. Errors were computed per block and for each sequential position. Error frequency was arcsin-transformed before being submitted to an ANOVA to stabilize the variance (p. 356 in Winer et al. 1991). The times between successive keying responses are denoted: the sequence initiation interval (T1) for the response to the stimulus and interkey intervals T2 through T6 for the five consecutive responses. Responses are denoted also by indices (R1–R6).
Results
Practice blocks
Figure 2 shows the RTs obtained with both hands in the frontal location as a function of Block and Key collapsed across the two sequences. The RTs were analyzed using a 9 (Block) × 2 (Sequence: LLRRRL vs. RRLLLR) × 6 (Key) repeated-measures ANOVA. From Blocks 2 and 9 only the sub-block was included in which participants used the right hand in the normal frontal location. This ANOVA showed main effects of Block, F(8,184) = 232.4, p < .001, η 2 p = .91, and Key, F(5,115) = 67.6, p < .001, η 2 p = .75. These effects support the notions that participants improved with practice, and that RTs differed as a function of key position in the sequence. A significant Block × Key interaction confirmed that key presses at some sequential locations gained more from practice than others, F(40,920) = 7.8, p < .001, η 2 p = .25.

Response times as a function of Block and Key position. Blocks 2 and 9 include only the sub-blocks with the right-hand keypad in the frontal location (like in the practice blocks). Between-hand transitions occurred before R3 and R6
With respect to the effect of the between-hand transitions, Fig. 2 indicates that in Block 1 the second between-hand transition during T6 was not slower than the preceding responses. This implies that R6 was not treated as a separate “1-element chunk” and, hence, that a between-hand transition does not necessarily lead to a clear segmentation of a movement sequence. In Block 1, T6 was even shorter than T5, F(1,23) = 6.9, p = .02, η 2 p = .23, but this advantage of T6 reduced with block, F(1,23) = 7.1, p < .001, η 2 p = .24, and it was no longer significant across Blocks 2–9, F(1,23) = 0.9, p = .34, η 2 p = .04.
Figure 2 shows also that the first between-hand transition during T3 was indeed relatively slow in the earlier blocks. Planned comparisons indicated that while R3 was significantly slower than R2 and R4 together in each of the 9 blocks, Fs(1,23) > 5.7, ps < .03, η 2 p s > .20, in later blocks this effect can be attributed to the fast R2 and not to R4. T3 was significantly longer than T4 only in Blocks 1 and 2, Fs(1,23) > 6.6, ps < .02, η 2 p s > .22, and this T3–T4 difference was indeed significantly greater in Blocks 1–4 than in Blocks 6–9, F(1,23) = 7.5, p = .01, η 2 p = .25. Given that the fast R2 can be attributed to response preparation on the basis of explicit sequenced knowledge (Verwey 2015), which was high (see below), these results support initial segmentation at T3, but not at T6, and further show that the initially slow R3 did not last with practice. Only the fast R2, relative to R3, persisted until Block 9, F(1,23) = 10.4, p = -.003, η 2 p = .31.
Arcsin-transformed error proportions per key were subjected to the same repeated-measures ANOVA as used for the RTs. Only the first error in a sequence counted because execution of the sequence was terminated after an error. The ANOVA showed main effects of Block, F(8,184) = 17.1, p < .001, η 2 p = .43, and Key, F(5,115) = 6.4, p < .001, η 2 p = .22, and a Sequence × Block interaction, F(8,184) = 2.7, p = .008, η 2 p = .11. These results indicated a relatively high error rate in Block 1 (of 3.3 % per key), and in Block 8 (2.2 % per key), while the other error proportions per key were below 2 %. The error rate was high for R3 relative to the other keys (1.9, 1.1, 2.6, 2.2, 2.2, and 1.3 %, respectively). Finally, according to the above-mentioned Sequence × Block interaction, LLRRRL had a relatively high error rate in Block 2 compared to RRLLLR (1.7 vs. 1.0 % per key), whereas error rates tended to be somewhat higher for RRLLLR in Blocks 4, 5, and 7.
Test blocks: representing movement sequences
To analyze the rate at which RT changed within the test blocks after the between-hand transitions, we analyzed performance in Block 2 (i.e., after 80 or 100 practice trials per sequence), and in Block 9 (after 580 or 600 practice trials) by distinguishing four successive five-trial bins. The averages of the errorless sequences in these bins were therefore analyzed with a 4 (Bin) × 2 (Block: 2 vs. 9) × 2 (Sequence: LLRRRL vs. RRLLLR) × 2 (Location of the right hand: Front, Side) × 6 (Key) repeated-measures ANOVA (see Fig. 3). In addition to the typical main effects of Block, F(1,23) = 134.6, p < .001, η 2 p = 0.85, and Key, F(5,115) = 52.2, p < .001, η 2 p = .69, this ANOVA showed main effects of Bin, F(3,69) = 41.6, p < .001, η 2 p = .64, and Location, F(1,23) = 10.5, p = .004, η 2 p = .31. The sequence main effect was not significant, F(1,23) = 1.6, p = .21, η 2 p = .07, and neither were all other interactions that included sequence and location, with the exception of the highest-order Bin × Block × Sequence × Location × Key interaction, F(15,345) = 2.0, p = .01, η 2 p = .08). These results suggest that location had similar effects on the LLRRRL and RRLLLR sequences.

Individual RTs in Bins 1–4 of Blocks 2 and 9 pooled across the two right-hand location conditions
According to the significant Key × Location interaction, relocating the right hand slowed some sequence elements more than others, F(5,115) = 2.6, p = .03, η 2 p = .10 (the location effect amounted to 55, 15, 52, 24, 13, and 20 ms for R1–R6, respectively). This is inconsistent with the applicability hypothesis and supports the adjustment hypothesis. A planned comparison confirmed that this interaction was a result of a larger location effect on responses that according to the adjustment hypothesis are preceded by an adjustment of the spatial sequence representation (i.e., R136), than on the other responses (R245), F(1,23) = 7.1, p = .01, η 2 p = .24. Further support for the adjustment hypothesis comes from the significant Bin × Location interaction which shows that the slowing that resulted from relocating the right hand was reduced across successive bins (61, 29, 17, 12 ms, respectively), F(3,69) = 3.0, p = .04, η 2 p = .12. This rapid reduction in the location effect is incongruent with the applicability hypothesis, as that would require a new representation which would probably take many more than the 20 trials per sequence available in each test block to develop. The reduction in the location effect for R136 across successive bins was not supported by a Key × Bin × Location interaction in the omnibus ANOVA, F(15,345) = 0.99, p = .47, η 2 p = .04 [but it was significant in a Block 9 ANOVA, F(3,69) = 2.8, p = .05, η 2 p = .11].
Figure 3 shows that the location effect had been caused by R1 and R3, especially in the earlier bins of Block 9, and not by R6. This was not unexpected given that the last response of a six-key sequence (just like R2) has been found to disproportionally benefit from explicit sequence knowledge (Verwey 2015). This notion was supported by a planned comparison across both test blocks and sequences showing that the location effect was greater for R13 than for R6, F(1,23) = 5.6, p = .03, η 2 p = .20.
Given the above support for the adjustment hypothesis, we then used planned comparisons to examine the prediction of that hypothesis that adjustment should be stronger in Block 9 than in Block 2 (because execution in Block 9 involves more task-specific representations). In line with this prediction, the location effect in R13, relative to R245, was significant across all bins of Block 9, F(1,23) = 11.9, p = .002, η 2 p = .34, while this was not the case with Block 2, F(1,23) = 0.6, p = .63, η 2 p = .03. Furthermore, the location effect in R13 (relative to R245) was significantly larger in Block 9/Bin 1 than in Block 2/Bin 1, F(1,23) = 4.7, p = .04, η 2 p = .17. This Block difference did not reach significance across all fours bins, F(1,23) = 2.4, p = .13, η 2 p = .09, which is reasonable given that the adjustment hypothesis suggests that the location effect reduces quite quickly within a test block. Indeed, a Location × Bin interaction in the Block 9 ANOVA reflected a reducing location effect across successive bins, F(3,69) = 4.0, p = .01, η 2 p = .15, though the location effect was still significant across Bins 2–4, F(1,23) = 5.3, p = .03, η 2 p = .19.
While the location effect was significant for R13 across both sequences, according to the adjustment hypothesis the location effect should be larger in R1 of RRLLLR than of LLRRRL, especially in Block 9/Bin 1 when representations are more task-specific than in Block 2. This prediction is supported by the earlier mentioned Bin × Block × Sequence × Location × Key interaction in the omnibus ANOVA, F(15,345) = 2.0, p = .01, η 2 p = .08. A planned comparison to test this specific hypothesis showed that in Bin 1 of Block 9, R1 of RRLLLR was substantially slower when carried out by the relocated right hand than R1 of LLRRRL (856 vs. 581 ms, respectively), F(1,23) = 4.6, p = .04, η 2 p = .17. Also, in Block 9/Bin 1 R1 was substantially slower with the right hand at the side than in the front, F(1,23) = 5.1, p = .03, η 2 p = .18. Most likely because of the limited statistical power of higher-order interactions, this effect was not significantly greater in Block 9/Bin 1 than in Block 2/Bin 1, F(1,23) = 2.8, p = .11, η 2 p = 11.
Arcsin-transformed error proportions in Blocks 2 and 9 were analyzed using a 2 (Block: 2, 9) × 2 (Location) × 6 (Key) repeated-measures ANOVA. It showed main effects of Block, F(1,23) = 6.4, p = .02, η 2 p = .22, and Key, F(5,115) = 3.8, p = .003, η 2 p = .14, indicating a slight increase in errors after practice (1.4 vs. 2.0 % per key), and some variation across key positions (1.6, 0.7, 2.4, 2.0, 2.1, and 1.5 %, respectively). The LLRRRL sequence had a higher error rate than RRLLLR with the right hand in the frontal location (1.8 vs. 1.3 %), and a lower error rate with the right hand on the side (1.7 vs. 2.2 %), F(1,23) = 14.1, p = .001, η 2 p = .38. The Location × Key interaction, F(5,115) = 3.3, p = .009, η 2 p = .13, indicated that with the right hand on the side, error proportion was a little higher for R1 (frontal: 1.3 % vs. side: 1.9 %), and R4–R6 (1.4 vs. 2.3 %), whereas it was lower for R3 (2.8 vs. 1.9 %).
Taken together, these analyses showed several findings in support of the adjustment hypothesis: Two of the responses that according to the adjustment hypothesis were preceded by adjustment (R13) were slowed more by the right-hand relocation than the other responses (R245). This slowing was greatest after more extensive practice in Bin 1 of Block 9 after which it reduced in the ensuing five-trial bins. However, R6 did not show any effects of relocating the right hand. This can be attributed to the use of explicit sequence knowledge. Finally, the location effect on R1 in the RRLLLR sequence appeared quite large, especially in Bin 1 of Block 9 (the expectation that this R1 would be relatively slow was not supported by all associated higher-order interactions which is probably due to a lack of statistical power).
Test blocks: chunking boundaries in Blocks 2 and 9
We also examined the effect of the between-hand transitions in Blocks 2 and 9 in the condition in which the right hand was in the frontal location. We used the R5–R6 difference and the R3–R4 difference to explore whether the first response following a between-hand transition might have induced the start of a segment that eventually consolidated (we excluded R2 from the last comparison because that response was most likely sped up by explicit knowledge, Verwey 2015). It immediately stood out that R6 was never slower than R5, not even in Block 1 (see Fig. 1). In contrast, the first between-hand transition appeared to be followed by a slow R3, that in Block 2 was 171 ms slower than R4, F(1,23) = 7.4, p = .01, η 2 p = .24. Detailed examination of the individual participants’ RTs per sequence showed that in Block 2 R3 was slower than R4 in only 30 of the 48 sequences (each of the 24 participants carried out 2 sequences). So, the between-hand transition certainly had no consistent effect on all participants. In Block 9, the R3–R4 difference (of 44 ms) did not reach significance any more, F(1,23) = 2.3, p = .14, η 2 p = .09, and R3 appeared slower than R4 in only 25 of the 48 sequences. So, like the second between-hand transition, the first between-hand transition did not seem to induce a concatenation point.
Awareness
We examined the numbers of participants who correctly recorded the six elements of 0, 1, or 2 sequences. Table 1 shows that 22 of the present 24 participants (92 %) had full awareness of two six-key sequences that were practiced. This was unexpectedly high given that the participants in five recent studies—which involved display of key-specific stimuli—showed that significantly less participants (namely 47 %) had been fully aware, χ2(2) = 103.3, p < .001 (these studies were reported in Ruitenberg et al. 2012; Verwey 2015; Verwey and Abrahamse 2012; Verwey et al. 2010; Verwey and Wright 2014). Due to this high awareness, we could not assess whether performance correlated with awareness (especially of R2 and R6).
Half of the present 24 participants (50 %) indicated that they had reconstructed their explicit knowledge when filling out the questionnaire by executing the sequences on the table top or covertly in their heads (Table 1). This number of reconstructing participants was significantly less than across four previous studies (Verwey 2015; Verwey and Abrahamse 2012; Verwey et al. 2010; Verwey and Wright 2014) where 68 % of the participants indicated to have used this strategy, χ2(2) = 55.2, p < .001. On the one hand, these numbers indicate that, despite the capacity of most participants to write down their sequences, still half of them had no direct access to their sequence knowledge. On the other hand, given that explicit knowledge of discrete keying sequences is highest at the start and end of a sequence due to primacy and recency effects (Verwey 2015), the high awareness in the present study show that it is quite likely that the present participants could speed up R6 using explicit knowledge.
Discussion
In order to better understand the nature of the representations that make up the motor chunks used to execute DSP keying sequences, we explored in detail how execution of two bimanual, familiar keying sequences would be affected when the right hand is relocated to the side. Explicit sequence knowledge was assessed to see whether that kind of sequence knowledge might be used to counteract a potential hand relocation effect on, especially, R6 (Verwey 2015). We further explored whether the between-hand transitions between R2 and R3 and between R5 and R6 would induce segmentation of the sequence in early practice, and whether these would eventually consolidate into concatenation points of successive motor chunks.
Adjusting spatial representations
The present data support an adjustment hypothesis that assumes that practice induces highly task-specific representations that can be adjusted when one of the hands is in a new location. They are inconsistent with the applicability hypothesis that asserts that inapplicable representations are no longer used.Footnote 2
The support for the adjustment hypothesis comes from the findings that relocating the right hand affected mostly the first response carried out by each hand (i.e., R1 and R3 in RRLLLR, and R3 in LLRRRL—but not R6, see below), and that this slowing lasted only about 15 trials. This slowing suggests that before a hand could start executing its part of the keying sequence, the sequence representation had to be adjusted to the location of that hand. The finding that this effect reduced so quickly in the successive bins of the test blocks shows that participants quickly were able to perform this adjustment more efficiently. This efficiency may be based on performing the adjustment during execution of the preceding responses (Verwey 1995, 2001), but the observation that even in RRLLLR R1 rapidly became faster (in which case preparation could not be carried out during earlier responses) suggests that the adjustment itself was quickly learned. Such a rapid adjustment is in line with neurophysiological studies showing adjustment of neural representations of space in less than 50–100 ms (Derdikman and Moser 2010; Georgopoulos et al. 1986; Zacks 2008).
The adjustment hypothesis is not supported by the observation that R6 did not show a hand location effect. It is possible that adjustment of R6 was easy because it involved just a single response and could entirely occur during execution of the preceding responses. Indeed, preparing one response during a preceding keying sequence seems to proceed more smoothly than when a few responses are prepared during the preceding key presses (Verwey 1995, 2001). Alternatively, the high awareness in the present participants of their sequences and the high saliency of the last response (one key press that was executed with another hand) may imply that the participants used explicit knowledge to speed up the last response rather than that they adjusted the sequence representation for just a single last response. This possibility is in line with the recent finding that especially the last response of a six-key DSP sequence is sped up by using explicit sequence knowledge (Verwey 2015). Preparing explicit knowledge of R6 could probably occur during execution of earlier responses because after practice, the central processor was no longer required for executing the sequence (Abrahamse et al. 2013; Verwey et al. 2015).
The current pattern of results provides some indications as to the nature of the motor chunks. The observation that sequence execution by both hands suffered equally from relocating one hand suggests that after about 600 trials the sequence representation relied primarily on a cross-hand trunk- or head-based reference frame that was adjusted at each between-hand transition. While neurophysiological research provided evidence for the existence of hand-based reference frames (Zacks 2008), the present finding that relocating one hand slowed both hands suggests that sequence execution did not rely much on such hand-specific, egocentric representations. Basically, allocentric representations may have played a role as well, but these are not believed to play an important role at advanced levels of movement execution (Willingham 1998). Earlier findings that execution rate is slowed when a sequence is carried out by other effectors, should probably be attributed to a spatial representation that is also effector-specific (Andresen and Marsolek 2012; Park and Shea 2005; Verwey and Clegg 2005; Verwey and Wright 2004), rather than to a muscle-oriented representation (Hikosaka et al. 1999; Keele 1968; Shea et al. 2011; Verwey et al. 2015). This dominant role of an effector-specific spatial representation is in line with findings with DSP sequences that execution rate reduced more when fingers of the other hand were used (Verwey and Wright 2004) than adjacent fingers of the same hand (Verwey et al. 2009). Participants in the latter study using adjacent fingers seem to have been able to make better use of the spatial hand-specific representations than in the former study where the other hand was being used. It should be noted, however, that the present results do not necessarily reject the possibility that sequence coding did include a component that was muscle specific or in a hand-based reference frame. For example, early in Block 9, participants may have relied on such a hand-based representation. Still, the dominant representations in Block 9 seem to have been one coded in a cross-hand trunk- or head-based spatial reference frame.
The finding that R1 and R3 in RRLLLR were both slowed indicates that a sequence representation was activated in memory, and it was then adjusted before executing R1 and then adjusted again before executing R3. In terms of motor buffer models, like the dual processor model (Verwey 2001), this shows that motor chunk representations that have already been loaded into the motor buffer can still be adjusted to different spatial conditions. Apparently, once loaded the motor buffer remains open to cognitive manipulations.
No consolidation of between-hand transitions
We further examined whether segmentation with limited practice may be determined by salient between-hand transitions and whether this would consolidate into motor chunks with practice. It was immediately obvious that R6 was never faster than R5. And while across all participants R3 appeared to be significantly slower than R4 in Block 2, this pattern occurred in only about two-thirds of the 48 averaged sequences per participant and block (2 sequences per participant in each block). In Block 9 the R3–R4 difference did not reach statistical significance at all. These results reject the hypothesis that in discrete keying sequences a between-hand transition is an important determinant of segmentation and chunking. This endorses the idea that motor chunks—at this level of practice—do not include hand-based representations, but include cross-hand representations.
Conclusions
The present study indicates that after 600 practice trials per sequence, motor chunks in a DSP task rely heavily on a cross-hand representation that codes individual key presses in a trunk- or head-based spatial reference frame. Recent indications that explicit knowledge is especially important for the last response in a six-key sequence (Verwey 2015) suggests that the lack of a hand location effect on R6 was caused by the use of explicit knowledge. After these 600 practice trials, it took only about 15 trials to fully adjust this representation to a novel location of the right hand. This spatial sequence representation seems to be implicit in the sense that, despite the high scores on an awareness test, half of the participants indicated that to write down the sequence elements they had to reconstruct their sequences by mentally or physically “executing” them. No indication was found for a clear contribution of a muscle-based (motor) representation or a hand-based spatial representation as that should have made execution rate of all sequence elements insensitive to the changed right-hand location. Indications for effector-specific learning—previously taken as evidence for motor learning—can perhaps be explained better by an adjustment of the timing to the biomechanical properties of the effectors used (Park and Shea 2003; Shea and Kovacs 2013). Nevertheless, a role of hand-based representations cannot be excluded yet. Such a representation may have been responsible for executing the sequences in the trials immediately after the hand had been relocated. Finally, the present data indicate that a between-hand transition may perhaps influence how some participants strategically segment their sequences in early practice, but there are no indications that these transitions determine the sequential positions at which successive motor chunks are eventually concatenated.
Notes
Segmentation involves the perceivable grouping of elements that probably reflects some cognitive strategy, whereas motor chunking explicitly suggests the use of integrated sequence representations (Verwey and Eikelboom 2003).
Because the adjustment hypothesis predicts effects especially after substantial practice, we performed also an ANOVA on just Block 2 results which is not reported here. In that block, the location effect did not reach significance, neither across all responses nor for some responses alone. This is consistent with the notion that performance in Block 2 was still largely based on sequence representations that are not hand location-specific (like the learned 6-digit numbers). In other words, the lack of significant location effects in Block 2 supports the assumption of the applicability hypothesis that the location effect in Block 9 is based on slower developing representations.
References
Abrahamse EL, Jiménez L, Verwey WB, Clegg BA (2010) Representing serial action and perception. Psychon Bull Rev 17(5):603–623
Abrahamse EL, Ruitenberg MFL, De Kleine E, Verwey WB (2013) Control of automated behaviour: insights from the discrete sequence production task. Front Hum Neurosci 7(82):1–16
Abrams RA, Landgraf JZ (1990) Differential use of distance and location information for spatial localization. Percept Psychophys 47(4):349–359
Ackerman PL (1988) Determinants of individual differences during skill acquisition: cognitive abilities and information processing. J Exp Psychol Gen 117:288–318
Acuna DE, Wymbs NF, Reynolds CA, Picard N, Turner RS, Strick PL et al (2014) Multifaceted aspects of chunking enable robust algorithms. J Neurophysiol 112(8):1849–1856
Adam JJ, Backes W, Rijcken J, Hofman P, Kuipers H, Jolles J (2003) Rapid visuomotor preparation in the human brain: a functional fMRI study. Cogn Brain Res 16:1–10
Anderson JR (2014) Rules of the mind. Psychology Press, New York
Andresen DR, Marsolek CJ (2012) Effector-independent and effector-dependent sequence representations underlie general and specific perceptuomotor sequence learning. J Mot Behav 44(1):53–61
Berner MP, Hoffmann J (2008) Effector-related sequence learning in a bimanual-bisequential serial reaction time task. Psychol Res 72(2):138–154
Berner MP, Hoffmann J (2009) Integrated and independent learning of hand-related constituent sequences. J Exp Psychol Learn Mem Cogn 35(4):890–904
Bernier P-M, Grafton ST (2010) Human posterior parietal cortex flexibly determines reference frames for reaching based on sensory context. Neuron 68(4):776–788
Berniker M, Franklin DW, Flanagan JR, Wolpert DM, Kording K (2014) Motor learning of novel dynamics is not represented in a single global coordinate system: evaluation of mixed coordinate representations and local learning. J Neurophysiol 111(6):1165–1182
Bo J, Seidler RD (2009) Visuospatial working memory capacity predicts the organization of acquired explicit motor sequences. J Neurophysiol 101(6):3116–3125
Bo J, Borza V, Seidler RD (2009) Age-related declines in visuospatial working memory correlate with deficits in explicit motor sequence learning. J Neurophysiol 102(5):2744–2754
Bonanni R, Pasqualetti P, Caltagirone C, Carlesimo GA (2007) Primacy and recency effects in immediate free recall of sequences of spatial positions. Percept Mot Skills 105:483–500
Broadbent DE (1975) The magic number seven after fifteen years. In: Kennedy A, Wilkes A (eds) Studies in long term memory. Wiley, Oxford, pp 3–18
Cho YS, Proctor RW (2002) Influences of hand posture and hand position on compatibility effects for up–down stimuli mapped to left–right responses: evidence for a hand referent hypothesis. Percept Psychophys 64(8):1301–1315
Colby CL, Goldberg ME (1999) Space and attention in parietal cortex. Annu Rev Neurosci 22(1):319–349
Cowan N (2000) The magical number 4 in short-term memory: a reconsideration of mental storage capacity. Behav Brain Sci 24(1):87–114
Criscimagna-Hemminger SE, Donchin O, Gazzaniga MS, Shadmehr R (2003) Learned dynamics of reaching movements generalize from dominant to nondominant arm. J Neurophysiol 89:168–176
De Kleine E, Verwey WB (2009) Representations underlying skill in the discrete sequence production task: effect of hand used and hand position. Psychol Res 73(5):685–694
Derdikman D, Moser EI (2010) A manifold of spatial maps in the brain. Trends Cogn Sci 14(12):561–569
Flanders M, Soechting JF (1995) Frames of reference for hand orienting. J Cogn Neurosci 7(2):182–195
Fleishman EA, Hempel WE (1955) The relation between abilities and improvement with practice in a visual discrimination reaction task. J Exp Psychol 49(5):301–312
Gentilucci M, Chieffi S, Daprati E, Saetti MC, Toni I (1996) Visual illusion and action. Neuropsychologia 34(5):369–376
Georgopoulos AP, Schwartz AB, Kettner RE (1986) Neuronal population coding of movement direction. Science 233(4771):1416–1419
Halford GS, Wilson WH, Phillips S (1998) Processing capacity defined by relational complexity: implications for comparative, developmental, and cognitive psychology. Behav Brain Sci 21:803–865
Henry FM, Rogers DE (1960) Increased response latency for complicated movements and a ‘memory drum’ theory of neuromotor reaction. Research Quarterly 31:448–458
Heuer H, Massen C (2013) Motor control. In: Healy AF, Proctor RW (eds) Handbook of psychology. experimental psychology, vol 4. Wiley, Hoboken, pp 320–354
Hikosaka O, Nakahara H, Rand MK, Sakai K, Lu X, Nakamura K et al (1999) Parallel neural networks for learning sequential procedures. Trends Neurosci 22(10):464–471
Jeannerod M (1997) The cognitive neuroscience of action. Blackwell, Oxford
Johnson GJ (1991) A distinctiveness model of serial learning. Psychol Rev 98(2):204–217
Jones MR (1981) A tutorial on some issues and methods in serial pattern research. Percept Psychophys 30(5):492–504
Keele SW (1968) Movement control in skilled motor performance. Psychol Bull 70(6):387–403
Keele SW, Jennings P, Jones S, Caulton D, Cohen A (1995) On the modularity of sequence representation. J Mot Behav 27(1):17–30
Keele SW, Ivry R, Mayr U, Hazeltine E, Heuer H (2003) The cognitive and neural architecture of sequence representation. Psychol Rev 110(2):316–339
Keisler A, Shadmehr R (2010) A shared resource between declarative memory and motor memory. J Neurosci 30(44):14817–14823
Kennerley SW, Sakai K, Rushworth MFS (2004) Organization of action sequences and the role of the pre-SMA. J Neurophysiol 91(2):978–993
Keulen RF, Adam JJ, Fischer MH, Kuipers H, Jolles J (2002) Selective reaching: evidence for multiple frames of reference. J Exp Psychol Hum Percept Perform 28(3):515–526
Koch I, Hoffmann J (2000) Patterns, chunks, and hierarchies in serial reaction-time tasks. Psychol Res 63(1):22–35
Kornbrot DE (1989) Organization of keying skills: the effect of motor complexity and number of units. Acta Psychol 70:19–41
Kovacs AJ, Mühlbauer T, Shea CH (2009) The coding and effector transfer of movement sequences. J Exp Psychol Hum Percept Perform 35(2):390–407
Krakauer JW, Ghilardi MF, Ghez C (1999) Independent learning of internal models for kinematic and dynamic control of reaching. Nat Neurosci 2:1026
Lange RK, Godde B, Braun C (2004) EEG correlates of coordinate processing during intermanual transfer. Exp Brain Res 159(2):161–171
Leoné FTM, Monaco S, Henriques DYP, Toni I, Medendorp WP (2015) Flexible reference frames for grasp planning in human parieto-frontal cortex. eneuro, ENEURO. 0008-0015.2015
Logan GD (1988) Toward an instance theory of automatization. Psychol Rev 95(4):492–527
Logan GD, Van Zandt T, Verbruggen F, Wagenmakers E-J (2014) On the ability to inhibit thought and action: general and special theories of an act of control. Psychol Rev 121(1):66
Logie RH, Cowan N (2015) Perspectives on working memory: introduction to the special issue. Mem Cogn 43(3):315–324
McIntyre J, Stratta F, Lacquaniti F (1998) Short-term memory for reaching to visual targets: psychophysical evidence for body-centered reference frames. J Neurosci 18(20):8423–8435
Miller GA (1956) The magical number seven, plus or minus two: some limits on our capacity for processing information. J Exp Psychol 56:485–491
Miller J, Ulrich R (2003) Simple reaction time and statistical facilitation: a parallel grains model. Cogn Psychol 46(2):101–151
Newell A, Rosenbloom P (1981) Mechanisms of skill acquisition and the law of practice. In: Anderson JR (ed) Cognitive skills and their acquisition. Erlbaum, Hillsdale, pp 1–55
Nicoletti R, Umiltà C, Ladavas E (1984) Compatibility due to the coding of the relative position of the effectors. Acta Psychol 57(2):133–143
Nissen MJ, Bullemer P (1987) Attentional requirements of learning: evidence from performance measures. Cogn Psychol 19(1):1–32
Obhi SS, Goodale MA (2005) The effects of landmarks on the performance of delayed and real-time pointing movements. Exp Brain Res 167(3):335–344
Panzer S, Wilde H, Shea CH (2006) Learning of similar complex movement sequences: proactive and retroactive effects on learning. J Mot Behav 38(1):60–70
Panzer S, Gruetzmacher N, Ellenbürger T, Shea CH (2014) Interlimb practice and aging: coding a simple movement sequence. Exp Aging Res 40(1):107–128
Park J-H, Shea CH (2003) Effect of practice on effector independence. J Mot Behav 35(1):33–40
Park J-H, Shea CH (2005) Sequence learning: response structure and effector transfer. Q J Exp Psychol Sect A 58(3):387–419
Pellizzer G, Bâ MB, Zanello A, Merlo MCG (2009) Asymmetric learning transfer between imagined viewer- and object-rotations: evidence of a hierarchical organization of spatial reference frames. Brain Cogn 71(3):272–278
Petit LS, Pegna AJ, Mayer E, Hauert CA (2003) Representation of anatomical constraints in motor imagery: mental rotation of a body segment. Brain Cogn 51(1):95–101
Proctor RW, Reeve TG (1988) The acquisition of task-specific productions and modification of declarative representations in spatial-precuing tasks. J Exp Psychol Gen 117:182–196
Proctor RW, Wang D-YD, Pick DF (2004) Stimulus-response compatibility with wheel-rotation responses: Will an incompatible response coding be used when a compatible coding is possible? Psychon Bull Rev 11(5):841–847
Proteau L, Carnahan H (2001) What causes specificity of practice in a manual aiming movement: Vision dominance or transformation errors? J Mot Behav 33:226–234
Proteau L, Marteniuk RG, Levesque L (1992) A sensorimotor basis for motor learning. Evidence indicating specificity of practice. Q J Exp Psychol 44A(3):557–575
Rosenbaum DA, Meulenbroek RJ, Vaughan J (1999) Remembered positions: Stored locations or stored postures? Exp Brain Res 124:503–512
Rosenbaum DA, Cohen RG, Dawson AM, Jax SA, Meulenbroek RG, van der Wel R et al (2009) The posture-based motion planning framework: new findings related to object manipulation, moving around obstacles, moving in three spatial dimensions, and haptic tracking. Adv Exp Med Biol 629:485–497
Ruitenberg MFL, De Kleine E, Van der Lubbe RHJ, Verwey WB, Abrahamse EL (2012) Context-dependent motor skill and the role of practice. Psychol Res 76:812–820
Ruitenberg MFL, Abrahamse EL, Verwey WB (2013) Sequential motor skill in preadolescent children: the development of automaticity. J Exp Child Psychol 115(4):607–623
Ruitenberg MFL, Verwey WB, Schutter DJLG, Abrahamse EL (2014) Cognitive and neural foundations of discrete sequence skill: a TMS study. Neuropsychologia 56:229–238
Ruitenberg MFL, Verwey WB, Abrahamse EL (2015) What determines the impact of context on sequential action? Hum Mov Sci 40:298–314
Sakai K, Kitaguchi K, Hikosaka O (2003) Chunking during human visuomotor sequence learning. Exp Brain Res 152(2):229–242
Seidler RD, Bo J, Anguera JA (2012) Neurocognitive contributions to motor skill learning: the role of working memory. J Mot Behav 44(6):445–453
Shea CH, Kovacs A (2013) Complex movement sequences. How the sequence structure affects learning and transfer. In: Arthur W, Day EA, Bennett W, Portray AM (eds) Individual and team skill decay: the science and implications for practice. Taylor/Francis, New York, pp 205–239
Shea CH, Kovacs AJ, Panzer S (2011) The coding and inter-manual transfer of movement sequences. Front Psychol 2:1–10
Shepard RN, Metzler J (1971) Mental rotation of three-dimensional objects. Science 171:701–703
Stadler MA (1993) Implicit serial learning: questions inspired by Hebb (1961). Mem Cogn 21(6):819–827
Stanley J, Krakauer JW (2013) Motor skill depends on knowledge of facts. Front Hum Neurosci 7:1–11
Sternberg S, Monsell S, Knoll RL, Wright CE (1978) The latency and duration of rapid movement sequences: comparisons of speech and typewriting. In: Stelmach GE (ed) Information processing in motor control and learning. Academic Press, New York, pp 117–152
Ulrich R, Miller J (1997) Tests of race models for reaction time in experiments with asynchronous redundant signals. J Math Psychol 41(4):367–381
Verwey WB (1995) A forthcoming key press can be selected while earlier ones are executed. J Mot Behav 27(3):275–284
Verwey WB (1996) Buffer loading and chunking in sequential keypressing. J Exp Psychol Hum Percept Perform 22(3):544–562
Verwey WB (1999) Evidence for a multistage model of practice in a sequential movement task. J Exp Psychol Hum Percept Perform 25(6):1693–1708
Verwey WB (2001) Concatenating familiar movement sequences: the versatile cognitive processor. Acta Psychol 106(1–2):69–95
Verwey WB (2003) Processing modes and parallel processors in producing familiar keying sequences. Psychol Res 67(2):106–122
Verwey WB (2015) Contributions from associative and explicit sequence knowledge to the execution of discrete keying sequences. Acta Psychol 157:122–130
Verwey WB, Abrahamse EL (2012) Distinct modes of executing movement sequences: reacting, associating, and chunking. Acta Psychol 140:274–282
Verwey WB, Clegg BA (2005) Effector dependent sequence learning in the serial RT task. Psychol Res 69(4):242–251
Verwey WB, Dronkert Y (1996) Practicing a structured continuous key-pressing task: Motor chunking or rhythm consolidation? J Mot Behav 28(1):71–79
Verwey WB, Eikelboom T (2003) Evidence for lasting sequence segmentation in the discrete sequence production task. J Mot Behav 35(2):171–181
Verwey WB, Wright DL (2004) Effector-independent and effector-dependent learning in the discrete sequence production task. Psychol Res 68(1):64–70
Verwey WB, Wright DL (2014) Learning a keying sequence you never executed: evidence for independent associative and motor chunk learning. Acta Psychol 151:24–31
Verwey WB, Abrahamse EL, Jiménez L (2009) Segmentation of short keying sequences does not spontaneously transfer to other sequences. Hum Mov Sci 28(3):348–361
Verwey WB, Abrahamse EL, De Kleine E (2010) Cognitive processing in new and practiced discrete keying sequences. Front Psychol 1(32):1–13
Verwey WB, Shea CH, Wright DL (2015) A cognitive framework for explaining serial processing and sequence execution strategies. Psychon Bull Rev 22(1):54–77
Wiestler T, Waters-Metenier S, Diedrichsen J (2014) Effector-independent motor sequence representations exist in extrinsic and intrinsic reference frames. J Neurosci 34(14):5054–5064
Wilde H, Magnuson CE, Shea CH (2005) Random and blocked practice of movement sequences: differential effects on response structure and movement speed. Res Q Exerc Sport 76(4):416–425
Willingham DB (1998) A neuropsychological theory of motor skill learning. Psychol Rev 105(3):558–584
Winer BJ, Brown DR, Michels KM (1991) Statistical principles in experimental design. McGraw-Hill, New York
Witt JK, Ashe J, Willingham DT (2008) An egocentric frame of reference in implicit motor sequence learning. Psychol Res 72(5):542–552
Wymbs NF, Bassett DS, Mucha PJ, Porter MA, Grafton ST (2012) Differential recruitment of the sensorimotor putamen and frontoparietal cortex during motor chunking in humans. Neuron 74(5):936–946
Zacks JM (2008) Neuroimaging studies of mental rotation: a meta-analysis and review. Cogn Neurosci J 20(1):1–19
Acknowledgments
This experiment was carried out by Eduard C. Groen in fulfillment of his bachelor’s thesis requirements. We thank Elian de Kleine and Elger L. Abrahamse for their support in all phases of the study.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Verwey, W.B., Groen, E.C. & Wright, D.L. The stuff that motor chunks are made of: Spatial instead of motor representations?. Exp Brain Res 234, 353–366 (2016). https://doi.org/10.1007/s00221-015-4457-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-015-4457-8