
Abstract
Recently, the Czech Insolvency Register covers about 200000 insolvency proceedings. In order to better assess the real impact of indebtedness across the Czech society, the data about creditors or reasons for debt might be of great value. Unfortunately, the vast majority of such information is contained only in scanned document copies attached to the insolvency proceedings. Therefore, this study aims at finding efficient pre-processing, clustering and classification techniques capable of extracting the wanted information from these cca 1200000 pdf-files.
The first author was partially supported by the Czech Science Foundation under Grant No. 15-04960S. The second author was partially supported by the Charles University, project GA UK No. 120616.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
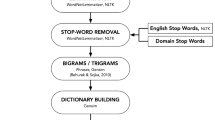


Notes
References
Aggarwal, C.C.: Data Mining: The Textbook. Springer, Berlin (2015)
Bradski, G., Kaehler, A.: Learning OpenCV. O’Reilly, Sebastopol (2008)
Chen, C.L.P., Zhang, C.Y.: Data-intensive applications, challenges, techniques and technologies. Inf. Sci. 275, 314–347 (2014)
Duda, R.O., Hart, P.E.: Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 15, 11–15 (1972)
Dunn, J.C.: Well-separated clusters and optimal fuzzy partitions. J. Cybern. 4(1), 95–104 (1974)
Kiryati, N., Eldar, Y., Bruckstein, A.M.: A probabilistic Hough transform. Pattern Recogn. 24, 303–316 (1991)
Kohonen, T.: Self-Organizing Maps. Springer, Berlin (2001)
Liu, B.: Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data. Springer, Berlin (2007)
Mrázová, I., Zvirinský, P.: Czech insolvency proceedings data: social network analysis. Procedia Comput. Sci. 61, 52–59 (2015)
Patel, C., Patel, A.: Optical character recognition by open source OCR tool tesseract: a case study. Int. J. Comput. Appl. 55, 50–56 (2012)
Pedregosa, F., et al.: Scikit-learn: machine learning in Python. JMLR 12, 2825–2830 (2011)
Rousseeuw, P.J.: Silhouettes: a graphic aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20(1), 53–65 (1987)
Still, M.: The Definitive Guide to ImageMagick. Apress, Berkeley (2005)
Vapnik, V.: The Nature of Statistical Learning Theory. Springer, Berlin (1995)
Vesanto, J., Alhoniemi, E.: Clustering of the self-organizing map. IEEE Trans. Neural Netw. 11, 586–600 (2000)
Zhang, T., Oles, F.: Text categorization based on regularized linear classifiers. Inf. Retrieval 4, 5–31 (2001)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Mrázová, I., Zvirinský, P. (2017). Extraction and Interpretation of Textual Data from Czech Insolvency Proceedings. In: Rutkowski, L., Korytkowski, M., Scherer, R., Tadeusiewicz, R., Zadeh, L., Zurada, J. (eds) Artificial Intelligence and Soft Computing. ICAISC 2017. Lecture Notes in Computer Science(), vol 10246. Springer, Cham. https://doi.org/10.1007/978-3-319-59060-8_12
Download citation
DOI: https://doi.org/10.1007/978-3-319-59060-8_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-59059-2
Online ISBN: 978-3-319-59060-8
eBook Packages: Computer ScienceComputer Science (R0)